
K元N立方体网络均匀跨步通信模式的性能分析与优化
2015-03-08 07:29卢宏生施得君黄永勤胡舒凯
湖南大学学报(自然科学版) 2015年2期
卢宏生,施得君,黄永勤,胡舒凯
(江南计算技术研究所,江苏 无锡 214083)
K元N立方体网络均匀跨步通信模式的性能分析与优化
卢宏生†,施得君,黄永勤,胡舒凯
(江南计算技术研究所,江苏 无锡 214083)
K元N立方体网络是高性能计算机常用的一种网络结构.均匀跨步通信是高性能计算最重要的通信模式之一.针对K元N立方体网络均匀跨步通信模式,推导出其性能下限的理论公式,采用自行开发的网络模拟器模拟了多种结构、多种跨步值和多种消息长度的传输性能.最后针对节点重映射和消息分割两种优化措施进行了模拟和分析.模拟结果显示,4元N立方体网络具有良好的All-to-all性能,接近All-to-all性能最好的K元N树网络.
K元N立方体;All-to-all通信;均匀跨步通信;节点重映射;消息分割
对于很多重要应用而言,比如快速傅里叶变换等[1],All-to-all通信都是非常重要的通信模式,是影响性能的关键所在[2].许多网络设计的目标就是获得良好的All-to-all性能.标准的All-to-all通信可参考图1所示的MPI_AlltoAll的定义[3],每个进程都向其他所有进程发送数据,这意味着每个进程也同时接收来自其他进程的数据.由于标准的All-to-all通信可能存在大量竞争,包括网络的竞争,目标的竞争,从而导致性能大幅下降.
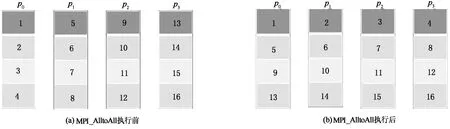
图1 MPI_AlltoAll功能示意图
假设共计N个进程{P0,P1, …,PN-1}.一种常用的优化手段是将All-to-all通信过程分解成N-1个阶段.阶段i,i=[1, …,N-1],每个进程Pk只向进程P(k+i)%N发送数据,这意味着每个进程Pk同时在接收P(k+N-i)%N发送的数据.这种方式有序化了All-to-all通信,降低了可能的阻塞,提升了整体All-to-all性能.上述每个阶段的通信都属于均匀跨步模式.所谓均匀跨步模式就是参与通信的所有进程对,其目标进程号和源发送进程号差值都相同.这种均匀跨步模式是许多重要应用中的通信基础模式,是超级计算机网络结构设计中的重要参考指标.图2是一个4进程All-to-all通信的阶段划分示意图.

图2 All-to-all阶段划分
在高性能计算中,每种通信模式的性能都和网络拓扑结构有着重要的关系.其中K元N立方体结构一直是网络结构研究的热点,是高性能计算机常用的一种拓扑结构.典型的系统包括IBM Blue Gene,Cray Gemini等.本文重点研究K元N立方体网络均匀跨步模式的性能及其优化.
1 均匀跨步通信性能分析
All-to-all通信由于涉及很多因素,其性能的理论分析是十分复杂的.IBM的Kumar等人基于Bluegene/L系统3D环网结构提出了一个针对多维环网的All-to-all通信模型性能公式[4].假设三维环网中每一维的处理器数量分别为Px,Py,Pz,系统中处理器的总数量为P=Px*Py*Pz,最长维处理器数量M=max(Px,Py,Pz),每个处理器发送m字节数据到其他处理器,单个字节在网络中的传输时间为β,则在All-to-all通信模式下,网络所传输的数据总量为P*P*m.每个包在最长维的平均步长为M/4,该维的链路总数为2P,因此完成All-to-all通信的时间T=P2*m*M/4*b/(2P)=P*(M/8)*m*β.该公式反映了All-to-all模式下3D环网的最好性能.如引言中所述,All-to-all通信可分解成若干步均匀跨步通信,因此分析均匀跨步通信模式的性能具有重要意义.
