
基于视觉信息和标签路径的数据抽取*
2015-03-20 00:49:37邹晓明谈凤真
中国海洋大学学报(自然科学版) 2015年5期
张 巍, 邹晓明, 谈凤真
(中国海洋大学信息科学与工程学院,山东 青岛 266100)
基于视觉信息和标签路径的数据抽取*
张 巍, 邹晓明, 谈凤真
(中国海洋大学信息科学与工程学院,山东 青岛 266100)
结合网页的视觉信息和DOM树结构,研究从Deep Web查询结果页面中抽取半结构化数据的问题。通过视觉块与整个网页的面积比定位数据区域。根据数据记录两两相邻等视觉特征找到包含数据记录的一组节点,并通过比较各节点的DOM树结构的相似度去除噪音节点。根据xpath属性将各条数据记录的数据项对齐。对整个抽取过程生成模板,可以使抽取效率得到很大提高。对8个Deep Web网站进行了抽取数据实验,结果表明本文方法是有效的。
Deep Web; 数据抽取; 视觉信息; 标签路径
随着互联网的飞速发展,其中蕴含了海量的信息可供利用。与Surface Web 相比, Deep Web 蕴含的信息量是它的400~500 倍,并且其信息质量和增长速度要远远高于Surface Web。Deep Web覆盖了现实世界中的各个领域,比如商业、教育、政府等,并且95%的信息可以公开访问,因此如何有效获取Deep Web信息并加以利用备受人们关注[1]。
Deep Web网页的数据抽取一般有3种方法。手工方法:由编程人员通过观察网页的HTML源码找出能够定位目标数据的一些模式,并根据这些模式抽取数据,这种方法能够准确地抽取数据,但是需要花费大量的人力,并且抽取数据所用的模式不能适应网页的变化,所以不适合用于网页的自动抽取。半自动方法:首先人工标注一些网页,并利用机器学习的算法学习到一组抽取数据的规则,然后利用这些规则从具有类似格式的网页中抽取数据,文献[2-3]分别基于决策树、SVM和CRF对数据的自动抽取进行了研究,这类方法在一定程度上可以适应网页的变化,但是要得到一个好的模型,通常需要大量的人工标注。全自动方法:根据Deep Web页面的特点自动从网页中寻找数据记录,并将数据项对齐输出。这种方法不需要手工参与,适合大量站点的自动抽取。RoadRunner[4]通过比较多个样本页面的HTML结构来推测共同模式。但随着样本数量的增加,效率会急剧下降。IEPAD[5]首先把页面解析成HTML标签串,然后提出一种通过PAT树进行字符串匹配的方法识别数据记录并抽取数据项。MDR[6]实现了数据记录的抽取,通过挖掘多个相似的广义节点来识别数据区域,其中每一个广义节点对应一条数据记录。DEPTA[7]在MDR的基础上,通过简单树匹配算法对齐DOM子树实现了数据项的对齐和抽取。但这2种方法都需要遍历大量的节点,效率较低,而且也没有实现模板,从而使每一个页面都需要重复执行复杂的抽取过程。VIPS[8]通过比较网页元素的字体、颜色、是否超链接等视觉特征将页面划分成不同的视觉块。ViDE[9]基于VIPS提出一种基于视觉信息的数据抽取方法,该方法在一定程度上克服了现有方法对HTML源文件的依赖,但是每次抽取数据都需要先计算页面的视觉信息,这需要花费大量的时间。
本文结合网页的视觉信息和DOM树结构,提出一种从Deep Web查询结果页面中抽取半结构化数据的自动化方法。首先根据网页的视觉特征来定位数据区域和数据记录,然后利用数据记录DOM树结构的相似性去除噪音节点,再通过xpath属性来对齐数据项。最后生成抽取数据模板,从而可以对Deep Web页面进行高效、准确地数据抽取。
1 概述
