
一种环形网络的可扩展流水仲裁器设计*
2015-03-09 06:46:15任秀江施晶晶谢向辉
湖南大学学报(自然科学版) 2015年8期
任秀江,施晶晶,谢向辉
(江南计算技术研究所, 江苏 无锡 214083)
一种环形网络的可扩展流水仲裁器设计*
任秀江†,施晶晶,谢向辉
(江南计算技术研究所, 江苏 无锡 214083)
对环形网络的仲裁器结构进行研究,提出了一种可扩展流水仲裁器结构,能够同时完成通信缓冲和通信链路的分配.对14个通信节点互连进行了建模模拟,各节点命中数量差值小于5%,该结构仲裁器具有较好的仲裁公平性;然后采用Chartered 65 nm工艺对RTL设计进行了时序综合实验,关键通路延迟比同等规模的全交叉开关结构降低36.8%;同时该仲裁结构中的仲裁核心逻辑时序受互连规模变化影响较小,具有一定的可扩展性.
仲裁器;片上互连;环形网络;可扩展设计
随着微处理器体系结构的发展和VLSI工艺水平的持续进步,设计人员可以将更多的功能模块集成到单个芯片中,多核结构已经成为微处理器发展的方向.与传统的单核处理器相比,多核系统的片上通信机制变得更加复杂,对片上互连结构的要求也越来越高;另一方面,随着工艺的不断进步和片上芯片数量的不断扩大,片上通信的线延迟正逐渐成为片上互连设计实现时需要考虑的重要因素.
片上网络技术[1-3]能够提供灵活扩展的互连架构,但额外的路由器设计不仅引入了新的功耗和面积开销[4-6],路由算法、通信协议等设计更大大增加了片上互连的设计复杂度[7],尤其在片上通信节点数有限的芯片中,片上网络设计的性价比不高.传统的互连结构,如基于总线的结构或者全交叉开关结构,具有结构简单、易实现的特点,但可扩展性受限.环形网络是一种改进的多段总线互连结构,分段的互连线结构易于高频实现和互连规模的扩大,仲裁器设计对发挥环形网络的可扩展性具有重要影响.
本文对环形网络的仲裁器结构进行研究,提出了一种阻塞式可扩展流水仲裁器结构,能够较为公平地完成请求仲裁和链路分配,并且仲裁核心的逻辑长度受网络规模影响小,能够应用于不同通信节点数量的环形网络设计中,具有一定的可扩展性.
1 相关研究
1.1 环形网络互连结构
早期的片上互连结构中通信节点之间由物理介质直接互连,通信数据直接在源、目的之间传输,没有通过第三方设备.这种基于直接连接的互连结构具有结构简单、易于实现的特点.比较有代表性结构有总线结构、交叉开关结构.
总线是应用最早、最传统的互连结构,如:ARM的AMBA[8],IBM的CoreConnect[9],Silicore的Wishbone,均为总线结构.总线结构中所有设备共享物理介质,因此无法在同一时刻支持一对以上设备通信,通信带宽受限;并且随着片上通信距离的增大,全局连线延迟往往可以达到若干个时钟周期,对总线结构直接的影响是传输效率的进一步降低.
交叉开关(Crossbar)是在总线之后发展起来的常用互连结构[10],国内外多款多核处理器中均采用交叉开关结构互连,如:Sun公司的UltraSPARC多核处理器[11]、IBM公司POWER系列多核处理器[12].交叉开关在每一对通信节点间提供独立的物理互连,能够克服带宽限制问题,可以实现尽可能多的并发通信,通信效率高.但交叉开关的连线资源开销与节点数成比例增加,节点数增多会导致通信端口的连线数量剧增、线负载增大,不利于后端设计实现,不利于互连规模扩展.
环形网络中也是通过共用物理链路实现互连的,与总线结构不同的是,通信节点将物理连线分成多段,段间有寄存器站台隔开,有利于实现高频设计.不重合的段与段之间可以独立使用,能够提供较高的聚合通信带宽.环形网络中连线规整,易于同时实现多套物理连线,降低片上通信的冲突性.例如,IBM研制的CELL处理器[13]中实现了4套环形网络来降低通信冲突、提高聚合通信带宽.设置不同方向的环形网络,可以将网络直径减少为网络规模的一半.
环形网络是对总线结构和交叉开关结构的折中,因此环形网络同时具有总线结构易于实现和交叉开关聚合带宽高的优点.同时,环形网络中的互连通过分段的总线连接,节点数增加对网络实现的影响小,并且由于连线规整,易于后端实现.但环形网络有些非相邻节点的通信会存在通信链路竞争的问题,如何做好环形网络中各段链路的分配工作,对发挥环形网络聚合通信带宽、提高通信效率具有重要意义.
1.2 NoC片上网络
为解决大规模多核SoC中的全局通信问题,基于路由转发的互连结构——片上网络(NoC:Network on Chip)成为近些年学术界研究的热点[1-3].借鉴于分布式计算网络,片上网络NoC中通过路由器将分布在芯片上的计算资源连接起来,路由器负责转发各设备之间的通信信息,有效地实现了计算与通信的分离.
