
汉语篇章级小句关系的标注体系
2015-04-21 08:33吴云芳徐艺峰王恺然
中文信息学报 2015年3期
吴云芳,徐艺峰,王恺然
(计算语言学教育部重点实验室(北京大学) 北京 100871)
汉语篇章级小句关系的标注体系
吴云芳,徐艺峰,王恺然
(计算语言学教育部重点实验室(北京大学) 北京 100871)
句际关系自动分析属于篇章语义学研究的范畴,虽然英语句际关系的研究已有大量工作,但汉语句际关系的自动分析还只是刚刚起步。该文在RST理论框架下,结合汉语特点,提出了完整的汉语篇章级小句关系标注体系。将汉语话题和逻辑关系置于同一个框架下进行描述,将小句关系划分为事件附属关系和事件逻辑关系两大类。逻辑关系又包括6个中类、15个小类。目前已在人民日报语料上完成了8 000个句子的小句关系标注。抽取出其中1 000个句子检测了双盲标注的一致性,揭示了汉语意合性语言小句关系标注的困难;并基于标注数据对关系类型进行了定量分析,指示了汉语句际关系自动分析将面临的重点和难点。
句际关系;小句关系;语料库标注
1 引言
句际关系分析旨在探讨句子之间存在的或并列、或因果、或转折等多种逻辑关系,是实现文本内容深层理解的必需环节。句际关系的研究属于篇章分析(discourse analysis)的范畴。修辞结构理论(Rhetorical Structure Theory, RST)[1]将篇章结构划分为两个层级: 高层是整篇文本的结构框架(schema),基层是局部段落中句子与句子之间的连贯关系(coherence relations),篇章的整体关系就由这两个层次搭建起来。廖秋忠[2]指出,篇章研究可以分为两大类: 篇章连贯与篇章结构的研究。句际关系自动分析即是研究篇章微观层面的意义连贯。从发展趋向看,中文信息处理研究由字、词、句拓展到篇章层面,具有重要的理论意义。
句际关系自动分析有着广泛的实践应用价值,可应用于文本摘要、语篇生成、智能问答、情感分析、机器翻译等,能显著提升相关应用系统的性能。Louis 和Nenkova[3]基于实例关系和阐释关系来自动判别概括句和具体句,应用于文本摘要。Lin et al.[4]自动识别出句际关系,利用句际关系的转移矩阵对句子重新排序,比前人方法的错误率下降了29%。Girju[5]基于WordNet的语义类,利用词汇模式自动识别因果关系,将其嵌入到一个问答系统中,对因果类问句的准确率提升了25%。张志昌等[6]处理Why型问题回答时,利用关联标记、特定语义角色、词间蕴涵来识别句子之间的因果关系。Wang 和Wu[7]拟合不同句际关系的权值,使篇章级情感分析的性能得到了显著提升。Guzman et al.[8]研究表明,句际结构分析可以提升自动机器翻译评测的性能。
句际关系的自动分析研究强烈依赖于句际关系标注语料库,另一方面近年来句际关系标注语料库的建设大大刺激了句际关系的研究热潮。面对国外语言信息处理篇章语义关系的研究热潮,学界急切期待有广泛影响的、全面系统的、信息处理用的汉语句际关系标注语料库。而高质量语料库建设的基础和前提是科学的标注体系和完善的标注规范。
面向大规模高质量汉语句际关系标注语料库的建设,本文提出了信息处理用汉语篇章级小句关系的标注体系,并报告了真实文本中小句关系的标注实践。第2节评述了国内外句际关系标注语料库的建设状况;第3节阐释了小句关系的标注原则;第4节设定了小句关系的关系类型;第5节描述了对1 000个句子的双盲标注及其一致性检验;第6节基于标注语料对句际关系进行了定量分析;第7节是本文总结和进一步工作的展望。
2 相关工作
2.1 句际关系语料库的建设
近年来,在篇章语义研究热潮的带动下,英语等国外语言都纷纷建设句际关系语料库,汉语也曾有句际关系语料库构建的一些初期尝试。
英语中的句际关系标注语料库主要有两个。(1) 英语篇章标注语料库(RST-DT),是由Carlson et al.[9]依据修辞结构理论RST构建的,设定了78种修辞关系,标注了宾州树库中的385篇华尔街日报文档。(2)宾州篇章树库(Penn Discourse TreeBank, PDTB),标注了2 159篇共计100万词的华尔街日报文档,先于2006年发布了第一版,后又于2008年发布了第二版[10]。另外,其他语言例如印地文、土耳其语、捷克语、哥本哈根语、阿拉伯语也纷纷仿效PDTB构建了句际关系语料库。
