
结合相似度量和反馈调节的推荐算法
2015-03-07 09:24:58王庆庆吴共庆
合肥工业大学学报(自然科学版) 2015年9期
王庆庆, 吴共庆, 李 磊
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
迄今为止应用最广泛的推荐算法是协同过滤算法[1-7],它通过挖掘用户的历史评分数据对用户喜好进行建模。随着社交网络的兴起,一些基于社交信任的推荐系统也相继被提出[8-11]。其背后共同的动机是,在社交网络中,一个用户的品味与其信赖的朋友的品味相似或受其影响[12]。
推荐系统虽已在商业中广泛应用,但多数算法都存在固有弱点。首当其冲的是数据稀疏性带来的问题。在商用推荐系统中可用数据的密度通常低于1%[9],无论是协同过滤还是基于信任的算法都无法规避此类问题。协同过滤很难处理评分稀少的用户。而基于信任的算法中,新连入社交网络的用户,直接信任的邻居寥寥可数,意味着很多物品无法预测。这迫使算法要去考虑用户的间接邻居(即邻居信任的用户)。但是将间接邻居纳入考虑后,部分用户的邻居规模会陡增,有限相似的邻居会带来长尾噪音的干扰问题[5]。
此外,目前已有算法都基于这样一个假设,即所有评分数据客观真实,却忽略了某些可能异常的评分数据。例如,对于某物品,多数用户给出高评分,却有极少数给出了低评分。
为了克服上述问题,本文提出了一种新的用户相似度量方法,从用户信任的邻居中识别出相似度较高的K个邻居,进行第1次预测评分;利用一次预测结果,反馈检查并修正原评分数据中的异常评分,然后进行第2次评分预测,以期提高推荐准确度。本文的相似度量依据是,邻居评过分的物品集与目标用户的物品集重叠度越高,则该邻居和目标用户的相似度越高。
1 相关工作
传统的协同过滤可分为2类,即 Memorybased方法和 Model-based方法。前者在Amazon等商用推荐系统中应用较为普遍[13],典型模型有基于用户的[2,7]和基于物品的[4,5]协同过滤。此类方法推荐结果直观、易理解;但数据稀疏性使得模型很难计算物品间或用户间的相似度,因为它/他们之间的共同项太少。后者的典型模型有隐语义模型 LFM[14-16]。LFM 利用矩阵分解技术[16]将一个高维矩阵分解成2个或多个低维矩阵的乘积[14],通过特定系数线性组合物品因子向量来对用户的偏好建模。LFM虽能更好地为评分数较少的用户提供推荐,但是需要反复迭代才能获得较好的性能,且不能对推荐结果进行解释。
上述方法均基于一个假设,即用户是独立同分布的,忽略了用户间的社交联系。真实世界中,对于未知物品,人们一般会先向身边信任的朋友咨询,收集他们对物品的评价,而各人的喜好也容易受朋友影响。出于此动机,许多研究者开始研究基于社交信任的推荐。文献[8]提出了信任感知的推荐系统,它通过信任网络中的信任传播来度量用户的信任值,以此代替相似度权值;文献[10]提出了一种基于topk推荐的最近邻算法,利用信任网络中的邻居和矩阵分解的用户潜在特征空间中的邻居,形成“联合邻居”来代替观察值的加权平均;文献[17]中不仅考虑信任的邻居对目标商品的评分,还考虑相似商品的评分,通过随机游走模型求得两者间的折衷。上述模型都需要计算用户间的相似度和信任值,因而不能扩展到大规模数据集上;文献[12]提出用户在不同分类上信任不同朋友,为此将原社交网络分成多个子网络,每个子网络对应单个分类,单个分类中的朋友根据专业知识分配不同的信任值。但在数据稀疏时,信任网络按分类划分后,数据稀疏性会随之增大,推荐的覆盖率和准确度将大大降低。
2 方 法
2.1 用户重合相似度量
协同过滤的关键步骤之一就是相似度量。常见的有余弦相似度、皮尔逊相关系数和调整后的余弦相似度[5]。但是面对稀疏的数据,2个用户间的共同评分物品集本来就小,经常仅一两个物品,在这些小集合上非常相似,并不能肯定2个用户的相似度就高。为了解决这一问题,提出了新的相似度量。
定义1 用户重合相似度,是指用户u和v之间评分重合的数目占自身评分总数的比重,即

