
基于文本纹理特征的中文情感倾向性分类
2015-04-21 08:33许歆艺刘功申
中文信息学报 2015年3期
许歆艺,刘功申
(上海交通大学 信息安全工程学院, 上海 200240)
基于文本纹理特征的中文情感倾向性分类
许歆艺,刘功申
(上海交通大学 信息安全工程学院, 上海 200240)
随着互联网的发展,社交网络、电子商务等已经成为人们关注的焦点,对社交网络的文本进行情感倾向性分析和挖掘变得越来越重要。该文针对网络上的中文文本,提出一种基于文本纹理特征的情感倾向性分类方法。通过测试多种文本纹理特征对文本情感倾向性的影响,成功将文本纹理特征融入情感分类中。通过计算各类特征与文本的情感倾向性的相关度,对特征进行降维。相对于基于词频的情感倾向性分类方法,查准率平均提高了10%左右。
中文文本分类;情感倾向性;文本纹理;SVM
1 引言
近年来,飞速发展的互联网已经逐步成为了人们生活的一部分,网络上的信息随之急剧增长,互联网已经成为人们发表观点和评论的重要载体之一。网络上的文章、评论直接地反映了网民的态度和见解,对大量文本的分析可以相当真实地反映民众对于某一事物的态度,因此对网络上的文本进行情感倾向性分析和挖掘正变得越来越重要。
在同一主题下,对这些网络评论、文学作品进行挖掘和分析,识别出其中的情感倾向,对于电子商务、舆情监管等领域有着重要的意义和实用价值。文本倾向性分类正逐步成为自然语言研究领域的一个热点方向。
上世纪90年代起,国外就开始了对词汇倾向性的分析研究,Turney提出了一种通过一组基准词计算词语的情感倾向性的方法,达到了95%的准确率[1];Kim等人同样将工作重点放在情感词汇的倾向性分析上,在一对基准词集的基础上使用WordNet计算未知词汇的情感倾向性[2]。随着研究工作和实际应用领域的发展,对整篇文档的观点抽取和倾向性判断成为研究工作的热点,情感词的上下文信息和语义搭配关系也逐渐被应用到语义倾向性计算当中。Wiebe等利用词语的搭配关系进行文档级别的观点挖掘,将具有搭配关系的词对作为特征,判断整篇文档的情感倾向性[3]。而在实际工作中,单词的倾向性与短语的倾向性往往相反,Wilson和Wiebe等人在后期研究中着力研究了短语级情感倾向性,并对中立情感这一实际大量存在的文本进行研究[4]。在有领域针对性的文本倾向性分类方面,Melville给出一个统一的框架,可以使用不同背景知识生成模型结合传统的分类工作,达到更精准的分类效果[5]。
在中文领域的研究中,文本情感倾向性主要的研究方法主要分为两种,如朱嫣岚等人利用HowNet提供的语义相似度和语义相关场计算功能对词语的褒贬倾向度按一定计算法则进行赋值,并根据该值判别该词语义倾向,并在后续工作中利用词语倾向性进行计算文本倾向性[6];另一种方法把机器学习的文本分类方法应用于中文文本倾向性分类领域。通过采用不同的停用词表、特征选取方法、特征加权方法进行比较实验,并应用不同的分类算法进行分类寻取较好的分类效果。例如,代六玲[7]等人针对不同的特征选取方法的有效性,特别是组合的特征抽取方法进行了研究,缩短了分类精度和训练时间。基于机器学习方法的情感自动分类方面,徐军[8]等人还提出了词语成对共现对表现不同情感的影响。目前已有多种标准算法可用于文本的学习与分类,例如,K最近邻算法、朴素贝叶斯算法、支持向量机算法[9]。徐琳宏等人进一步考虑到语义理解,在处理词语倾向性的基础上添加了否定规则和程度副词的识别,对褒贬的识别力度得到了进一步加强[10]。
本文的研究工作采用机器学习的方法,识别包括句式、修辞、词语间依赖关系等在内的文本纹理,以情感词汇、评价词汇、语气词以及部分文本纹理为基础特征,并根据所识别的文本纹理调整基础特征的权重,并且通过对所有特征与褒贬文本的相关性检测对特征进行降维, 达到了更高的准确度以及更快的分类速度。
2 文本倾向性分类
现存的传统的文本情感倾向性分类大多是基于情感词汇的倾向性来进行综合判断[11],而情感分类是要对文本的整体进行情感倾向的判断,当受到分词的影响时,原本的句子纹理都被丢失了。
例如,“虽然总体算不错,但是我并不喜欢。”经过分词后变成“虽然”、“总体”“算”“不错”“,”“但是”“我”“并”“不”“喜欢”“。”如果直接将词语作为特征项,“不错”“喜欢”这样的特征词会将本句判定为一句正面感情的句子,然而当考虑到否定词的修饰、转折句型,本句完全是一句负面感情的句子。
本文中提到的句子纹理主要包括词语间依赖关系、句型、句子修辞手法等,本节将详细介绍将句子纹理提取为文本特征的原理和步骤。而经过实验,单纯将句子纹理本身作为特征效果并不很好。于是本文提出了一种基于句子纹理的文本特征的权重计算方法: 对于出现了句子纹理信息的句子,将其中的出现的特征的特征权重在原始权重的基础上做相应的浮动,同时对不同的特征权重计算方法进行了对比分析。本文在实验中还考虑到特征维度较高,进行降维工作[12],实际使用维度从1 206维降至260,同时能保持分类正确率不变。