汉语中有关句际关系的语料库主要如下: (1)清华大学构建的汉语树库[11],描述了句际之间11种语义关系,是依附于句法树库的一个副产品。(2)Xue[12]依据PDTB的方法,提出了汉语句际关系树库建设的主要理念;Zhou and Xue[13]提出了类PDTB(PDTB-Style)的汉语篇章树库标注方法,在参照PDTB方法的同时针对汉语特性作出了很多修正。(3)华中师范大学开发的“汉语复句语料库”[14],全部收录的是有关联标记的复句,共计658 447句,语料主要选摘自《人民日报》和《长江日报》,但未收录没有关联标记的隐性句际关系。(4)浙江大学建设的汉语篇章修辞结构标注语料库[15],借助RST的理论体系和标注工具,自底向上构建篇章关系树,选取的语料主要是财经文本,主要标注句子间的语义关系而未标注小句间的语义关系。(5)台湾大学依据PDTB的标注理念,在Sinica树库的81篇文档上标注了句际关系[16],但台湾的报刊语言和大陆的规范汉语存在着很多词汇和句法上的差别。(6)2013年底,哈工大构建的汉语篇章关系语料(HIT-CDTB)[17]对外公开。选取了OntoNotes 4.0中的525篇文章。针对每一篇文本,标注了三部分内容: 分句篇章关系(篇章关系涉及到的两个关系元素位于同一个句子内)、复句篇章关系(两个关系元素是两个独立的句子)和句群篇章关系(篇章关系涉及的两个关系元素都是句子集合)。但是在标注体系上,哈工大语料库更多依循了PDTB的标注理念,有些方面并不能反映汉语的语言实际。
综上,现有的汉语句际关系标注语料库还不能完全满足中文信息处理的需求。因此,我们将致力于构建一个大规模高质量的汉语句际关系标注语料库,力争为汉语句际关系研究提供基础资源和基准语料。
2.2 汉语复句语义关系的研究
汉语语言学中有关句际关系的探讨主要集中于复句研究,是描写性的而非实证性的,是面向人的而非面向机器的。徐赳赳[18]比较分析了汉语语言学复句研究与修辞结构理论RST的区别: 复句研究的理论不够系统,而后者理论较为完整;复句研究注重关联词语的形式标记,而后者注重功能。
前人从不同的角度出发提出了多种不同的分类方法,主要有下面三种代表性的观点: (1) 吕淑湘和朱德熙[19]提出了直分法,划分为并行、进一步、交替、比例、比较得失、因果、条件、无条件、让步、假设等十种关系。(2) 胡裕树[20]主张“联合-偏正”二分法,把复句分为联合和偏正两大类,联合类又分为并列、连贯、递进、选择四类,偏正类又分为因果、条件、让步、转折四类。这种二分法的影响很大,是很多语文教材所采用的分类体系。(3) 邢福义[21]主张“因果-并列-转折”三分系统,因果类复句又分为因果、推断、假设、条件、目的五类;并列类复句又分为并列、连贯、递进、选择四类;转折类复句又分为转折、让步、假设三类。另外,吴为章和田小琳[22]区分了句子与句子组成句群时的12种语义关系,包括并列、连贯、递进、选择、总分、解证、因果、目的、条件、转折、假设、让步等,由于汉语中逗号使用的灵活性使复句与句群的界限变得模糊,句群的关系类型一般也适用于描述复句的语义关系。
3 理论支撑与标注原则
3.1 篇章理论支撑
句际关系可以从结构关联和语义关联两个方面来描述。
结构关联方面,我们选择修辞结构理论RST作为指导。RST理论将篇章结构分为两个层级,目前我们只关注基层句与句之间的连贯关系。主要理论主张是: (1)关系性,小句之间存在着各种语义关系,绝大部分关系是不对称的,可分为“核心成分(nucleus)”和“从属成分(satellite)”两类;(2)功能性,小句之间的语义关系是从功能的角度来考量的;(3)层次性,小句之间的关系不是一个扁平结构,而是一个层级结构。RST理论和PDTB理念的最大区别是,RST要求整个文本块形成一个完整的树结构,而PDTB在一个局部上下文窗口内来描述逻辑关系。我们在RST框架下来构建汉语篇章树库,更符合汉语传统语言学的理念;而前人所建汉语篇章语料库大多依循了PDTB框架,并不能反映汉语的实际。
