
潜变量量尺的拓展及研究展望
2015-02-18 06:30:40刘红云
统计与决策 2015年6期
刘 源 ,刘红云
(1.北京师范大学 心理学院,北京 100875;2.香港中文大学 教育学院,香港 999077)
早在西汉时期,刘向在《战国策·齐册三》中就提出来的“物以类聚,人以群分”的思想传承至今,对于总体分群的科学研究意义也在于此。当然,并不是所有的分群都像性别、出生地那样可以直接观测或通过测验得到。由于观测不到的异质性,研究者需要考虑同一个样本或总体中的潜在群体,这就是潜类别分析(LCA)的初衷,即根据一系列的观测变量将被试分群。然而,对于LCA的基本假设,其观测变量和潜变量均是离散型数据,这对于被试特性的描述信息不充分[1],阻碍了潜类别分析的进一步发展。所以,潜变量量尺的拓展成为这类模型发展新的契机。
1 潜变量量尺的拓展
由于心理学所研究的个体特质的复杂性,潜变量技术对数据类型的要求也变得复杂。在结构方程模型、因素分析等潜变量技术下,其重要前提假设就是群体的同质性。反映在因素分析里,则假设“因素”(潜变量)是连续变量,即潜变量属于“尺”量表。如果潜变量的量尺不能用一个连续的特质来解释,比如人群中的“特质类型”或者发展趋势中发展曲线不同的组,潜变量是连续变量的假设就被推翻,即潜变量属于“类”或“群”量表,需要用到另外的模型。潜变量也和观测变量一样,存在一个量尺。Masyn,Henderson 和 Greenbaum[2]提出的“尺类谱(DCS)”描述了潜变量的量尺。在这个谱系上,潜变量由完全的类别变量变化到完全的连续变量,不同的潜变量数字特征类型对应了不同的分析方法。
潜变量量尺的拓展,使得潜类别模型的应用迅速拓展。研究者在不知道潜变量数据类型假设的时候,可以通过模型比较的方法探索,以确定潜变量的类型。如果在这个谱系的“尺量表”端,则使用因素分析(FA)/项目反应理论(RT),它们假设潜在特质(如FA中的因素,IRT中的被试能力水平θ)是连续变量;而另一端为“类量表”,则使用LCA模型,它假设潜变量为类别变量,总体具有不同质的特征。从“尺量表”过度到“类量表”,可以将潜变量看成其他混合型数据,根据潜变量在谱系上的不同位置,还可以使用混合因素分析(FMA)、半参数因素分析(FA)、混合半参数因素分析等不同的技术(详见表1)。
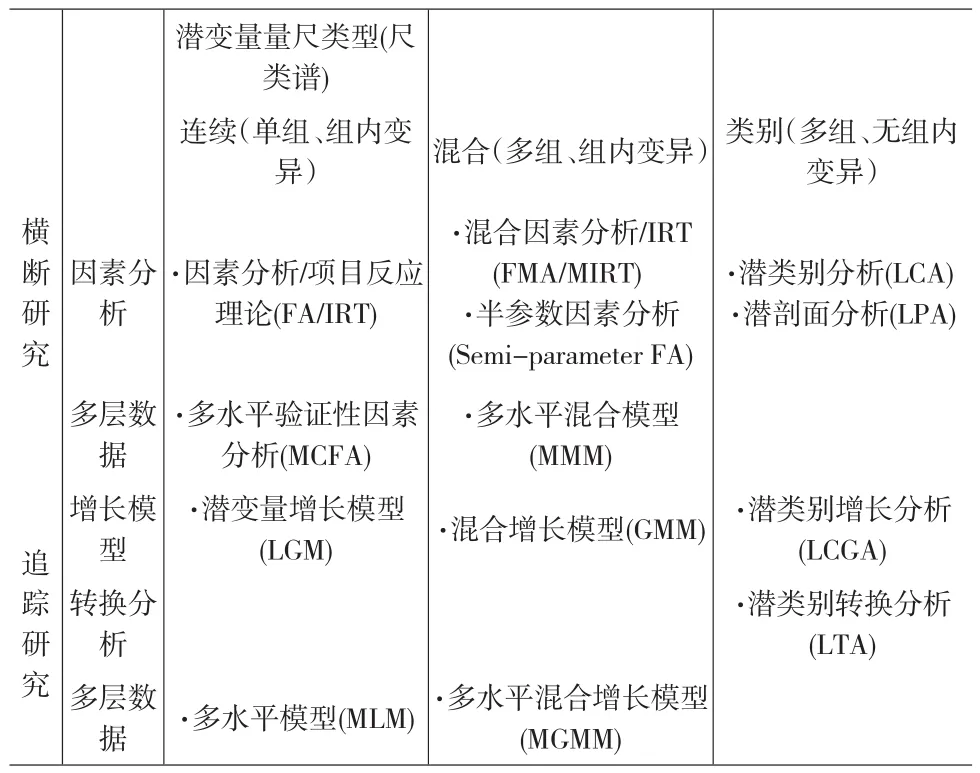
表1 潜变量分析技术
2 潜类别模型方法的拓展
想要宏观地把握潜类别模型分析的技术,可以根据心理学的研究范式,从横断和追踪研究两个方面去了解各个模型的使用条件。