以图3所示8元1维环网为例,不同的均匀跨步形式有不同的性能.比如当以源目标对(P0→P1,P1→P2,P2→P3,P3→P4,P4→P5,P5→P6,P6→P7,P7→P0)进行通信时,由于所有路径均不存在链路冲突,因此该均匀跨步方式下通信性能可以达到100%.8元1维环网的网络直径为4,当以(P0→P4,P1→P5,P2→P6,P3→P7,P4→P0,P5→P1,P6→P2,P7→P3)进行通信时,每个消息的步长均为4,存在链路冲突,会导致通信性能的下降.假设8元1维环网采用均衡的确定性路由算法,即当步长为4时,源节点号为偶数的通信采用向右路由方式,源节点号为奇数的通信采用向左路由方式.这种按奇偶分配路由方向的策略可以保障最大化的路由均衡.

图3 8元1维环网
通过一个路径矩阵我们详细分析该情况下的链路冲突情况.如图4所示,8×8矩阵A,第i行表示以Pi为源点发起的消息.第i行向量(bi0,bi1,bi2,bi3,bi4,bi5,bi6,bi7),bij=+1表示从左到右到达j,bij=-1表示从右到左到达j,bij=0表示不经过该路径.通过矩阵我们发现2个现象.第1个现象是8个消息所占用的链路冲突率为50%.即每条链路最多被2个消息所使用;第2个现象是虽然1条链路被2个消息所使用,但由于可能冲突的消息的起点是错开的,因此当消息长度特别短时,并没有冲突发生.上述事实说明,均匀跨步的消息性能和消息发送的源节点和目标节点的映射关系、消息的长度都有重要的关系.

p0p1p2p3p4p5p6p7p00+1+1+1+1000p1-10000-1-1-1p2000+1+1+1+10p3-1-1-10000-1p4+10000+1+1+1p50-1-1-1-1000p6+1+1+10000+1p7000-1-1-1-10
图4 8元1维环网链路使用矩阵
Fig.4Linkutilizationarrayon8-nodering
Kumar以IBMBlueGene系统为参考,给出了3D环网All-to-all性能的上限评估公式.但事实上,在设计高性能计算机网络系统时,我们更关注其All-to-all性能的下限.因为应用与算法是多种多样的,知道了网络可能的性能下限,才能针对重大应用选择适应性更好的网络架构.下面从理论上初步分析均匀跨步的性能下限.K元N立方体网络,共有KN个节点,网络直径为N*K/2,链路总数为N*2*KN条.对于均匀跨步消息,网络链路冲突最大的情况是任一对通信节点间的步长均等于网络直径.所以理想情况下,需要的链路数为N*(K/2)*KN.所以我们得到系统链路吞吐率的下限公式为:
min(2N*KN/(N*(K/2)*KN),1)=min(4/K,1)
这是一个十分有趣的公式.它显示,对于K元N立方体而言,均匀跨步通信的吞吐率下限与维数无关,仅和每一维的长度相关.当K≤8时,均匀跨步通信吞吐率超过50%;特别当长度K=4时,即4元N立方体在进行均匀跨步模式通信时,吞吐率可以达到100%.了解一种网络结构All-to-all性能的下限对于网络结构的设计、各种网络参数的选取具有重要的参考意义.由上述公式可见,在All-to-all通信性能方面,4元N立方体性能接近K元N树性能.当然上述情况的分析都是基于理想情况.后面将用模拟器检查我们的分析是否准确.
2 均匀跨步通信性能模拟
2.1 网络模拟器
为了更好地模拟网络通信的性能,我们开发了一款采用C++编写的节拍级网络模拟器netsim.该模拟器支持K元N立方体、K元N树等多种网络结构.我们重点模拟了K元2立方体网络,即2D环网.该2D环网基于5端口路由器实现.路由器采用从输入缓冲经交叉开关到输出缓冲的传统的路由器结构.之所以没有采用目前比较主流的高阶路由器结构,主要是考虑构建2D环网所需路由器的端口比较少,同时这种结构的差异对我们研究的影响很小.我们研究的重点在于消息长度、通信模式和网络拓扑间的关系上.
模拟过程中的基本参数如表1所示.
模拟过程中无如特别说明,每个消息包长为64个flit,每个flit8B.链路带宽8B/周期.根据上述数据可知,1个节点向其相邻节点发送一个512B的消息包,最快需要的时间是T=Ts+2*Trn+2*Trou+Trr+Tr+63=113(周期).
