
一种面向储粮微环境的GPSO改进算法研究
2015-03-11 10:05吴建军祝玉华
中国粮油学报 2015年12期
吴建军 甄 彤 祝玉华
(河南工业大学,郑州 450001)
粮堆本身是一个比热容大、蓄热性强的生态系统[1],表现出特殊的稳定性,同时,粮食作为热的不良导体,散热与升温需要外界提供较大的能量,花费一定的时间;相反,如果外界提供的热量不够或者时间较短,整个粮堆温度的变化就会不明显。在粮仓中,如细菌、霉菌、酵母菌的生长,造成粮食中的有机物质被分解利用,粮食就会发生霉变。因此需要提前掌握粮堆内部温度的变化趋势。
在粮堆温度变化预测领域的研究中,已经有很多的技术和方法被广泛应用,比如早期的统计预测算法领域中的线性回归、求和自回归滑动平均模型、指数平滑模型、非参数回归模型等方法。随着近年来人工智能算法的发展,基于智能计算的粮情预测模型也引起了众多科研人员的关注,并取得了一定的研究成果。
利用储粮微环境的GPSO改进算法,建立粮食温度场变化理论及规律的预测及控制模型,以期适应复杂的大型粮堆储藏环境,为粮食调控过程优化提供参考。
1 自适应PSO算法研究
粒子群算法(Particle Swarm Optimization,PSO)[2-3]通过模拟鸟群、鱼群及其他一些昆虫的群体行为,对于模拟的群体在觅食行为中,个体成员通过学习自身和同伴的经验,从而不断改变自身的行为选择。
假设种群规模为N,zi=(zi1,zi2,…,ziD)为第i个粒子的位置矢量,则粒子的位置和更新[4]由下述式(1)、式(2)给出:
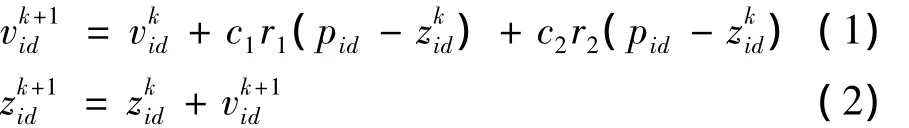
式中:vi=(vi1,vi2,…,viD)表示粒子 i的飞行速度,即粒子移动的距离,其中式中(i=1,2,…,m)。pi=(pi1,pi2,…,pid,…,piD)表示该粒子群任意个体迄今为止的最佳位置;pg=(pg1,pg2,…,pgd,…,pgD)表示整个粒子群迄今为止的最优位置。式中k表示迭代次数;c1,c2表示学习因子,其值来源于自身经验,其作用是使得粒子具有向自身的和群体中其他粒子的最佳位置靠拢的特性;r1,r2为均匀分布的随机数,表示范围为[0,1],r1,r2使得群体具有多样性的特点。
为了改善算法的收敛性能,Shi等[4]引入了惯性权重的概念,速度和位置更新公式改为:
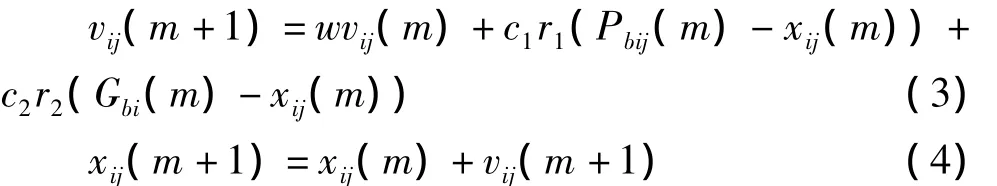
w为惯性权重,决定的是对粒子当前速度继承的多少。合理选择w可以使粒子具有均衡探索和开发能力。惯性权重表达式采用Shi等[4]提出的线性递减权重策略,如公式(5)。
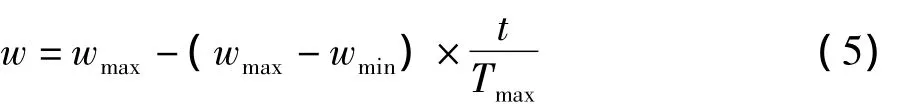
从分析Shi等[4]研究已知,惯性权重w在粒子群算法中主要起到平衡算法的全局或局部的收缩能力。w取较小值时,算法的搜索空间较小,w取较大值时,算法的搜索空间则变得较大,因此在研究面向储粮微环境的粒子群改进算法时,怎样动态调整w值避免算法早熟是改进算法的方向。
在计算前期,搜索空间较大,怎样采用较好的搜索策略使得算法进行全局搜索得到较好的解,怎样在计算后期使算法在较好解内进行局部搜索得到最优解,是面向储粮微环境改进算法GPSO的研究重点。
2 面向储粮微环境改进算法GPSO的目标函数的设计
粮堆温度变化预测模型本研究采用传热模型,即粮堆内粮食热平衡方程:

式中:t为时间参数,ρg为粮食的密度参数,H g为粮食水分参数,RW为粮食的失水速率参数,Tg为粮堆内的粮食温度参数;cpg为粮食的比热容参数;hg-a为粮食表面和空气之间的对流换热系数;ξ为单位体积内粮食与空气接触的比表面积,Lvap为粮食水分的蒸发潜热,cpv为水蒸气的比热容参数。
针对粮食粮堆内粮食热平衡方程,本研究利用高斯核函数把训练集数据Tg映射到一个高维线性特征空间,进而实现在高维数的线性空间中构造回归估计函数,则对于预测粮堆温变化预测函数f( Tg) 为如下形式:
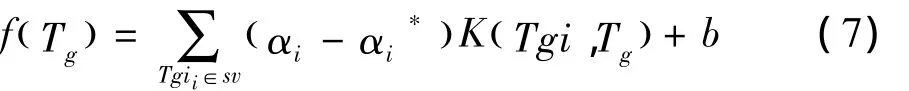
约束条件为Tmin≤Tg≤Tmax。
在式(7)中的b如下表示:

3 面向储粮微环境的GPSO粒子群算法研究
在Shi等[4]研究的基础上,考虑到自适应动态权重ω(t,σ)算法综合了考虑时间与目标函数标准差对搜索空间的影响,但由于粮食在实际保管过程中,因为季节的不同,对于策略的调整需要加上粮食保管季节的调节因子g。对于因子g的赋值策略是利用正弦函数的性质,在算法迭代过程中,要使得惯性权重的值较大值或较小值适应样本环境,保持的时间更加合理(更长)。吴子丹等[5]在跟踪分析归纳了我国大型粮仓不同区域、不同年份全年粮情数据后,提出了基于正弦函数的预测模型,该模型通过分析我国大型粮仓不同区域、不同年份全年数据得到,1个完整年份的粮食温度变化成正弦曲线变化。具体为粮堆内部温度伴随时间的推移变化规律可以近似的用正弦曲线来描述,且粮堆某点平均温度、温度变化幅度都可以通过历史数据计算获得,而初始相位ω则与检测点的位置有关。因此本研究在该模型基础上对惯性最终自适应动态惯性权重的具体修正如下:
在自然储存条件下,g根据季节不同,取4个不同的时间,区间取值分别不同,假设当前日期为d,ds<d<de,ds为起始日期,de为结束日期。