2.1 横断研究中的潜类别模型
2.1.1 因素分析中的分类
对潜变量量尺的拓展,极大的丰富了潜类别模型的应用。所以,从这个角度出发,LCA也可以看成是一种广义的因素分析模型(如图1所示)。假设观测变量都是类别(或连续)变量的情况下,LCA模型假设潜在因子是一个类别变量,在项目的反应概率量尺上有不同的类别,类内不存在变异;而IRT模型(或FA模型)则是一个假设潜在因子(能力)是连续变量的模型,在项目反应概率量尺上存在连续变化的一个群体[3]。其中,观测变量为连续,潜变量为类别的情况,较早的研究提出“潜在剖面分析”。但是随着LCA技术的发展,其已经将观测变量拓展到连续变量的情形下,所以较新的研究都使用LCA代替之[4]。
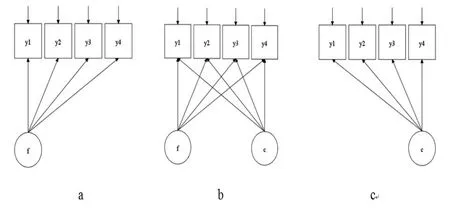
图1 几种因素分析模型的数据假设及其比较
对于潜变量的数字特性,可以从原来的“连续”“类别”两种极端情况推广到“混合”模式。在尺类谱的中间,可以得到混合IRT(MIRT)或混合因素分析(FMA),潜变量是混合型,其数据特征要求总体不同质,即总体用“类”度量;同时,在每一个群体里,都可以用连续的因素来表征,即群内用“尺”度量[2]。在实际应用中,FMA假设在项目反应概率上存在不同的群类,而群类内又存在组内变异,可以解决因素分析中总体不同质的问题。
由此可知,在尺类谱上可以组合成很多较为实用的模型;不同模型假设不同,其解决的问题也不同,针对不同总体内部的形态也不同。如果分群不存在组内差异,LCA便是较好的选择,其在认知、临床、教育考试、心理测验等领域有广泛的应用[1,5]。如果分群具有组内差异,MIRT(或FMA)则是首选。它们可以广泛地应用在临床病理与学习障碍研究[6,7]、心理与人格测验[8,9]等领域,旨在连续的总体中找到不同的群,并探讨用不同的机制和手段分别对不同的群体进行干预。
2.1.2 多水平混合因素分析模型
前文中所提到的数据模式,均在同一层级的抽样中产生。而在实际中,特别是在组织行为学和教育心理学领域,分层数据更为常见。这种数据就称为多水平结构的数据,其分析方法多采用多水平模型(MLM)或多层线性模型(HLM)。在MLM中,多层数据结构违反了一般回归分析测量误差残差独立的假设,测量的变量来自于不同层级。在MLM的分析思路中,核心的思想就是将变异分解为组间变异和组内变异[10]。此后,研究者将多水平的数据应用到结构方程模型当中,衍生出了多水平验证性因素分析模型(MCFA)等技术,并且开发出了相应的软件(如Mplus)使得多层分析的技术得到了很好的发展。
