
一种面向不可靠网络的快速RDMA通信方法*
2015-03-09 06:51:08王绍刚徐炜遐庞征斌
湖南大学学报(自然科学版) 2015年8期
王绍刚,徐炜遐,吴 丹,庞征斌,夏 军
(国防科学技术大学 计算机学院, 湖南 长沙 410073)
一种面向不可靠网络的快速RDMA通信方法*
王绍刚†,徐炜遐,吴 丹,庞征斌,夏 军
(国防科学技术大学 计算机学院, 湖南 长沙 410073)
大数据量的远程内存访问(RDMA)传输是并行计算机中最基本的通信模式之一,对系统整体性能的影响很大.随着并行计算机系统的规模扩大,系统的容错性设计面临着很大的挑战,互连网络具有链路不可靠、自适应路由等特点,如何面向不可靠网络实现可靠的端到端RDMA传输是并行系统体系结构设计的一大难题.提出一种面向不可靠网络下的快速RDMA传输方法,方法能够在节点控制器芯片上高效实现,对上层驱动软件和应用提供可靠的端到端RDMA传输服务.与传统的建立连接的方法相比,方法的硬件设计复杂度大大降低;方法另一优点是实现了按需重传,避免了传统方法中一次RDMA传输出现错误时,需要重传整个RDMA数据的开销,在相同的错误概率下,新方法的传输效率得到了很大的提升.
远程内存访问;RDMA;MPI;滑动窗口
高性能并行计算机系统发展迅速,2013年11月份发布的Top500高性能计算机排行榜中,系统峰值性能已经达到50 P (Petaflops),处理核数达到数十万的规模.据此发展趋势,国际上高性能计算机计算水平将在2015年左右达到100 P量级,在2016年达到1 E (Exaflops)量级[1-4].如此大规模的系统需要支持数百万个节点的高效通信,节点间通信机制已成为制约系统性能乃至成败的关键因素.
并行计算机互连网络中,Serdes链路速率已达40Gbps[5-7],高速链路的误码率大大增加,给链路级的可靠传输带来了很大的挑战;随着网络规模的扩大,网络的平均故障时间越来越短,并行计算机的互连网络变得越来越“不可靠”.在这种条件下,并行计算机体系结构设计迫切需要进行对应的容错设计.
远程内存访问(RDMA)是并行机系统中最基本的通信模式之一[1,3],其他复杂的聚合通信也依赖基本的RDMA支持,在其基础上实现的并行软件运行库(MPI,PGAS等)是并行作业的基础,对作业的性能影响很大.在实现方案上,基于节点控制器硬件支持的RDMA操作是提高通信性能的有效方式,也是控制器设计中的难点.在高速互连网络环境下,如何实现可靠的端到端RDMA传输,需要有效解决报文到达乱序、链路层校验漏检、链路故障处理等问题.
硬件支持RDMA通信的现有方法包括文献[2-4,8]中的工作.总体来看,现有方法存在的主要问题是方法的可扩展性不高,在提高并行RDMA传输的数量时,硬件资源的开销增长较快;单报文出错的情况下,需要将整个RDMA报文完全重传,带来了不必要的开销.
针对现有方法的缺点,本文提出了面向不可靠网络快速RDMA通信的实现方法,方法可高效的实现在节点控制器中.本文针对底层互连网络的假设为:1)由于自适应路由、链路流量控制等原因,互连网络是乱序的;2)由于链路故障等原因,互连网络可能丢弃报文.
本文提出的面向不可靠网络的快速RDMA传输方法具有如下的创新点:
1)方法更易于在硬件中实现,具有很好的扩展性,在同等硬件资源的条件下,本文方法能够将节点控制器所支持的并行RDMA传输数量大大提升.
2)本文提出的方法最大限度地减少了数据重传,通过采用部分重传的方法,避免了现有方法在单报文出错或丢失时,需要将整个RDMA数据进行重传所带来的开销.
1 远程内存访问(RDMA)
1.1 概 念
远程内存访问(RDMA)是并行计算环境下基本的通信模式,在此基础上能够实现多种软件通信协议,如MPI,TCP/IP通信协议等[9].因而RDMA通信模式的效率对系统通信性能具有显著的影响.一次RDMA传输的基本操作是将发送方指定内存区域中的数据搬移到接收方指定的内存区域中,可以通过表1的参数进行描述.