在表征形式上,句际关系形成一颗层级结构树。为了形式上的统一和处理的方便,我们将多核心的并列关系转变成了右向的二叉树结构。例如对下面的例1句子,{n}表示逗号隔开的语言片段的序号),可用图1的树结构来表示,其中,弧上的标签表示语义关系类型,弧的箭头指向中心成分。
例1 {1}中国虽然面临耕地少、人口多、粮食需求压力大的现实,[转折,1,2-4]{2}但也存在着巨大的发展潜力,[分述,2,3-4]{3}中国有解决粮食问题的经验和办法,[并列,3,4]{4}农民中蕴藏着巨大的生产积极性,[因果,1-4,5-6]{5}完全有理由相信, [属性,5,6]{6}中国政府和人民有能力依靠自己的力量解决粮食供给问题。
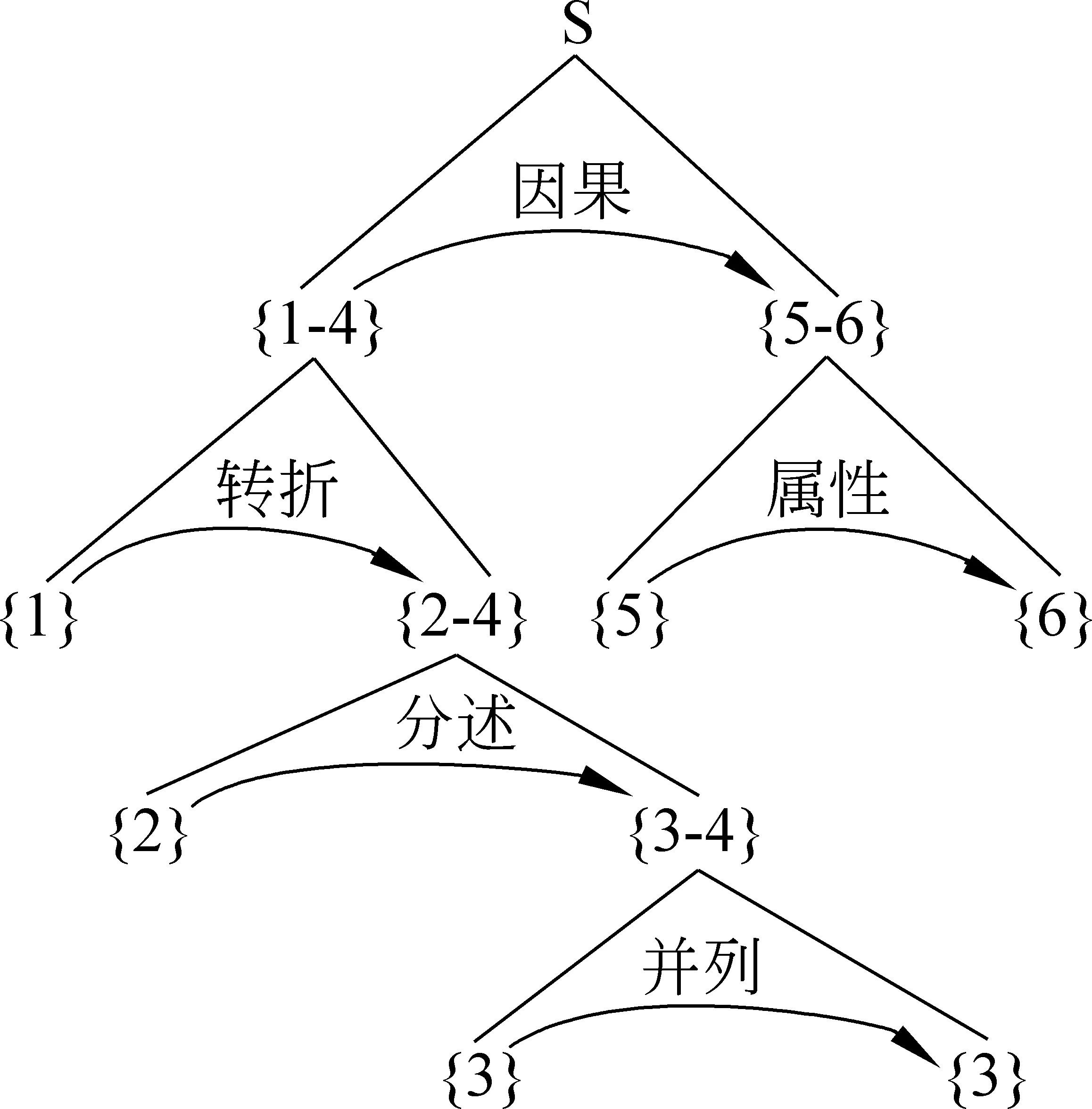
图1 句际关系树示例
语义关联方面,我们借鉴RST、PDTB以及汉语传统语言学的分类体系,提出了事件附属关系和事件逻辑关系两大类关系类型,详见下文的描述。
3.2 汉语语言理论支撑
前贤语言学家指出[23-24],汉语是话题优先的语言(topic-prominent),是篇章取向的语言(discourse-oriented language);而英语是主语优先的语言(subject-prominent),是句子取向的语言(sentence-oriented language)。汉语语言的这两个特性对句际关系自动分析和标注有着重要的影响。
话题优先意味着话题在汉语真实文本中频繁出现,其语义辖域可能覆盖到后续的一个或多个句子。话题经常由短语结构(例如名词短语或者介词短语)来充当, 而不是一个包含主谓结构的句子。话题的广泛存在使得基本篇章单元(elementary discourse unit, EDU)的切分成为汉语句际关系分析中一个相对困惑的问题,而英语句际关系研究中EDU的识别是一个颇为容易的问题。
篇章取向意味着汉语所谓的句子和篇章之间不存在明显的界限,汉语的句子不等同于英语中的sentence。虽然形式上是以句点结束,但汉语句子可以包含多套完整的主谓结构,导致一个句子可以很长很复杂。篇章取向混淆了汉语句子和篇章的严格区分,使得句子层面的篇章分析(sentence-level
discourse parsing)和文本层面的篇章分析(text-level discourse parsing)叠加在一起。也因此,在本文的行文中,小句关系和句际关系没有作严格的区分。
上述两个语言特征使汉语句际关系分析一开始就遭遇两个问题: 如何确定一个句子以及如何确定一个基本单元。本文以一种实用的、直观的方法来解决这两个问题,以句点显性标识的一个语言片段称之为一个句子,其中以逗号分隔的语言片段称之为小句,一个小句即对应于一个句际关系的基本单元。本文目标是处理句子层面的结构和语义关系,但是汉语的句子有些时候其实就相当于英语的文本级篇章,因此本文描述的小句关系体系可以便捷地迁移到宏观的篇章层面。我们将逗号分隔的语言片段即看作是一个基本单元,用不同的关系标签来标示,关于逗号的种种歧义问题期待能在高层的篇章分析层面来联合解决。
3.3 标注原则
(1) 标注单元
目前阶段我们集中于句子范围内小句之间语义关系的识别和标注。句子的认定遵从“点号标句”的从众性原则,即以标点符号“。!?;……”等分隔开的语言片段。而更大单元的篇章语义关系识别,例如句群之间的语义关系留待将来的研究。根据我们前期的考察和预标注,句子之间的关系松散且相对简单,而小句之间的关系紧密且丰富多样。
小句关系的基本组成单元EDU是“小句”,即形式上以逗号“,”分隔开的语言片段,既可以是一个主谓结构也可以是一个名词性短语、介词性短语等。
(2) 显性和隐性关系
我们将对文本中任意相邻的两个小句均标注句际关系,而不论是否有关联标记的连接。对于有关联标记的显性关系,标注者参考关联标记来标注关系类型。而对于隐性关系,标注者只能通过意义功能的理解来标注关系类型,但不需要像PDTB那样补充出关联标记。因为汉语中隐性关系不是关联标记的简单省略,而是通过词汇、句法语义来承载句际语义功能,在很多情形下无法加入一个合适的关联标记。
(3) 层级结构
汉语小句关系形成一颗有层级结构的树,不允许有非树结构的存在,例如共享论元、嵌套论元、交叉论元和重叠论元。
(4) 关系类型
