
现代汉语虚词用法知识库建设综述
2015-04-21 08:33张坤丽昝红英柴玉梅韩英杰
中文信息学报 2015年3期
张坤丽,昝红英,柴玉梅,韩英杰,赵 丹
(郑州大学 信息工程学院,河南 郑州 450001)
现代汉语虚词用法知识库建设综述
张坤丽,昝红英,柴玉梅,韩英杰,赵 丹
(郑州大学 信息工程学院,河南 郑州 450001)
现代汉语虚词用法繁杂多样,虚词用法的研究对汉语语义理解及语法分析起着非常重要地作用。该文在分析虚词及词汇知识库研究现状的基础上,对三位一体的现代汉语虚词用法知识库中虚词用法词典、虚词用法规则库和虚词用法标注语料库的建设过程进行了详细描述,对虚词知识库现存的问题进行了分析。利用已经构建的现代汉语虚词知识库,对虚词用法自动识别进行了研究,并对现代汉语虚词知识库的应用进行了初步的探讨。
虚词用法知识库;虚词用法词典;虚词用法规则库;虚词用法标注语料库
1 前言
在汉语中,意义较为空灵、在句子中承担语法特征和相关实词之间语义关系描述的词语称之为虚词。虚词的语义及用法复杂多样,且对所在句子的语义影响很大[1]。众多的语言学家对汉语虚词的语义及用法进行研究,研究成果众多。首先是一些关于虚词的词典,如吕叔湘先生的《现代汉语八百词》,北京大学中文系1955、1957级语言班的《现代汉语虚词例释》,武克忠的《现代汉语常用虚词词典》,侯学超的《现代汉语虚词词典》,张斌的《现代汉语虚词词典》等,尽管各书侧重点不同,收录词条也不尽相同,但都结合体例,对虚词进行了较为详尽的分类辨析。其次是出现了一些虚词研究的专著和大量的虚词研究论文,如陆俭明、马真的《现代汉语虚词散论》充分体现出虚词研究在语法研究中的作用,使汉语的虚词研究达到了新的高度。张斌、范开泰主编的现代汉语虚词研究丛书以及其他学者的研究成果,都对各类虚词分别做了细致的描述,并加以解释,总结规律。
虽然语言学家对虚词的研究硕果累累,但语言处理系统最终需要强大的知识库支持[2],而词汇知识库在自然语言处理系统中,具有非常重要的作用。现代汉语词汇知识库的代表主要有: 以汉语和英语所表示的概念为描述对象,以描述概念与概念之间以及概念所具有的属性之间的关系为基本内容的知网(HowNet)[2];以真实语料为支撑,包含框架及框架关系的汉语框架语义网(Chinese FrameNet,CFN)[3];由哈尔滨工业大学信息检索研究室在《同义词词林》[4]的基础上剔除生僻词所完成的义类词典《同义词词林(扩展版)》;按照语法功能与意义相结合的准则进行词语收录,依照语法功能分布的原则对所收词语进行归类,并分类描述每个词语的相关语法属性的《现代汉语语法信息词典》(GKB)[5]。在以上汉语词汇知识库中,HowNet及《同义词词林(扩展版)》对虚词语义表达不够详细,CFN并未涉及虚词,GKB在汉语虚词信息收录方面则较为薄弱[6],对虚词仅以语义概念进行区分,未进行用法的细化。
综上,以语言学家对虚词研究的成果为基础,构建完备的现代汉语虚词词汇知识库是自然语言处理的迫切需求。针对自然语言处理技术及应用研究的实际需要,现代汉语虚词用法知识库(the Chinese Function word usage Knowledge Base,CFKB)将汉语虚词界定为副词、介词、连词、助词、语气词、方位词,在俞士汶等[6]“三位一体”构建思想的指导下,从现代汉语虚词的用法入手,构建了包括现代汉语虚词用法词典、现代汉语虚词用法规则库以及现代汉语虚词用法标注语料库的知识库,其中语料库中包含了《人民日报》七个月语料的虚词用法的标注。以下将对CFKB的总体框架、具体内容、建设过程进行详细的描述,对现存的问题及基于CFKB虚词用法自动识别的研究结果进行分析。
