
基于弹性分布数据集的海量空间数据密度聚类*
2015-03-09 06:50:43李璐明蒋新华廖律超
湖南大学学报(自然科学版) 2015年8期
李璐明,蒋新华,廖律超
(1. 中南大学 信息科学与工程学院,湖南 长沙 410075;2.长沙理工大学 特殊环境道路工程湖南省重点实验室,湖南 长沙 410004;3. 福建工程学院 福建省汽车电子与电驱动技术重点实验室,福建 福州 350108)
基于弹性分布数据集的海量空间数据密度聚类*
李璐明1,2†,蒋新华1,3,廖律超1,3
(1. 中南大学 信息科学与工程学院,湖南 长沙 410075;2.长沙理工大学 特殊环境道路工程湖南省重点实验室,湖南 长沙 410004;3. 福建工程学院 福建省汽车电子与电驱动技术重点实验室,福建 福州 350108)
为了快速挖掘大规模空间数据的聚集特性,在cluster_dp密度聚类算法基础上,提出了一种基于弹性分布数据集的并行密度聚类方法PClusterdp.首先,设计一种能平衡工作负载弹性分布数据集分区方法,根据数据在空间的分布情况,自动划分网格并分配数据,使得网格内数据量相对均衡,达到平衡运算节点负载的目的;接着,提出一种适用于并行计算的局部密度定义,并改进聚类中心的计算方式,解决了原始算法需要通过绘制决策图判断聚类中心对象的缺陷;最后,通过网格内及网格间聚簇合并等优化策略,实现了大规模空间数据的快速聚类处理.实验结果表明,借助Spark数据处理平台编程实现算法,本方法可以有效实现大规模空间数据的快速聚类,与传统的密度聚类方法相比具有较高的精确度与更好的系统处理性能.
空间数据;聚类算法;弹性分布式数据集;Spark
作为数据分析的重要手段之一,聚类分析在空间数据挖掘中扮演重要的角色.空间聚类分析将空间数据按其聚集特性分成若干聚簇,使得位于同一聚簇的数据具有较大的相似性,而位于不同聚簇的数据具有较大的差异性[1].根据不同的指导思想,可将聚类算法分为基于划分的聚类[2]、基于层次的聚类[3]、基于密度的聚类[4]、基于网格的聚类[5]以及基于特定模型的聚类[6].经典划分式算法k-means[7]与其改进算法k-medoids[8],k-means++[9],通过多次迭代来确定聚簇中心并将数据归类.算法实现简单,但对噪音敏感,对非球形的聚簇的处理效果较差.
层次聚类算法BIRCH[10]遵循自顶向下原则,将数据集分层并用树形结构表示.利用CF树作为索引,BIRCH在对数据进行压缩的同时,尽可能保留了数据的聚集特性并减小I/O操作.但CF树的构造策略将较大地影响运算效率,而压缩数据导致BIRCH算法不易发现稀疏数据间的相互关系,无法得到全局最优解.
密度聚类算法DBSCAN[11]通过计算数据对象间的距离,获取每个数据对象的邻域内邻居的聚集特性,根据邻域内的对象数目定义核心点、密度可达、密度相连等相关概念.进而,通过密度可达与密度相联过滤数据稀疏的区域,发现稠密点.基于DBSCAN算法的聚类质量较好,可以较好地避免“噪声”数据的干扰,发现任意形状的聚簇.但DBSCAN的效果依赖领域半径与最小核心点数的选择,算法调试困难.OPTICS[12]算法能减少输入参数对聚类结果的影响,对输入不敏感,其输出为包含聚簇信息的数据对象的排序,可从中提取出聚簇.由于需计算每对数据对象间的距离,密度聚类算法的效率较低.
网格聚类算法STING将原始聚类空间划分为若干相等大小的网格,通过统计分析获取网格特性,以网格为对象进行聚类.此方法可以大幅度降低计算量,获得较高的处理效率.但用网格代替数据对象本身,将会丧失部分数据对象的聚集特性,影响聚类结果的精确度.