NoC概念从被提出之后就受到广泛关注,并有多个处理器采用了NoC作为互连结构,影响比较大的有:麻省理工的RAW处理器[14],Intel的TeraFLOPS处理器[4,15-16],Tilera公司的Tile64处理器[5,17-18]等.基于路由转发的片上网络具有很好的扩展性,也引入了众多新问题,如NoC拓扑结构、路由算法选择、流量控制等与片外网络有着很大不同,这些都大大增加了片上互连的设计复杂度.
NoC中路由器的引入进一步加剧了片上的功耗、面积开销.文献[19]中介绍在Teraflops和RAW原型芯片中NoC所占功耗比重分别为30%和40%.文献[4,19]中对路由器的功耗分布进行了分析,缓冲功耗比例达22%;文献[20]分析RAW和TRIPS处理器中输入缓冲所占功耗分别达到了31%和35%.在面积开销方面,Teraflops芯片中路由器面积占瓦片面积的17%[4],其中大部分面积均为输入或输出端口中的缓冲;TILE64处理器的片上网络中缓冲占到60%[5],TRIPS处理器中输入缓冲占到路由器面积的75%以上[6].
1.3 仲裁机制研究
仲裁器是互连结构中的核心部件,它负责在相互冲突的通信请求之间做出选择,在源和目标之间建立通信.例如:在总线中,仲裁器需要对不同设备同时提交的请求进行选择,决定不同请求对总线的占用,保证不同设备对总线的串行时间使用;在路由器中,仲裁器的功能更加复杂,不仅需要对目标方向相同的多个通信请求进行选择,还需要根据目标坐标为通信请求选择合适的传输方向.
除了解决通信冲突,公平性和效率也是评价一个仲裁器的重要指标.公平性是指仲裁器需要保证各个通信设备之间能够几率均等地使用通信资源,不允许有饥饿的情况发生,比较典型的仲裁机制有轮转仲裁[21]、堆栈仲裁等.在一些特殊的情况下,也会使用有优先级的仲裁设计,比如固定优先级仲裁[22].效率是指仲裁器需要最大化通信资源的使用率,有通信请求的情况下,尽可能地使不冲突的通信请求能够并发处理,努力减少通信资源的空闲时间.
当通信设备增多、仲裁规模扩大后,仲裁逻辑往往会成为电路的关键路径,尤其是在高频设计中.这种情况下通常会使用分级仲裁,同时收到的多个请求先进行分组仲裁,经过分组后的结果再进行最终仲裁.在分级仲裁结构中,选择仲裁机制时需要注意避免饥饿情况的发生,比如多级的轮转仲裁结构中极易发生饥饿[23,24].为解决轮转仲裁中的饥饿问题,引入了超时机制和固定优先级仲裁,即为每个请求的等待时间进行计数,如果等待时间超过某一阈值,则提高该超时请求的仲裁等级.超时机制的引入,能够解决饥饿问题,但对互连结构的通信效率有所影响.
随着片上通信规模的增多,仲裁器需要在时序、公平、效率等方面均衡考虑,这是仲裁器设计的重点.例如,CELL处理器的EIB互连结构[25]中,将传输请求的处理分为两个阶段:请求仲裁阶段和链路仲裁阶段.这种分段仲裁结构能够降低仲裁时序,同时也能够兼顾通信设备间的公平性.但也存在问题,例如获得请求仲裁的请求在没有获得链路仲裁之前将一直占有请求目标的通信资源,降低了通信节点上的资源利用效率;并且请求仲裁阶段,请求的广播和侦听过程较为复杂,延时较长,这会降低仲裁器效率.
本文对基于环形网络的仲裁结构进行研究,提出了一种可扩展的流水仲裁结构,并且针对某SoC芯片完成了14节点的环形网络设计.通过软件模拟和后端实验,具有较高的可实现性.本文后续章节安排如下,第2部分介绍了用于环形网络的可扩展流水仲裁器的结构,第3部分对基于该仲裁器的环形网络和交叉开关结构进行了软件模拟和设计实现比较,最后对模拟、实验结果进行小结.
2 环形网络的可扩展流水仲裁器
为充分发挥环形网络结构的高聚合带宽优势,同时解决上文所述EIB仲裁结构的缺点,提出一种可扩展流水仲裁器结构.