2 现代汉语虚词用法知识库建设
2.1 CFKB构建过程
CFKB包含现代汉语虚词用法词典、现代汉语虚词用法规则库、现代汉语虚词用法语料库三部分,包括副词、介词、连词、助词、语气词、方位词等六类虚词。CFKB构建过程如图1所示。

图1 CFKB构建过程
在CFKB的构建过程中,先构建词典及规则库;再利用规则自动标注语料;之后对语料进行人工校对。在校对过程中,对词典和规则进行调整。具体如下:
(1) 根据各类词性的语法特征,设计虚词用法词典的框架;
(2) 依据《现代汉语语法信息词典》、人民日报分词与词性标注语料以及经典文献(《现代汉语八百词》、《现代汉语虚词词典》、《现代汉语词典》)确定现代汉语虚词用法词典的词条,填充用法描述、释义、例句等属性内容;
(3) 设计用法规则描述规范,依据词典中用法的描述,人工构建初步的用法规则库;
(4) 设计基于规则的虚词用法自动识别算法,对《人民日报》已分词和词性标注的1998年1月的语料中的虚词进行了用法自动标注;
(5) 对自动标注后的《人民日报》采用人工双盲校对,标注用法不一致的加入第三方讨论确定最终的标注结果,并形成校对规范(或完善校对规范);
(6) 根据人工校对过程中遇到的问题及已完成的校对语料,完成以下工作。
a. 对用法词典,根据实际语料的用法调整用法、用法描述、补充例句等内容;
b. 对规则库,根据自动标注结果和人工校对结果统计自动标注的准确率,根据准确率调整规则内容及规则顺序;
(7) 利用新的规则自动标注《人民日报》2000年1月的语料,重复(5)至(7)完成《人民日报》语料2000年1至6月中的虚词用法标注。
按照以上过程,从2005至2013年,历时八年,目前CFKB中虚词用法词典、虚词用法规则库及包含七个月《人民日报》语料虚词标注的语料库已经完成,且已逐步完善,以下对这三部分逐一进行介绍。
2.2 现代汉语虚词用法词典
现代汉语虚词用法词典的构建是在GKB[5]以及刘云[7]和彭爽[8]的工作基础上进行的,GKB[5]从语法功能角度对虚词进行了描述,刘云[7]为副词、连词、介词和语气词等设计了相应的描述属性,对常用虚词进行了归类和总结;彭爽[8]研究了现代汉语介词的语法特点和语法功能,构建了初步的介词用法词典。
现代汉语虚词用法词典的建设经过框架设计、内容填充和反馈修改三个步骤。
(1) 框架设计
现代汉语虚词用法词典的框架包含四大类属性: 标识类、句法功能描述类、范畴类和用法描述类。其中标识类对六大类词性都是相同的,是对虚词的每个用法赋以唯一的编码(ID),作为联系规则库和语料库的唯一标识,其编码形式为“POS_全拼[_tn] [_m] [x] [y]”,其中“POS”为词性,“全拼”为拼音全称,“tn”标明同音词序号,用于对同词类的同音不同形词语的编码区分,“m”为义项编号(1,2,3,…),“x”为用法编号(a,b,c,…),“y”是对用法的进一步细化编号(a,b,c,…),“[ ]”表示根据需要可选。对标识类更详细的描述见文献[9]。用法描述类、句法功能描述类和范畴类则因词性而异。如方位词用法关注前后搭配为“时间”、“处所”、“名”,则将其作为用法词典中的用法描述类属性;对于某些副词而言,位置改变不影响语义的表达,如“他们几个本来不是一个单位的”和“本来他们几个不是一个单位的”两句中的副词“本来”放在主语之后,或放在主语之前,语义完全相同,因此将“位移”作为副词的用法描述属性。对范畴类属性,连词关注“关系”(转折、并列、递进……),副词关注“副词小类”(描摹性、评注性、程度……),介词则关注其宾语为“体宾、谓宾”等。用法词典各类词性框架设计详见文献[9-11]。虚词用法词典作为一个整体,各类词性的框架设计既有统一的属性,也有因其自身特征而不同的属性,使虚词用法知识库在自然语言处理中能够最大化的发挥作用。