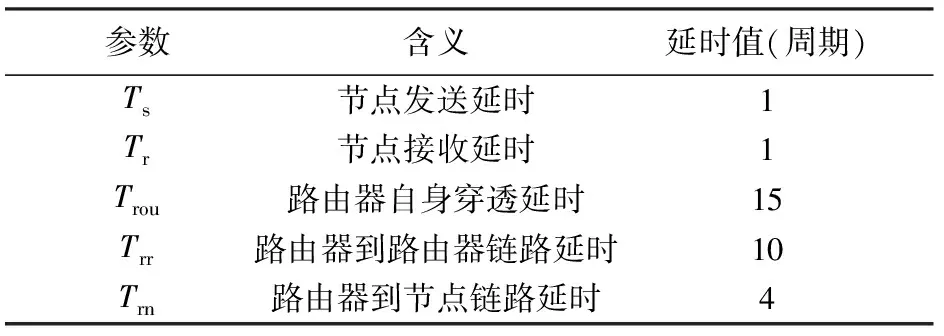
表1 模拟器主要参数表
2.2 性能模拟
我们分别对4×4 2D环网和8×8 2D环网进行了模拟.针对4×4 2D环网的16个节点,我们分别模拟长度为512 B,1 kB,2 kB,4 kB,8 kB,16 kB,32 kB,64 kB,128 kB,256 kB,512 kB,1 MB的All-to-all消息.每个All-to-all消息被划分为15个阶段完成.
表2中横向表示消息长度,纵向代表阶段,表项为相应长度消息在该阶段时传输所用时间.通过研究发现,在4×4 2D环网中,All-to-all通信的每个阶段,无论哪种消息长度,每对源目之间的消息传输延时都和该对源目之间点到点消息传输时的延时相同,即不存在因链路冲突所产生的延时,吞吐率均可达到100%,和我们第2节的分析是完全吻合的.
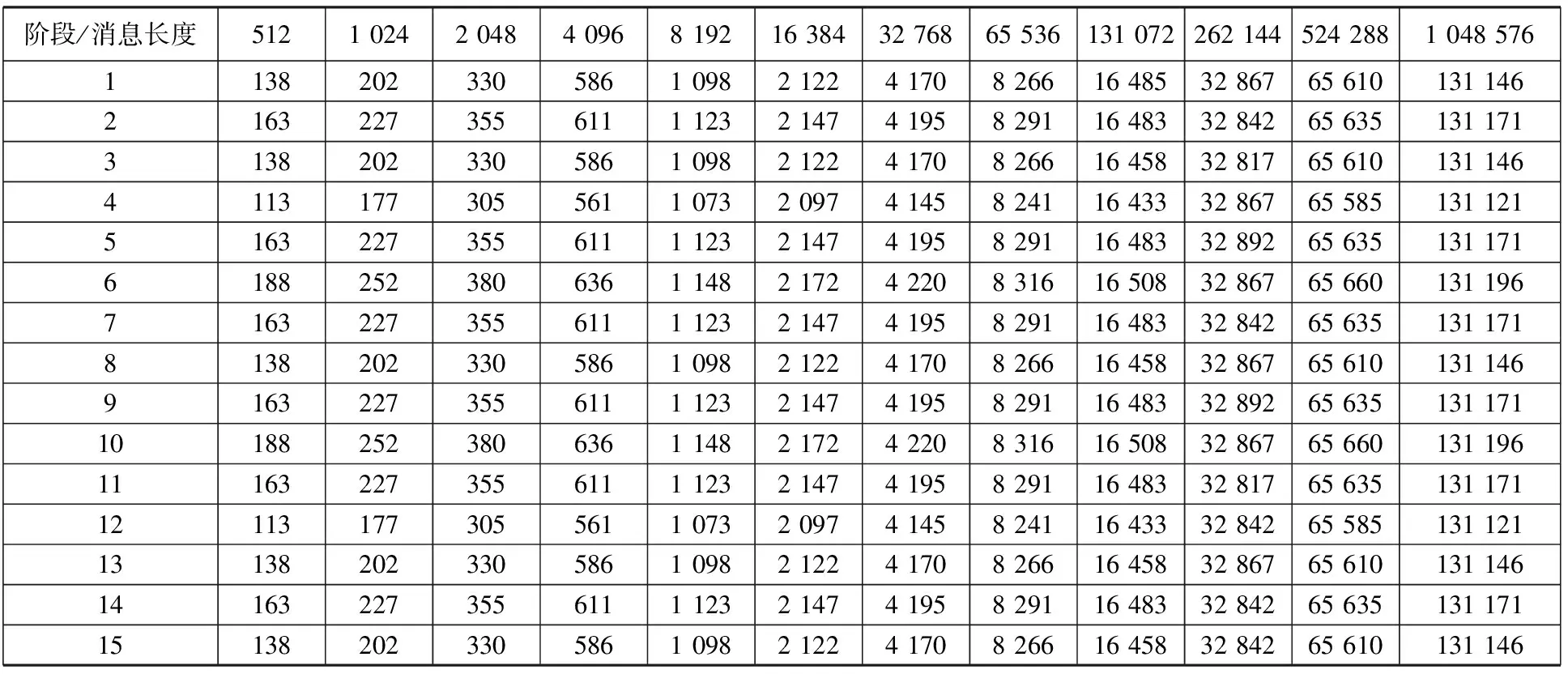
表2 4×X4 2D环网不同消息长度消息性能表
图5是 8×8 2D环网执行不同长度的All-to-all通信在63个阶段的吞吐率.其中系列i,i=[1..12],分别对应长度为512*2i-1B的消息.每个阶段p,p=[1..63],坐标(X,Y)的节点向坐标((X+dx)%8,(Y+dy)%8)的节点发送消息,dx=p%8,dy=p/8.结果显示,各个阶段的吞吐率有很大的差别.部分阶段,无论消息长度,吞吐率均达到100%,这主要得益于上述阶段不存在链路冲突;还有部分阶段吞吐率很低,最低的仅为14%,远低于我们预测的8×8 环网50%的吞吐率下限.这主要是因为我们的预测中仅从链路数量需求方面考虑了冲突的情况,但实际上作为环网,采用确定性维序路由算法后,链路之间存在依赖关系.这种依赖关系使得链路冲突率进一步加大.对于K元N立方体网络,K越大,影响越大.第2节中预测的最低值更接近最低值的上限或All-to-all通信阶段的平均值.