2.1 中心仲裁的环形网络结构
图1所示是中心仲裁控制环形网络结构示意图.整个环形网络由通信单元、节点站台、流水仲裁器组成.其中通信单元是本地设备的接口部件,负责向流水仲裁器提出通信请求;流水仲裁器集中控制通信节点上的通信资源分配和通信链路的分配;节点站台负责根据中心仲裁器的指示控制传输数据的传输和上下网通道的选通.环形网络上的通信过程分为以下3步:
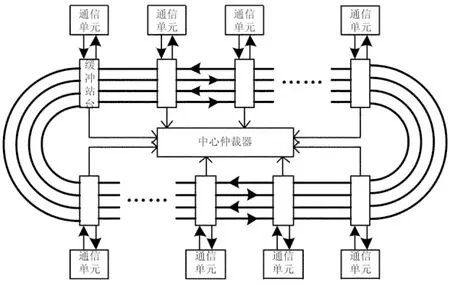
图1 中心仲裁控制的环形网络结构图
1)通信单元向仲裁器发出通信请求;
2)仲裁器根据请求目标节点的通信资源占用情况和通信链路的使用情况对请求进行仲裁处理;
3)获得仲裁成功响应的请求将通信数据发送到仲裁器分配的环形网络链路上,传送到目标节点下网.
由于链路冲突、目标接收缓冲的分配均在流水仲裁器中的仲裁阶段解决,通信数据在环形网络上的传输不会发生冲突,这种机制可以简化节点站台的设计.节点站台只需根据通信数据中携带的目标号控制链路开关决定数据继续传输或者下网到达目标节点,到达目标节点的数据无条件下网写入接收缓冲.
2.2 可扩展的流水仲裁器
流水仲裁器是环形网络的核心部件,负责接收通信请求、分配接收缓冲资源、分配通信链路等功能.
2.2.1 仲裁器总体结构
流水仲裁器的控制结构由两套链路构成.图2所示是请求提交和响应返回通路,主要由请求发送单元、请求筛选单元、仲裁核心三部分构成.该通路主要用于通信请求的提交和仲裁结果的返回.请求发送单元与通信单元连接,支持多个虚通道设置,负责将多个虚通道中的请求进行选择后提交给请求筛选单元;请求筛选单元连接多个通信单元,能够接收缓存通信单元提交的通信请求;仲裁核心接收请求筛选单元提交的通信请求,进行仲裁后对通信请求方返回仲裁响应.
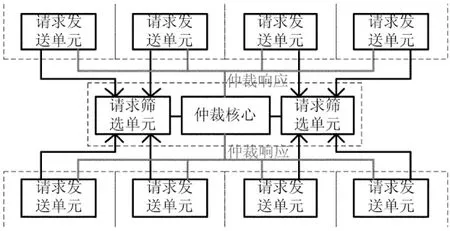
图2 请求提交和响应返回通路
通过调节寄存器站台,使得仲裁响应返回各通信节点的延迟相同,因此通信节点收到响应后可以在固定的时间内发送数据上网,这可以简化响应通路设计.
除了请求提交通路外,还有一条简单的信用释放链路,由信用释放单元、中心信用管理单元构成.该通路是个单向通路,主要作用是将通信单元中接收缓冲的释放信息发送到中心信用管理单元中.
2.2.2 有条件筛选请求
请求筛选操作分布在多个单元中配合完成:请求发送单元,完成不同虚通道间请求的筛选;请求筛选单元,完成不同请求发送单元提交请求的筛选.
位于通信单元内的请求发送单元中包含多个虚通道,能够保存不同类型的请求.相同虚通道内的请求采用先来先服务的原则进行排队,不同虚通道内的请求则采用公平的堆栈仲裁策略选择后进行提交.请求发送单元为每个虚通道中的头请求设置一个年龄计数器,提交出去的请求每返回一次失败响应,则将年龄计数器加1.根据接收到的仲裁响应,请求发送单元完成下述操作:
1)仲裁成功响应,启动数据传输,清除命中虚通道的年龄计数值,根据堆栈仲裁器选择提交下一个请求;
2)仲裁失败响应,将仲裁失败的虚通道年龄计数值加1,根据堆栈仲裁器选择提交下一个请求;
3)如果选择提交的请求的年龄计数值超过预设阈值,则将提交请求的超时标签置有效;
请求筛选单元连接多个通信单元,能够接收通信单元提交的通信请求,并按照一定的策略选择请求提交给仲裁核心.图3所示为连接4个通信单元的请求筛选单元结构示意图.请求筛选单元中有请求提交缓冲,能够保存接收到的请求,请求提交缓冲的深度大于等于连接的通信单元数.
请求筛选单元接收缓存请求的策略是:请求阻塞排队,短距离优先.请求筛选单元采用先来先服务的顺序阻塞排队,缓存有效请求的同时保存请求的提交时间到“时间标签”中.对于同时间到达的多个请求,按照请求传输距离进行排队编号并保存到缓冲队列中.