两个语段之间只能标注唯一的一种关系类型,且需要标注到最细层次的关系类型。
(5) 论元标示
联合关系都是多核心结构,主从关系都是单核心结构。为了处理上的统一和方便,联合关系以最右向成分作为核心。这样,任何一个小句关系都有且仅有两个论元语段组成,核心论元和从属论元。
4 汉语小句关系的关系类型
小句关系的本旨在于描述事件之间的各种关系,我们将其分为事件附属关系和事件逻辑关系两大类。事件逻辑关系标示了不同事件之间的各种逻辑关系,例如因果、转折等;而事件附属关系则交待了事件发生的时间、地点、发出者及其他话语成分。针对汉语特点提出了“事件附属关系”,是本文体系与前人研究的显著不同。
前人在研究复句语义关系时,专注于描述事件之间并列、转折、因果等多种逻辑关系,却有意无意忽略了复句中存在的描述时间、地点、所属等语义内容的语言片段。另一方面,前人在研究汉语的话题结构时,专注于证明话题的存在以及说明汉语的“话题-评述”结构,但对于评述结构中又存在的各样逻辑关系却不关心。描述同一个语言对象,复句语义关系和话题结构从不同的角度加以关照和描写,却像两条不相交的平行线。而事实上,在实际的语料库标注过程中,要标注一个完整的句子生成一棵完整的层级结构树,话题等成分的标注和逻辑关系的标注是缺一不可的。本文体系将话题结构和逻辑关系置于同一个框架下进行描述和标注,充分照顾了汉语特点,使标注体系更加简洁、完整和有效。
4.1 事件附属关系
根据对语料的考察,事件附属关系进一步可划分为以下三类。
(1) 话题(topic)[TOP]
引出一个话题,或者阐述事件发生的时间地点即时域式话题(如例2),或者是事件的所属施动者即所属式话题(如例3)。话题经常将其辖域延伸至后面多个小句而形成话题链。话题是语言类型学上汉语的显赫范畴之一,将其显性标示出来,可以凸显汉语特色。另一方面,话题在汉语真实文本中高频出现,如果不加标注,则无以形成完整的层级结构树,人工标注者将无所适从,最终将导致语料的标注一致性非常低。
例2 {1}在未来的世界,[TOP,1,2-3]{2}各个国家和各个民族能够始终和睦相处、友好合作、共同发展,{3}能够建立起公正合理的国际政治经济新秩序。
例3 {1)吉林省梨树县女农民蔡淑珍,[TOP,1,2-6]{2}过去不懂技术,{3}养鸡鸡死,{4}养兔兔亡,{5}赔了几万元,{6}险些寻了短见。
(2) 属性(attribute)[ATT]
表明言谈内容的发出者或者意见的持有者。这与PDTB语料是类似的。这样的标注信息对于有些应用(例如情感计算)非常有用。
例4 {1}朱邦照说,[ATT,1,2-3]{2}中方认为,[ATT,2,3]{3}叶利钦总统辞职是俄罗斯的内部事务。
(3) 标记(marker)[MAR]
话语标记不参与命题意义的表达,在言谈当中起组织结构、建立关联的作用,一般是由词语性成分或者词汇化的短语性成分充当。同话题、属性一样,话语标记的语义辖域也经常延伸至后面多个小句。以往的研究中,将话语标记常常附加于其后的第一个小句,但不能反映话语标记真正的语义辖域。
例5 {1}同时,[MAR,1,2-3]{2}也希望你们安全生产、经济调度,{3}实现经济增长方式的转变。
4.2 事件逻辑关系
在大量参考前人文献的基础上,通过考察真实文本语料,我们设定了表1所示的事件逻辑关系类型。表中“[ ]”内表示英文标记符。

表1 汉语小句逻辑关系类型
表1所示的小句关系包含大、中、小三种关系类型,显示了不同粒度下的类型区分。大类上(CLASS)区分为“联合”和“主从”,这符合汉语语言学的一般认识,也符合RST理论关于“核心”与“从属”成分的论述。中类上划分为六个类别,最细致的小类上划分为15个类别。我们在设定具体关系类型时,密切考虑了智能问答、情感计算等自然语言处理应用系统的需求。在上述大、中、小三层语义关系下,进行句际关系分析时可以根据实际应用需求选择不同的粒度。
(1) 等立 [COOR]
表示同类事物的并列,或者表示类似事件的并存。常用关联标记是“也”、“又”、“还”,“一方面……另一方面……”等。
例6 {1}旧西藏交通险阻,[COOR,1,2]{2}行路艰辛,{3}货物运输、邮件传递全靠人背畜驮。
(2) 时序 [TEMP]