阶段号
图6是8×8 2D环网不同消息长度完整的All-to-all通信时所有阶段吞吐率的平均值.随着消息长度的增加,链路冲突的影响就越明显,表现为吞吐率在不断下降.随着消息长度不断增长,下降趋势趋缓,和我们预测的50%的吞吐率有10%的差距.利用相同的模拟参数,我们还构建了7端口路由器模型,模拟了4×4×4和8×8×8 3D环网All-to-all通信各阶段的情况.结果和2D环网类似.4×4×4环网吞吐率达到100%,而8×8×8环网在消息长度为32 kB时,平均吞吐率为40%.
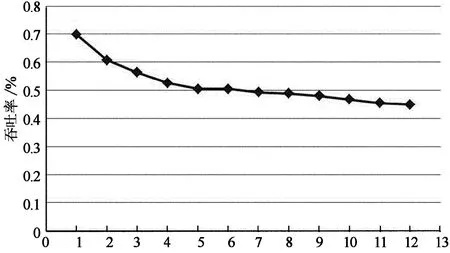
长度类别
3 All-to-all性能优化
在很多应用中,All-to-all性能都是性能的关键.优化All-to-all通信性能也一直是研究的热点.将All-to-all通信分解为N-1个均匀跨步过程是一种比较常见的优化方法.在前面的分析和模拟中,我们发现均匀跨步的性能和网络的结构有很大的依赖关系,而应用程序看到的跨步通常是逻辑上的概念.比如进程号,它并不等同代表网络中物理位置的物理号.真正影响通信性能的是物理号.是否可以通过变换逻辑和物理的映射关系改变均匀跨步的性能,从而提升All-to-all通信性能呢?
为此,我们编写了一个模拟程序,选择8X8 2D环网进行模拟,用A,B,C,D 4个矩阵分别记录X+,Y+,X-,Y- 4个方向的链路,一个完整的All-to-all消息被分解为63个阶段,分别记录每个阶段所有链路的使用情况.