表1 RDMA的参数化描述
1.2 现有方法分析
在现有的并行计算机系统中,如天河1[8],Infiniband控制器[9-10]等,节点控制器支持RDMA传输的方法主要是在数据传输之前,在发送方和接收方首先建立连接,建立连接的节点间可以进行RDMA数据的传输.在乱序互连网络中,并且有可能会产生丢包、错包的情况下,节点间在进行RDMA数据传输一般依赖接收方的计数器来检测一次RDMA传输的所有报文是否已经收全.如果目的方计数器超时,或者收到的报文校验出错时,现有方法一般要求发送方将整个RDMA数据重传一次.
在Cray系列超级计算机中[4],RDMA数据传输采用的是发送方滑动窗口的策略,该策略与链路层滑动窗口方案类似,即在发送方维护报文发送窗口,报文到达接收方后,要求接收方返回接收响应;发送方通过响应确定接收方已经成功接收报文,并在出错或超时的情况下重传发送方的报文.
通过分析可以看出,现有方法存在的主要缺点是:
1)对于链路出错导致的少量报文错误时(实际系统中常见的情况),现有方案要求重传整个RDMA数据,而实际上只有小部分数据才需要重传,导致大部分已经正确接收到的数据需要重传.
2)计数器的硬件资源消耗较大,导致芯片中并行RDMA传输数量受限,直接导致方案的可扩展性不好,这在大规模并行机中成为很严重的问题.
3)对于发送方滑动窗口的方案,由于方案要求接收方为每个数据报文返回一个响应报文,增加了互连网络的开销,并且加大了RDMA传输的延迟;此外,发送方的重传缓冲区的资源开销也很大,方案无法支持大容量的多路并行传输.
2 基于接收方滑动窗口的RDMA传输
鉴于传统RDMA实现方法存在的缺点,本文提出了基于接收方滑动窗口的RDMA实现方法,方法有效支持乱序传输的互连网络,并支持出错情况下的部分RDMA数据重传,有效提高了在不可靠网络环境下的数据传输效率.此外,方法的另一个有点硬件实现的资源开销较小,在同等的资源开销下,方法能够支持更多数目的RDMA并行传输.
2.1 基于节点控制器的RDMA实现思路
在基于滑动窗口的RDMA实现方法中,一次RDMA传输(以写操作为例)分为如图1所示的3步.
步骤1 发送方向接收方发送RDMA传输请求报文,接收方为其分配相应的接收资源,主要是保存在片内RAM的上下文接收资源.资源分配成功后,接收方向发送方发出响应,告知接收方上文标号(CID),通过CID可以从RAM中取出接收方上下文信息并处理.如果不成功,则接收方返回分配失败的响应,发送方接收到该响应后,将按照一定的策略延迟重试,直到连接建立成功.
步骤2 连接建立成功后,发送方向接收方发出RDMA写报文,其中每个报文中均携带接收方的接收上下文标号(CID).由于一次RDMA传输分解为多个RDMA写报文组成,每个RDMA写报文携带相应的序列号.例如,一个RDMA报文分解为4 096个写报文时,报文携带的序列号为0~4 095.通过报文序列号,可以计算出本报文所传输数据在内存中的起始地址(基地址+序号×单报文数据长度).
步骤3 接收方通过滑动窗口,将RDMA报文收集完全后,向发送方返回响应,通知发送方RDMA传输完成,发送方和接收方可以将RDMA传输连接撤销,相关资源可以释放重用.
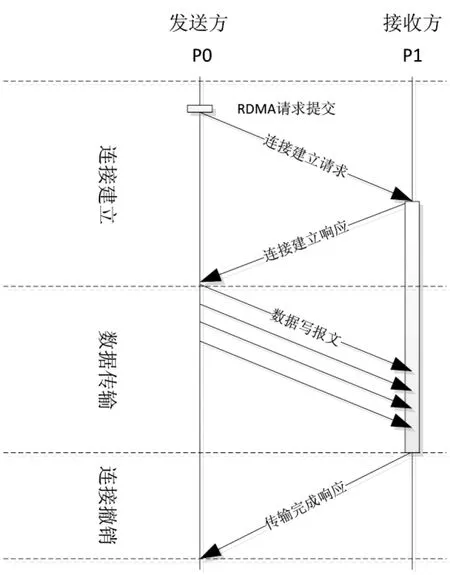
图1 基于滑动窗口的RDMA执行顺序
对于RDMA读来说,可以看作是接收方首先向发送方发出RDMA请求,由RDMA读的接收方发起RDMA写请求,因而在实现上也可以由RDMA写完成,本文中重点关注RDMA写传输的实现.
