
多特征融合的室内场景分类研究
2015-04-17 07:29钟映春连伟烯
广东工业大学学报 2015年1期
孙 伟,钟映春,谭 志,连伟烯
(广东工业大学自动化学院,广东广州510006)
场景分类也被称为场景感知、场景识别.2006年在MIT召开的首次场景理解研讨会(Scene Understanding Symposium)上明确提出,场景分类是图像离解的一个新的有前途的研究方向[1].尽管当前的分类方法都宣称可以解决任何类型的场景分类问题,但目前的实验表明这些方法通常只能够较好解决室外场景分类问题.相比之下,室内场景分类仍然是一个困难且具有挑战性的任务[2].文献[3]中的实验结果表明,采用同样的特征提取和分类识别方法在室内场景的分类精度远低于室外场景的分类精度.可见,如何提高室内场景的分类精度具有重要意义.在早期的研究中,通常提取图像的低级特征来实现场景分类,例如提取颜色,纹理和形状等特征[4].Szummer和Picard[5]使用这种特征来确定图像是室外还是室内的场景.但是,这种简单的全局特征还不足以描述整幅图像的特征,它在具有复杂环境背景的大数据集情况下,分类性能不佳.为了克服这个问题,Olivia和Torralba[6-7]采用并改进了全局特征Gist.这种特征描述在室外场景识别方面性能优异,例如对森林、山峰和郊区等场景图像的分类精度较高,但是在室内场景下,Gist特征的区分能力有限.David G[8]提出了一种基于尺度空间的、具有图像缩放、旋转和仿射变换不变性的图像局部特征描述算子SIFT.由于SIFT具有良好的区分能力,使得它一直是许多场景识别算法中最优先选择的局部特征描述算子[9].SIFT局部特征描述算子在室外场景分类上精度较高,但对室内场景的区分能力同样偏低.Quattoni和Torralba提出了一种室内场景的特征描述方法,即采用Gist+ROI的方法描述场景图像[3].该方法采用全局特征描述算子Gist与局部特征描述方法ROI(Region of Interest)相结合的方法,对室内场景分类表现出较好的结果,但感兴趣区域ROI的获取不仅需要花费大量的计算时间,而且在获取ROI区域前需要进行图像分割.这不利于图像理解.最新的研究表明,在人类对目标的识别过程中,在场景分类之后才进行图像分割,而后才是目标识别过程.P.Espinace等[10]提出了通过目标检测来对室内场景分类.这种方法基于语义的中间描述,这个方法需要对目标进行明确的检测.虽然这个方法具有比较好的分类效果,但此方法存在较多不足.其一是当图像中没有明确目标时就无法进行场景分类,其二是目标识别需要花费大量的计算时间,其三是目标识别通常是在场景分类之后进行,即场景分类的结果是为目标识别提供指导信息.
针对当前室内场景识别精度普遍较低的问题,本文提出一种融合全局特征和局部特征的多特征室内场景分类的方法.
1 室内场景分类方法的总体架构
由于室内场景各个类别之间具有较高的相似性,导致室内场景分类的识别精度较低.为了提高室内场景分类的精度,本文通过改进室内场景图像的特征提取来改善室内场景识别精度.对于室内场景图像,单一特征只能描述它的部分属性,从而缺少足够的区分信息,在室内场景类型比较相近的情况下通常不能取得较好的分类效果.此外,场景的全局特征描述和局部特征描述又各自有优点;局部特征描述对目标区域识别的部分特性具有良好的适应性,在场景切换的每个目标,包括不同视角,不同光照强度等情况能很好地适应;全局特征空间是使用场景的全局信息,没有场景图像分割的布局描述,也不需要一个清晰的目标,便可以反映整个场景图像的整体结构.由此,合理的融合全局特征和局部特征,不仅能在一定程度上提高室内场景分类的精度,而且无需进行图像分割、ROI检测和目标识别等,从而提高分类效率.图1所示为本文的室内场景分类总体架构.