Deep Web网站最显著的特征是用户向服务器提交关键字查询,服务器查询Web数据库,并将结果加上格式控制后以网页的形式返回,浏览器通过渲染网页把结果表现出来。其中Web数据库存放的是结构化数据,但是返回结果是网页形式的半结构化数据,这些数据有一定的结构,但是不同记录的相应字段没有明确的对应关系,各记录的字段数目也不一样,所以它们无法直接被利用,需要将其结构化,并用图5所示的存储结构保存为结构化数据。网页中显示查询结果的部分称为数据区域,通常由标题、查询结果列表、导航信息等组成。其中查询结果列表称为数据记录,也就是所要抽取的半结构化数据,其它的是数据区域中的噪音。数据记录的抽取,通常可以通过以下三步来完成:
首先,定位数据区域。由于查询结果页面最主要的目的是突出查询结果以方便用户查看,所以其数据区域一般会放在页面的明显位置,并且占据网页的大部分区域。根据Deep Web页面的这个特点,可以通过查找与整个网页的面积比大于某一个阈值的区域来定位到数据区域,如果这样的区域有多个,则选择面积最小的[6]。
第二,定位数据记录。数据记录是数据区域中的列表部分,这些数据记录有相似的格式控制,即具有相似的标签名和样式。将每一条数据记录看作一棵DOM子树,那么这些子树除了叶子节点(数据项)的值不同,其DOM树结构十分相似。所以遍历数据区域得到它所有的孩子节点,并按标签名分类,则数据记录节点会在同一个类别中。从数据记录的视觉信息来看,无论他们怎么排列,其位置总是相邻的。所以再将按标签名得到的分类按是否相邻分类,得到的互相相邻并且面积之和大于数据区域面积的1/2以上的一组节点就会包含数据记录,但是这组节点里还可能包含噪音。由于数据记录节点之间的DOM树结构十分相似,而与噪音节点相差较大,所以通过比较他们的DOM树的相似度,可以把噪音节点去除掉。
第三,对齐数据项。数据记录由语义各不相同的项组成,每一个具有单独语义的项称为数据项。例如当当网中关于一本书的数据记录是“C++程序设计 2010年 清华大学出版社 价格:¥20 折扣:9折 ...”。这样一条记录显然无法在实际中直接使用。需要进一步把数据记录分成不同的语义单位,例如“C++程序设计”、“ 清华大学出版社”、“价格:¥20”,并且将不同数据记录的相同语义的数据项对齐。
另外,由于同一个Deep Web网站的查询结果页面的结构十分相似,因此可以将首次抽取的网页的一些参数保留下来作为模板,在其它类似页面的抽取中直接用来定位和对齐数据,这样就不需要每一页都重复复杂的抽取过程,可以大幅提高抽取效率。
2 定位数据区域
对于Deep Web的查询结果页面,按照功能一般可以分为以下几部分:查询区域、查询结果的分类、查询结果列表以及广告等。查询区域包括搜索文本框、高级搜索、以及热门搜索关键词等,一般位于网页的顶部;查询结果的分类是指将查询结果按照地区或价格等属性进行分类,点击分类中可以得到更具体的查询结果。例如当查询一个城市的餐饮时,可以把查询结果再按价格或中西餐分类,当点击分类时,可以得到更精确的查询结果。查询结果列表是整个页面中最主要的部分,也就是我们要找的数据区域。
数据区域具有明显的视觉特征。为了突出查询结果,数据区域一般是页面中面积最大的部分,并且它不会只位于网页中线的一侧。本文通过如下方法找到包含数据区域的节点:遍历DOM树,找到满足下面条件的节点:
Area(node)/Area(body)>Tregion
如果这样的节点有多个,将面积比最小的作为数据区域的节点。采集50个Deep Web查询结果页面作为样本,并训练得到通过视觉信息定位数据区域的决策树,当Tregion为0.4时,可以准确地定位到数据区域。
3 定位数据记录
数据区域通常包括标题、查询结果列表、导航信息等,其中的查询结果列表就是要抽取的数据记录,定位数据记录需要从数据区域中找到数据记录的节点。通常分为两步:
(1)将数据区域的所有孩子节点中标签名相同的分为一类。由于数据记录是由Web数据库中的结构化数据加上统一的格式控制产生,所以他们的DOM树除了叶子节点(数据记录的具体描述)外,其结构十分相似,并且其根节点具有相同的标签名。在数据区域的DOM树中,数据记录节点的位置不尽相同,可能在同一个父节点下,也可能有不同的父节点(见图1)。但如果将数据区域的孩子节点按标签名分类,那么所有数据记录节点会分在同一类别中;

图1 数据记录节点在DOM树中的位置Fig.1 Position of data record nodes in the DOM tree
(2)通过分析数据记录的视觉特征,从第一步的分类结果中找到包含数据记录的类别。这些视觉特征有:
①数据记录是相邻的,常见的数据记录的排列方式有两种:垂直分布和均匀分布,也会有其他的不规则的排列,如图2所示。虽然数据记录在网页中的分布排列越来越丰富,但是这些排列方式共有的特点是每一条数据记录都至少可以找到另外一条数据记录与其相邻。所以把对按标签名得到分类再按是否相邻分类,则数据记录节点位于标签名相同并且互相相邻的类别中;

图2 数据记录的分布
②数据区域一般包含标题、数据记录、导航信息等,但是数据记录占数据区域的大部分,因此对于第1步得到标签名相同并且相邻的分类,如果分类内节点的面积之和大于数据区域面积的50%,就可以确定数据记录包含在这一组节点中,但是这些节点中还可能包含标题等噪音数据。定位数据记录具体算法(见图3)。

图3 定位数据记录的算法
该算法首先深度遍历数据区域节点,得到其所有孩子节点。将这些孩子节点按标签名分类,得到{Ci|0≤i 另外,在按相邻位置分类时,不需要判断每一个标签名的分类。因为HTML标签按照标记内容的不同可以分为块级元素和内联元素。块级元素显示的为一块内容,通常用于布局,如div,table等。内联元素是语义级的元素,它只能容纳文本或者其他内联元素,如a,font等。显然,数据记录是对实体的具体描述,通常会包含多个数据项,只可能是块级元素,因此只需考察块级元素的分类。 4.1 去噪 数据区域通常由标题、查询结果列表、导航信息等组成。例如,在当当网的查询结果页面中,标题是对数据记录列属性的说明,如书名、价格等。查询结果列表是对各属性的具体描述。导航信息指“上一页 下一页”等。其中查询结果列表以外的部分称为数据区域中的噪音。由于数据记录的产生有统一的格式规则,所以各条数据记录的DOM树结构十分相似。通过比较数据记录节点和噪音节点的DOM树结构相似度就可以把两者区分开来。 图4 数据记录的DOM树 (1)将数据记录表示成xpath的集合。一条xpath是指从DOM树的根节点到叶子节点的标签路径。数据记录的根节点到所有叶子节点的xpath的集合记为xpaths,可以用{xpathij|0≤j (2)由于数据项中可选项的存在,两条数据记录的DOM树结构可能不会完全相同,因此只要xpaths1和xpaths2的相似度大于一个阈值,就可以认为二者具有相似的DOM树结构。本文中采用的阈值为0.6。xpaths1和xpaths2的相似度计算公式是: intersection是指xpaths1和xpaths2中相同的xpath的数目;union是指xpaths1和xpaths2形成的集合中xpath的数目。只有2条xpath完全一致时才认为相等。 4.2 对齐数据项 在查询结果页面中,每一条数据记录包含若干个数据项,由于可选项的存在,各条数据记录中包含的数据项的个数不一定相同。例如当当网中,每一条数据记录包含的数据项是:书名、出版时间、出版社、作者、价格、折扣等,其中折扣是可选项,某些数据记录中可能不包含折扣信息;另外,有的网站中每本图书会有一个标签,如“专业 最新 适合入门”,作为读者对该书的评价,显然所有的评价应该作为一个数据项,但是每本书的评价关键词的数量是不一定的,在数据项对齐之前先要确定将那几个项作为一个数据项。