表示相关的事件依时间序列先后发生。常用关联标记是“接着”、“然后”等。
例7 {1}穆罕默德塔拉尔1929年11月1日出生于旁遮普省,[TEMP,1,2-3]{2}1951年毕业于旁遮普大学法学院,[TEMP,2,3]{3}1974年供职于拉合尔高等法院。
(3) 选择 [ALT]
表示在两个事件中作出选择。常用关联标记是“或者……或者……”等。
例8 {1}主要原因不在于英文或华文难学,[ALT,1,2]{2}或教师教得好,{3}而在于缺少学习动机与缺乏机会使用所学语文。
(4) 递进 [PROG]
表示两个事件在量上有增强递进的关系。常用关联标记是“不但……而且……”等。
例9 {1}可以肯定,{2}人类在未来仍将与科技为伍,[PROG,2,3]{3}并且会愈来愈依赖它,{4}科技之利与弊仍将伴随我们进入下一世纪。
(5) 顺承 [SUCC]
一个接一个地说出连续的动作或者相关的事件。一般而言,当不存在其他明显的句内关系时,标注“顺承”。
例10 {1}本世纪初,{2}数万名华人劳工远涉重洋来到南非,[SUCC,2,3]{3}同当地人民一道为南非的开发作出了贡献。
(6) 转折 [CONT]
说明两个事件在逻辑上有逆转关系。常用关联标记是“但是……”等。
例11 {1}主要原因不在于英文或华文难学,{2}或教师教得好,[CONT,1-2,3]{3}而在于缺少学习动机与缺乏机会使用所学语文。
(7) 让步 [CONC]
前一小句先做出让步,后一小句作出转折。常用关联标记是“即使……也……”等。
例12 {1}即使送出去了,[CONC,1,2]{2}收者也不一定领情。
(8) 因果 [CAUS]
说明事物间的因果联系,是典型的推论关系。常用关联标记是“因为……所以……”等。
例13 {1}孤儿是祖国的未来,[CAUS,1,2]{2}也必须得到母爱。
(9) 结果 [RESU]
说明因施行某种行为而产生的结果。常用的连接标记是“导致”“使得”等。
例14 {1}可以肯定,{2}人类在未来仍将与科技为伍,{3}并且会愈来愈依赖它,[RESU,2-3,4]{4}科技之利与弊仍将伴随我们进入下一世纪。
(10) 目的 [PURP]
说明施行某种行为的目的。常用关联标记是“为了……”等。
例15 {1}而应当继续努力,[PURP,1,2]{2}促使经济进一步回升。
(11) 假设 [HYP]
以某种假设即某种虚拟性条件作为前提从而得出某种结论。常用关联标记是“如果……就……”等。
例16 {1}没有法制保障人民主权和个人权利的实现,[HYP,1,2]{2}人民就不会有当家作主的意识。
(12) 条件 [COND]
以某种条件为依据推断出某种结果。常用关联标记是“只有……才……”等。
例17 {1}不管遇到什么事情,[COND,1,2]{2}我们必须前进。
(13) 解证 [EXPL]
前一小句说明一个现象或者事实,后面小句从某一角度来进一步阐释这个现象或者解释事实。
例18 {1}中国的上海市与夸—纳省开展了多领域的经济合作,[EXPL,1,2]{2}先后建立了家电、五金、搪瓷、文具等企业。
(14) 分述 [LIST]
前一小句是概括,后面的小句列举其中包含的元素,一般包含两个以上的元素。
例19 {1}出席茶话会的还有: [LIST,1,2-4]{2}中央军委委员傅全有、于永波、王克、王瑞林,{3}全国人大常委会秘书长曹志,{4}全国政协秘书长朱训等有关方面负责人和各界人士共400多人。
(15) 总括 [GENE]
前面的小句陈述一系列相关事情,后面小句总括前面小句的意思。常用关联词语有“总而言之”、“一言以蔽之”等。
例20 {1}依法治国、建设法治国家的实质,{2}就是要确保党和政府依法执政和依法行政,{3}执法司法部门依法办事,{4}公民依法行使权利和履行义务,[GENE,2-4,5-6]{5}一句话,{6}就是要从法律和制度上保障人权。
5 汉语小句关系的标注实践
5.1 语料标注
在上述标注体系的指导下,我们设计开发了句际关系标注的计算机辅助软件。在这款软件中,标注者可以方便地进行结构的分析和关系的标注,软件可以对非树结构进行自动检测和报错。实践证明,计算机辅助标注软件大大提高了标注速度,减少了人工的误操作。