(2) 内容填充
在确定了词典中六大类词性的框架之后,基于刘云和彭爽的工作,主要参考了《现代汉语语法信息词典》[5]、吕叔湘《现代汉语八百词》、《现代汉语词典》(第5版)以及张斌《现代汉语虚词词典》等语言资源,并基于《人民日报》1998年1月以及2000年1至6月分词和词性标注语料中的虚词,结合汉语虚词的实际用法规律,按用法属性进行分解,将每一个用法作为词典中的一条记录。针对不同学者的不同见解,词典内容依据面向自然语言处理的需求,分解、辨析各用法描述,抽取可操作的用法特征进行填充。为跟踪用法词典信息来源,分别在相应内容之后用“

图2 虚词用法词典样例
(3) 反馈修改
在语料校对的过程中,通过反馈和辨析,也对虚词用法词典进行了调整。首先是对词典中一些词语的增删,如“又”在语料中与“既”搭配使用时,都标注为连词,如下句:
这样/rz 既/c 方便/v 广大/b 市民/n 参加/v 活动/vn ,/wd 又/c 能/vu 更/d 好/a 地/ui 维持/v 秩序/n ,/wd 确保/v 安全/an 。/wj (20000101-10-014-006/m)
根据语料中词性标记,在2009年的版本[10]中收录为连词,但经过辨析,此例中的“又”语义为“表示几个动作、状态、情况累积在一起”,仍属于副词范畴,因此从连词词典中删除“又”。又如原副词词典[10]中收录了“沿途”,而未收录“沿街”,通过考察语料,“沿街”作为副词在语料中出现,且其用法和性质与“沿途”类似,因此在副词词典增加了此词条。
其次是对已有的用法进行增删,如副词“也”表示关联时,除了表示递进、选择、转折、假设、让步、条件、因果等关系外,在语料中还发现了单纯的承接关系,如“也就是在那以后不久,我们从南宫进入国统区,向黄河前进”,因此在词典中增加了一个新的用法,并通过抽取语料中可操作的用法特征,总结为“也+就是在…,也+正是…,也+正因为…,也+可以说…。
虚词用法词典的建设是一个不断完善和改进的过程, 2007年版本[9]共计虚词1 914个,用法3 538条;2009年版本[10]共计虚词1 922个,用法3 622条;目前的版本(2013年)中共计虚词2 401个,用法4 337条。作为对比,虚词用法词典2009年版本[10]各类虚词的统计结果以及目前版本的详细用法统计结果在表1中列出。从表1中可看出除助词外,每类词的词语数及用法数都有较大的调整。
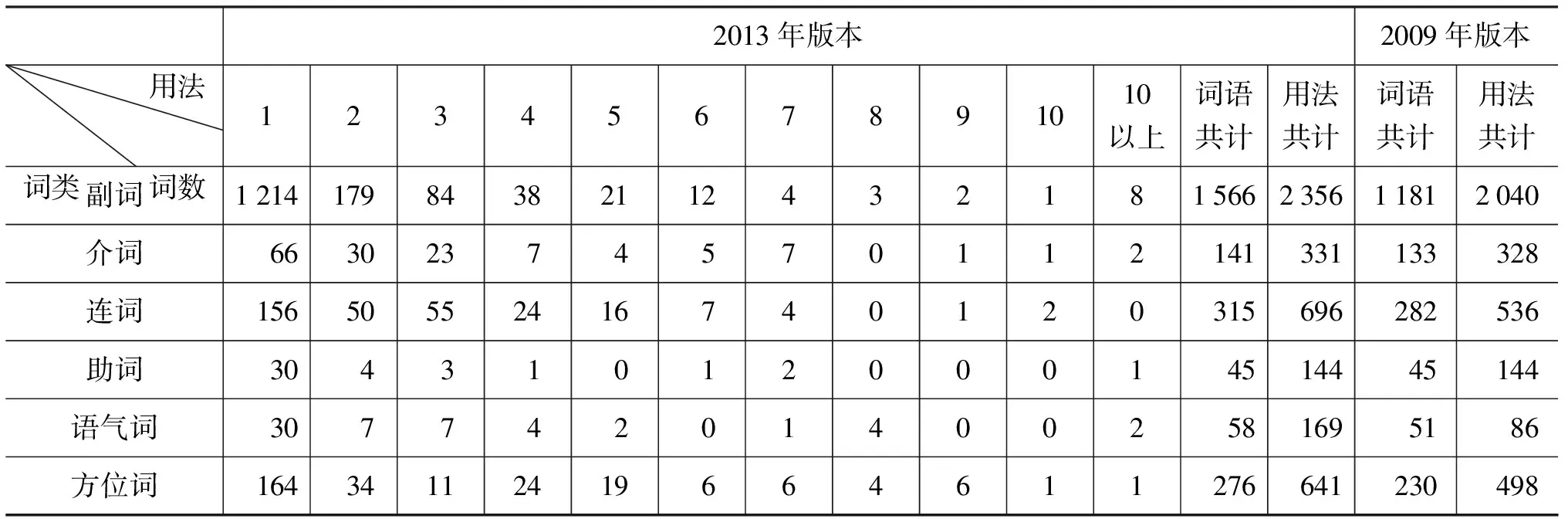
表1 现代汉语虚词用法词典中虚词用法分布
目前虚词用法词典已初具规模,但其中对于常用虚词(在语料中出现频次较高),语言学家对其研究较多,其语义及用法划分颗粒度较小,而对于不太常用的虚词或用法较为简单的虚词,其语义及用法划分颗粒度较大。如对于图2所示副词“都”的第二个语义“甚至”,就分别给出了四种在这个语义下的特殊框架,d_dou1_2a作为单独的用法,用法描述为“与‘连’字同用”,如例句“连书包里的东西都淋湿了”;而副词“足以”仅有一个语义(用法)描述为“修饰动词、形容词或动词短语”。通过用法描述的比较,发现二者在用法分割粒度上有较大的差异,是否有必要统一划分标准,也是下一步虚词用法词典的完善中需要考虑的问题。
2.3 现代汉语虚词用法规则库