所以可选项的存在和数据项的长度(指一个语义完整的数据项包含的项的个数)可变是数据项对齐的主要问题。 (1)确定数据项的粒度,即一条数据记录中那几项可以作为一个数据项。将数据记录中的每一个叶子节点看作一个项,它是数据记录中的最小单位。其中某些项关系比较密切,应该把它们做为一个数据项来看。理想的情况是将通常人所观察到的语义单位作为一个数据项,这样的一个数据项可能包含一个或多个项。例如数据项“标签:专业 最新 适合入门”,其中每个词语为一个项,由于这几个项之间语义联系紧密,就作为一个数据项来看。从数据记录的产生来看,数据项之间的区分主要是给不同的数据项加上不同的格式控制,使同一数据项的各个项之间的视觉特征相似,并且同一数据项的项的间隔较小,不同的数据项的间隔较大。但是视觉信息对数据项的区分只是起到辅助作用,更主要的是人对数据项的语义的理解。假如将“标签:专业 最新”换成“标签:专业 清华大学出版社”,虽然这个数据项的视觉特征没有变,但是我们会把后面的理解成两个数据项。由于语义的处理较为复杂,本文采用一种较简单的方法来确定数据项。 遍历数据记录的孩子节点,如果遇到文本节点,就将它的父节点的内容作为一个数据项。这样得到的数据项可能将理想的数据项分成多个,如将“标签:专业 最新”分成“标签:”“专业”“最新”。再将得到的数据项,按照其在网页中的位置从上到下、从左到右排列。这样虽然这三个数据项是分开的,但他们在数据记录中的位置仍然是相邻的,可以再根据语义将它们合并,本文暂不做讨论。 (2)得到数据项的xpath,并将它作为数据项的对齐属性。数据项的xpath是指从数据记录的根节点到数据项(叶子节点)之间的标签路径。在一条数据记录的DOM树中,对于两个不同的叶子节点,从根节点到他们的标签路径可能完全一样,所以数据项的xpath有可能重复。在Deep Web页面中,不同的数据项一般会通过元素的class属性对其有不同的格式控制,因此对xpath上的每个元素取两个值:标签名和节点的class属性。这样xpath就能很好的区分不同的数据项。 (3)对齐算法。得到所有的数据项及其xpath后,需要将不同数据记录中相应数据项对齐。首先将每条数据记录的数据项按照其在网页中的位置从上至下、从左至右排列。为了便于对齐,设计了一个类似二维数组的数据结构来保存数据项,如图5,记为Record[m+1][n],m表示数据记录的条数,n表示数据记录的xpath的条数。Record[0] [J]表示xpathj的属性信息,并与Record[i] [J] (0 图5 保存数据项的存储结构 图6 对齐数据项的算法Fig.6 Algorithm of aligning data items 当插入数据记录DRi的第j个数据项时,首先查找xpath[n2]中是否存在该数据项对应的xpath,如果存在,直接在Record2的相应位置存入数据项的值;否则说明此数据项是一个可选项,先在Record2中上次插入的位置之后新建一列,然后保存此数据项,并将其xpath也插入到xpath[n2]中。 在Deep Web数据抽取中,由程序自动定位数据区域和数据记录以及对齐数据项,这个过程需要对各个节点进行大量的遍历和计算。由于Deep Web页面是动态生成的,所以数据记录都有固定的模式。当数据区和数据记录定位后,可以把相关的属性保存下来作为模板参数,利用模板抽取同一网站的其他页面,可以使抽取的效率大幅提高。 5.1 数据区域和数据记录的模板 Deep Web网页最显著的特点是它们是查询Web数据库后动态生成的,有统一的格式控制,所以对于同一网站的不同页面,数据区域部分的网页格式是基本一样的。