我们选取了2000年2月的人民日报语料作为标注文本,目前已完成了一个月语料的所有标注。我们将精选一部分标注语料在北大计算语言学研究所的网站上公布,供研究者免费下载和使用。
语料库人工标注的一致性(inter-annotator agreement)是衡量语料库标注质量的重要指标。因此,我们抽取了1 000个句子进行双盲标注(doubly blind),即两个标注者依据标注规范分别独立标注语料,不可以交流讨论,两个标注者不一致的数据再由第三者进行仲裁,最后生成黄金标注数据。三个标注者均为语言学专业背景。
汉语句际关系的语料标注是一件困难的工作。由于汉语是意合性语言,小句之间常常不用显性的关联标记来连接,而是依靠上下文语境、词汇语义等来承载逻辑关系,由此,不同标注者在“揣测”小句之间的层级结构和逻辑关系时会产生不一致。这些不一致暴露了汉语句际关系标注的困难,有些情形下揭示了句际关系体系设定的不合理之处,提示了标注体系改进和完善的方向。
5.2 层级结构的标注一致性
双盲标注的1 000个句子中,小句数目大于等于3的句子数是528,即有528个句子包含两层以上的小句关系,也即所谓“多重复句”。我们对这528个句子来检测句际层级结构的标注一致性。评测中,使用宽式和严式两种评价指标。
严式一致性(strict agreement):
(1)
宽式一致性(looseagreement):
(2)
表2汇报了句际层级结构的标注一致性,严式和宽式一致性非常接近。68%的层级结构一致性不是很高,这一方面是由于所选取的语料是人民日报语料,政论性文体中的句子长度普遍偏长且句子结构相对复杂,另一方面也说明,汉语句子的层级结构标注是一件很困难的工作,一致性比较难以把握。

表2 层级结构的标注一致性
5.3 关系类型的标注一致性
关系类型的标注一致性建立在层级结构标注一致的基础之上,即只有在两个标注者层级结构标注一致的前提下才能够计算逻辑关系类型的一致性。由于小句关系是大、中、小三层的层次结构,因此我们在中类和小类两个不同的粒度上来评价逻辑关系的标注一致性。我们将“话题、属性、标记”合并为“附属关系”,看作是与“并列、对比、推论、条件、总分、分总”相平行的中类标签。句际关系类型一致性的计算公式如下:
(3)

表3 关系类型的标注一致性
表3汇报了关系类型的标注一致性。在小类层次上,语义关系的一致性不尽如人意;而在中类层次上,语义关系的一致性有了显著提升。句际关系的研究大都集中在中类层次上,因此74.4%的一致性还是比较满意的。
5.4 关系类型的混淆矩阵
标注体系中关系类别的设定是否合理,某种程度上可以用真实文本标注的实践来验证。如果两个类别混淆度很高,说明这两个类别界限不清晰,或许应该加以合并;如果某个类别与其他诸多类别都有混淆,说明这个类别定义不清晰、地位不明确,需要重新解释重做定义。由此,关系类型的混淆矩阵提示了标注体系进一步完善的方向。
为了了解两个标注者之间不一致性较高的关系类型,我们基于双盲标注语料统计分析了不同句际关系之间的混淆程度,如表4、表5所示。
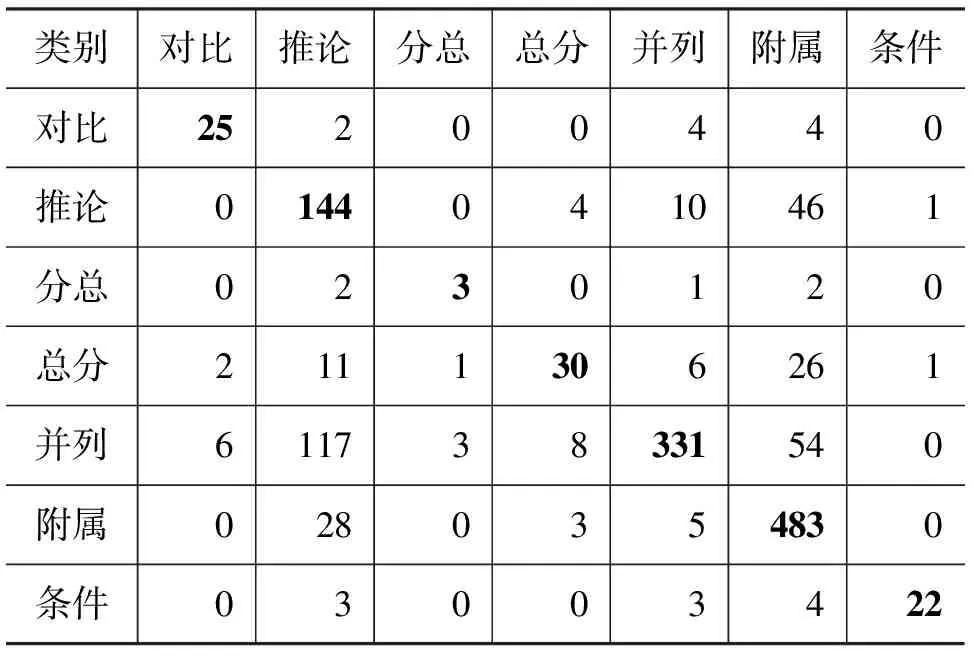
表4 中类标注的混淆矩阵
根据表4, 在中类关系层次上,1)由于其中一个标注者倾向于判定“并列”关系,使得“并列-推论”、“并列-附属”的混淆程度较高;2)由于其中一个标注者倾向于判定附属关系,使得“附属”与其他诸多类别都发生了混淆;3)从总体上看,“并列”和“附属”这两个类别在文本中出现频度高,且易于别类发生混淆,因此在标注规范中需要更为详细的说明。
根据表5,在小类关系层次上,1)由于其中一个标注者倾向于判定“顺承”关系,使得“顺承-结果”、“顺承-话题”、“顺承-目的”的混淆程度高,因此对于“顺承”关系,标注规范中还需详加描述;2) 由于其中一个标注者倾向于判定“话题”关系,使得“话题-目的”、“话题-解证”、“话题-因果”的混淆程度高;3)“标记-话题”的混淆程度较高;4)由于对“时序”关系的定义不清晰,“时序”语义类的一致性较差。

表5 小类标注的混淆矩阵
6 汉语小句关系的定量分析