在初步完成现代汉语虚词用法词典的基础上,规则库的建设也分为三步,即确定规则描述形式及规范、规则构建及反馈修改。
(1) 确定规则描述形式及规范
根据虚词用法特征的不同表现,抽取可操作的判断条件特征,包括句首(F)、左搭配(M)、左紧邻(L)、右紧邻(R)、右搭配(N)以及句末(E),以有序的BNF形式构建了现代汉语虚词用法规则库。识别规则的一般描述形式为:
@
其中,“@”为规则起始标志符;“^”为各特征定义连接符,各个特征之间默认为合取关系;“ID”为所识别的用法的编码ID;“→”表示定义为;“[ ]”表示可选内容,即一个用法可用六个特征的一个或多个进行描述;“<词>”表示该特征位置上出现的词语;“a、v、n”等表示该特征位置上出现的词性。
除了一般描述形式中的六大特征之外,还引入了框架及语义类描述,有以下三种形式:
a.同词或同词性的语境,用“A”和“B”表示,如
$不
@
@
b. 前后词有包含关系的,用“T”和“S”表示,以“%”作为标记,如:
$不
@
c.引入语义类,语义类保存在文件中,规则中引用语义类文件,以一对单引号作为标记,如:
$十分
@
上例对“十分”的规则描述中,将 “爱、愁、担心、惦记、发愁、害怕、恨、后悔、怀念、怀疑、嫉妒、……”心理动词语义类写入文件“xinli_v.txt"中,在使用规则识别时调用。
(2) 规则构建
虚词用法规则是依据已建立的虚词词典中的用法描述,以较高自动识别准确率为出发点,人工进行构建的。对比较复杂的用法,一个用法可以用多条规则来描述。如图2副词“都”的2b用法描述为“‘都’前后用同一个动词(前一肯定,后一否定)。A~A(不|没|没有|未|
$都
@
@
@
@
@
@
@
@
@
@
@
@
(3) 反馈修改
根据校对后的语料对规则库的修改主要采用两种方式。
a. 人工方式。对于规则内容,对比人工校对后语料和规则自动标注的语料,依据每个用法规则自动标注的准确率,分析标注错误或规则无法识别的句子,从中抽取可以形式化的规律,修改规则。对于规则排序,考虑到基于规则自动识别虚词用法的需要,同一虚词的多条用法规则并不是以用法编码的字母序排列,参考用法规则之间的互相覆盖程度以及虚词各用法在真实文本语料中的分布概率,规则描述较为清晰完备、自动识别准确率较高的规则优先级别较高,排在前面。
b. 自动方式。主要针对规则无法识别的用法(自动标注为
通过多次修改和调整,目前已完成的规则库包含副词2 456条规则,介词385条规则,连词747条规则,助词165条规则,语气词182条规则,方位词761条规则。
尽管在确定规则描述形式时尽可能的将所有可以形式化的全部描述出来,由于规则自身仅能处理可形式化的用法描述,目前的规则库仍然有一定的缺憾。如用法描述中出现的“修饰动词短语”、“修饰小句”等,“动词短语”中在动词之前可以有若干修饰成分,很难形式化,而“小句”也没有统一的框架,对于这一类问题,规则是无法准确描述的,因此在以后的建设中采用其他的形式对其进行补充。
2.4 现代汉语虚词用法语料库
虚词用法语料库是对约有876万余词的分词与词性基本标注语料库(即1998年1月和2000年1至6月的《人民日报》语料)采用基于规则的虚词自动标注的基础上,分别由来自语言学和计算机专业的人员进行背靠背人工标注,根据虚词用法词典用法描述,对语料中出现的虚词用法标注进行确认和修改,再对双方不一致的用法标注加入第三方讨论确定结果。为了保证语料库中用法标注的一致性,根据标注的过程及讨论的结果确定某一虚词用法的标注准则,即用法分割原则,确保标注均按照这个原则进行。