当数据区域定位以后,可以记录数据区域的节点信息作为模板,如标签名、BODY节点到数据区域节点的标签路径等。由于每个页面的数据区域节点有相同的格式,因此可以根据模板信息直接定位数据区域,而不必遍历所有的节点。 同样,同一网站的数据记录也有相同的格式控制,把数据记录的节点信息作为它的模板,则定位数据记录时只需要判断符合模板信息的节点。 5.2 对齐数据项的模板 由于可选项的存在,不同数据记录所包含的数据项的个数不同,所以需要对齐。但是,数据记录中的可选项只是少数,一般是1~2项,而且包含可选项的数据记录可以认为是信息比较丰富的,一般会放在查询结果列表中比较靠前的位置。这样通过第一页的抽取,基本所有的可选项都会出现。 将第一页的数据项对齐后所有数据项的xpath作为对齐数据项的模板,这个模板基本包含所有的可选项。当利用该模板对齐其他页面的数据时,若出现新的可选项,也将其xpath插入来更新模板。另外,利用模板来对齐数据的好处是可以对齐多页数据。 总之,当首次抽取某个Deep Web网站的数据时,首先定位数据区域和数据记录,然后对齐和保存数据项,并保存相应的模板。由于Deep Web网站的数据一般会分页显示,通常会有“下一页”“Next”等关键字提示,可以利用启发式规则自动点击翻页。当抽取后面的类似结构网页时,就可以利用已经保存的模板来抽取数据,使抽取效率得到很大提高。若由于网站改版等原因使网页的结构发生变化,已保存的模板不能抽取当前页面的内容,则需要重新进行定位数据区域等操作,并得到新的模板。 为了验证基于视觉信息和标签路径的数据抽取算法的准确率,本文通过Webbrowser控件来渲染网页,实现了原型系统。本节给出实验结果。 6.1 实验数据 实验的数据来自购物、招聘等8个Deep Web网站,通过对每个网站的查询入口提交关键词获得查询结果页面。通常情况下,若数据记录中包含可选项,在前两页中都会出现,因此,对每个网站抽取前两页数据作测试。 6.2 数据记录的实验结果 选用DEPTA算法作为对比,因为它是利用DOM树抽取数据的典型算法。查准率是指抽取的数据记录占抽取的所有记录的比例,查全率是指抽取的数据记录占网页中所有数据记录的比例。表1是对八个网站(见表2)进行抽取实验后两种算法的比较: 表1 本文算法和DEPTA的比较Table 1 Comparison of our method and DEPTA /% 从表中可以看出,本文的方法能够准确地定位数据区域和去除噪音,因而抽取的数据记录有较高的准确率,但是也有部分数据记录没有找到。这是因为,有个别网页使用WebBrowser不能正确渲染,得不到相应的DOM树,无法抽取数据。 6.3 数据项的对齐实验 找到数据记录后,遍历其子节点就可以得到数据项,因此数据项的查准率、查全率和数据记录基本相同。但是对于数据项,更关注不同数据记录的数据项是否对齐,因为即使所有的数据项都找到并且全部准确,如果具有相同语义的项没有对齐,这样的数据也无法利用。表2列出了选取的8个网站的对齐结果,第二列是本文算法得到的数据项的列数,第三列是能够对齐的列数。 从表中可以得到,对齐的平均准确率只有84.5%。由于本文对齐的依据是数据项的xpath,但是xpath不是唯一的,不同的数据项可能有相同的标签名和class属性,使不同的数据项放在同一列。而且同一列数据项的class属性也可能不一样,这样会使相同的数据项放在不同列。总之,如何确定数据项的分割粒度以及对齐所依赖的属性还有待进一步的研究。 表2 数据项对齐的准确率Table 2 Alignment accuracy of data item 本文针对从Deep Web页面中抽取半结构化数据的问题,提出了一种通过视觉信息和标签路径进行自动抽取的方法。