经典聚类算法缺乏对聚簇中心的明确定义.针对该缺陷,Rodriguez等人提出了一种基于密度的聚簇中心的描述并设计cluster_dp[13]算法.算法计算空间数据对象的局部密度与最小高密度距离,两者皆高的数据对象即为聚簇中心.同时,算法比较局部密度与聚簇平均边界密度,将聚簇成员标记为核心成员(cluster core)与光晕(cluster halo).但算法尚未完全做到聚簇中心的自动判别,算法运行过程中需绘制决策图,靠人工经验辅助判断.
随着数据规模的激增,传统的聚类算法往往由于数据量过大而无法运行,迫切需要高速、有效、高伸缩的海量数据聚类算法.面向计算机集群GFS[14],BigTable[15]和MapReduce[16]技术为海量数据的聚类分析提供了思路.作为上述技术的开源实现,Hadoop并行计算框架在聚类分析领域被广泛应用[17].Lv对k-means进行改进,提出了基于Hadoop的Parallel K-means[18].Ferreira提出了一种基于Hadoop MapReduce的高纬度数据聚类分析方法[19].由于追求高吞吐量,基于HadoopMapReduce框架的并行聚类算法需要多次读写磁盘以存取中间结果,导致算法 I/O开销较大,具有较高的延迟,无法用于实时聚类.
为提高集群并行计算的效率,Matei Zaharia等人提出了弹性分布数据集(Resilient Distributed Dataset,RDD )抽象,并在RDD上扩展MapReduce编程接口,架构了通用大数据并行计算平台Spark[20].Spark具有高于Hadoop 近百倍的运算性能,能应对实时大规模空间数据的快速聚类分析.基于Spark框架,实现了分布式k-means II[21],但与传统k-means算法相同,算法无法发现非球形簇.
针对传统密度聚类算法无法分析海量、高维空间数据的缺陷,在算法cluster_dp的基础上提出一种基于弹性分布数据集的聚类方法PClusterdp.主要工作如下:
1) 提出基于自适应网格的RDD分区算法,用于平衡计算集群内工作节点的负载,减少计算等待时间,降低计算节点间通讯开销.
2) 改进局部密度的计算方式以适应并行计算,降低RDD分区内计算量,提高算法运行效率.
3) 构建辅助函数自动确定聚簇中心,消除聚类过程中的人工干预.
4) 设计聚簇合并算法归并局部聚类结果,消除RDD分区产生的影响,提高聚类分析结果的准确度.
1 问题描述与相关概念
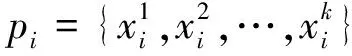
PClusterdp算法的实现基于如下基本概念.