其中,Ru表示用户u的评分物品集合。
例如,用户u对n1个物品评过分,用户v对n2个物品评过分,设u和v同时评过分的物品为n3个,则用户u对v的重合相似度为n3/n1,而用户v对u的重合相似度为n3/n2。显而易见,用户的相似度矩阵为非对称矩阵。对于用户u和v,当共同评分物品数n3较小时,若n1较大,则用户u对v的重合相似度不会很高;若n1也不大时,恰好能反映出用户u对v的重合相似度较高。
2.2 邻居的挑选
从信任网络中可以得到目标用户直接申明信任的邻居,即直接邻居。通过广度优先检索可得到直接邻居信任的用户,即间接邻居。两者组成了用户的初始邻居。通过观察,发现不同用户的初始邻居数目差别很大。为了避免有限相似的邻居的长尾噪音干扰,为邻居数目设置一个阈值,即邻居数的最大值K。对于邻居数多的用户,从初始邻居中挑选出与用户联系更密切的K个邻居;而对于邻居数不多的用户,从第3层邻居中选取部分补足。具体操作是按用户对邻居的重合相似度递减排序,取前K个邻居作为用户的近邻。
2.3 评分预测与反馈调节
本文算法中涉及2次评分预测,过程相同。即挑选出目标用户u的邻居集合ONu后,利用邻居对目标物品i的评分预测用户u对物品i的评分^ru,i,计算公式如下:
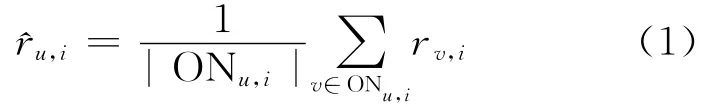
其中,ONu,i表示用户u的邻居对物品i评过分的用户集合,rv,i表示用户v对物品i的评分。
对于目标物品i,存在以下情况:多数人给出高评分,却有极少数用户给出差别较大的低分;反之亦然。称这些与多数评分差别较大的评分为异常评分项,对于用户u和物品i,本文算法对于异常评分项的识别和修正的过程如下。
(1)求得邻居评分中大于一次预测值的评分所占比例pu,i,计算公式为:

其中,f(x)定义如下:

(2)若高分比例pu,i<α∈[0,0.5),即高分所占比例较小,则认为高分评分为异常评分项,将高分邻居的评分标记为-1,表明其评分值需要下调ε(本文中取ε=1);反之若低分比例1-pu,i<α,即低分所占比例较小,则认为低分评分为异常评分项,将低分邻居的评分标记为1,表明其评分值需要上调ε,计算公式为:

(3)修正评分矩阵,计算公式为:
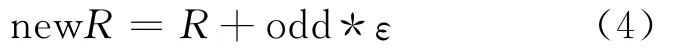
在修正后的评分数据newR上,重复评分预测过程,见(1)式,得到二次预测结果,即为最终结果。
2.4 算法流程与性能分析
算法流程如下:


在SCFA算法中,用户间相似度的时间复杂度O(n2),n为用户个数。通过设置邻居数阈值,可以有效控制邻居数为常量K,因此生成预测的时间复杂度为O(n)。综上,整个SCFA算法的时间复杂度为O(n2)。
3 实验结果与分析
3.1 数据集
采用文献[18]的数据集Epinions,包括22 166个用户,296 277个物品,912 441个评分,直接申明的信任关系355 727个。对于用户,选取信任人数不小于5的用户(共计9 282人);对于物品,选取评分数目不小于15的物品(共计8 594个),组成了新的实验数据集。新数据集的评分矩阵稀疏度为0.997 9,信任矩阵稀疏度为0.996 4。其中,评分矩阵将会被分割为2个子集,即训练集和测试集。从评分数少于5个的用户的评分物品中,随机选择1个评分放入测试集中;从评分数不少于5个的用户的评分物品中,随机选择10%,向上取整(即用户评分个数为5时,5×0.1=0.5,向上取整,随机选择1个)评分放入测试集中。
3.2 评价标准
使用均方根误差RMSE和平均绝对误差MAE作为评价标准。两者通过计算预测的用户评分与真实的用户评分之间的偏差度量预测的准确性,RMSE或MAE值越小,推荐的质量越高。