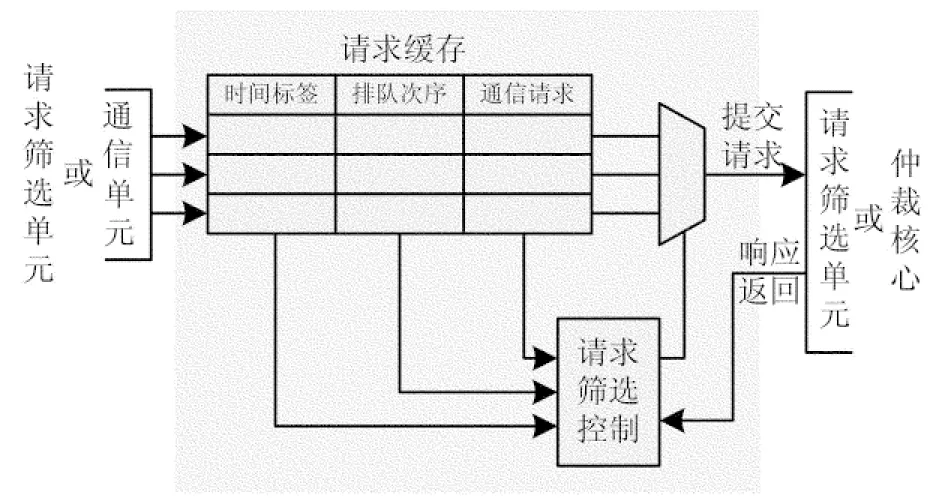
图3 请求筛选单元结构示意图
请求筛选单元向仲裁核心提交请求的策略是:有信用优先.请求筛选单元按照时间标签从小到大(时间标签相同的则按照排队次序从小到大)开始遍历缓冲队列,挑选第一个有通信信用的请求提交到仲裁核心;如果都没有通信信用,则按照队列顺序提交.这种以通信信用为条件的优先称为有条件优先.
请求筛选单元实际上是在请求提交的过程中按照既定策略对请求进行了初步选择,被优先选择的请求都是属于命中几率高的请求(满足基本通信条件,即目标方有通信信用).请求阻塞排队和提交则保证每个通信单元都能有公平机会进行通信,防止饥饿或死锁发生.通信单元中的接收缓冲被占满后,释放的时间是不确定的;而环形网络中链路的占用总会在某一固定时间内排空.因此在请求筛选阶段选择有信用的请求优先提交可以提高仲裁效率和链路利用效率.
仲裁核心会返回请求仲裁两种响应,请求筛选单元根据仲裁结果和请求实际情况,分3种情况进行处理:
1)请求成功响应,接到成功响应后请求筛选单元清除请求缓冲队列中的相应条目,并提交下一个请求,同时对仲裁命中的请求发送单元返回仲裁成功信号;
2)请求失败响应,并且该请求的超时标签有效,则重新提交该请求;
3)请求失败响应,该请求的超时标签无效,则清除请求缓冲队列中的相应条目,按照规则提交下一个请求,同时对仲裁失败的请求发送单元返回仲裁失败信号.
2.2.3 有条件阻塞的流水仲裁
环形网络上的通信请求仲裁命中必须同时满足两个条件:通信目标有接收缓冲(也即是有通信信用),传输链路空闲.
仲裁器对请求的仲裁策略采取有条件阻塞仲裁策略.仲裁核心对请求筛选单元提交来的请求进行信用仲裁和链路仲裁,对满足阻塞条件的请求采取阻塞式仲裁,直到命中后才接收下一个请求进入仲裁核心.通信请求有条件阻塞仲裁策略是:
1)在仲裁阶段对由于没有通信信用的通信请求返回仲裁失败响应,不能阻塞其他请求的仲裁;
2)除此之外的请求情况,仲裁核心对于提交来的请求将会采取无条件阻塞仲裁的办法直到仲裁命中.
环形网络通信中短距离传输占用的环形网络链路少,并且可以支持链路不重合的多个通信并发执行,仲裁器对短距离通信请求进行优先选择有利于提高链路利用率和环形网络通信带宽,减少通信请求的总等待时间.
如图3所示的请求筛选单元中,设计有缓冲能够缓存通信请求,请求缓冲的深度与请求筛选单元的输入源数有关,每个请求源对应一个固定条目.通信请求一旦被仲裁核心或者下一级请求筛选单元选中,则会从缓冲中读出,然后该缓冲允许写入下一个新的通信请求;如果通信请求满足仲裁条件,仲裁核心可以连续地仲裁.也就是说,该仲裁器中通信请求从通信单元提交出来,到经过请求筛选单元筛选后最终提交到仲裁核心,这个过程都是可以流水连接的.因此当通信请求比较密集的时候,该仲裁器结构能够连续仲裁,流水地返回仲裁响应,仲裁能力取决于仲裁核心的设计复杂度.
2.2.4 仲裁器的可扩展性
基于上节所述请求筛选机制的仲裁结构,可以根据通信单元数目灵活组装配置,构成不同层次的筛选结构.这种通过裁剪请求筛选的方法,可以使仲裁核心的仲裁逻辑保持不变.因此该仲裁结构能够在保持关键时序路径不变的情况下,适应通信节点数量的变化.如图4所示,当通信单元数目由6增加为18时,请求筛选单元由一层增加为两层构成的多级请求筛选结构.由于通信请求在请求筛选单元之间是能够流水提交处理的,因此仲裁核心逻辑可以不做重大修改,保持原有的仲裁逻辑长度便可完成从6节点到18节点的设计.