首先通过计算视觉块与整个网页的面积比定位数据区域。然后根据数据记录两两相邻等视觉特征找到包含数据记录的一组节点,并通过比较各节点的DOM树结构的相似度去除噪音节点。再根据xpath属性将各条数据记录的数据项对齐,最后对抽取过程生成模板。实验表明,本文抽取的数据记录达到了较高的准确率。未来的工作将考虑通过数据项的语义来划分数据记录,并提高数据项对齐的准确率。 [1] 刘伟. Deep Web数据集成研究综述 [J]. 计算机学报, 2007, 30(9): 1475-1489. [2] Wang Y, Hu J. A machine learning based approach for table detection on the Web [C].//Proc of the 11th Int Conf on World Wide Web. New York: ACM, 2002: 242-250. [3] Pinto D, McCallum A, Wei X. Table extraction using conditional random fields [C].//Proc of the 26th Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2003: 235-242. [4] Crescenzi V, Mecca G, Merialdo P. Road-runner: Towards Automatic Data Extraction from Large Web Sites[C].//Proc of the 26th Int'l Conf. on Very Large Database Systems. Roma, Italy: [s.n.], 2001: 109-118. [5] Chang Chia-Hui, Lui C. IEPAD: Information Extraction Based on Pattern Discovery[C].//Proceedings of the 10th International Conference on World Wide Web. Hong Kong: [s.n.], 2001: 681-688. [6] Liu B, Grossman R L, Zhai Yanhong. Mining data records in Web pages [C].// Proc of the 9th Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2003: 601-606. [7] Zhai Y, Liu B. Web data extraction based on partial tree alignment [C].// Proc of the 14th Int Conf on World Wide Web. New York: ACM, 2005: 76-85. [8] Cai D, Yu S, Wen J R, et al. VIPS: a vision-based page segmentation algorithm [R]. Microsoft Technical Report, MSR-TR-2003-79, 2003. [9] Liu W, Meng X, Meng W. Vision-based Web data records extraction [C].// Proc of the 9th Int Workshop in Web and Databases. New York: ACM, 2006: 20-25. 