其中,^ru,i为预测的用户u对物 品i的评 分;ru,i为用户u对物品i的真实评分;Rtest为测试集中的用户 -物品对(u,i)。
3.3 对比实验和实验参数
采用的对比模型是经典的基于物品的协同过滤算法,算法简称如下所述。
IBCF:实现的是文献[5]中以皮尔逊相关系数作为相似度量的基于物品的协同过滤。
SC:本文中利用用户重合相似度优化邻居后进行一次预测的算法。
SCFA:利用SC预测结果反馈修正评分数据后,进行二次预测的算法。其中的参数取α=0.2,ε=1,均为经验值。
3.4 实验结果
在Epinions实验数据集上,在IBCF算法和本文的SC算法、SCFA算法上针对所有用户在RMSE和MAE 2个评价指标上进行对比,见表1所列。其中,SC、SCFA的RMSE和 MAE值选取的是以50为步长从K=50到K=1 000进行的20组实验的均值。通过比较,发现在RMSE上SCFA算法比IBCF提高了6.0%,在MAE上提高了12.4%。因此,对于所有用户,实验结果好于传统的IBCF算法的实验结果。

表1 IBCF与SCFA关于所有用户的RMSE和MAE值对比
对于SC和SCFA算法,以50为步长从K=50到K=1 000进行了20组实验,如图1所示。结果显示,在RMSE上SCFA比SC提高了0.9%,如图1a所示;在 MAE上提高了4.4%,如图1b所示。对比结果显示修正评分数据中的异常项有助于算法精度的提高。
将评分数少于10的用户视为冷启动用户,比较IBCF和SCFA在这些冷启动用户上预测结果的RMSE和MAE值,如图2所示。
由图2结果可知,本文算法在RMSE上提高了12.4%,在MAE上提高了15.4%。这说明只要冷启动用户连接到了信任网络中,基于信任的方法能更加有效地解决冷启动用户的推荐问题。
将初始邻居(即直接邻居加间接邻居)的数目大于K的视为多邻居的用户,比较IBCF和SCFA预测结果的RMSE和MAE值,如图3所示。
通过观察图3结果,发现本文算法在RMSE上提高了6.0%,在 MAE上提高了12.4%。这说明利用用户相似度过滤掉有限相似的邻居能够有效提高推荐的精度。
通过上述实验结果的对比,不难发现无论是在所有用户,还是冷启动用户和多邻居用户上,相比传统的基于物品的协同过滤算法,本文的SCFA算法都可以获得更低的RMSE和MAE值,因此推荐的效果更好。

图1 IBCF、SC和SCFA不同K值上所有用户的RMSE和MAE值的比较
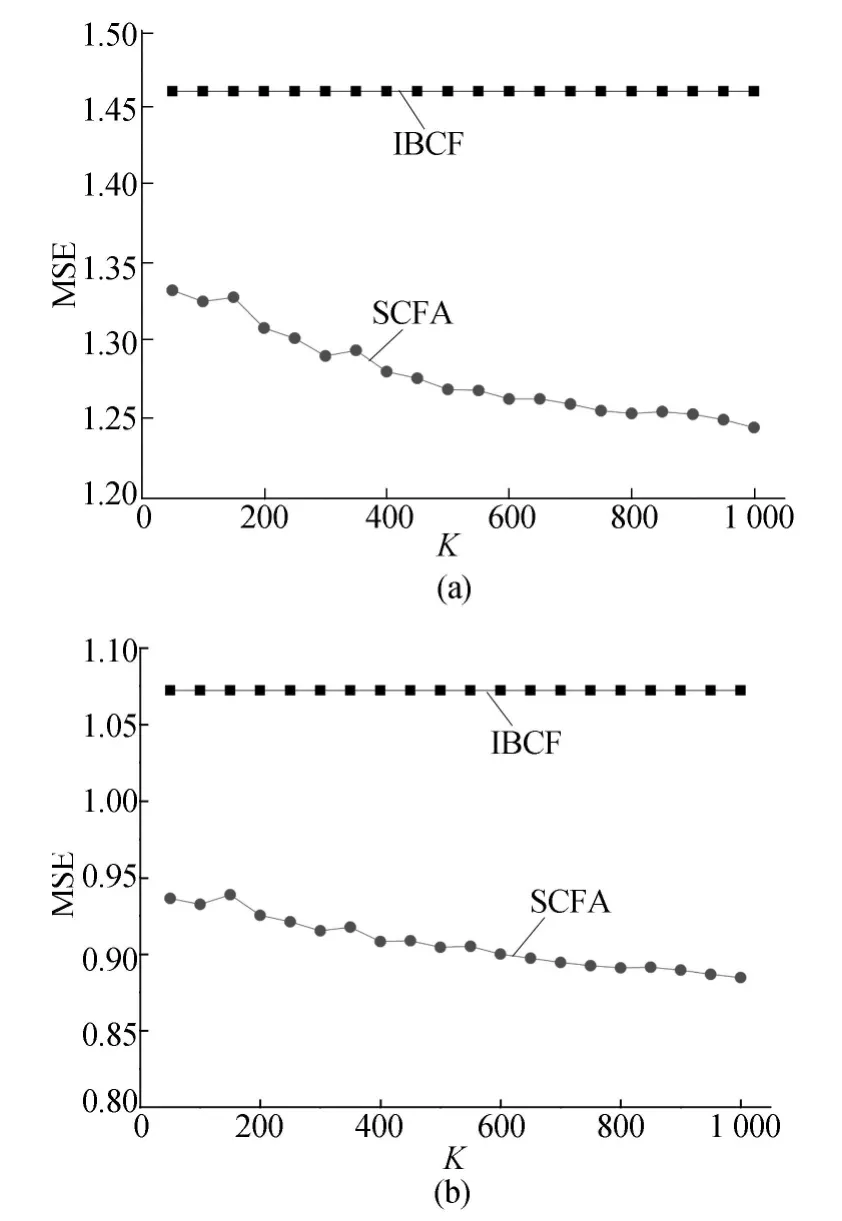
图2 IBCF和SCFA不同K值上冷启动用户的RMSE和MAE值的比较