图1 基于句子纹理的文本情感倾向性分析总体流程图
2.1 支持向量机算法
本文实验中使用的分类算法为支持向量机算法,又称为SVM算法[13]和最大边缘算法(Maximum Margin)。SVM可以用于监督式或者半监督式学习[14],依靠对有限的样本的学习实现对非线性和高维度模式的识别。
SVM本质上是一个二分类的分类器,目的是为了在一个支持平面上寻找一个将两类类别区分开的超平面,因此经典的SVM分类器非常适合用于本文实验中区分正反两面情感的分类工作。在多分类,比如更细腻的情感倾向性划分中,可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。
2.2 基于文章纹理的特征构造方法
为了消除分词给文本情感倾向性判断带来的不良效果,本文在实验中尝试了各种帮助表现文意的元素,除了词语本身之外还有词语间的依赖关系、词语顺序、句型、文章修辞手法等等。本节将阐述的实验中用到的文本特征中包括了情感词汇、评价词汇、语气词、句型以及文本纹理,文本纹理中包括词语间依赖关系和文本修辞手法。本节将首先给出实验中
采用的特征项,随后说明特征权重的两种计算方法,然后给出将用以调整特征项权重的句子纹理,最后给出调整特征项权重的方案。
2.2.1 基础特征项
在本文实验中,以情感词汇、评价词汇、语气词这三类词汇作为特征向量的基础组成部分。
• 情感词汇
这里指表现对象正面或者负面的情绪的词语,如: 畅快、大喜过望、感兴趣、悲哀、委屈、哀怨等。
• 评价词汇
这里指描述对象正面或者负面特征的词语,例如,标致、别具一格、隽永、碍眼、鄙俗、表里不一等。
• 语气词
语气词是表示语气的虚词,常用在句尾或句中停顿处表示种种语气。常见的语气词有: 哈,吗,啦,唉。
这三类词汇都能表达文本中人物的情感、人和物的特征,进而表现了文本的作者的情感倾向性。其中,情感词汇也是传统的文本倾向性分析的研究中最常用也是最重要的特征项。因此本文在构造文章纹理特征时,也采用了这三种词汇作为待分析情感倾向性的文章的特征项。但是从实验数据中可以明显看到,仅仅简单采用这三种词汇作为特征所得到的分析结果并不十分理想。
2.2.2 文本纹理特征项
在本文实验中,除基础特征项之外,尝试了以下几种文本纹理作为特征的组成部分。
• 词语间的依赖关系
词语间存在着复杂的依赖关系,如果单纯地以词语作为特征项会丢失很大一部分文意。比如“总的来说,我并不赞同这一提议。”本身这个句子表达了作者对这件事的一种否定,但是经过单纯以词语作为特征项的特征化处理后,这些词汇综合的情感倾向性为褒义。显然,单纯以词语来判别句子中表达的作者态度是有欠缺的。
本文在实验中先通过Stanford Parser获取词语依赖关系组,如: dvpmod(防止, 有效),并提取依赖关系,如: dvpmod,并将词语依赖关系作为文本特征的一部分。
• 句型
文本中句子的句型是句子纹理的一个重要部分,本文选择了转折句作为研究的切入点。转折句表示出作者表达的意向的着重点主要在句子的后半句,因此识别转折句能够体现出作者的表达意图和表达重点。
汉语中,转折句型主要有以下结构:
可是、但是、尽管……还、虽然(虽是、说、尽管、固然)……但是(但、可是、然而、却) 、却、不过、然而、只是 、尽管……可是……、虽然……但是……、……却……
转折句的识别方法为:
1) 对句子进行分词;
2) 在句子中查找是否出现上面提到的结构,如出现则判定为转折句。
• 文章修辞手法
在中文中有一种特殊的句子纹理——修辞手法,是一种通过修饰、调整语句,运用特定的表达形式以提高语言表达作用的方法。由于修辞手法能表现作者相对一般句子更为强烈的情感,尤其是排比句。排比句利用三个或三个以上意义相关或相近,结构相同或相似和语气相同的词组或句子并排,达到了一种加强语势的效果。所以本文拟从文中提取排比的修辞手法,并将其作为特征项的一部分。
修辞手法的识别方法为:
1) 先通过Stanford Parser获取一个整句的句法结构;
2) 排比句中分句的句式结构往往相近甚至相同,因此通过句子结构提取和识别,把结构相似度高的分句判定为排比句。
2.2.3 特征的权重
特征的权重[15]基本可以分为两大类: 特征出现频率、特征出现与否。本文分别试验了这两种权重,并对以特征出现频率作为权重的方法进行了改进。下面主要介绍以特征出现频率为基础的权重设定方法。
由于经过实验,数据显示单纯添加词语的依赖关系、句式本身作为特征并且计算其频率作为特征权重的效果并不好,这是因为纹理特征本身与文章情感倾向性之间并无直接的联系,纹理特征的直接引入反而给文章情感倾向性带来了一定噪声。因此文本在实验中根据词语依赖关系、句式、修辞来改变核心词的特征权重,表2给出的修改值为经过实验(对比数据列于表4)所得到的最优值。
1. 基于词语依赖关系的特征权重
从Stanford Parser解析得到的词语依赖关系中选择了两种依赖关系作为文章纹理特征研究的切入点: 否定修饰(negative modifier)和副词修饰(adverbial modifier)。
否定修饰如: neg(愉快, 不),“愉快”一词出现一次,其特征权重原本应当采取“+1”操作,由于否定修饰的影响,取消该“+1”操作。
程度副词修饰的作用是改变情感词和评价词汇原本的表现强烈程度,知网情感分析用词语集中总结了219个程度副词,并划分为六个程度。