责任编辑 陈呈超 Data Extraction Based on Vision and Tag Path ZHANG Wei, ZOU Xiao-Ming, TAN Feng-Zhen (College of Information Science and Engineering, Ocean University of China, Qingdao 266100, China) Semi-structured data extracted from Deep Web query results page is studied, based on the visual information and DOM tree structure of pages. The data region is determined by the ratio of visual block area to the entire page. A set of nodes with data records are identified according to visual features, such as adjacency. Noise nodes are eliminated by comparing the similarity of nodes’ DOM tree structure. According to xpath attributes, all data items are aligned. Template is generated for the process of extraction, which significantly improves the extraction efficiency. Experiments of data extraction were conducted with eight Deep Web websites, the results of which fully testify the effectiveness of our method. Deep Web; data extraction; visual feature; tag path 山东省自然科学基金项目(ZR2012FM016)资助 2013-10-30; 2014-09-20 张 巍(1975-),男,副教授。E-mail: ihcil@ouc.edu.cn TV149.2 A 1672-5174(2015)05-114-06 10.16441/j.cnki.hdxb.201303954 对齐数据项




5 模板
6 实验
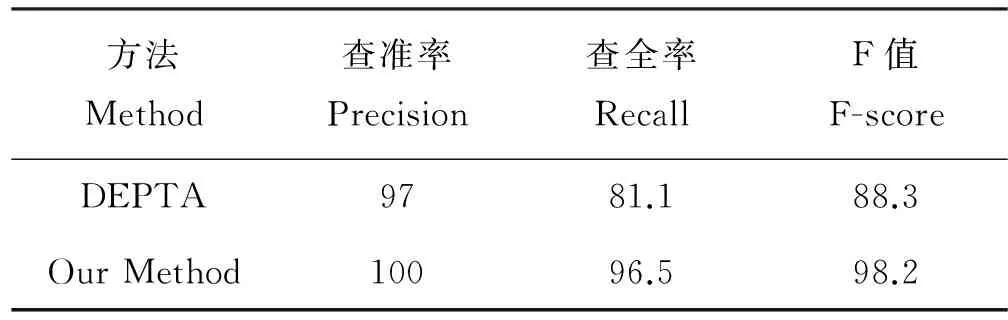
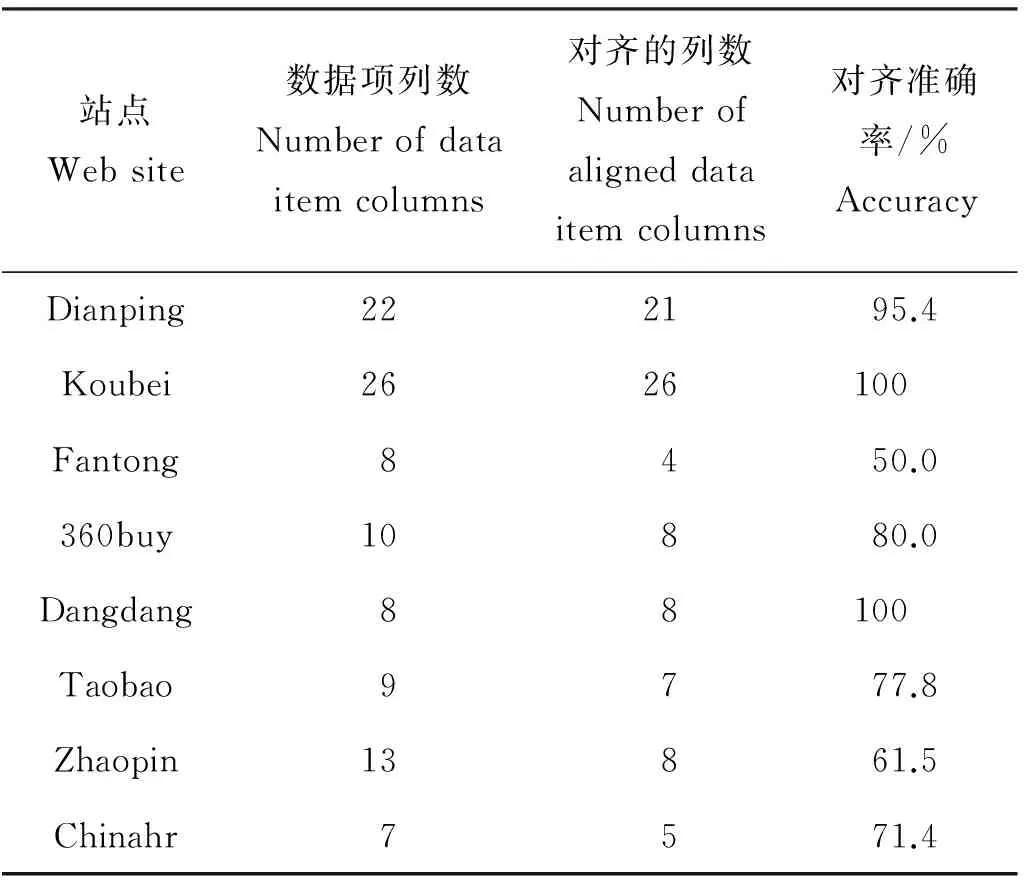
7 结语
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14甘肃科技(2020年19期)2020-03-11 09:42:42计算机与生活(2019年11期)2019-11-12 05:41:02科技与创新(2019年14期)2019-08-12 12:55:20电子制作(2018年10期)2018-08-04 03:24:38电子制作(2017年2期)2017-05-17 03:54:56电子测试(2015年18期)2016-01-14 01:22:58计算机与网络(2014年7期)2014-03-25 10:57:07计算机工程与设计(2011年7期)2011-09-07 10:16:42电脑爱好者(2011年11期)2011-06-22 08:20:18