在2000年2月的人民日报语料上,已经由一名语言学者标注了所有句子的小句关系,其中抽取1 000个句子进行了严格的双盲标注,又对其中2 000个句子进行了多次的人工校对,现一共有大于等于2个小句的黄金标注数据2 100个句子。基于这2 100个句子,我们统计分析了小句关系的不同分布,以期对汉语句际关系有较为全面的定量认识,提示进一步研究的重点和难点。
6.1 不同关系类型的分布
在不同粒度的层面上,不同关系类型的分布如表6所示。可以看出,在真实的新闻体语料中,不同关系的分布是极不平衡的。在小类关系层次上,分布频率最高的是“等立”关系,其次是“话题”,两者分布之和高达41.9%;而“让步”、“选择”、“分述”、“假设”、“条件”等关系出现的频率非常低。在中类关系层次上,分布频率最高的是“并列”关系,其次是“附属”关系,然后是“推论”关系,三者分布之和高达85.8%,而“对比”、“条件”、“总分”、“分总”的分布都是比较低的。“话题”的高频出现验证了本文设置“事件附属关系”的合理性和重要性,如果没有这种关系类型,标注者在标注真实文本时将会无所适从。

表6 不同关系类型的分布
6.2 显性和隐性关系的分布
关联标记对于句际关系的类型区分有重要提示作用,前人的复句研究中非常重视关联标记的作用。参考前贤的研究文献,我们列出了表征不同语义关系的139个连词、80个副词。据此关联标记词表,对2 100个句子统计分析了有标记显性关系和无标记隐性关系的分布,如表7所示。在统计时摒除了三种附属关系。
表7显示,显性关系的比例仅为20.1%,而隐性关系的比例高达79.9%。汉语复句研究中非常重视关联标记的作用,而事实上在真实文本中,大量分布的是没有关联标记的隐性关系。根据英语PDTB
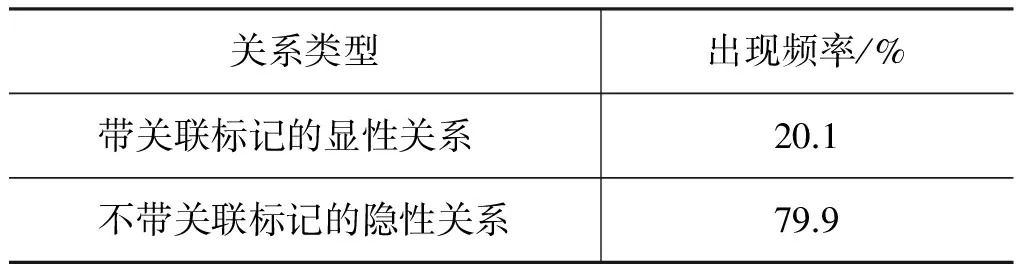
表7 显性和隐性关系的分布
语料的统计[25],40 600个句际关系中,显性关系的比例为45.5%,隐性关系的比例为54.5%。与英语语言相比较,汉语隐性关系的分布比例高出许多。隐性关系的广泛分布与汉语“意合型语言”的特性是相符合的,即小句之间的语义关系不是依据形式标记而主要是依据内部的逻辑语义来链接。因此,关联标记的作用在大规模汉语真实文本处理中是很受限制的,汉语句际关系自动识别的重点和难点应该是隐性关系而非显性关系。
6.3 不同类型显性和隐性关系的分布
进一步地,我们统计了不同语义类型下有标记和无标记的分布,在统计时摒除了三种特殊的附属关系以及出现次数极少的“让步”关系,结果如表8 所示,显示时按照无标记隐性关系的出现频率由高到低排列。

表8 不同关系显性和隐性的分布
表8显示,只有递进、转折、选择这三种逻辑关系显性多于隐性关系,其余的逻辑关系都是隐性明显多于显性关系。顺承、分述、结果、总括这四种关系,隐性类型占据的比例均高达90%以上。相比之下,假设、因果、条件这三种逻辑关系显性和隐性的比例相对平衡。
7 结语
汉语篇章级句际关系的研究才刚刚起步。本文综述了国内外篇章树库构建的状况,评述了汉语复句的有关研究成果。在此基础上,我们提出了汉语小句关系的标注体系,针对汉语话题优先的语言特点,明确提出了“事件附属关系”和“事件逻辑关系”的分类规范。依据这个初步的标注规范,对人民日报语料进行了人工标注,现阶段已经标注完成1个月的人民日报语料,并抽取其中1 000个句子进行了双盲标注检测。基于标注语料,统计分析了小句关系的不同分布,包括不同语义类型的分布和显性隐性关系的分布,指出了汉语句际关系自动分析将面临的重点和难点。
进一步的研究工作将沿三个方向来开展。其一,进一步完善小句关系标注规范,在更大的语料上、组织更多的人力来标注小句关系。其二,将小句关系拓展到句子之间、句群之间甚或段落之间,形成更为全面完善的汉语句际关系标注规范。其三,基于句际关系标注语料库,开展句际关系自动分析的研究,构建汉语篇章分析器,初步满足自动文摘、智能问答、情感计算等应用系统的实际需求。
[1] Mann W,Thompson S. Rhetorical structure theory: towards a functional theory of text organization [J], Text, 1998, 8(3): 243-281.
[2] 廖秋忠. 廖秋忠文集[M]. 北京: 北京语言学院出版社,1992.