基于本文的方法,一次RDMA传输可能由多种类型的报文参与完成,报文所包含的位域和说明如表2所示.
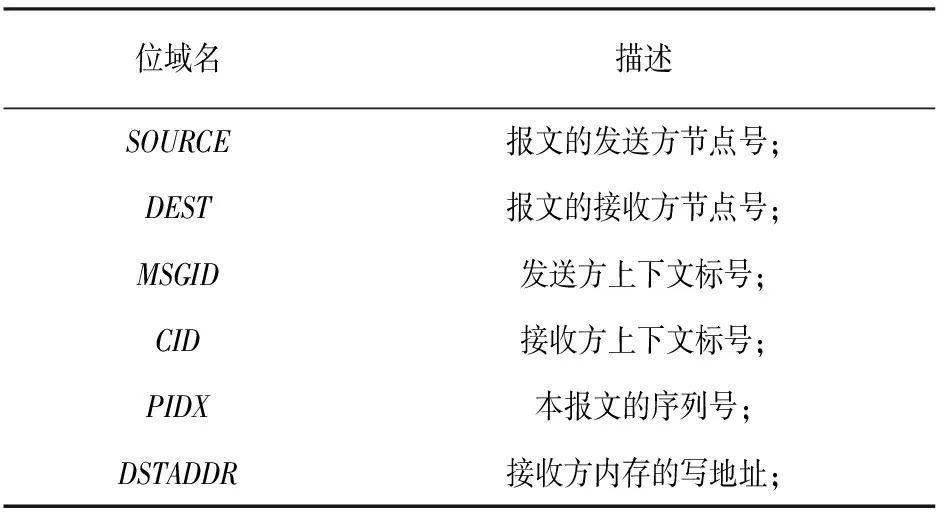
表2 主要报文位域说明
报文类型及说明如表3所示.

表3 RDMA传输参与报文类型
2.2 连接上下文格式
连接上下文是记录RDMA传输状态的表格数据结构,表格中每一个表项记录一次RDMA传输过程中的状态.在硬件实现上,上下文记录表主要保存在片内存储器中,上下文表项的个数是折衷性能和硬件资源而确定的.上下文表项的项数越多,则其他节点与该节点可以建立的连接数越多,因而系统中可以并发进行的RDMA传输越多,并发传输规模对大系统的可扩展性具有意义.
在本文提出的方法中,连接上下文包括发送端和接收端两部分,进行RDMA传输时,需要在发送端和接收端的连接上下文间建立连接,上下文表项的结构由表4所示.
2.3 RDMA传输流程
2.3.1 连接建立流程
建立连接的过程是在发送方和接收方的上下文中为本次RDMA传输分配资源.发送方的上下文资源在节点收到处理器发出的RDMA请求时分配,并向接收方节点发送连接请求RDMA_RQT报文,通知接收方节点分配接收上下文.
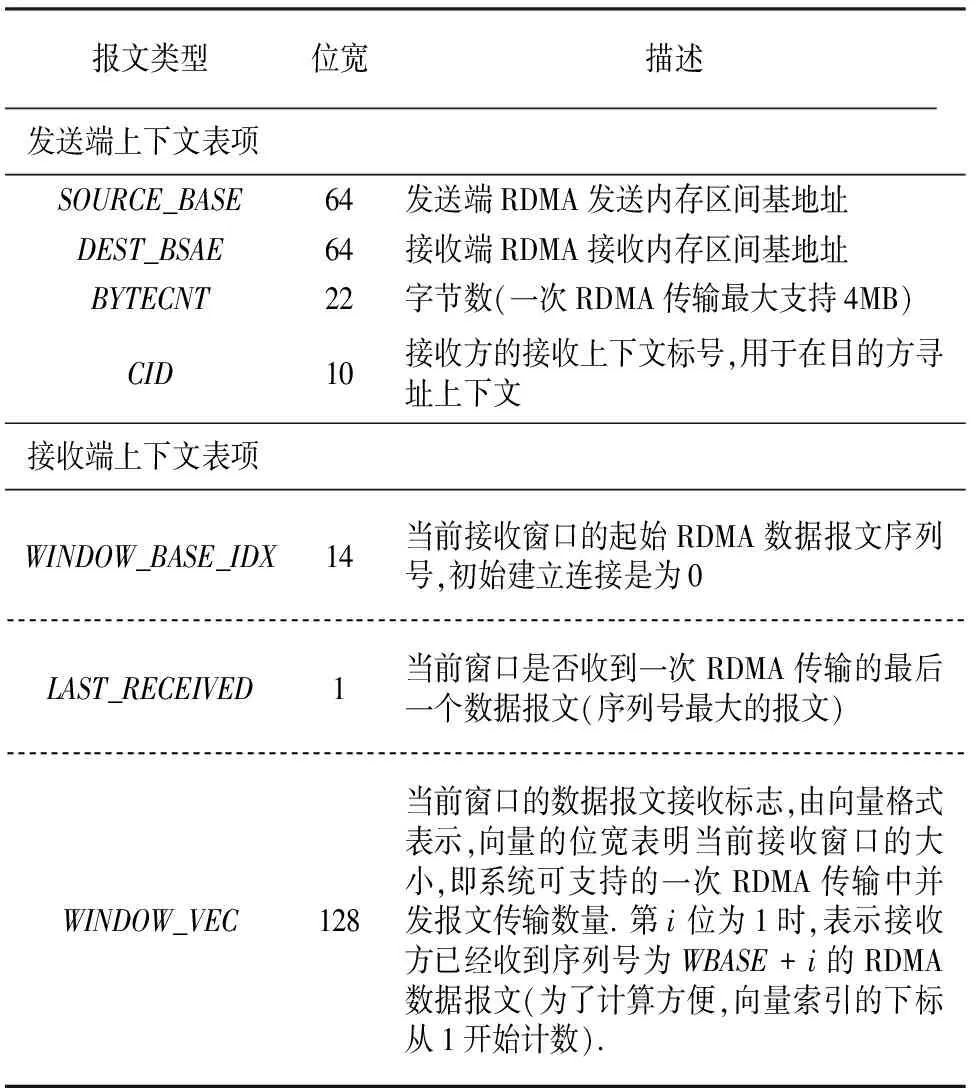
表4 RDMA连接上下文表项数据结构
接收方将分配的结果,即CID号,通过RDMA_RSP报文通知发送方.接收方无可用上下文资源而导致分配失败时,也通过RDMA_RSP报文告知发送方,发送方可按照策略(延迟重试等)重试.
2.3.2 正常数据传输流程