图1 室内场景分类方法的总体架构Fig.1 The general steps for the indoor scene recognition
2 场景图像特征提取
2.1 场景图像的SIFT特征提取
局部特征描述算子(Scale Invarance Feature Transfer,SIFT)是根据多尺度图像金字塔极值点检测和梯度直方图的基础上,通过使用所描述的梯度方向直方图向量附近目标的关键点的计算方法.计算的主要步骤包含:精确定位尺度空间极值检测的关键点,确定关键点的方向,生成关键点特征描述符等.
针对一幅场景图像的经典SIFT特征提取,会生成n×128的特征矩阵,其中n为关键点个数,128为关键点的特征维度.由于关键点的个数与场景图像的梯度等因素有关,因此不同场景图像的关键点个数不同.这就导致每幅场景图像的特征点个数不同.如果以关键点个数最大值构建特征矩阵,将导致生成的特征矩阵是稀疏矩阵,其中存在大量的0值元素.这种情况下场景图像特征矩阵的冗余特征就非常多,导致场景分类效果差.因此,对经典的SIFT特征提取方法进行改进.步骤如下:
(1)根据Lowe的SIFT特征提取程序[11],得到关键点的位置坐标.
(2)使用FCM(Fuzzy C-Means)算法,以关键点的位置坐标作为特征,对关键点进行聚类处理.设定聚类数目为100,即令每幅场景图像提取100个SIFT关键点,聚类结果中属于同一类的关键点求平均值,作为本类别的唯一关键点,从而生成100×128的特征矩阵;
(3)使用主成分分析方法[12](Principle Component Analysis,PCA)对每幅图像生成的特征矩阵降维.
2.2 场景图像的Gist特征提取
Oliva和Torralba[6-7]从感知的场景出发,包括场景图像最基础的特征,比如:场景图像颜色、场景图像空间频率以及场景图像的纹理特征,提出了结构化的场景,即产生感知Gist的经过.Gist特征是通过模拟人的视觉来提取图像粗略的信息,以形成简单但足以描述场景图像的特征,同时这种特征还能反映上下文的信息.Gist特征利用频谱分析来捕获图像的空间结构的属性,把图像特征按照开放度、粗糙度、自然度、扩张度、崎岖度等进行提取.同时,通过具有多尺度多方向的Gabor过滤器来提取场景的轮廓信息,这也是Gist特征获取的过程.这里的Gabor过滤器实质是Gabor函数,如式(1)所示:
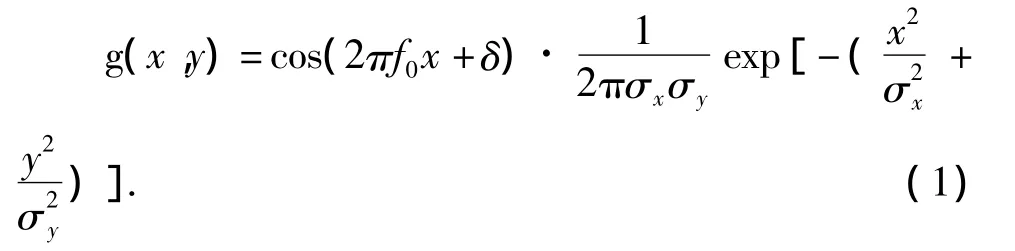
其中,x和y分别表示场景图像对应像素的横坐标和纵坐标,σx和σy代表Gaussian因子分别在x和y方向的方差,f0表示过滤器中心位置的频率,δ表示谐波相位差.
在实际应用中通过使用在不同方向以及不同的空间分辨率的Gabor过滤器来对场景图像进行采样滤波处理[13],经过滤波后的场景图像被划分成N×N的网格,在N×N的网格中通过求在各个方向以及各个尺度下的平均值来组成一个特征向量,它就可以作为场景图像Gist特征来对场景进行分类处理.本文在灰色图像上计算场景的方向和强度的对比特征.其中,方向通道加滤波器在4个角度(0°,45°,90°,135°)在4个尺度,形成16个子通道;暗亮强度的暗亮中心环绕在4个尺度,形成4个子通道.由此,一幅场景图像就形成20个子通道.对于一幅被分成4×4网格的场景图像,生成20×4×4=320维的向量.
2.3 场景图像的PHOG特征提取
形状描述特征算子PHOG不仅可以表示场景图像的的局部形状特征,而且可以表示场景图像的空间布局.通过逐级得分割图像,再每个分割图像中计算每一块梯度方向直方图,把每一块求得结果通过线性求和的方式统一成一个特征向量.梯度方向直方图金字塔就是由上述过程得到[14].
本文采用Anna Bosch和Andrew Zisserman提供的程序做实验[15].为了获得场景图像的轮廓特征以及形状描述,需要把一幅场景图像分级分块,其过程如图2所示.场景图像分割块通常是由横向和纵向坐标平均分割得到,在下一阶段的每个前级已被划分成4个.计算出包含在每一级每一小块的梯度方向直方图,其中梯度方向直方图是包含边缘点,然后累加每一个梯度直方图,最后得到一个场景图像特征,也被称为描述场景图像形状表征的PHOG特征.假设场景图像需要分割成L级,其中第L级中的每一小块被均分成2L块,如此一来便会获得4L个场景图像块.另外,对于每一块的梯度直方图会有K个区间,所以得到的PHOG特征描述就共有维.
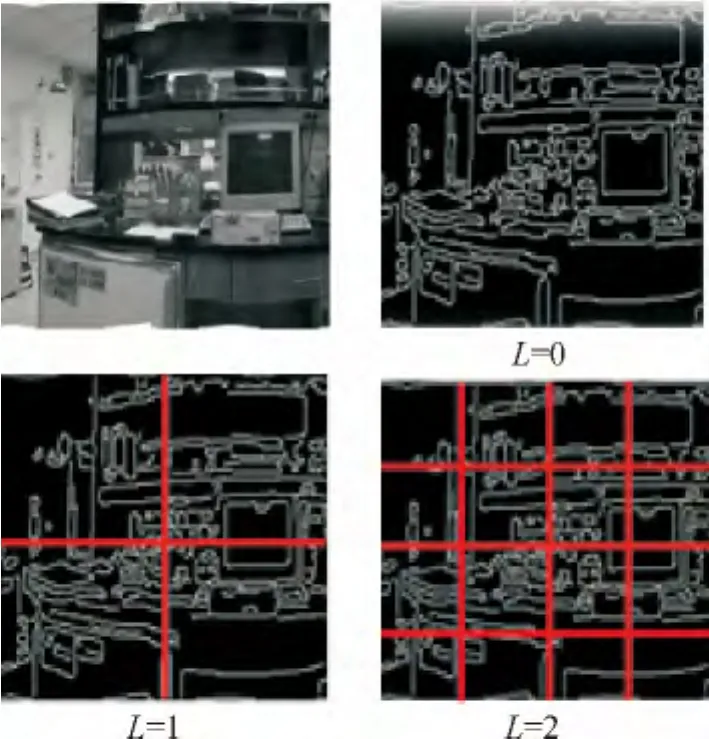
图2 图像的PHOG特征描述过程Fig.2 Step of PHOG features
2.4 多特征融合
通过上述特征提取,分别得到场景图像的SIFT特征、Gist特征和PHOG特征,其中Gist特征为全局特征,其他两个为局部特征.为了降低特征融合的复杂度,本文采用线性组合的方式融合3种特征,即