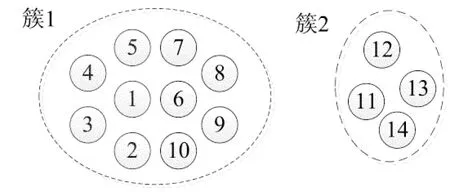
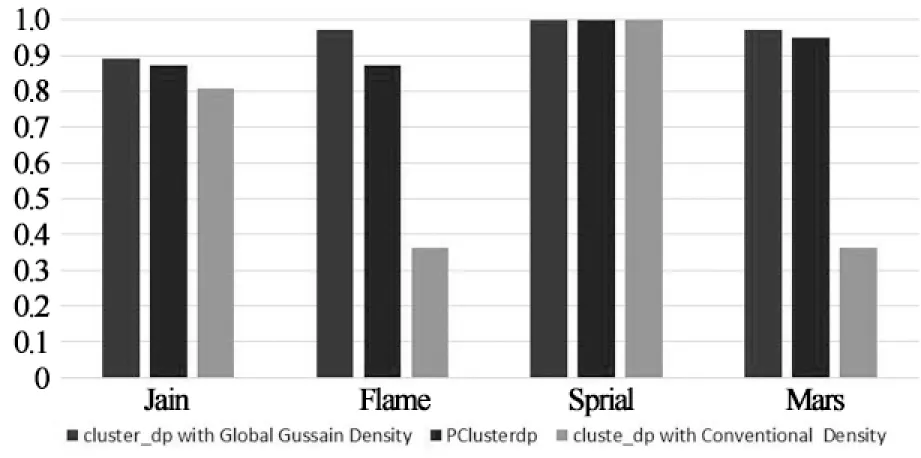
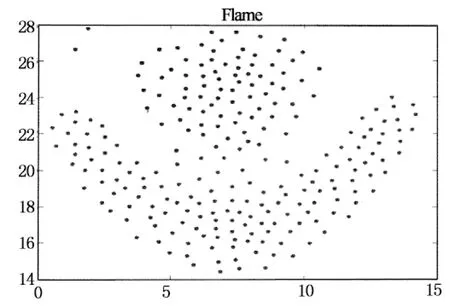
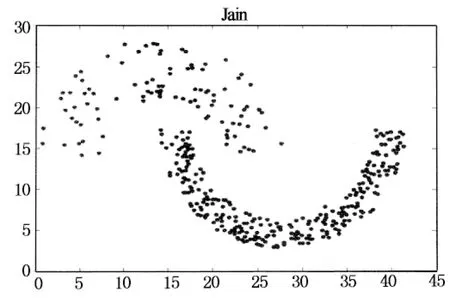
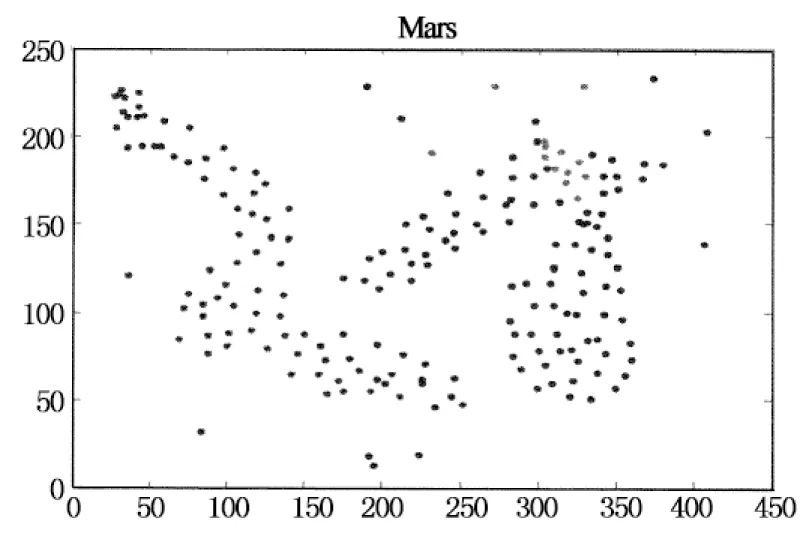
定义1(dc邻域):以给定数据对象pi为中心,其半径为dc内的k维空间称为pi的dc邻域.对dc邻域内的数据对象pj,有dist(pi,pj) 定义2 (局部密度ρi):pi的dc邻域内数据对象的数目称为pi的局部密度,记为ρi.有: (1) 定义3 (最小高密度距离δi):若pj是所有局部密度高于ρi的数据对象中距离pi最近对象,则称NN(pi)=pj为pi的最近高密度邻居.称δi=dist(pi,pj)为pi的最小高密度距离.有: (2) 2.1 弹性分布式数据集介绍 弹性分布式数据集的本质是一种只读的可并行记录集合.RDD基于内存计算设计,数据常驻内存, I/O 开销少.RDD自带分区列表,分区 (Partition) 分布在各计算节点的内存上,以实现并行.创建Key-Value 型RDD可控制数据的分区,优化计算过程.RDD自带两类API接口操作数据:转换 (Transformation) 在现有RDD基础上变化生成新的RDD;动作 (Action) 通过RDD来计算并反回结果[20]. 在cluster_dp算法的基础上,利用RDD模型设计密度聚类算法PClusterdp.借助集群并行,在保证准确率的前提下提高密度聚类算法的吞吐量和计算效率.算法的主要特点如下: 1) 准确性:算法有原始算法80%以上的准确率. 2) 高吞吐:并行集群能处理千万级以上数据. 3) 高效率:算法效率较原始算法有数倍提升. 2.2 PClusterdp总体框架 PClusterdp利用RDD存储数据,基于“RDD分区-区内并行计算-合并局部结果”思想设计,借助分割S实现RDD分区与并行.算法总体框架如表1所示: 表1 PClusterdp算法 映射数据对象到分割后的空间网格G,生成基于网格编号的Key-Value RDD.利用MapPartition接口,根据网格编号划分RDD,分配同区的数据对象到相同计算节点.各节点独立运行密度聚类算法得到基于网格分区的局部簇.随后,合并相邻网格中局部簇,生成最终聚类结果. 2.3 基于数据对象数目的RDD分区算法 PClusterdp算法借助分割计算空间实现RDD分区.传统的空间分割算法通常将计算空间划分为大小均匀的网格.然而,在聚类分析中,数据对象在计算空间中呈现不均匀分布.基于均匀网格的RDD分区策略将导致分区内数据量差异大,使得计算节点负载失衡,影响计算效率.为平衡各计算节点的负载,避免数据丢失,并使RDD的分区过程可控,PClusterdp采用一种基于数据对象数目的空间划分策略.算法引入空间网格索引,保证网格内数据量相对均衡.RDD依照网格编号分区并分配数据到计算节点,可平衡各计算节点的负载,提高算法的效率.为说明空间划分原理,设网格中数据对象的数目上限为10,基于数据对象数目的空间划分结果如图1所示. 图1 基于对象数目的空间划分示意图 得到各层网格的基本信息后,统计各层网格内数据对象的数目.统计算法采用Map-Reduce思想设计以提高运算速度.广播索引结构并均分待聚类数据对象到各计算节点.各节点各自统计网格内的数据.然后归并网格内数据量信息.具体空间划分算法如表2所示. 表2 空间划分算法 得到完整索引结构后,遍历索引,查找数据量小于给定值的最大网格,一旦找到则停止继续往下遍历,得到空间划分的结果.据此结果映射数据对象,生成基于网格编号的Key-Value RDD.利用Key-Value RDD的MapPartitionWithIndex函数接口,自动生成基于网格RDD分区. 2.4 改进的分区内聚类算法 RDD分区后,在各分区上并行地运行cluster_dp算法,得出基于网格分区的局部簇.在此修改cluster_dp算法,使其能适应并行计算.算法细节如表3所示: 表3 改进cluster_dp算法 2.4.1 改进的的局部密度定义 局部密度的计算方法决定了聚类的效果, cluster_dp算法利用局部定义与最小高密度距离判断聚簇中心.数据对象的局部密度差异越大,越能捕捉聚簇中心对象的特性,聚类效果越好.