表1 知网程度副词表

续表
特征权重修改幅度的参考值为:

表2 程度副词对特征值修改幅度表
2. 基于转折句句型的特征权重
转折句中,作者通过转折来强调突出转折后的半句的句意,比一般的陈述句感情更为强烈。因此本文通过识别句子是否为转折句,来调整句子情感倾向性: 减少前半句中出现的情感词汇、评价词汇的特征权重,修改后每个词出现一次对特征值的增加幅度为+0.5(标准为+1);增加后半句中出现的情感词汇、评价词汇的特征权重,修改后每个词出现一次对特征值的增加幅度为+1.8(标准为+1)。
3. 基于排比修辞手法的特征权重
排比句是把三个或以上意义相关或相近、结构相同或相似、语气相同的词组或句子并排在一起组成的句子。排比比一般句子更能突出作者的感情思想,起到强调句意的作用。因此本文通过识别句子是否为排比句,来调整句子的情感倾向性: 增加该句中出现的情感词汇和评价词汇的特征权重,修改后每个词出现一次对特征值的增加幅度为+1.3(标准为+1)。
2.3 基于互信息量MI的特征降维
互信息(Mutual Information)是一种有用的信息度量,它是指两个事件集合之间的相关性。两个事件X和Y的互信息定义为:
I(X;Y) =H(X)-H(X|Y)=H(Y)-H(Y|X)
=H(X)+H(Y)-H(X,Y)
=H(X,Y)-H(X|Y)-H(Y|X)
通过计算特征的出现以及正面(负面)文本的出现这两个事件发生的相关性,可以得知每一个特征与文本倾向性的相关度。
在本文实验中预先定义的特征集合的维度为6 919维,其中包含了3 730个正面情感词汇和评价词汇,3 116个负面情感词汇和评价词汇,20个语气词,53个词语间的依赖关系,而在实验中实际出现的特征共为1 206维,经计算互信息量并对其进行排序可以筛选出与正面(负面)文本相关度最高的那一部分特征,随后为了消减噪声的影响,剔除了出现在该类别文本中出现次数极少的部分特征,共得到260个分别与正面文本负面文本相关度最高的特征。通过实验发现降维之后分类的正确率能够保持不变。