从构建GPSO的自适应动态权重ω(t,σ)可以看出,算法综合了考虑时间与目标函数标准差对搜索空间的影响,也考虑了粮食储存的实际影响因子。例如在2月2日至5月4日,虽然气温逐步升高,但较为温和,此时粒子群的聚集度比较大,各粒子的分布比较集中,粒子群体的多样性较低。惯性权重以步长(2-tanh(σ)×(1+g))非线性增加,由于此时正弦函数非线性增长,惯性权重w的减小趋势缓慢,维护了群体的多样性,从而避免了种群的多样性迅速降低。在5月5日至8月6日,粒子群聚集度较小,粒子的位置分布呈分散性,这时惯性权重w的值以步长(2-tanh(σ)×(1+g))非线性增加,由于此时正弦函数非线性减小,w的减小速度加快,使得算法能快速收敛于最优解。
因此,通过对动态权重的修正,在考虑粮食储存的实际影响因子g的情形下。不仅使得算法在初期搜索空间较大,在后期算法的搜索空间减少;同时可以看出,动态权重的可以在粒子的多样性不能保证时自动增大。
通过对动态权重的修改,面向储粮微环境的GPSO算法如下:
1)初始化,设定粒子群中的粒子位置和速度。
2)每个粒子适应度的计算,即确定目标函数J。
3)粒子的训练,计算直到当前优化时刻m为止,所经历的具有最好适应度的位置,均方差σ的计算,通过计算粒子群适应值的均方差,利用该课题提出的公式(9)计算惯性权重w。
4)通过改进策略,全局寻优,训练群体中所有粒子经历过的最好位置。
5)更新粒子最优速度与位置。完成目标函数适应度的比较以及新粒子的更新,从而实现个体历史最优值以及群体历史最优值的更新。
6)对进行判断比较,判断是否满足要求,或进化到预先设定的迭代次数。如果满足终止条件,则停止,否则返回步骤3)重新搜索。
对于算法的时间复杂度,一般用T表示最大迭代次数,N表示粒子总数,D表示决策变量的维数,GPSO算法相对于PSO而言,综合了考虑时间与目标函数标准差对搜索空间的影响,对于权重计算的时间复杂度为T1(N)=O(N×D×T),标准PSO算法的时间复杂度为T2(N)=O(N×D×T),则GPSO算法得时间复杂度为T(N)=T1(N)+T2(N)=O(N×D×T),即改进算法GPSO和标准PSO算法处于同一时间复杂度。
4 面向储粮微环境的GPSO算法分析
为了测试改进算法的有效性,尤其是对原有PSO是否有所提升,下面试验中对于Shi等[4]提出的自适应惯性权重的模糊系统算法简称自适应PSO,本研究采用了1个多峰函数Schaffer[6]和1个单峰的函数Sphere函数分别对改进前后的粒子群进行测试。对于Schaffer函数,用来测试算法的全局优化能力。Sphere函数是1个单峰函数,具有1个单峰值,用来检验算法的效率。
4.1 Sphere函数
算法效率的检验,常用Sphere函数进行检验,它的函数公式为:

Sphere函数具有唯一的最小值0,是1个连续单峰值函数。本研究选用其二维形式,如图1所示。

图1 二维Sphere函数图
为了验证GPSO算法效果,在验证中,PSO、PSO和GPSO算法采用相同的参数(c=0.5)以及迭代次数,分别采用以上2种方法搜索Sphere函数的最小值。为了更好的检验效果,设计2类试验,试验用计算机的型号为星锐4572G(宏基)CPU为酷睿i5(英特尔),经过在同一硬件配置的计算机上运行60次,得到平均结果(见图2)。
试验1使用的粒子群,种群规模均设定为20,迭代次数均设定设为30,全局最优值变化曲线比较见图2。