其中K1,K2,K3为各特征向量对应的权值,且K1+K2+K3=1.本文中,令K1=K2=K3.
3 仿真及实验结果分析
本文使用的室内场景图像集是基于MIT的Oliva&Torralba(OT)图像库中提取的[16],包含如图3所示的办公室、卧室、厨房、起居室、商店5个类别的室内场景图像,每幅图像的大小为256×256,每类图像的数量为50幅,共250幅.CPU为intel CORE DUO 2.10GHz,内存为6G,操作系统为Windows7,编程软件为MATLAB2010.

图35 个类别的室内场景图像集Fig.3 Five categories of indoor scene image sets
3.1 训练集与测试集的占比实验
本文选用核函数为RBF的SVM分类器,用一对多(1vs Rest)方式拓展成多类判决.为了得到合理的训练集在整个场景图像数据集中的占比,本文设定每类训练样本数分别占整体数的50%、60%、70%、80%来进行实验,结果如表1所示.表中c为SVM惩罚参数,g为SVM核参数.

表1 各个特征样本的实验结果Tab.1 The experimental results for each feature
由表1可知,训练图像数量占总图像数量为70%的时候分类效果最佳,由此本文采用训练图像数量占总图像数据集为70%的情况进行实验.
3.2 室内场景图像分类实验
在场景图像识别精度评价中,混淆矩阵主要用于比较分类结果和实际值,可以把分类结果显示在一个混淆矩阵中.混淆矩阵的每一行代表分类的信息,每一行中的数值等于分类的值与实际值的比值.采用不同特征对场景图像进行训练和识别后得到的混淆矩阵如表2至表5所示.采用符号代表各个图像场景类别:C1-办公室;C2-卧室;C3-厨房;C4-起居室;C5-商店.
在表2中,对于每一行Cii(i=1,2,……5)代表第i类的分类正确率,Cij(i≠j)代表第j类错分为第i类的错误率.对于每一行

表2 使用Gist特征的混淆矩阵Tab.2 Confusion matrix for using Gist feature

表3 使用SIFT特征的混淆矩阵Tab.3 Confusion matrix for using SIFT feature

表4 使用PHOG特征的混淆矩阵Tab.4 Confusion matrix for using PHOG feature

表5 使用多特征的混淆矩阵Tab.5 Confusion matrix for using muti-features
由表2和表5对比可知,使用多特征在卧室(C2)类和起居室(C4)类分类精度得到了提高,其中起居室类提高了13%,其他3类分类精度保持不变;由表3和表5对比可知,使用多特征在卧室(C2)类、厨房(C3)类、起居室(C4)类和商店(C5)类得到了大幅的提高;由表4和表5对比可知,使用多特征在卧室(C2)类、厨房(C3)类、起居室(C4)类分类精度得到了提高,只有商店(C5)类分类精度有小幅下降.由上述表格的分析可知,使用多特征相比单一特征在分类精度上确实有所提高;而且使用多特征融合的方法各个类的分类精度要比使用单一特征各个类的分类精度差异要小,避免了某一类别分类精度很高,而某一类别分类精度很低.
由表6可以看出,使用多特征方法的平均分类正确率最高,而且分类执行时间与单一特征相比,略高于Gist和PHOG,但是显著低于SIFT特征.由此可知,多特征方法不仅在整体上分类正确率得到了提高,而且对每个类别的分类正确率的差异最小.这说明多特征融合的方法对各个类别的识别具有比较高的一致性.