表3为实验所得部分相关度最高的情感词汇、评价词汇、语气词以及依赖关系
表3 部分MI值最高的情感词汇、评价词汇、语气词、依赖关系

类 别正面文本负面文本情感词汇与评价词汇便捷精彬彬有礼可笑大方强硬吉上上完备显著细致像话一流应有幽静正面优雅肮脏怡傲慢骄傲冰冷

续表
3 实验流程及结果
本文采用机器学习的方法对文本进行倾向性研究,实验中的训练数据和测试数据都采用谭松波收集整理的携程网酒店评论平衡语料库,正面文本和负面文本各2 000条,分别分为10份数据,轮流将其中九份即3 600条作为训练数据,另外一份数据即400条作为测试数据,根据10折交叉验证的平均值验证实验结果。分类算法采用的是SVM支持向量机算法。特征向量的构造方法采用的是以情感词汇、评价词汇、语气词、词语间依赖关系的作为特征项。特征权重的计算使用了两种方法,一是采用特征出现频率为基础、依靠词语间依赖关系和句式对特征出现频率做修正的方法,二是采用特征出现与否记录为0和1作为权重。实验还尝试对特征维度进行降维,使得实际使用的特征维度降到了原本的21.6%。
下面首先给出对同一批特征选取方案中的特征权重修正的实验结果,参见表4。

表4 根据文本纹理特征对特征权重修改方案实验结果

续表
从表4可以看出,在基础特征相同情况下,纹理特征特别是词语间依赖关系对于文意的表现存在很大的影响。通过实验,不断修改不同的修改参数更好地模拟文本纹理结构对文意的影响程度。
本文在接下来的实验中都将采用修改组合四,即本文2.2.3“特征的权重”一节中提到的修改方案。在包括决定特征权重修改参数、压缩维度的预备工作完成后,实验步骤如下:
1) 使用中科院汉语分词系统ICTCLAS对文本进行分词
2) 使用Stanford自然语言处理工具Stanford Parser获取词语间依赖关系
3) 提取文本中的情感词汇、评价词汇、语气词、词语间依赖关系作为特征项
4) 计算特征项出现频率作为特征权重
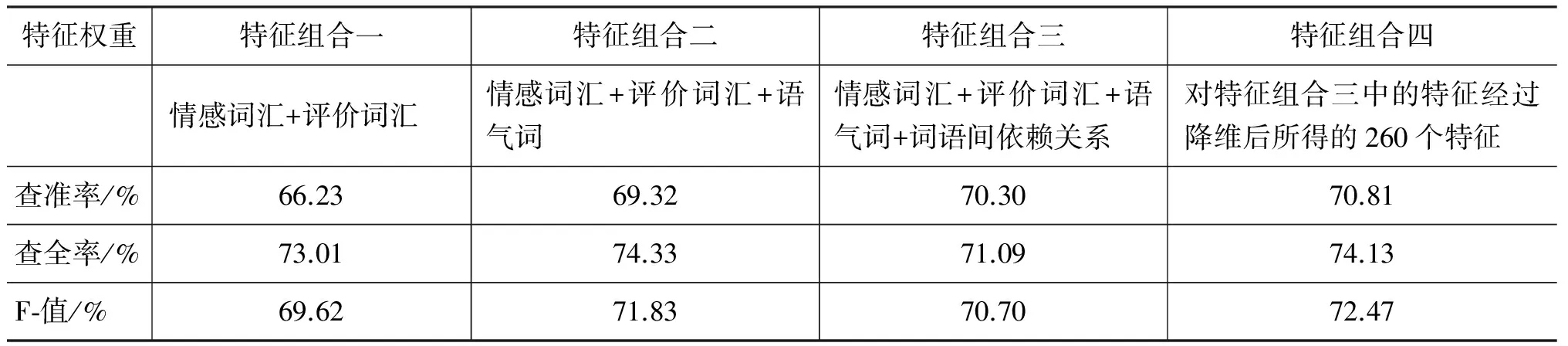
表5 以特征出现与否(0/1)作为特征权重进行分类