图3 IBCF和SCFA不同K值上多邻居的用户的RMSE和MAE值的比较
4 结束语
本文提出了新的用户相似度量方法,并通过一次预测结果反馈调节异常评分项。在真实数据集Epinions上进行实验,结果显示该方法比传统的基于物品协同过滤算法具有更好的准确度。
[1] Niemann K,Wolpers M.A new collaborative filtering approach for increasing the aggregate diversity of recommender systems[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2013:955-963.
[2] Bellogin,Parapar J.Using graph partitioning techniques for neighbour selection in user-based collaborative filtering[C]//ACM Conference on Recommender Systems,2012:213-216.
[3] Koren Y.Factorization meets the neighborhood:a multifaceted collaborative filtering model[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2008:426-434.
[4] Deshpande M,Kapypis G.Item-based top-N recommendation algorithms[J].ACM Transactions on Information Systems,2004,22(1):143-177.
[5] Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[J].ACM International Conference on World Wide Web,2001,4(1):285-295.
[6] Karypis G.Evaluation of item-based top-N recommendation algorithms[C]//International Conference on Information and Knowledge Management,2001:247-254.
[7] Goldberg D,Nichols D,Oki B M,et al.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM,1992,35(2):61-70.
[8] Massa P,Avesani P.Trust-aware recommender systems[C]//ACM Conference on Recommender Systems,2007:17-24.
[9] Ma H,Yang H,Lyu M R,et al.SoRec:social recommendation using probabilistic matrix factorization[C]//International Conference on Infornation and Knowledge Management,2008:931-940.
[10] Yang X,Steck H,Guo Y,et al.On top-k recommendation using social networks[C]//ACM Conference on Recommender Systems,2012:67-74.
[11] Konstas I,Stathopoulos V,Jose J M.On social networks and collaborative recommendation[C]//ACM SIGIR Conference on Research and Development in Information Retrieval,2009:195-202.
[12] Yang X,Steck H,Guo Y,et al.Circle-based recommendation in online social networks[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2012:1267-1275.
[13] Linden G,Smith B,York J.Amazon.com recommendations:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,4(1):76-80.
[14] Jamali M,Ester M.A matrix factorization technique with trust propagation for recommendation in social networks[C]//ACM Conference on Recommender Systems,2010:135-142.
[15] Koren Y,Bell R,Volinsky C.Matrix factorization techniques for recommender systems[J].Computer,2009,42(8):30-37.
[16] Salakhutdinov R,Mnih A.Probabilistic matrix factorization[C]//NIPS,2007:1257-1264.
[17] Jamili M,Ester M.TrustWalker:a random walk model for combining trust-based and item-based recommendation[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2009:397-406.
[18] Tang J,Gao H,Liu H,et al.eTrust:understanding trust evolution in an online world[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2012:253-261.
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
电子制作(2017年10期)2017-04-18 07:23:07
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
电测与仪表(2015年10期)2015-04-09 11:48:32