公式(1)为局部密度原始定义,该定义仅考虑数据对象dc邻域内的数据量,导致多数数据对象具有相同的局部密度,从而影响最小高密度距离的计算,影响聚簇中心对象的判断.文献[13]提供了一种基于高斯核函数的局部密度定义,使用该定义计算局部密度需要遍历整个数据集,不适用于并行计算.为平衡运算速度与计算结果精度,实现并行计算,定义如下改进的局部密度计算方式. (3) 公式(3)在公式(1)的基础上考虑了邻域内数据对象的紧凑程度.对于dc邻域内拥有相同邻居数的数据对象,通过计算数据对象与其邻居间的距离扩大局部密度的差异.可以认为,在dc邻域范围内的邻居数相同情况下,与其邻居之结合越紧密的数据对象拥有越大的局部密度. 图2 局部密度差异示意 2.4.2 改进的聚簇中心确定策略 原始cluster_dp在确定聚簇中心时,需绘制决策图,并通过人机交互进行判断.为摆脱算法对决策图的依赖和人为干预,设计辅助函数γ自动判定聚簇中心. 已知数据对象的局部密度为ρi,其最小高密度距离为δi,则设: (4) 其中,max(ρ)*max(δ)为网格内最大局部密度与最小高密度值的乘积.由于局部密度与最小高密度距离具有不同的尺度,因此借助网格内局部密度与最小高密度距离的最大值进行简单归一化操作.将γi限定在 [0,1]后,将其降序排列,其结果如图3所示. Point 可以看出非聚簇中心对象γ趋近0,聚簇中心对象的γ值离散分布且远离原点.由此,可通过预设阀值确定聚簇的中心候选对象.预设值的选取依赖实际应用环境,选择γ>0.2的数据对象作为聚簇中心候选对象生成局部簇,可得到较为理想的聚类结果.得到聚簇中心候选对象后,即可确定聚簇的数目,进而将网格内数据归类到对应的局部簇中. 2.5 局部聚簇的合并策略 生成分区内局部簇后,需对局部簇的成员进行合并与调整,得到全局聚类结果.局部簇合并分为如下两种情况: 2.5.1 分区内聚簇合并策略 改进后的局部密度定义虽在一定程度上提高了局部密度的差异性,然而局部密度相等的情况无法完全避免,特殊情况下聚类结果仍将产生偏差. 如图4所示,簇1中数据对象均匀且对称分布.其中,两邻近数据对象1和6拥有相同的局部密度.根据聚类中心的选择方法数据对象1和数据对象6可能同时被认定为聚类中心,从而导致一个簇被拆分成两个.分区内聚簇合并用来解决上述问题,如果两聚簇中心之间的距离小于预设阀值ε,则合并两个聚簇中心所对应的簇. 图4 网格内合并示意图 2.5.2 分区间聚簇合并策略 每个RDD分区对应一空间网格,对于靠近网格边界的数据对象,需要在相邻网格之间再次评估其聚集特性,避免由于划分RDD造成的归类错误.原始算法通过计算两个簇间的平均局部密度,将聚簇成员标记为核心成员(clustercore)与光晕(clusterhalo) .其中,核心成员为聚簇的中心部分,由高密度点组成,是稳定的数据对象聚集;而光晕对应聚簇外围,包含低密度数据点,是聚簇的非稳定部分数据的聚集.利用核心与光晕的概念,提出网格间聚簇的合并方法.如果邻接网格中靠近网格边界的数据对象分布存在如下情况,则需调整数据对象所属聚簇. 情况1 相邻网格中近边界处存在聚簇核心对象,并且核心对象相互靠近.如图5所示,数据对象1与6是两个簇的核心对象,且其距离小于ε.由于网格的存在,将原本应归为同一聚簇的数据对象分配到了不同的聚簇中.此情况下合并两个聚簇. 情况2 两邻接网格的边界处存在光晕对象.此时需重新评估光晕点所归属的聚簇.如图6所示,光晕对象6离g1网格内的聚簇c1较近,此时应调整数据对象6所属聚簇.具体调整算法如表4示. 图5 合并跨网格的聚簇 图6 调整光晕对象所属聚簇 在光晕对象所在网格的邻接网格中查找密度高于光晕对象的数据对象,并计算满足条件的数据对象到光晕点的距离.若计算得出的最小距离小于当前光晕对象的最小高密度距离,则更新光晕点的最近高密度邻居与最小高密度距离,并根据更新后的最近高密度邻居将光晕对象分配到新的聚簇中. 表4 光晕对象聚簇Id调整算法 3.1 实验环境搭建 为了进行对比测试,将测试平台分成伪集群测试平台与真小型集群测试平台两部分.前者基于小型工作站搭建,其配置为:Intel(R) Core(TM) i5-3470 3.2GHz 4核CPU,1TB硬盘,4GB内存.在平台上搭建Spark V 1.1.0伪集群,可模拟4个计算节点. 后者由20台测试机组成,各服务器硬件配置为:Inter(R) Xeon(R) CPU E5-2650 V2 2.6GHz,内存8G,硬盘200G,网络带宽1000Mbps.机群搭载Spark V 1.1.0.两平台上运行相同的PClusterdp算法,代码采用Scala语言编写. 