表6 以原始词频计算权重进行分类

表7 以原始词频计算权重,以词语间依赖关系、句式修正词频进行分类
5) 识别文本中转折句、排比句,对出现在该句中的特征频率进行修正
6) 对存在于副词修饰、否定修饰的词语间依赖关系中的词语的特征频率进行修正
7) 使用SVM分类器对训练集进行学习
8) 使用SVM分类器对测试集进行分类,并评估结果的正确率和召回率
由实验结果表5~7可见,在相同特征组合情况下,权重的计算方法的选择很大影响到结果的准确率。传统计算方法中以词频作为基础计算权重的方法可以得到比较不错的计算结果(表6),但是本文提出的由词语依赖关系与句式修正词频的计算方法明显提升了计算的结果(表7)。可见对于文本中词语间相互关系以及整体句子结构的挖掘进一步提升了文本倾向性判断的准确率。
通过比较表5~7的横向数据,可以看到语气词的引入提高了判断的准确性,就是说虽然语气词本身一般不含有任何正负面情感,但是我们在表达正面与负面情感时确实使用了不同的语气词。词语间依赖关系本身作为特征是一种冗余,因为几乎所有依赖关系本身不能够表达任何正负面情感,必须与具体的词语相结合才能表达出信息。
通过比较表5~7的最后两列数据,可以发现降维后,大大加快了特征抽取与计算过程的时间,在大规模的文本分类(比如数十万条的微博情感分类)中节省了大量时间。另外在计算特征与文本相关度的结果中,发现不同的语料库所对应的高相关度特征中情感词汇不尽相同,而语气词非常相似,因此后续工作中可以针对不同类别语料库中相同部分进行研究,找出更多共通的特征。而且由于排除了很多冗余的特征,所以在准确率的评判中与前三种组合中结果最好的第二组相比,降维后的结果有的略低一些,有的不变,有的略高一些,综合看来降维对准确率没有特别大的影响,但是能极大提高工作效率。
4 总结与展望
本文主要做了两部分工作,其一是从文本中词与词之间的结构、句子结构中进行挖掘文本纹理,修正了以词频为基础的特征权重计算方法,有效提高了分类的准确性。
因为这些文本纹理是一种用以帮助表达作者情感起伏强弱变化的结构,采取以情感词语和评价词语为基础,通过识别文本纹理修正特征权重可以更好拟合作者情感起伏。在将来的研究中,结合更多的词语间依赖关系以及句式的研究,可以通过进一步的寻找依赖关系、句式与情感倾向之间的关系来达到更高的准确率。
其二是对繁多的特征进行分析降维, 删减了与不同情感倾向性相关度较低的特征,保留了有明显相关度的特征。实验证明,降维的过程既能保证分类的准确性,也大大提高了分类速度。
因为考虑到网络文本的不标准、描述对象的不统一,在文本中有些词汇的出现有很大的随机性,而根据相关度降维这一工作恰恰删除了这些随机性和冗余度,但是在删除过程中虽然删除了一些不恰当的特征,但是也排除了一部分出现次数过少或者被错误信息干扰了的有用特征,所以查准率并没有能得到提升,但能与降维前保持一致。在将来工作中可以用更多算法来计算特征与不同文本间的相关度,更多更好保留有用特征。
[1] Peter D Turney, Michael L Littman. Measuring praise and criticism: Inference of semantic orientation from association[J].ACM Transactions on Information Systems (TOIS).2003, 21(4):315-346.
[2] Kim, S M, E Hovy. Automatic Detection of Opinion Bearing words and Sentences[A]. Companion Volume to the Proceedings of IJCNLP-05[C].Jeju Island, KR,2005: 61-66.
[3] Janyce wiebe, Theresa wilson, Matthew Bell. Identifying Collocations for Recognizing Opinions[A]. ACL-01 Workshop on Collocation: Computational Extraction, Analysis, and Exploitation[C]. Toulouse, France, 2001: 24-31.
[4] Theresa Wilson, Janyce Wiebe, Paul Hoffmann.Recognizing Contextual Polarity:An Exploration of Features for Phrase-Level Sentiment Analysis[J].Computational Linguistics,2009,35(3):399-433.
[5] Prem Melville, Wojciech Gryc, and Richard D. Lawrence.Sentiment analysis of blogs by combining lexical knowledge with text classification[A]. KDD ′09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining[C].New York, USA:ACM, 2009,1275-1284.
[6] 朱嫣岚,闵锦,周雅倩等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1): 14-20.