在高性能并行计算机中,互连网络由于链路带宽平衡、自适应路由等特性,网络经常是乱序的,即报文在发送端发送的顺序和报文在接收端接收的顺序不一致.互连网络的链路故障也会导致报文丢失.为了解决以上的问题,本文采用滑动窗口的方式支持上述的网络特性.
举例来说明数据的传输流程,假设发送方需要发送5个数据报文到接收方,报文的序列号分别为0至4, 由于网络乱序的原因,到达接收方时的顺序为2,1,0,4,3,接收方接收的流程如图2所示.
在接收上下文中,WBASE的含义是当前期望接收的数据报文的最小序列号,即序号之前的报文全部接收.在建立连接时,WBASE初始化为0,即RDMA报文序列中的第1个报文.接收标志向量表明的是WBASE序号之后的128个(假设标志向量的位宽为128位)数据报文是否已经收到,为了计算方便,向量的下标从1开始计数,如果WVEC的第i位为1,则表明序号为WBASE+i的报文已经被接收方成功接收.
如果接收方收到报文的序列号在接收窗口内,但不是最小的未接收报文的序列号,即:PIDX>WBASE,并且PIDX≤WBASE+128.在这种情况下,只需要将WVEC[PIDX-WBASE]置为1即可,表明已经收到了序号为PIDX的数据报文.即在向量WVEC中,索引下标为i的位为1时,表示收到了序号为WBASE+i的数据报文.
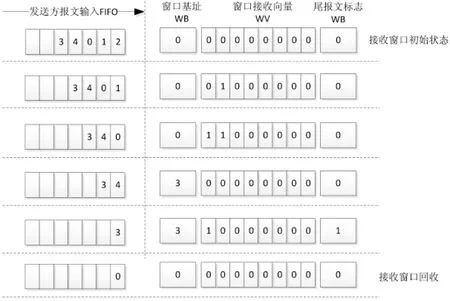
图2 基于窗口的目的方上下文处理
如果收到的报文等于WBASE,则表明收到了下一个最小序号的数据报文,在这种情况下,需要更新当前窗口的WBASE和WVEC.窗口WBASE需要更新为未接收报文中的下一个最小的序号,可以根据当前WBASE和WVEC的值计算得到:
WBASE=WBASE+LOC(WVEC).