标注的结果是在相应的虚词后标上用法编码,已完成虚词用法标注的《人民日报》语料标注样例如下:
20000401-01-001-006/m 中国/ns 和/c
在进行虚词用法标注的过程当中,也对原有的分词和词性标注进行了辨析,若发现原语料中的分词或词性标注不合适的地方,用“@”在语料中标出,然后分情况处理。除了校对过程中人工发现词性错误之外,韩英杰等[13]对规则标注时自动标注为
在《人民日报》1998年1月及2000年1至6月这七个月语料中,由于助词“的”出现频次较高,共计约42万次,完成部分用法标注即有足够大规模的训练语料,因此只完成了五个月语料中约30万次助词“的”的用法标注。除了2000年2月及3月语料中助词“的”未标注用法外,目前已完成了《人民日报》七个月语料中其他全部的副词、介词、连词、语气词、助词、方位词的用法标注,共计标注约142万词次,形成了现代汉语虚词用法标注语料库。
虽然语料是以双盲校对为基础,并且制定了用法分割规范,但语料中虚词用法的语境千差万别,不同人的理解也会有差异,所完成的大规模的虚词用法标注语料中,很难保证所有的用法的标注都是完全一致的,因此对于语料库中虚词用法标注一致性的检查也是下一步需要解决的问题。
3 虚词用法自动识别研究
虚词用法自动识别是虚词用法知识库构建及应用的非常重要的一部分,对它的研究主要采用三种方式: 基于规则的虚词用法自动识别,基于统计的虚词用法自动识别,规则与统计相结合的虚词用法自动识别。
3.1 基于规则的虚词用法自动识别
基于规则的虚词用法标注首先读取语料,将语料文本内容切分成一个个句子(由于有些连词是起到连接句子的作用,所以会以段落为单元进行处理,详见周丽娟等[14]),按待标注虚词查找规则,调用相应的六个类型(规则中的F、M、L、R、N、F)的匹配器及特殊框架匹配器解析用法规则,进行标注。基于规则的虚词用法自动识别的具体设计及实现详见文献[15]及文献[16]。
规则库在标注语料的过程中进行了大量的调整和改进,相应的形式化规则描述效果也有了较大的改善,从而提高了虚词用法规则描述的准确性及基于规则的虚词用法自动识别的准确率,周丽娟等[14]、周溢辉等[17]、赵丹等[18]及韩英杰等[19]分别对基于规则的连词、语气词、方位词和助词的用法自动识别过程进行了研究。目前,利用虚词用法规则库,对《人民日报》1998年1月及2000年1至6月分词与词性标注语料中各类虚词用法自动识别的准确率分别为: 副词84.36%,介词71.71%,连词 83.68%,助词40.71%,语气词78.85%,方位词88.14%。其中助词准确率较低的原因是由于助词中“的”用法复杂(共39种),规则描述困难,且在语料中出现频次较高,它的识别准确率较低,从而影响了助词整体的准确率。
规则识别准确率的高低取决于规则描述的是否精准,由于规则描述中遇到的问题,因此也限制了基于规则的虚词用法自动识别的应用。
3.2 基于统计的虚词用法自动识别
针对规则识别的不足,利用经过人工校对的虚词用法语料库作为训练语料,对一些多用法的常用虚词,采用支持向量机(Support Vector Machine, SVM)、最大熵(Maximum Entropy, ME)以及条件随机场(Conditional Random Fields, CRF)等统计模型,对虚词用法进行基于统计的自动识别研究。