图4 基于筛选的可扩展仲裁器结构
3 模拟实验
3.1 软件建模模拟
对采用上面所述结构的流水仲裁器的环形网络进行了建模模拟.模拟平台采用SystemVerilog和Verilog语言,在ModelSim模拟环境下开发,通信激励通过调用随机函数产生,仲裁器实现采用RTL描述,能够实现节拍级模拟.其中:互连结构实现了环形网络结构、交叉开关结构,设计采用Verilog实现,环形网络结构中实现了上文所述的可扩展流水仲裁器结构,交叉开关中的仲裁器采用Round Robin结构;通信单元采用SystemVerilog构建模型,能够按照系统配置产生通信请求和接收通信数据.模拟系统能够根据顶层配置参数选择调用交叉开关或者环形网络进行互连,通信单元模型可以通过参数控制激励产生.
3.1.1 仲裁公平性模拟
首先,采用环形网络结构,在保持物理连线规模不变的情况下,对不同通信链路规模的环形网络性能进行了模拟.物理连线规模为512位,按照链路宽度分为3种情况:
1)64位*8套链路,4套顺时针方向,4套逆时针方向;
2)128位*4套链路,2套顺时针方向,2套逆时针方向;
3)256位*2套链路,1套顺时针方向,1套逆时针方向;
主要测试目的是测试不同链路规模下,验证该流水仲裁器结构的仲裁公平性.设置网络节点规模为14个,各个网络均采用数据包的通信方式,数据包长度固定为128Byte.设置各通信节点固定运行20 000拍,运行过程中各节点均为满入射率,通信目标伪随机生成.
在相同时间内,三个网络中各个节点发出、接收到的通信次数柱状图如图5所示.从图中可以看到,在固定的时间内,各节点发出的通信请求命中数量相差在5%以内,由此可见该流水仲裁器设计对各个节点的通信机会是公平的.
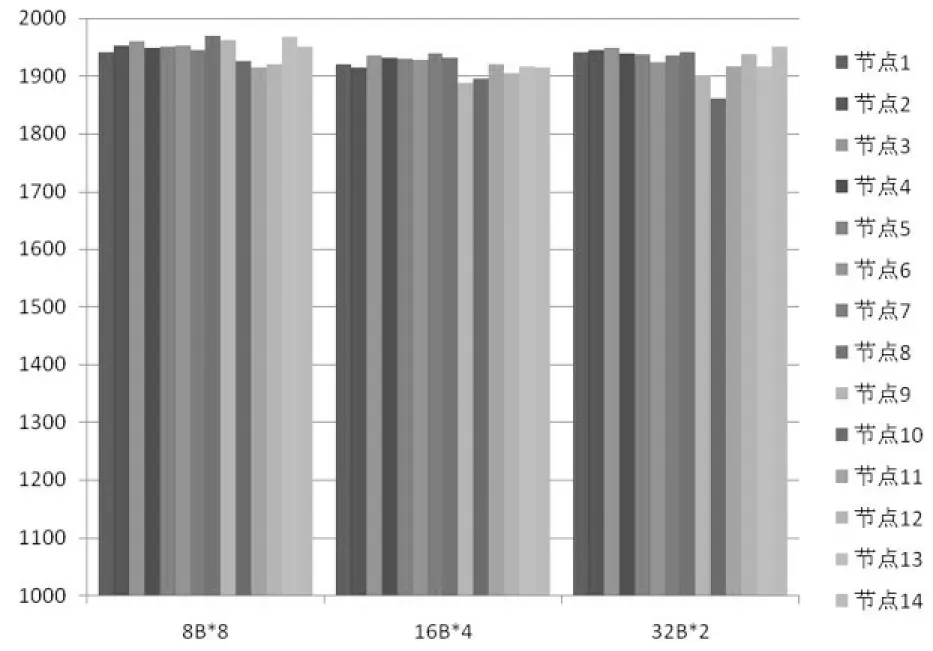
图5 各节点发出通信请求数量
除此之外,仲裁器的公平性还可以从最大通信延迟上反映出来.根据通信模拟条件可以知道环形网络中一次通信延迟如下式所示:
通信延迟t=请求仲裁延迟+数据发送延迟+链路传输延迟;
(1)
数据发送延迟=数据包大小/链路宽度;
(2)
数据传输延迟=(目标号-源号)%(节点数/2 -1).
(3)
由于链路宽度差异以及通信源、目标距离造成的通信延迟变化很小,最大通信延迟主要是由于请求仲裁排队决定的.在极限情况下,即所有节点的通信目标相同时,此时最后命中的节点将会等待时间最长,即产生最大通信延迟.
最大通信延迟T=(节点数-2)*(数据发送延迟+最大数据传输延迟).
(4)
根据上面公式可以算出64位*8,128位*4,256位*2三个环形网络的最大通信延迟的理论值分别为:264拍,168拍,120拍.