WVEC的更新方法是:
WVEC=WVEC< 其中,LOC(WVEC)表示向量WVEC从最低位开始连续1的个数. 2.3.3 窗口外报文处理 在某些极端互连网络延迟情况下,有可能接收方收到的报文在窗口之外,即:PIDX PIDX PIDX>WBASE+128的情况是由于网络乱序,或某些极端情况下的重传引起的,此时,由于接收方的窗口还不能覆盖该报文的序号,接收方也将丢弃此类报文,由于接收方主存还未写入数据,因而接收方需要向发送方返回RDMA_RESEND报文,通知发送方重发该报文. 综上所述,接收方收到报文后的处理流程如图3所示.在算法描述中,假设窗口向量的位宽为128位,为了方便计算,下标从1开始计数. 2.3.4 异常数据传输流程 RDMA传输过程中可能出现的异常情况包括:接收方报文接收超时、接收到窗口范围之外的报文、僵尸报文处理. 1)接收方超时处理 基于本文提出的滑动窗口RDMA传输方法,接收方为上下文中WBASE所指示的数据报文建立超时机制,也就是滑动窗口中序列号最小的那个报文,因而每个窗口只需要一个超时计数器进行超时计数.如果当前滑动窗口最底部的报文超时,接收方将主动向发送方发出RDMA_RESEND报文,该报文中携带着当前WBASE指针,要求发送方重发序号为WBASE的报文.发送方收到RDMA_RESEND报文后,需要根据RDMA请求中,源方的基地址以及报文序号,从源方内存中重新读取该报文的数据. 如果接收方连续多次数据报文接收超时,可能的原因是网络中某条链路持续故障,导致大量数据报文丢包.在这种情况下,接收方可以要求发送方重发从WBASE索引号开始的所有数据报文.报文重发的类型(单报文重发,或多报文重发)可以由RDMA_RESEND报文中的标志位指定. 图3 接收方接收到报文时的窗口处理流程 2)僵尸报文处理 所谓僵尸报文,是指由于报文重传导致网络中出现重复报文,在网络严重阻塞的情况下,可能发送方和接收方的RDMA传输完成后(已经解除了连接),重复报文才到达接收方.更严重的情况是,重复报文到达接收方时,可能接收方上下文重新分配给其他RDMA传输,如果依据僵尸报文中的CID匹配接收方上下文,可能会导致当前的RDMA传输错误.RDMA传输协议需要正确辨别出僵尸报文,在接收方将其丢弃. 本文采用两种策略来判断僵尸报文: 1)在接收方上下文中,记录发送方上下文信息,包括发送方节点号、发送方上下文索引号、发送方RDMA传输标号(MSGID). 2) 发送方的MSGID用来进一步区分使用相同发送上下文的RDMA传输,MSGID的位数可以按实际系统网络情况确定,例如20位的MSGID出现重复的时间间隔已经足够长,可以有效区分网络中的僵尸报文. 针对本文提出的基于接收方滑动窗口的RDMA传输方法,我们采用SystemVerilog[11]建模语言实现了硬件传输引擎,并在VCS模拟器上针对多种系统规模和实现参数进行了仿真. 在模拟环境中,节点间通过3D-Torus模式进行互连,互连网络采用自适应路由的方式,为了增加网络报文乱序的力度,网络模型中随机加入了随机的报文延迟. 已有的RDMA传输方法主要有:发送方滑动窗口方案、接收方报文计数器方案.本文分别在硬件实现复杂度、传输延迟和不可靠链路条件下的传输性能等方面与本文提出的方案进行对比评测. 3.1 实现资源对比 对于给定的RDMA传输方案,其在硬件中的资源消耗情况对于系统的可扩展性有显著的影响,方案所需的硬件资源小,意味着在有限的芯片中,实现更多的连接资源.本文分析对比了三种RDMA实现方案的硬件资源消耗情况. 基于发送方滑动窗口的实现方案中,发送方将发送给接收方的报文首先保存在重传缓冲区中,由于缓冲区需要保存完整的报文,并且需要为每个接收方节点设置一个独立的重传缓冲区,因而这种方案中,源方的重传缓冲区的资源消耗量非常大. 基于接收方计数器的方案中,发送方不需要设置发送缓冲区,其主要的硬件开销来源于发送方和接收方上下文资源.该方案中,接收方上下文中需要保存的信息有:超时计数器、发送方上下文表项号、RDMA报文总数、当前已接收的RDMA报文数、重传索引号(为了在接收方区分重传报文与延迟到达的报文).可以看出,接收方计数器方案中,上下文中的计数器资源比较多,存储器开销比较大. 本文提出的接收方滑动窗口方案中,主要硬件开销也来源于上下文资源,但本文上下文资源的信息量比较少,主要包括以下信息:窗口基地址、窗口接收向量、超时计数器、末尾报文标志.此外,由于向量操作的逻辑比较简单,硬件组合逻辑和时序逻辑的开销也比较小. 3种方案的资源对比情况如表5所示. 