3.2 实验内容与结果分析 3.2.1 准确率对比测试 准确率对比测试在伪集群测试平台上进行.测试数据集选用标准密度聚类测试数据集:Mars,Flame,Spiral[22-24]与Jain[25].测试比对PClusterdp算法与传统cluster_dp算法的聚类效果.原始cluster_dp算法分别采用传统密度定义即公式(1)与全局高斯核公式计算局部密度并判定聚类中心.PClusterdp算法采用公式(3)配合公式(4)判定聚类中心.设被正确归类的数据对象数目为Cr,实验使用如下评价函数评价聚类效果: (5) 算法的聚类准确率比对结果如图7所示: 图7 算法准确率对比 PClusterdp算法具体聚类效果如图8所示: (a) (b) (c) (d) 3.2.2 效率对比测试 效率测试对比cluster_dp算法与PClusterdp算法处理海量数据集所需时间.实验从福州市2014年12月16日运营车辆1.2亿条定位数据中分别抽取1万,10万,100万,1000万,1亿个数据对象,分成4组进行对比测试.其所消耗的时间如图9所示: 图9 并行算法效率对比图 3.2.3 实验结果分析 准确率测试结果表明,使用全局高斯核密度的cluster_dp算法具有最高的准确率.PClusterdp算法使用的基于邻域半径的高斯核局部密度定义,综合考虑领域范围内数据点数目与领域范围内数据点距离.配合网格内聚簇合并策略,PClusterdp算法能够较好地把握数据的聚集特征.经多个数据集测试,PClusterdp算法的评价函数值均达到85%以上,说明算法的聚类中心确定策略配合改进的局部密度定义使用是可行的,算法具备一定的鲁棒性.由聚类效果图可以看出,PClusterdp算法可以发现任何形状的簇.而使用传统密度定义(公式1)的cluster_dp算法,计算出的局部密度差异度较小,导致聚类的精确度最低,且不同数据集使用之间差异较大,鲁棒性较差. cluster_dp算法需遍历整个数据集计算数据对象的局部密度,算法时间复杂度为O(n2).PClusterdp算法通过空间网格减少局部密度的计算量,计算密度时仅需遍历对象所在网格分区及其相邻的8个网格分区内的数据.设单个网格分区内数据量为m,PClusterdp算法的时间复杂度为O(81*m2),由于m远小于n,PClusterdp算法的时间复杂度大幅降低.由算法效率对比测试结果看出,原始cluster_dp算法无需分割数据集,在数据集规模小时花费时间少.但当数据规模增长时,cluster_dp算法花费时间呈指数集上升,数据规模上亿时,使用cluster_dp算法聚类需花费数小时,算法伸缩性差.PClusterdp算法在分割数据集与集群通讯上需花费少量时间,数据规模较小时,算法效率不及原始cluster_dp算法.但当数据集规模上升时,PClusterdp算法时间的增长相对平缓,算法的可伸缩性较强.能在30min内处理上亿条数据,PClusterdp算法具备一定的吞吐量,基本能满足实时计算的要求. 针对传统密度聚类算法效率不高、伸缩性不强无法适用于海量、高维数据的特点.提出了一种基于cluster_dp算法的改进分布式密度聚类算法PClusterdp.算法重新定义了局部密度的计算方式,通过设计基于局部密度与最小距离的函数的辅助分析函数,解决了原始算法需依靠决策图人工干预聚类中心问题.改进后的算法能够自动计算聚类中心并发现任意形状的聚簇.该算法还引入空间网格和弹性可分布数据集对待处理数据进行分区,利用Spark实现了算法的并行处理,使传统的聚类分析算法能够适用于海量、高维数据的分析处理. 实验结果表明,该算法具有较强的鲁棒性,能适用于不同类型的数据集.算法的聚类结果较为稳定,能够有效揭示数据聚集模式.同时,算法具有较强的伸缩性,可应用于海量数据的挖掘分析. [1]HANJ,KAMBERM,PEIJ.Datamining:conceptsandtechniques[M].ThirdEdition.Singapore:ElsevierPteLtd, 2012. [2]TVRDIKJ,KÏIVI.Differentialevolutionwithcompetingstrategiesappliedtopartitionalclustering[J].SwarmandEvolutionaryComputation, 2012, 7269(4): 136-144. [3]CARVALHO,AXY,ALBUQUERQUEP,etal. Spatial