[3] Louis A, Nenkova A. Automatic identification of general and specific sentences by leveraging discourse annotations[C]//Proceedings of EMNLP, 2011.
[4] Lin Z, Ng H, Kan M. Automatically evaluating text coherence using discourse relations[C]//Proceedings of ACL, 2011.
[5] Girju R. Automatic detection of causal relations for question answering[C]//Proceedings of ACL workshop on multilingual summarization and question answering, 2003.
[6] 张志昌,张宇,刘挺,李生. 基于话题和修辞识别的阅读理解Why型问题回答[J]. 计算机研究与发展,2011, 48(2):216-223.
[7] Wang F, Wu Y. Exploiting discourse relations for sentiment analysis[C]//Proceedings of COLING, 2012.
[8] Guzman F, Joty S, Marquez L, Nakov P. Using Discourse Structure Improves Machine Translation Evaluation[C]//Proceedings of ACL, 2014.
[9] Carlson L, Marcu D, Okurowski M, Okurowski M. Building a discourse-tagged corpus in the framework of Rhetorical Structure Theory[C]//Proceedings of the 2nd SIGDIAL workshop on discourse and dialogue, 2001.
[10] Prasad R, Dinesh N, Lee A, et al. The Penn Discourse TreeBank 2.0[C]//Proceedings of LREC, 2008.
[11] 周强. 汉语句法树库标注体系[J]. 中文信息学报,2004,18(4):1-8.
[12] Xue N. Annotating discourse connectives in the Chinese Treebank[C]//Proceedings of the Workshop on Frontiers in Corpus Annotations, 2005.
[13] Zhou Y, Xue N. PDTB-style discourse annotation of Chinese text[C]//Proceedings of ACL, 2012.
[14] 邢福义,姚双云.汉语复句语料库的建设与利用[C]//载朱小健主编《中文信息处理的探索与实践》. 北京: 北京师范大学出版社, 2006.
[15] 乐明. 汉语篇章修辞结构的标注研究[J].中文信息学报, 2008,22(4): 19-23,42.
[16] Huang H, Chen H. Chinese discourse relation recognition[C]//Proceedings of IJCNLP, 2011.
[17] 张牧宇,秦兵,刘挺.汉语篇章级句间语义关系体系及标注[C]//Proceedings of CCIR 2012.
[18] 徐赳赳. 现代汉语篇章语言学[M]. 北京: 商务印书馆, 2010.
[19] 吕淑湘,朱德熙. 语法修辞讲话(第2版)[M]. 北京: 中国青年出版社, 1979.
[20] 胡裕树(主编). 现代汉语(重订本)[M]. 上海: 上海教育出版社, 1995.
[21] 邢福义. 汉语复句研究[M]. 北京: 商务印书馆, 2001.
[22] 吴为章,田小琳. 汉语句群[M]. 北京: 商务印书馆, 2000.
[23] Li N, Thompson A. Subject and topic: a new typology of languages[M]. Li N. (eds). Subject and Topic. New York: Academic Press.1976.
[24] 曹逢甫. 主题在汉语中的功能研究[M]. 北京: 语文出版社.1995.
[25] Prasad R, Miltsakaki E Dinesh, et al. The Penn discourse treebank 2.0 annotation manual[C]//Proceedings of IRCS Technical Reports Series, 2008.
Intra-Sentence Relationship Annotation Scheme for Chinese Discourse Analysis
WU Yunfang, XU Yifeng, WANG Kairan
(Key Laboratory of Computational Linguistics, Ministry of Education, Peking University, Beijing 100871, China)
Automatic discourse analysis has aroused strong interests in the recent years. Compared to the bulks of work on English discourse analysis, much less work has been done in Chinese discourse parsing. A non-negligible reason is that there is no well-annotated Chinese discourse corpus publically available. Under the RST-framework, this paper proposes an intra-sentence relationship annotation scheme for Chinese discourse analysis. We consider both the topic and the logic aspect, discriminating the attachment relationship and logic relationship in Chinese intra-sentence relationship. The logic relationship consists of 6 types and 15 subtypes. Up to now, we have annotated 8,000 sentences in thePeopleDailyNews. We check 1,000 sentences in a double-blind manner for the inter-annotator agreement, which may give a hint for the difficulties in this task. Based on the annotated data, we give some statistics analysis and demonstrate some challenges for Chinese automatic discourse analysis.
discourse relation; Intra-Sentence Relationship; corpus annotation

吴云芳(1973—),博士,副教授,主要研究领域为篇章语义分析,智能问答系统。E⁃mail:wuyf@pku.edu.cn徐艺峰(1989—),硕士研究生,主要研究领域为是篇章语义学。E⁃mail:win1989@126.com王恺然(1988—),硕士研究生,主要研究领域为篇章语义学。E⁃mail:wangkairan@pku.edu.cn
1003-0077(2015)03-0071-11
2013-04-08 定稿日期: 2014-11-25
国家自然科学基金(61371129);国家重点基础研究发展计划(2014CB340504); 国家社科基金重大项目(12&ZD227);网络文化与数字传播北京市重点实验室开放课题(ICDD201402,ICDD201302)
TP391
A
猜你喜欢
成都理工大学学报·社会科学版(2022年1期)2022-05-26
通信技术(2021年12期)2022-01-25
韩国语教学与研究(2021年2期)2021-11-24
华北电力大学学报(社会科学版)(2021年2期)2021-07-21
文化创新比较研究(2020年13期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
西安航空学院学报(2014年4期)2014-07-13
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