表5 3种RDMA传输方案硬件实现开销对比 3.2 RDMA传输延迟评测 在本项延迟评测中,假设互连网络是理想的互连网络,即网络中没有错误报文,本文在模拟器上分别模拟了三种RDMA传输策略的延迟情况,RDMA数据的传输规模分别为32 K,64 K,128 K和256 K,RDMA传输的延迟如图4所示. 在三种方案中,基于发送方滑动窗口的延迟最大.主要原因是该方案需要接收方返回响应报文,其他两种方案在大部分情况下,接收方不需要向发送方返回响应报文.由于响应报文的存在,增加了网络负载,在网络比较拥塞的情况下,有可能会增大RDMA数据传输的延迟.此外,发送方滑动窗口的大小设置对延迟也有一定的影响,如果在滑动窗口的报文发送窗口内,接收方的响应报文未到达发送方,则发送发窗口报文的发送会产生停顿. 在无重传的情况下,本文方案的延迟基本与接收方计数器的方案相当,个别RDMA的延迟大于接收方计数方案,主要原因是由于网络中乱序的力度较大造成的,如果报文超出了接收方窗口的范围,本文的方案会导致发送方重传该报文,带来了一定的延迟开销. 在本文的方案中,接收方接收向量的长度设置应综合考虑网络行为和硬件资源开销设置,增加接收向量的长度,能够容忍更大力度的网络乱序行为,但会导致片上存储器资源的增加(增加了接收方上下文资源). RDMA传输容量 3.3 不可靠链路性能评测 在本项延迟评测中,假设互连网络是不可靠的互连网络,模拟时随机的丢弃网络中传输的RDMA数据报文.本文在模拟器上分别模拟了三种RDMA传输策略的延迟情况,RDMA数据的传输规模分别为32 K,64 K,128 K,256 K,RDMA传输的延迟如图5所示. RDMA传输容量 在相同的注错概率下,本文提出的方案的延迟要远远优于接收方计数器方案,主要的原因是采用了部分重传的策略,只重传出错的报文,并且在出错的概率较小的情况下,只是单报文的重传.而接收方计数器方案遇到了一个报文错误后,需要重传RDMA的全部数据,将带来非常大的延迟开销. 与发送方滑动窗口的方案相比,本文的方案的延迟也有明显的降低.主要的原因是,在单报文出错的情况下,发送方滑动窗口的方案将重传整个重传缓冲区中的报文,并且发送方在等待超时,将停顿后续数据报文的发送,这些策略都带来了较大的延迟开销. 随着注错概率的增加,本文的方案的低延迟优势更加明显,在实际系统中,如果链路层经常出现断开的情况,因而接收方计数的方案的性能将非常低. 3.4 网络错误力度对传输延迟的影响 在本项测试中,在网络模型中依次增加了随机丢包的概率,来测试网络错误力度对RDMA传输延迟的影响,测试网络丢包的概率为无丢包,1 ‰,2 ‰,3 ‰,4 ‰和5 ‰.256 K RDMA传输的延迟各种方案的下降概率如图6所示. 网络丢包概率/‰ 从测试结果可以看出,接收方滑动窗口对网络容错的能力最高.由于采用了丢失报文重传的机制,RDMA传输的性能下降幅度最小.而接收方计数方案的性能下降幅度最大,其原因是任何一次网络丢包,都将导致方案重传整个RDMA的数据.发送方滑动窗口的性能下降幅度居中,主要原因是响应报文的回传时间影响了整个RDMA传输的性能. 3.5 滑动窗口大小对性能的影响 基于本文提出的方案,接收方滑动窗口的大小选取主要取决于互联网络的乱序力度,滑动窗口大小的选取应能够使接收方收到的绝大部分数据报文包含在接收窗口内,因而能够避免数据报文的重传.对于乱序力度较低的路由策略,可适当选取较小的滑动窗口,而对于乱序力度较高的路由策略,应选择较大的滑动窗口. 为了测试滑动窗口大小对传输性能的影响,我们模拟了在某种乱序力度下各种窗口大小的延迟.在测试中,通过修改网络报文传输延迟的参数,得到一次模拟中最大接收方相邻两个数据报文的序号间隔来反映网络的乱序力度,图7给出了在相同大小的窗口下,乱序力度增大时,RDMA传输性能的下降比例. 网络丢包概率 从测试的结果来看,当网络传输的乱序力度小于窗口的大小时,RDMA传输的性能基本与顺序传输的性能相当,在这种配置条件下,接收方基本没有重传的现象发生.当网络传输的乱序力度大于窗口的大小时,RDMA传输的性能有了较明显的下降,例如乱序力度达到64时,如果滑动接收窗口的大小为32,则RDMA的传输性能为理想情况下性能的70%,而当滑动窗口的大小设为64时,传输性能可达到理想情况下的95%.以上模拟说明,在实际系统中,为了确保RDMA传输的性能,应根据网络的具体实现,选择适当的滑动窗口大小,以使大部分情况下,接收方收到的数据报文都落在滑动窗口范围内. 随着并行计算机高速互连网络性能的提升及网络规模的扩大,互连网络的平均无故障运行时间越来越短,迫切要求体系结构引入容错性设计.