由于每一个虚词的用法都有较大差异,因此采用统计的方法对虚词用法自动识别,每一个虚词要训练一个模型,昝红英等在文献[20]、[21]中分别对副词“就”和“才”的自动识别进行了研究,采用统计方法的准确率分别高出规则方法约42%和29%。文献[22]中采用统计方法对介词“把”的用法自动识别进行了研究。昝红英等[23]和张坤丽等[24-25]分别对常用连词、副词和介词的用法自动识别进行了研究,采用统计方法进行自动识别,相较于规则自动识别结果,宏平均准确率分别高出规则约28%、27%、30%。
3.3 规则与统计相结合的虚词用法自动识别
虽然从总体上来讲基于统计的用法自动识别的效果优于基于规则的,但是通过对虚词每一个用法识别结果分析表明,在某些用法上基于规则的效果优于基于统计的方法,因此考虑采用规则和统计相结合的方法对虚词用法进行自动识别。
张静杰等[26]通过考察标注语料中副词“都”的分布率,将每个用法单独使用规则及单独使用统计方法的准确率作为参考,采用规则与统计相结合的方法,进行用法自动识别研究,准确率达到98.54%,分别高出规则方法和统计方法16.54%和8.92%。周丽娟等[27]对三个月《人民日报》语料中的多用法连词采用不同的规则与统计相结合的方式进行用法自动识别研究,准确率相比于规则和统计方法均有一定的提高。昝红英等[28]采用规则与统计相结合的方法对常用介词的用法进行了自动识别研究,宏平均准确率为82.02%,分别高出规则方法和统计方法14.64%和5.22%。
4 汉语虚词用法知识库应用初探及前景
现代汉语虚词知识库的研究成果可直接应用于自然语言理解中,已经初步探讨虚词用法在短语结构分析、句法分析、信息抽取及语法偏误自动识别中的作用。在短语结构分析方面,昝红英等[29]将连词用法识别的结果引入到连词短语结构分析中,以2000年1月《人民日报》为实验语料,分别采用规则和统计的方法对连词结构进行识别,相较于不引入连词用法特征,采用统计方法识别准确率最高能提高4%左右;在句法分析方面,昝红英等[10]初步探索了虚词用法标注对依存句法分析结果的影响,张静杰[30]、庞熠雅[31]将介词和连词用法识别的结果分别引入到哈工大LTP平台依存句法分析和Stanford Parser短语结构句法分析的后处理中,提高了句法分析的准确性;在信息抽取方面,昝红英等[32]将介词用法识别结果引入到会议事件元素的抽取中,相比于已有方法的最好结果,准确率能提高9%左右;在语法偏误识别方面,韩英杰等[33]将连词用法引入到语法偏误分析中,能够自动识别连词的误加、误代和遗漏等部分语法偏误。
以上仅是对现代汉语虚词知识库应用的一些初步的探讨,目前,基于规则和基于统计的汉语虚词用法自动识别算法能够对文本中出现的虚词进行用法的自动标注,结合汉语虚词用法词典,除了在以上领域外,还可以在机器翻译、问答系统等自然语言处理领域取得一定的应用效果,另外在对外汉语教学中针对汉语虚词的语义理解、同义及近义虚词的辨析、介词结构及连词结构的固定搭配以及虚词偏误的自动分析等也可以起到一定的辅助学习作用。
5 结语
“三位一体”的现代汉语虚词知识库的建设汲取了语言学家对虚词研究的精华,借鉴了其他汉语词汇知识库建设的经验,结合了真实语料,目前已经完成了副词、介词、连词、助词、语气词、方位词这六大类词性的现代汉语虚词用法词典和虚词用法规则库,完成了包含七个月《人民日报》约142万词次虚词用法标注的语料库,并依据规则库和语料库对虚词用法的自动识别进行了研究,对虚词知识库的应用进行了初步的探讨。
虽然现代汉语虚词知识库已经过多年的建设,已逐步趋于完善,但解决词典、规则及语料库中存在的问题是构建面向自然语言处理的精准虚词用法知识库需要努力的方向。除此之外,基于现代汉语虚词用法知识库的应用探讨,也是进一步工作的方向。
[1] 吕叔湘,朱德熙.语法修辞讲话[M].沈阳: 辽宁教育出版社, 2002.