图7(a)代表了一个逻辑节点号到物理节点号的映射关系.图7(b)中的4个图分别表示在阶段9即p[i]进程向p[(i+9)%64]进程(i=[0..63])通信时X+,Y+,X-,Y-4个方向共计256条链路的使用情况.图7(c)中的4个图则分别表示在阶段31即p[i]进程向p[(i+31)%64]进程(i=[0..63])通信时X+,Y+,X-,Y- 4个方向共计256条链路的使用情况.很容易发现,2个阶段的链路情况并不相同,这和我们前面的分析是吻合的.一个有趣的现象是:完成完整的All-to-all通信后,所有X+,Y+,X-,Y- 4个方向共计256条链路,每条链路均被使用了64次.多次更换映射关系,现象依旧.实际上,由于我们面对K*K2D环网是一个对称网络,无论逻辑节点号和物理节点号如何映射,对于完整的All-to-all通信而言,都是每个节点都和其他所有节点完成一次通信.而我们采用的是均衡的先X后Y确定性维序路由算法,因此无论如何映射,每条链路使用的次数是固定的,只在每个阶段有一定的差异.由于网络的对称性,每条链路最终使用的次数都是相同的.但这并不意味着重新映射逻辑节点号与物理节点号无助于提升All-to-all通信性能.事实上,由于映射关系的不同,每种映射下每个阶段的链路冲突率是不同的,最终所有阶段叠加的结果就是All-to-all通信性能并不相同.
如图8所示,(a),(b)分别对应4×4 2D环结构下两种逻辑处理器号和物理处理器号的映射关系.16个处理器的2D环网的All-to-all通信划分成15个均匀跨步通信阶段.(a.1),(a.2),(a.3),(a.4)表示映射关系1时阶段1的X+,Y+,X-,Y- 4个方向链路的使用情况.(b.1),(b.2),(b.3),(b.4) 表示映射关系2时阶段1的X+,Y+,X-,Y-4个方向链路的使用情况.定义一条链路的权值W为同一个阶段传输的消息数量.可以发现,映射关系1在阶段1时最大链路权值为1,即意味着在此阶段通信的16个消息没有链路冲突,消息以满带宽传输.而映射关系2在阶段1时最大链路权值为2,即意味这在此阶段通信16个消息中有2个消息共享(1,1)到(2,1)号链路.因此消息性能将为峰值性能的一半.阶段i的最大权值记为Wi.W=∑Wi/15(i∈[0..15])是All-to-all通信各阶段平均最大链路权值.结果显示,在映射关系1下,W1=1.在映射关系2下,W2=1.87.即4×4 2D 环网在映射关系1下All-to-all消息带宽可以达到链路峰值,而在映射关系2下,All-to-all消息带宽仅为链路峰值带宽的1/W2=53%.