本文提出的基于接收方滑动窗口的RDMA传输方法,采用部分出错数据部分重传的策略,大大降低了现有方法的传输延迟,并且方法的实现简单,能够有效的实现在节点控制器(NIC)的硬件中,且方法有较好的可扩展性. [1] [EB/OL][2014-09-15]. http://www.top500.org [2] MIYAZAKI H, KUSANO Y, SHINJOU N,etal. Overview of the K computer system[J]. FUJITSU Scientific Technical Journal, 2012, 48(3): 255-265. [3] VENKATA M G, GRAHAM R L, LADD J,etal. Exploring the all-to-all collective optimization space with connectX CORE-Direct[C]//Proceedings of 41st International Conference on Parallel Processing (ICPP). New York: IEEE,2012:289-298. [4] FAANES G, BATAINEH A. Cray cascade: a scalable HPC system based on a dragonfly network[C]//International Conference for High Performance Computing, Networking, Storage and Analysis. Salt Lake City, USA:IEEE, 2012. [5] WEI Long-fei, JI Jin-yue, LIU Hai-qi,etal. A multi-rate SerDes transceiver for IEEE 1394b applications[C]// IEEE Asia-Pacific Conference on Circuits and Systems.Kaohsiung:IEEE,2012. [6] AZIZ P, HEALEY A, LIU CATHY,etal. SerDes design and modeling over 25+ Gb/s serial link[C]//44th International Symposium on Microelectronics. Long Beach, California, USA : IEEE, 2011. [7] NEDOVIC N, KRISTENSSON A, PARIKH S,etal. A 3 watt 39.8-44.6 Gb/s dual-mode SFI5.2 SerDes chip set in 65 nm CMOS[J]. IEEE Journal of Solid-State Circuits, 2010(45):2016-2029. [8] XIE Min, LUYu-tong, LIU Long,etal. Implementation and evaluation of network interface and message passing services for TianHe-1A supercomputer[C]//Proceedings of IEEE 19th Annual Symposium on High-Performance Interconnects (HOTI). New York: IEEE, 2011: 78-86. [9] TIPPARAJU V, GROPP W, RITZDORF H,etal. Investigating high performance RMA interfaces for the MPI-3 standard[C]//Proceedings of the 2009 International Conference on Parallel Processing (ICPP). Washington, DC: IEEE Computer Society, 2009: 293-300. [10]SONJA F. Hardware support for efficient packet processing[D].Columbus, Ohio: Ohio State University, 2012. [11]GANDHI M. SystemVerilog: The complete