hierarchical clustering [J]. Revista Brasileira de Biometria, 2009, 27(3): 411-442. [4] SANDER J, ESTER M, HANS P,etal. Density-based clustering in spatial databases: The algorithm gdbscan and its applications [J]. Data Mining and Knowledge Discovery, 1998, 2(2): 169-194. [5] WANG S, CHEN Y. HASTA: A Hierarchical-grid clustering algorithm with data field [J]. International Journal of Data Warehousing and Mining, 2014, 10 (2): 39-54. [6] BOUVEYRON C C, BRUNET-SAUMARD. Model-based clustering of high-dimensional data: a review [J]. Computational Statistics & Data Analysis, 2014, 71 (6): 52-78. [7] KIRI W, CLAIREl C, SETH R,etal. Constrained k-means clustering with background knowledge [C]//Proceedings of the Eighteenth International Conference on Machine Learning. USA, 2001: 577-584. [8] PARK HAE-SANG, CHI-HYUCK JUN. A simple and fast algorithm for K-medoids clustering [J]. Expert Systems with Applications, 2009, 36 (2): 3336-3341. [9] ARTHUR D, SERGEI V. k-means++: The advantages of careful seeding [C]//Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms. USA, 2007: 1027-1035. [10]ZHANG Tian, RAGHU R, MIRON L. BIRCH: A new data clustering algorithm and its applications [J]. Data Mining and Knowledge Discovery, 1997, 1 (2): 141-182. [11]ESTER, MARTIN,etal. A density-based algorithm for discovering clusters in large spatial databases with noise [C]//Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96). USA, 1996: 226-231. [12]ANKERST M,etal. Optics: ordering points to identify the clustering structure [C]//SIGMOD '99 Proceedings of the 1999 ACM SIGMOD international conference on Management of data. USA, 1999: 49-60. [13]RODRIGUEZ A, ALESSANDRO L. Clustering by fast search and find of density peaks [J]. Science, 2014, 334 (6191): 1492-1496. [14]GHEMAWAT S, GOBIOFF H, LEUNG S.