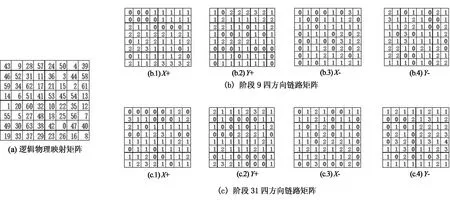
图7 8×8 2D环网链路使用矩阵
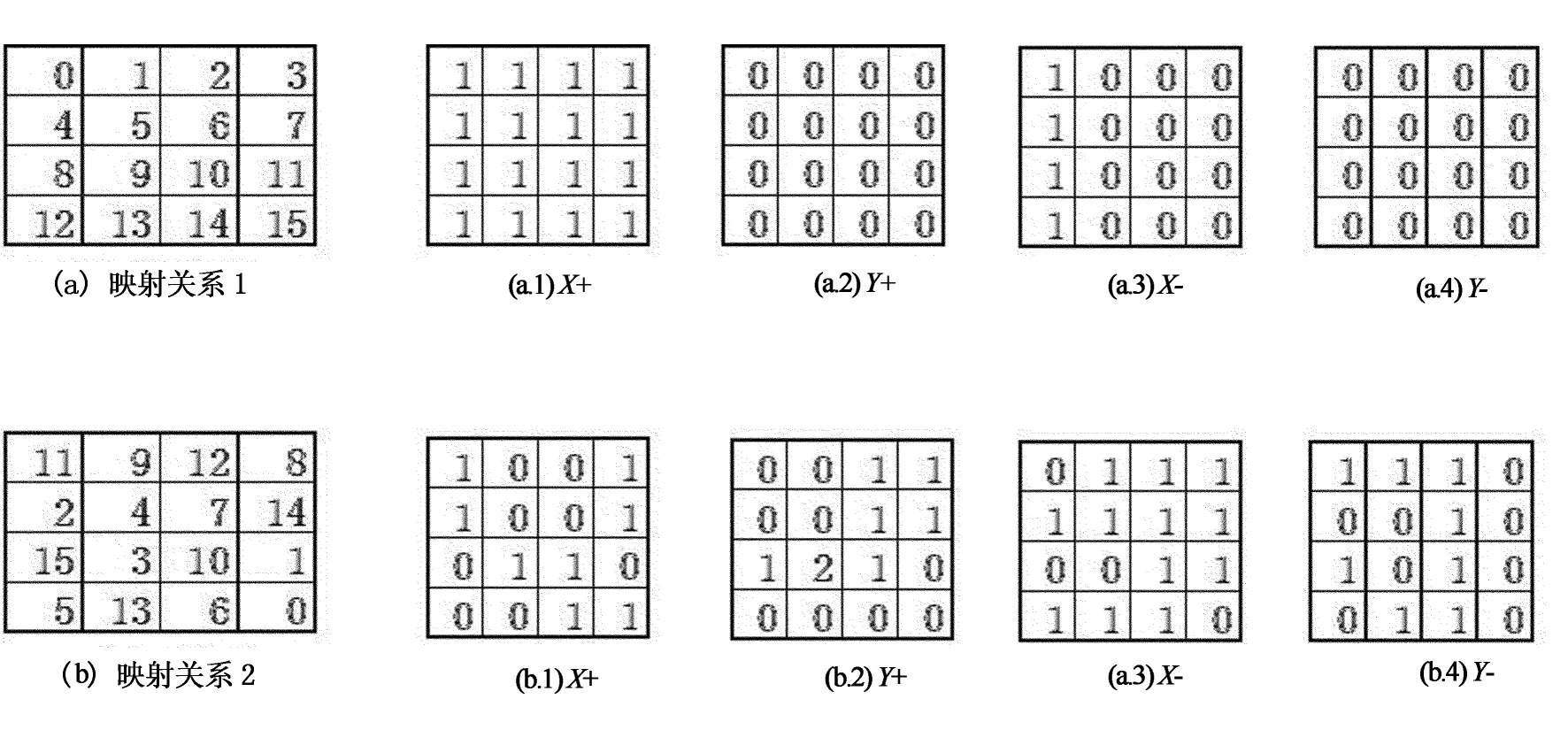
图8 两种映射关系下的4×4 2D 环网链路使用矩阵
针对All-to-all通信,也有一些研究人员尝试将长消息分割成小消息,通过对小消息的调度降低网络的冲突,从而提升性能[5].比如在InfiniBand 16元2树网络中通过将128 kB长消息拆分成16 kB小消息,All-to-all性能提升10%.但事实上,InfiniBand网络采用的是确定性路由,排除消息非常短的情况,无论消息长度多长,链路的使用情况是相同的.之所以通过将长消息拆分成短消息性能有所提升,主要是由InfiniBand HCA的消息发送机制造成的.HCA在发送消息时以时间片为单位,在一个时间片内连续调度同一个QP上的数据包,导致消息发射的频率并不恒定,从而导致网络拥塞.同时由于在All-to-all通信的各阶段间没有高效的同步机制,也容易造成目标节点的冲突,从而增加性能随消息长度浮动的变数.
总体来说,在理想情况下,这里的理想条件包括合理的消息发送机制、合理的NI,ROUTER均衡的缓冲配置、均衡的路由算法、足量的VC数量,决定All-to-all通信性能的关键首先是网络固有的属性即网络拓扑.良好的映射关系将有助于减少网络链路的冲突率,从而提升All-to-all通信的性能.因此在作业分配时,合理地配置节点资源或者在算法设计时紧耦合网络拓扑状况将大大提升All-to-all通信的性能.由于K元N树网络能够保证所有源和目标间的一一映射均不存在链路冲突[6],因此其任意均匀跨步模式的通信性能均可达到链路有效性能的100%,即等同于点到点通信性能.因此树型网络作为支持All-to-all通信的理想拓扑结构,是K元N立方体网络在All-to-all通信性能方面优化的重要标尺.