solution[J].Electronic Design, 2006(54) :22-27. A Fast RDMA Offload Method for Unreliable Interconnection Networks WANG Shao-gang†,XU Wei-xia,WU Dan,PANG Zheng-bin,XIA Jun (College of Computer, National Univ of Defense Technology, Changsha, Hunan 410073, China) Large data RDMA (Remote Data Memory Access) transport is the most commonly used parallel communication mode for parallel computers, which has great impact on the whole system performance. As the system size increases, the fault-tolerate architecture design faces new challenges. The interconnection network usually uses the adaptive routing mode and becomes more unreliable. This paper proposed a fast RDMA offload method for unreliable interconnection networks, which can be efficiently implemented on the NIC hardware and provides reliable RDMA communication for upper driver and programs. Compared with the traditional approaches, the hardware overhead is greatly reduced. Another benefit is that it can partially retransmit the fault data, which greatly reduces the whole RDMA delay. Simulation results show that the RDMA delay is greatly reduced, compared with the traditional methods. remote data memory access, RDMA, MPI, sliding window approach 1674-2974(2015)08-0100-08 2014-09-16 国家自然科学基金资助项目 (61202024,61202126),National Natural Science Foundation of China(61202024,61202126) 王绍刚(1979-),男,山东烟台人,国防科技大学博士 †通讯联系人,E-mail:wshaogang79@gmail.com TP302.1 A
3 性能评测

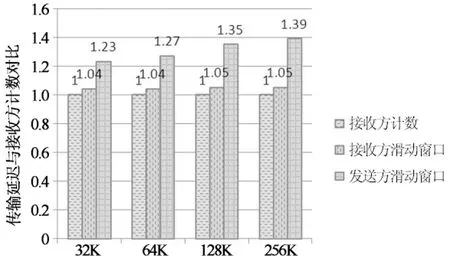
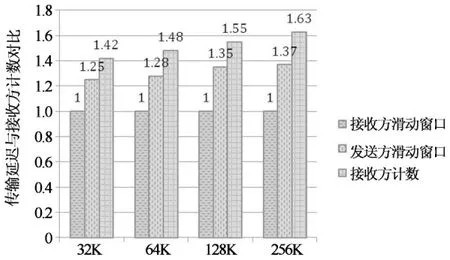
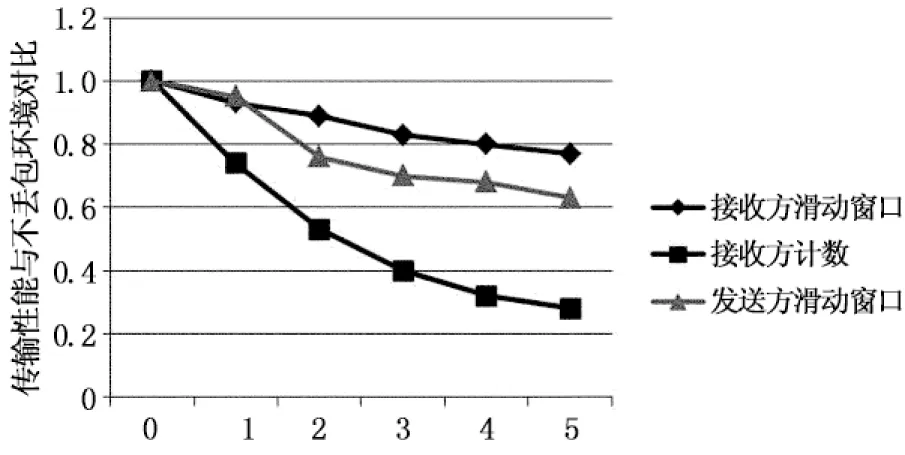
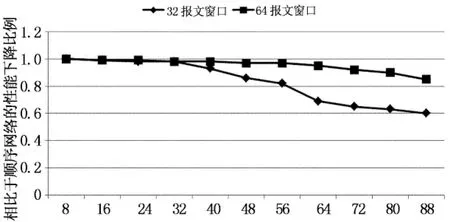
4 结 论
猜你喜欢
汽车电器(2022年9期)2022-11-07 02:16:24铁道通信信号(2020年4期)2020-09-21 09:15:24中国外汇(2019年11期)2019-08-27 02:06:30制造技术与机床(2018年11期)2018-11-23 01:08:02计算机与数字工程(2018年9期)2018-09-28 02:30:32意林(绘英语)(2018年1期)2018-04-28 01:21:42铁道通信信号(2016年8期)2016-06-01 12:10:21电子设计工程(2015年6期)2015-02-27 12:05:02城市轨道交通研究(2015年11期)2015-02-27 11:02:50雷达学报(2014年4期)2014-04-23 07:43:07