-T. The Google file system [C]//SOSP '03 Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles. USA, 2003: 29-43. [15]FAY C, JEFFERY D, SANJAY G,etal. Bigtable: a distributed storage system for structured data [J]. ACM Transactions on Computer Systems, 2008, 26(2): 4-18. [16]LEE D, J.-S K, SEUNGRYOUL M, Large-scale incremental processing with MapReduce [J]. Future Generation Computer Systems, 2014, 36(6): 66-79. [17]SHVACHKO K, HAIRONG K, RADIA S,etal. The hadoop distributed file system[C]//Mass Storage Systems and Technologies (MSST). USA, 2010: 1-10. [18]LV Z, HU Y, ZHONG H,etal. Parallel PK-means clustering of remote sensing images based on MapReduce [J]. Web Information Systems and Mining, 2012, 6318 (2010): 139-142. [19]ROBSON L F, CORDEIRO, CAETANO T J,etal. Clustering very large multi-dimensional datasets with MapReduce[C]//KDD '11 Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. USA, 2011: 690-698. [20]ZAHARIA M, CHOWDHURY M, DAS T,etal. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing [C]//NSDI'12 Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation. USA, 2012: 2. [21]BAHMANI B, MOSELEY B, VATTANI A,etal. Scalable k-means++ [J]. Proceedings of the VLDB Endowment, 2012, 5(7): 622-633. [22]GIONIS A, MANNILA H, TSAPARAS P. Clustering aggregation [J]. ACM Transactions on Knowledge Discovery from Data, 2007, 1 (1): 4. [23]FU L, MEDICO E. FLAME. A novel fuzzy clustering method for the analysis of DNA microarray data [J]. BMC Bioinformatics, 2007, 8(1): 3. [24]CHANG H, YEUNG D.-Y. Robust path-based spectral clustering [J]. Pattern Recognition, 2008, 41(1): 191-203. [25]DUBES R, JAIN A K. Clustering techniques: the user's dilemma [J]. Pattern Recognition, 1976, 8(4): 247-260. Density Based Clustering on Large Scale Spatial Data Using Resilient Distributed Dataset LI Lu-ming1, 2, JIANG Xin-hua1, 3, LIAO Lyu-chao1, 3 (1.School of Information Science and Engineering, Central-South Univ, Changsha,Hunan 410075, China;2.Hunan Key Laboratory for Special Road Environment, Changsha Univ of Science and