4 结束语
All-to-all性能的理论分析十分复杂.将All-to-all通信拆分成多个阶段的均匀跨步通信是一种提升性能的简单高效的方法.这种方法避免了目标的冲突.本文给出了一种K元N立方体网络中均匀跨步通信模式最低性能的估计值,这对高性能计算机网络结构的设计具有一定的参考价值.本文的公式显示其性能和一维的长度成反比.特别是当K=4时,4元N立方体网络有比较好的All-to-all性能.但最好的性能仍然属于完全无冲突的K元N树网络.在All-to-all通信方面,网络拓扑结构仍然是影响性能的第一要素.经过模拟与分析,也指出通过节点重映射手段可提升K元N立方体网络的All-to-all通信性能,而消息分割只在某些特定的系统中有效,并不具备普适性.
[1] YOGISH Sabharwal, SAURABH K Garg, RAHUL Garg,etal. Optimization of fast fourier transforms on the blue Gene/L supercomputer[C] // Proc of 15th International Conference on High Performance Computing.Bangalore, India, 2008: 309-322.
[2] All-to-allcommunication[EB/OL]. [2014-4-9].http://en.wikepedia.org/wiki/All-to-all_communication.
[3] MPI_Alltoall[EB/OL]. [2014-4-9].http://www.mpich.org/static/docs/v3.1/www3/MPI_Alltoall.html.
[4] SAMEER Kumar, YOGISH Sabharwal, RAHUL Garg,etal. Optimization of All-to-all communication on the blue Gene/L supercomputer[C] // Proc of 37th International Conference on Parallel Processing, Portland, Oregon, 2008: 320-329.
[5] 陈淑平, 卢德平, 陈忠平. InfiniBand网络中All-to-all通信性能优化[J]. 高性能计算发展与应用, 2012(2): 69-74.
CHEN Shu-ping, LU De-ping, CHEN Zhong-ping. Optimization of All-to-all performance in InfiniBand network[J]. Development and Application of High Performance Computing, 2012(2):69-74.(In Chinese)
[6] SABINE R Öhring, MAXIMILIAN Ibel, SAJAL K Das,etal. On generalized fat trees[C] // Proc of the 9th International Parallel Processing Symposium.Santa Barbara, California, 1995: 37-44.
Performance Analysis and Optimization of Uniform Stride Communication onK-aryN-cube Network
LU Hong-sheng†, SHI De-jun, HUANG Yong-qin, HU Shu-kai
(Jiangnan Institute of Computer Technology, Wuxi,Jiangsu 214083, China)
K-aryN-cube is a widely used network architecture for high performance computer. Uniform stride communication is one of the most important communication models for high performance computing. This paper gave the theoretical lowest limit performance of uniform stride communication inK-aryN-cubeand and achieved a series of performance simulations in a self-developed network simulator. The simulation parameters include network arrays, stride values and message lengths. We also simulated and analyzed two optimized methods, node remapping and message division. As a result, 4-ary N-cube has very good All-to-all performance that approaches the performance ofK-aryN-tree, which has the best All-to-all performance.
K-aryN-cube; All-to-all communication; uniform stride communication;noderemapping; message division
1674-2974(2015)02-0134-07
2014-09-16
国家“863”高科技研究发展计划项目(2014AA01A301)
卢宏生(1972-),广东广州人,江南计算技术研究所高级工程师†通讯联系人,E-mail:lu_hongsheng@126.com
TP301
A
猜你喜欢
哈尔滨铁道科技(2020年3期)2021-01-18
人民调解(2019年1期)2019-03-15
读者(2018年15期)2018-07-18
中学生天地(A版)(2017年6期)2017-06-23
中国交通信息化(2017年11期)2017-06-06
青年时代(2016年32期)2017-01-20
太空探索(2016年9期)2016-07-12
小学生导刊(低年级)(2016年6期)2016-07-02
智能建筑电气技术(2015年5期)2015-12-10
中国交通信息化(2014年12期)2014-06-05