图2 全局最优值变化曲线比较图
试验2使用的粒子群,种群规模均设定为不同,迭代次数依然设定为30,表1为设定的不同种群规模的优化。

表1 不同种群规模的优化结果
由图2可以看出,3种算法都具有比较强的搜索能力,群体最优值随迭代次数呈明显的下降趋势,但是在全局最优值的收敛速度方面,GPSO和自适应PSO收敛速度明显要快,常规PSO稍慢。由表1可以看出,在迭代次数相同的情况下,当改变不同的种群规模时,GPSO和自适应PSO的收敛精度明显较高,常规PSO稍逊。由以上2个试验的比较可以看出,在不同情况下,GPSO在搜索效率以及收敛精度方面相对于Shi等[4]的自适应权重改进粒子群算法优势更为明显。
4.2 Schaffer函数
对于算法的全局优化能力,常用Schaffer函数进行检验,它的函数如式(11)所示。
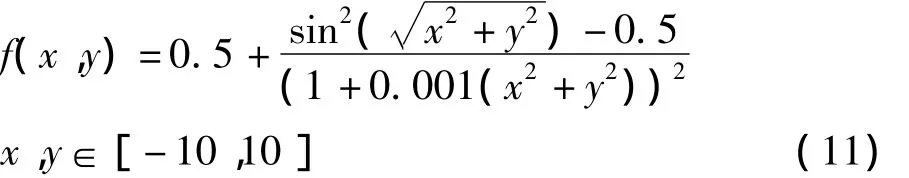
从式(11)可知,Schaffer函数表达式较为复杂,图3为其函数图。从图3可以看出该函数在(0,0)点处有全局最小值0,对于全局最优点,处于凹形区域底部,在该底部的同心圆上,还分布有大量局部最优点,并且两者的差值很小。

图3 Schaffer函数的空间分布图
在该次测试中,假设种群规模设为500,将迭代次数设为30,则GPSO与自适应PSO算法得到的群体最优值fg,其随迭代次数变化曲线如图4所示。
假设迭代次数设为40,将三者的目标函数值都设为0.000 000 1,同时选取6组不同规模的种群数目,进行50次试验。表2所示为3种算法的搜索情况。
从表2可以看出,在迭代次数相同情况下,利用GPSO和自适应PSO算法搜索的成功率在任何种群下均优于PSO;但随着种群规模的增加,GPSO的算法搜索成功率均优比自适应PSO有明显优势,同时,随着迭代次数的增加,GPSO的成功率比自适应PSO更加高。

表2 不同种群规模时优化成功率
从图4可知,对于相同规模的种群和迭代次数的情形下,在收敛速度和精度方面,GPSO和自适应PSO算法明显较优,常规PSO稍逊。设定目标值为0.000 000 1情形下,如果增加种群规模,虽然3种算法搜索的成功率都有所增加,但GPSO和自适应PSO算法明显优于常规PSO,但GPSO随着种群规模的增加,优势更为明显。上述试验表明,GPSO不仅在搜索效率和收敛精度,在全局优化能力和可靠性方面都优于PSO,在种群规模增大的条件下,随着迭代次数的增加,GPSO优于自适应PSO粒子群算法。

图4 全局最优值随迭代次数函数曲线
5 结论
本研究通过改进粒子群算法惯性权重和目标函数,提出一种面向储粮微环境的GPSO改进算法,结果表明改进算法在粒子分布较为分散时,即夏季和冬季,使得粒子群收敛速度较快,迭代曲线平稳,全局搜索能力强。在粒子分布较为密集时,粒子的速度较为缓慢,其局部寻优能力强。
[1]朱宗森,陈明锋,蒋金安,等.四项储粮新技术的应用现状与发展趋势[J].西部粮油科技,2006,31(6):67-69
[2]李宁,付国江,库少平,等.粒子群优化算法的发展与展望[J].武汉理工大学学报:信息与管理工程版,2005,27(2):26-29
[3]吴建军,张强.基于粒子群的神经网络改进算法在粮情测控中的研究[J],河南工业大学学报:自然科学版,2010:68-71
[4]Shi Y H,Eberhart R C.A modified particle swarm optimizer.IEEE International Conference on Evolutionary Computation,Anchorage,Alaska,May,1998:69 -73
[5]吴子丹.绿色生态低碳储粮新技术[M].北京:中国科学技术出版社,2011
[6]邓薇.《MATLAB函数速查手册》[M].北京:人民邮电出版社,2010.
猜你喜欢
河南工业大学学报(自然科学版)(2020年6期)2021-01-29
农业工程学报(2020年8期)2020-06-04
中国粮油学报(2020年4期)2020-05-25
中国粮食经济(2020年1期)2020-01-08
中国粮食经济(2018年4期)2018-12-27
金桥(2018年4期)2018-09-26
中国粮食经济(2018年7期)2018-01-01
中国粮食经济(2018年7期)2018-01-01
中国粮油学报(2017年9期)2017-11-03