表6 各方法平均分类正确率和执行效率Tab.6 Classfication accracy and execution efficiency for each model
4 结论
针对当前室内场景分类精度比较低的问题,本文提出一种全局特征和局部特征组合的方法去提高室内场景分类的精度.本文的贡献在于:(1)在对场景图像SIFT特征提取的时候,没有按照经典方法对图像进行分块处理,而是通过FCM聚类[17]的方式得到所需的特征描述.不仅保留了SIFT特征良好的局部描述性,而且获得了维度统一的特征矩阵;(2)使用多特征融合的方式对室内图像进行描述.特征矩阵不仅具有场景图像的全局描述,而且具有局部描述,从而达到提高分类精度的目标.实验结果表明,本文方法的分类精度相对于单一特征提高了3%左右.
[1]Bosch A,Munoz X,Marti R.A review:Which is the best way to organize classify images by content[J].Image and vision Computing,2007,25(6):778-791.
[2]Fatih C,Ugur G,Ozgur U.Nearest-Neighbor based Metric Functions forindoor scenerecognition[J].Computer Vision and Image Understanding,2011,115(8):1483-1492.
[3]Quattoni A,Torralba A B.Recognizing indoor scenes[C]∥ComputerVisionand PatternRecognition.Miami,USA:IEEE,2009:413-420.
[4]欧阳敏,汪仁煌,陈府庭.基于LAB颜色距离的共生矩阵的纹理特征提取[J].广东工业大学学报,2011,28[4]:48-50.Ouyang Y M,Wang R H,Chen F T.The extraction of teture based on the co-occurrence matrix of LAB color-difference[J].Journal of GuangDong University of Technology,2011,28(4):48-50.
[5]Szummer M,Picard R W.Indoor-outdoor image classification[C]∥Content-Based Access of Image and Video Databases(CAIVD 98).Bomboy:IEEE,1998:42-51.
[6]Oliva A,Torralba A.Modeling the shape ofthe scene a holistic representation of the spatial envelope[J].International Journal in Computer Vision,2001,42(3):145-175.
[7]Oliva A,Torralba A.Building the Gist of a scene:the role of global image features in recognition[J].Progress in Brain Research:Visual Perception,2006,155(2):23-36.
[8]David G.Distinctive image features fromscal-invariant keypoints[J].International Journal in Computer Vision,2004,60(2):91-110.
[9]Zhou H,Yuan Y,Shi C.Object tracking using SIFT features and mean shift[J].Computer Vision and Image Understanding,2009,113(3):345-352.
[10]Espinace P,Kollar T,Soto A.Indoor scene recognition through object detection[C]∥IEEE International Conference on Rob o tics and Automation(ICRA).Anchorage,AK:IEEE,2010:1406-1 413.
[11]David G.Demo Software:SIFT Keypoint Detector[CP/OL].[2013-10-10].http:∥www.cs.ubc.ca/~lowe/keypoints/.
[12]王振友,郑少杰,何远才,等.基于PCA方法的PET方法的PET图像多示踪剂分离[J].广东工业大学学报,2013,30(2):42-46.Wang Z Y,Zhang S J,He Y C,et al.The Application of compotent Analysis to the Separationof Mutipul Tracers in PET Images[J].Journal of Guangdong University of Technology,2013,30(2):42-46.
[13]Oliva A.Demo Software:Gist descriptor[CP/OL].[2013-10-10].http:∥download.csdn.net/detail/miaoxikui/2886892.
[14]Bosch A,Zisserman A,Munoz X.Representing shape with a spatial pyramid kernel[C]∥Internatinal Conference on Image and VideoRetrieval(CIVP'2007),Ansterdan,The Netherlands:ACM,2007:401-408.
[15]Bosch A.Demo Software:PHOG descriptor[CP/OL].[2013-10-10].http:∥www.robots.ox.ac.uk/~vgg/research/caltech/phog/phog.zip.
[16]Oliva A.Fifteen Scene Categories Dataset[DB/OL].[2013-10-10].http:∥www.datatang.com/data/11991.
[17]刘洪伟,石雅强,梁周扬,等.面向聚类挖掘的局部旋转扰动隐私保护算法[J].广东工业大学学报,2012,29(3):28-34.Liu H W,Shi Y Q,Liang Z Y,et al.Partial rotation perturbation for privacy-preserving clustering mining[J].Journal of Guangdong Universityof Technology,2012,29(3):28-34.
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
科技视界(2018年32期)2018-02-21
自动化学报(2017年4期)2017-06-15
自动化学报(2017年11期)2017-04-04
国防科技大学学报(2016年6期)2017-01-07
噪声与振动控制(2015年4期)2015-01-01