[2] 董振东.知网[DB/OL].http://www.keenage.com.
[3] You L P,Liu K Y.Building Chinese FrameNet Database[C]//Proceedings of 2005 IEEE NLPKE,2005: 301-306.
[4] 梅家驹,竺一鸣,高蕴琦,等.同义词词林[M].上海: 上海辞书出版社,1983.
[5] 俞士汶,朱学锋,王惠,等.现代汉语语法信息词典详解[M].北京: 清华大学出版社,1998.
[6] 俞士汶,朱学锋,刘云.现代汉语广义虚词知识库的建设[J].汉语语言与计算学报,2003,13(1):89-98.
[7] 刘云.汉语虚词知识库的建设[R].博士后出站报告.北京:北京大学,2004.
[8] 彭爽.现代汉语介词知识库的建设与相关研究[R].博士后出站报告.北京:北京大学,2006.
[9] 昝红英,张坤丽,柴玉梅,等.现代汉语虚词知识库的研究[J].中文信息学报,2007,21(5):107-111.
[10] 昝红英,朱学锋.面向自然语言处理的汉语虚词研究与广义虚词知识库构建[J].当代语言学,2009,11(2):124-135.
[11] Zan H Y, Zhang K L, Zhu X F, et al. Research on the Chinese Function Word Usage Knowledge Base[J]. International Journal on Asian Language Processing, 2011, 21(4):185-198.
[12] 吴云鹏,昝红英.基于错误驱动的现代汉语方位词用法规则的自动更新[C].第五届全国青年计算语言学研讨会论文集,武汉: 武汉大学,2010: 43-49.
[13] 韩英杰,张坤丽,昝红英,等.基于助词用法的汉语词性、分词错误自动发现[J].计算机应用研究,2011,28(4):1318-1321.
[14] 周丽娟,张坤丽,袁应成,等.基于规则的现代汉语连词用法自动识别研究[C].第五届全国青年计算语言学研讨会论文集,武汉: 武汉大学,2010: 96-102.
[15] 刘锐,昝红英,张坤丽.现代汉语副词用法的自动识别研究[J].计算机科学,2008,35(8A):172-174.
[16] 袁应成,昝红英,张坤丽,等.基于规则的虚词用法自动标注算法设计与系统实现[C].第十一届汉语词汇语义学研讨会论文集,苏州:苏州大学,2010:163-169.
[17] 周溢辉,昝红英,柴玉梅,等.基于主观认知的汉语助词和语气词区分问题研究[C].第十一届汉语词汇语义学研讨会论文集,苏州:苏州大学,2010:382-388.
[18] 赵丹,张坤丽,昝红英,等.面向机器识别的现代汉语方位词用法形式化描述研究[C].第十一届汉语词汇语义学研讨会论文集,苏州:苏州大学,2010:298-304.
[19] 韩英杰,昝红英,张坤丽,等.基于规则的现代汉语常用助词用法自动识别[J].计算机应用,2011,31 (12):3271-3274.
[20] 昝红英,张军珲,朱学锋,等.副词“就”的用法及其自动识别研究[J].中文信息学报,2010,24(5):10-16.
[21] Zan H Y, Zhang J H. Studies on Automatic Recognition of Chinese Adverb CAI’s usages Based on Statistics[C]//Proceedings of the 5th International Conference on Natural Language Processing and Knowledge Engineering(NLPKE2009).2009:393-397.
[22] Mu L L,Pang Y Y,Zan H Y.Studies on Automatic Recognition of Preposition BA’s Usages Based on Statistics[C]//Proceedings of IEEE CCIS2012,2012:1875-1879.