我们调整测试方式,每个节点固定提交400 000个通信请求,通信数据包固定128字节,通信目标伪随机.模拟过程中,我们记录下各个节点的通信请求包最长的处理节拍数,测试结果如图6所示,为各节点的一次数据包通信最大延迟对比曲线图.从图中的数值区间可以看到,测试中的最大通信延迟均没有超过理论极限值,这也可以说明在多套环形网络链路中,该流水仲裁器设计能够做到公平仲裁.
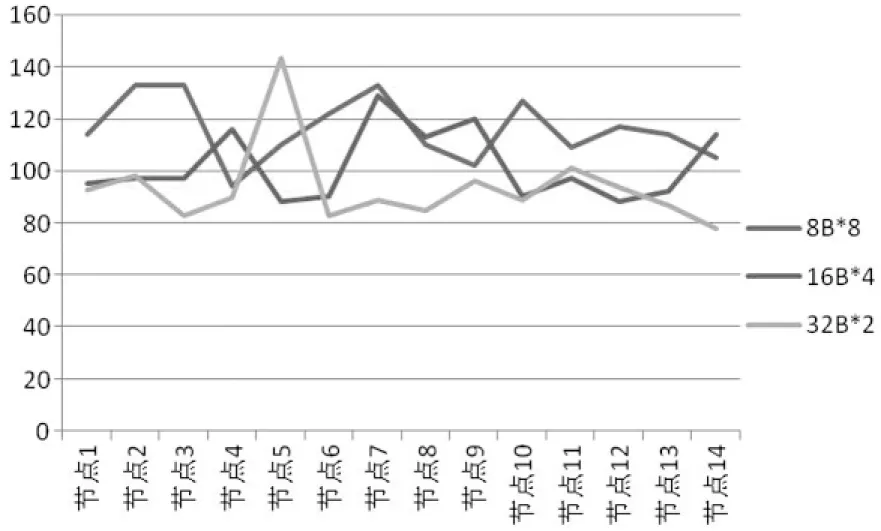
图6 各节点上通信请求最大延迟曲线图
3.1.2 仲裁效率模拟
如前所述,仲裁器设计除了要保证公平性,也要最大化发挥互连结构的通信效率,提高通信带宽.本节对采用不同仲裁能力的仲裁器结构对环形网络带宽效率进行了测试模拟,并与环形网络理想仲裁条件进行了对比.环形网络理想仲裁表示所有链路不冲突的请求可以并发传输,可以认为理想仲裁能够发挥环形网络的最大测试带宽.
实验条件设置为:时钟频率设置为1GHz,14个通信节点采用均匀随机激励模式,激励均为128字节固定长度数据包,运行时间为400 000拍.
考虑到环形网络中数据下网端口冲突可能限制带宽效率,实验分为存在下网冲突和无下网冲突两部分进行,分别对2种环形网络结构进行了带宽测试.结果如下表1所示.
从表1中的测试数据可以看到,与理想仲裁测试相比,采用每拍1个仲裁结果的流水仲裁器的环形网络带宽损失率在7%~26%左右;如果将仲裁能力提高到每拍2个,带宽效率普遍有所提高,带宽效率可以再提高2.8%~6.9%.从测试结果可以知道,仲裁能力与环形网络带宽效率成正比例关系,仲裁能力越高对带宽的利用效率越高.采用该流水仲裁器结构对带宽利用效率确实有一定的损失,但降低的仲裁能力要求,显然大大简化了仲裁核心逻辑的复杂度.
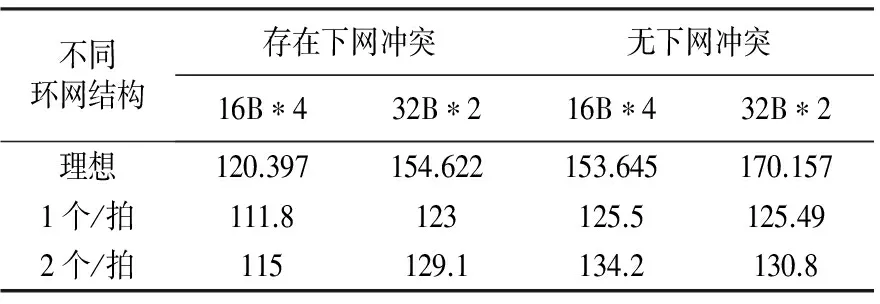
表1 带宽模拟结果
3.2 时序综合实验
如前所述,在该流水仲裁器结构中,各通信节点发出的通信请求经过请求筛选结构的筛选,到达仲裁核心逻辑的请求数量大大减少,这能够降低仲裁核心逻辑的复杂度,因此环形网络与交叉开关相比在高频率设计中更具可实现性.本节对采用该流水仲裁器的环形网络进行了RTL实现,并与交叉开关结构进行比较.
基于Chartered 65 nm工艺标准单元库,采用Cadence公司的DC工具进行了物理综合实验,实验结果如表2所示.