[7] 代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究[J].中文信息学报,2004,18(1): 26-32.
[8] 徐军,丁宇新,王晓龙,使用机器学习方法进行新闻的情感自动分类[J].中文信息学报,2004,18(1): 95-100.
[9] 刘依璐. 基于机器学习的中文文本分类方法研究 [D]. 西安:西安电子科技大学,2009.
[10] 徐琳宏, 林鸿飞, 杨志豪.基于语义理解的文本倾向性识别机制[J].中文信息学报,2007,21(6): 96-100.
[11] Bo Pang,Lillian Lee,Shivakumar Vaithyanathan.Thumbs up? Sentiment Classification using Machine Learning Techniques[A].EMNLP ′02 Proceedings of the ACL-02 conference on Empirical methods in natural language processing[C]Stroudsburg, PA, USA:Association for Computational Linguistics,2002: 79-86.
[12] 胡洁.高维数据特征降维研究综述[J].计算机应用研究.2008,25(9): 2601-2606.
[13] N. Cristianini, J. Shawe-Taylor.An introduction to support vector machines and other kernel-based learning methods[M].Cambridge:Cambridge University Press,2000.
[14] Nitin Namdeo Pise, Parag Kulkarn.Semi-Supervised Learning with SVM and K-Means Clustering Algorithm[A].Prasad, Bhanu.IICAI[C].IICAI,2010: 463-482.
[15] 张爱华,靖红芳,王斌等.文本分类中特征权重因子的作用研究[J].中文信息学报,2010,24(3): 97-104.
Texture Based Sentiment Orientation Identification for Chinese Texts
XU Xinyi, LIU Gongshen
(Shanghai Jiao Tong University, School of Information Security Engineering, Shanghai 200240, China)
With the development of Internet, the text orientation identification and text mining in social network is becoming a hot research issue. In this paper, a text sentiment orientation identification method using textures is proposed. The feature reduction is conducted by mutual information between the texture features and the text orientations. Compared to sentiment orientation classification method based on word frequency, the proposed method is proved about 10% increase for precision on average.
Chinese text categorization; sentiment orientation; textures of text; SVM

许歆艺(1989—),硕士,主要研究领域为自然语言处理,文本情感倾向性分析等。E⁃mail:katrinaxxy@gmail.com刘功申(1974—),博士,副教授,主要研究领域为信息内容安全,自然语言处理等。E⁃mail:lgshen@sjtu.edu.cn
1003-0077(2015)03-0106-07
2013-04-08 定稿日期: 2013-10-30
国家自然科学基金(61272441, 61171173)
TP391
A
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
心理学报(2022年5期)2022-05-16
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
当代陕西(2020年17期)2020-10-28
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
人大建设(2018年5期)2018-08-16
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