[23] Zan H Y, Zhou L J, Zhang K L. Studies on the Automatic Recognition of Modern Chinese Conjunction Usages[C]//Proceedings of Lecture Notes in Computer Science(Advanced Intelligent Computing).2011:472-479.
[24] 张坤丽,赵丹,昝红英,等.常用现代汉语副词用法自动识别研究[J].中文信息学报,2012,26(6):65-71.
[25] Zhang K L, Zan H Y, Han Y J, et al. Studies on Automatic Recognition of Contemporary Chinese Common Preposition Usage[C]//Proceedings of CLSW2012.Wuhan,2012:219-229.
[26] 张静杰,昝红英.副词“都”用法自动识别研究[J].北京大学学报(自然科学版),2013,49(1):165-169.
[27] Zhou L J,Zan H Y.Studies on a Hybrid Way of Rules and Statistics for Chinese Conjunction Usages Recognition[C].第十四届汉语词汇语义学研讨会论文集.郑州:郑州大学,2013: 356-361.
[28] 昝红英,张腾飞,张坤丽. 规则与统计相结合的介词用法自动识别研究[J].计算机工程与设计,2013,34(6):2152-2157.
[29] 昝红英,周丽娟,张坤丽.基于用法的现代汉语连词结构短语识别研究[J].中文信息学报,2012,26(6):72-78.
[30] 张静杰.虚词用法自动识别及其在依存句法分析中的应用研究[D].郑州大学硕士学位论文,2013.
[31] 庞熠雅.介词、连词用法在短语结构句法分析中的应用研究[D].郑州大学硕士学位论文,2013.
[32] 昝红英,张腾飞,林爱英.基于介词用法的事件信息抽取研究[J].计算机工程与设计,2013,34(7):2570-2574.
[33] 韩英杰,昝红英,吴泳刚,等.连词用法在对外汉语教学语法偏误自动识别中的应用研究[C].第十四届汉语词汇语义学研讨会论文集,郑州:郑州大学,2013: 13-18.
Survey of the Chinese Function Word Usage Knowledge Base
ZHANG Kunli, ZAN Hongying, CHAI Yumei, HAN Yingjie, ZHAO Dan
(College of Information Engineering, Zhengzhou University, Zhengzhou, Henan 450001, China)
The contemporary Chinese function words with their distinct usages play complex syntax roles. The study on Chinese function words is of great significance in Chinese syntax analysis and semantic understanding. This paper firstly reviews the current research on Chinese function words and lexical knowledge base. Then it describes a triune construction on the knowledge base of modern Chinese function words i.e. the usage dictionary, the usage rule and the usage-annotated corpus. With the the finished knowledge base so far, the automatic usage recognition of the Chinese function words is investigated, with other potential applications discussed.
function word usage knowledge base; function word usage dictionary; function word usage rule base; function word usage corpus

张坤丽(1977—),博士研究生,讲师,主要研究领域为中文信息处理。E⁃mail:ieklzhang@zzu.edu.cn昝红英(1966—),博士,教授,主要研究领域为中文信息处理。E⁃mail:iehyzan@zzu.edu.cn柴玉梅(1964—),硕士,教授,主要研究领域为机器学习,自然语言处理。E⁃mail:iehyzan@zzu.edu.cn
1003-0077(2015)03-0001-08
2013-04-08 定稿日期: 2013-09-10
国家自然科学基金(60970083,61272221);模式识别国家重点实验室开放课题基金;河南省教育厅科学技术研究重点项目(12B520055,13B520381);国家高技术研究发展863计划(2012AA011101);河南省科技厅科技攻关计划项目(132102210407)
TP391
A
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
北京大学学报(自然科学版)(2022年1期)2022-02-21
空间科学学报(2020年3期)2020-07-24
中国交通信息化(2019年7期)2019-10-08
水上消防(2019年3期)2019-08-20
中文信息学报(2019年7期)2019-08-05
制造技术与机床(2019年6期)2019-06-25
文贝:比较文学与比较文化(2016年1期)2016-11-14
海军航空大学学报(2015年1期)2015-11-11
环球人文地理(2014年14期)2014-08-15