表2 RTL综合实验结果
从表中可以看到,在14个节点规模下,该流水仲裁器的逻辑延迟是全交叉开关仲裁的63%左右,是理想仲裁器的46%左右.这是因为流水仲裁器通过请求筛选结构减少了到达仲裁核心的请求数量,能够有效降低仲裁器的关键路径逻辑级数;全交叉开关结构采用简单的13端口的轮转仲裁逻辑实现,逻辑级数较长;而理想仲裁器,由于节点数多达14个,需要同时完成尽量多的不冲突请求的仲裁所导致的逻辑级数剧增,因此逻辑延迟最大.在数据通路上,环形网络的下网逻辑为四选一MUX,而全交叉开关为十三选一MUX,环形网络也具有时序优势,环形网络的延迟仅为全交叉开关延迟的41%.通过上面的实验结果可以看到,基于请求筛选的流水仲裁器的环形网络在逻辑延迟和后端可实现性上比交叉开关结构具有优势.
此外,由于设计中同时采用顺时针、逆时针两个方向环形网络,网络通信的最大跨步为节点数的一半,这个特点使得仲裁核心记录链路的占用节拍减少为节点数的一半,因此对减少仲裁核心的逻辑长度有很大好处.对比表2中不同仲裁能力的流水仲裁器的延迟,可以发现每拍2个与每拍1个的逻辑延迟相差不大.我们专门对8个节点和14个节点的仲裁核心逻辑进行了DC综合对比实验.通过实验发现,节点数从8个增加到14个时,每拍1个仲裁结果的流水仲裁核心的逻辑延迟从0.54 ns增加为0.58 ns.这也在一定程度上反映了该流水仲裁器具有一定的可扩展性.
4 结束语
本文对环形网络的仲裁结构进行了研究,提出了一种基于请求筛选的可扩展流水仲裁器结构.该仲裁结构中,通信请求经过请求筛选单元的有条件优先选择,提交到仲裁核心的请求优先满足有通信信用的要求,有利于提高仲裁命中效率.短距离传输占用的环网链路少,比长距离传输请求更容易达到传输要求,请求排队和仲裁时,采用短距离优先策略能够更好的提高链路通信效率,减少请求的总等待时间.请求发送单元中的超时机制、请求筛选和仲裁时的阻塞式排队策略,则能够保证通信网络的基本公平性,并且通过模拟实验也说明该结构仲裁器具有较好的仲裁公平性.请求筛选结构设计独立性强,可根据环网规模和仲裁核心的仲裁能力灵活组装配置,时序综合实验也证明该结构逻辑级数少、实现延迟较小的特点,这些都有利于高频设计的实现.此外,由于仲裁核心时序受互连规模影响较小,有利于互连规模的扩展,适合用于通信节点数量不是特别大的片上互连设计中.
[1] HEMANI A, JANTSCH A, KUMAR S,etal. NetworkonChip: an architecture for billion transistor era [C]//Proceedings of the 18th IEEE NorChip Conference. Turku, Finland, 2000: 166-173.
[2] DALLY W J, TOWLES B. Route packets, not wires: on-chip interconnection net-works [C]// Proceedings of the 38th Design Automation Conference. Las Vegas, Nevada, USA, 2001: 684-689.
[3] BENINI L, MICHELI G D. Powering networks on chips: energy-efficient and reliable interconnect design for SoCs [C]// Proceedings of the 14th International Symposium on System Synthesis. Montreal, Canada, 2001: 33-38.
[4] HOSKOTE Y, VANGAL S, SINGH A,etal. A 5-GHz mesh interconnect for a teraflops processor [J]. IEEE Micro, 2007, 27 (5): 51-61.
[5] WENTZLAFF D, GRIFFIN P, HOFFMANN H,etal. On-chip interconnection architecture of the TILE processor [J]. IEEE Micro, 2007, 27 (5): 15-31.
[6] GRATZ P, KIM C, SANKARALINGAM K,etal. On-chip interconnection networks of the TRIPS chip [J]. IEEE Micro, 2007, 27 (5): 41-50.
[7] 钱悦. 片上网络演算模型即性能分析[D].长沙:国防科学技术大学, 2010.
QIAN YUE. Calculus models and performance analysis for networks-on-chip[D]. Changsha: National University of Defense Technology, 2010 .(In Chinese)
[8] ARM. AMBA Open Specifications [EB/OL]. 2011. http://www.arm.com/products/system-ip/amba/amba-open-specifications.php.
[9] IBM.Core Connect Bus Architecture[EB/OL]. 2011. https://www-01.ibm.com/chips/techlib/techlib.nsf/products/CoreConnect_Bus_Architecture.
[10]葛芬. 专用片上网络设计关键技术研究[D].南京:南京航空航天大学, 2010.