Technology, Changsha,Hunan 410004,China;3.Fujian Key Laboratory for Automotive Electronics and Electric Drive , Fujian Univ of Technology, Fuzhou,Fujian 350108,China) This paper proposed a density based parallel clustering algorithm to mine the feature of large scale spatial data. The proposed PClusterdp algorithm is based on the cluster-dp algorithm. First, we introduced a data object count based RDD partition algorithm for balancing the working load of each compute node in computing cluster. Second, we redefined the local density for each data point to suit the parallel computing. Meanwhile, in order to get rid of original algorithm's decision graph, we proposed a method to automatically determine the center point for each cluster. Finally, we discussed the cluster merge stratagem to combine the partially clustered data together to generate the final clustering result. We implemented our Resilient Distributed Dataset (RDD) based algorithm on Spark. The experiment result shows that the proposed algorithm can cluster large scale spatial data effectively, and meanwhile, the method has better performance than the traditional density clustering methods and can achieve the rapid clustering of massive spatial data. spatial data; clustering algorithm; resilient distributed dataset; Spark 1674-2974(2015)08-0116-09 2015-02-01 国家自然科学基金资助项目(61304199),National Natural Science Foundation of China(61304199) ;长沙理工大学特殊道路工程湖南省重点实验室开发基金资助项目 李璐明(1986-),女,湖南长沙人,中南大学博士研究生 †通讯联系人,E-mail:liluming@csu.edu.cn TP301.6 A

2 PClusterdp算法设计与实现


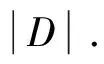







3 实验及结果分析


4 结 论
猜你喜欢
作文成功之路·作文交响乐(2023年2期)2023-07-13 02:34:42
环球时报(2022-03-29)2022-03-29 17:14:11
知识经济·中国直销(2018年7期)2018-07-27 02:49:52
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
计算机与网络(2015年8期)2015-12-27 07:37:41
电测与仪表(2015年8期)2015-04-09 11:50:16
电测与仪表(2015年7期)2015-04-09 11:40:16
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