GE FEN. The key technology of application-specific network on chip design[D].Nanjing: Nanjing University of Aeronautics and Astronautics, 2010. (In Chinese)
[11]LEON A S, SHIN J L, TAM K W,etal. A power-efficient high-throughput 32-thread SPARC processor [C]// Proceedings of IEEE International Solid-State Circuits Conference. San Francisco, CA, USA, 2006: 295-304.
[12]TENDLER J M, DODSON J S, FIELDS J S,etal. Power 4 system micro architecture[J]. IBM Journal of Research and Development, 2002, 46( 1) : 5-24.
[13]KAHLE J A. Introduction to the cell multiprocessor[J] .IBM Journal of Research and Development, 2005, 49( 4/ 5) : 589-604.
[14]TAYLOR M B, KIM J, MILLER J,etal. The raw microprocessor: a computational fabric for software circuits and general purpose programs [J]. IEEE Micro, 2002, 22(2):25-35.
[15]VANGAL S R, HOWARD J, RUHL G,etal. An 80-tile 1.28 TFLOPS network-on-chip in 65 nm CMOS [C]//Proceedings of International Solid-State Circuits Conference (ISSCC). San Francisco, CA, USA, 2007:98-589.
[16]VANGAL S R, HOWARD J, RUHL G,etal.An 80-tile sub-100-w TeraFLOPS processor in 65-nm CMOS [J]. IEEE Journal of Solid-State Circuits, 2008, 43(1):29-41.
[17]BELL S, EDWARDS B, AMANN J. TILE64 processor: A 64-core SoC with mesh interconnect [C]// Proceeding of International IEEE Solid-State Circuits Conference(ISSCC). IEEE, 2008:88-598.
[18]AGARWAL A, BAO L, BROWN J. Tile processor: embedded multicore for networking and multimedia [M]. 2007:1-12. http://www.hotchip s.org/archives/hc19/2_Mon/HC19.03/HC19.03.04.pdf.
[19]TAYLOR M B, PSOTA J, SARAF A,etal. Evaluation of the raw microprocessor: an exposed-wire-delay architecture for ILP and streams [C]//Proceedings of the 31st Annual International Symposium on Computer Architecture. Munich, Germany, 2004: 2-13.
[20]WANG H, PEH L-S, MALIK S. Power-driven design of router microarchitectures in on-chip networks [C]// Proceedings of the 36th Annual IEEE/ACM International Symposium on Microarchitecture. San Diego, CA, USA, 2003: 105-116.
[21]HIN E S, MOONEY V J, RILEY G F. Round-robin arbiter design and generation[R]. Atlanta, USA: Georgia Institute of Technology, Tech. Rep. 2002: 02-38.
[22]LUMMER W W. Asynchronous arbiters[J]. IEEE Transactions on Computers, 1972, 21(1): 37-42.
[23]FELICIIAN F, FURBER S B. An asynchronous on-chip network router with quality-of-service (QoS) support [C]//Proceedings of IEEE International SOC Conference . Santa Clara : IEEE, 2004 : 274-277.
[24]ZID M, ZITOUNI A, BAGNNE A,etal. New generic GALS NoC architectures with multiple QoS [C]//International Conference on Design and Test of Integrated Systems in Nanoscale Technology. La Marsa, 2006 : 345-349.
[25]THOMAS W, AINSW O, NORTHROP G,etal. Characterizing the cell EIB on chip network [C]//IEEE Computer Society. 2007: 6-14.
A Scalable Pipelined Arbiter Design for Ring Bus
REN Xiu-jiang†, SHI Jing-jing,XIE Xiang-hui
(Jiangnan Institute of Computing Technology, Wuxi,Jiangsu 214083, China)
The arbiter architecture of the ring bus was studied, and a novel extensible pipelined design was proposed, which can allocate the communication buffers and links simultaneously. Three characteristics have been found in the proposed design. Firstly, the arbiter is fair for each node, only with a 5% difference of the hit number. The communicated nodes were found in the simulation when the arbiter in an interconnect system was modeled with 14 nodes. Secondly, compared with the crossbar design, the worst time delay of our synthesis RTL design with Chartered 65 nm Technology was reduced by 36.8%. Furthermore, as the number of the nodes has less effect on the key circuit, the arbiter has certain scalability.
arbiter; interconnect; ring;extensible design
1674-2974(2015)08-0086-08
2014-09-19
上海教委科研创新重点基础研究资助项目(12ZZ182)
任秀江(1982-),男,山东莒南人,工程师
†通讯联系人,E-mail:sunshinebuxiu@126.com
TP302
A
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:18:10
移动通信(2021年5期)2021-10-25 11:41:48
文苑(2020年10期)2020-11-07 03:15:26
电子制作(2018年19期)2018-11-14 02:36:44
武大国际法评论(2017年1期)2018-01-23 03:23:34
天津诗人(2017年2期)2017-11-29 01:24:12
视野(2015年6期)2015-10-13 00:43:11
仲裁研究(2015年4期)2015-04-17 02:56:33
中国交通信息化(2014年3期)2014-06-05 03:07:09
海峡姐妹(2014年5期)2014-02-27 15:09:38