在多水平数据的结构下,变异同样可能存在潜在的异质性。多水平混合模型(MMM)[11]结合了多水平数据和混合模型的思路,可以探讨多水平结构下数据的潜在组别或者潜在群类对结果变量(连续变量、分类变量、称名变量等变量类型)的影响。在该模型提出之后,一系列的研究者对其估计方法做出了拓展,一般建议使用EM的估计方法或贝叶斯的估计方法。
图2是一个横断研究中混合MCFA的模型示意图。观测变量y1-y5的方差分解为组内部分(方框)和组间部分(圆圈),需要估计随机部分的在组内用黑点表示。fw表示组内的因子,受到潜类别变量c的直接影响。fb为组间的因子,在组间部分,c有组间的随机效应,随机截距便成为组间因子fb的指标。在这个模型中,组间部分的因子残差方差为0。如果在组间存在类别c与组间因子fb之间的路径,该模型变会变得复杂,产生许多跨级交互作用。研究者将混合MCFA模型应用到智力测验、人格测验、教育与学校的分层研究和临床诊断等领域上。在此基础上,研究者可以定义许多复杂的模型,且在不同层级上可以定义不同类别数,这使得该模型变得非常灵活。比如在混合MCFA中,研究者可以将学生对学校的满意度在不同学校的层级内分别建模;在混合IRT模型框架下,例如在跨文化地域研究中,研究者可以针对不同国家、不同洲进行分层,以建构不同文化下的类别模型,或对学业成就进行DIF检测。
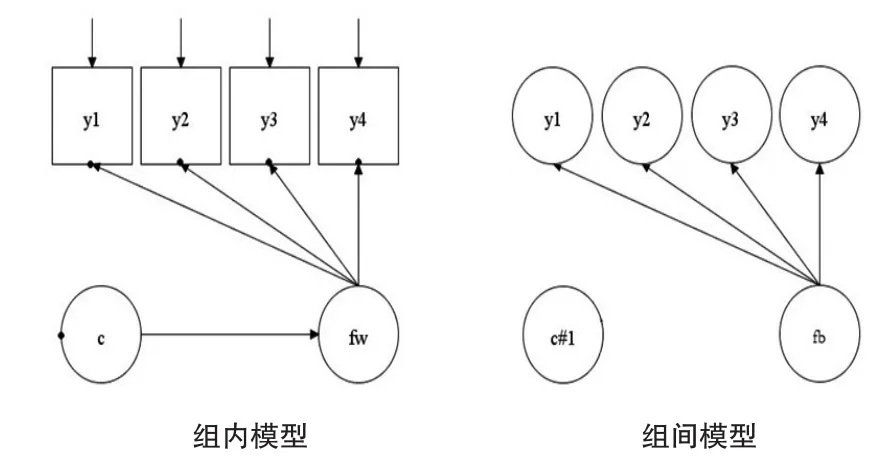
图2 多水平混合因素分析示意图
2.2 追踪研究中的潜类别模型
2.2.1 群的调节作用:潜类别转换分析
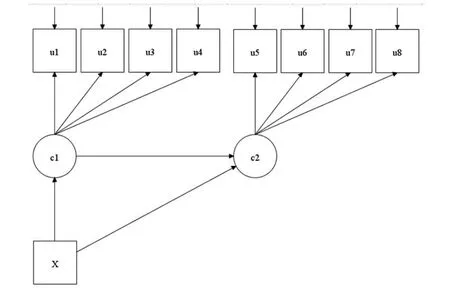
图3 潜类别转换分析模型示意图
如果对于不同时间点分别做LCA分析,则衍生出潜类别转换模型(LTA)。Nylund等人(2007)建议,在做LTA分析的过程中,首先就是在不同时间点分别做LCA模型(潜变量分别为c1和c2),其次使用列联表观察分类变化的情况,然后再分析类别c1到类别c2的转换情况(图3)。在这个列联表中,研究者可以分析某一个类别的群体随着时间的推移,其性质发生了怎样的改变,或者在什么样的条件下(加入协变量),哪些群体会转变成另外一个群体。这类研究思路旨在探讨个体随时间变化的类别转变,特别在发展心理学中很有价值。
上述研究的例子表明,协变量(贫穷水平)成为一个类别转换的调节作用。Muthén,Muthén和Asparouhov[12]在对同一批数据的处理当中(c1和c2都有两个类),将c1的两个类别分别定义:第一个类自由估计;第二个类的估计中,固定了c2的第一个类对贫穷回归系数的概率为0(即EWR转换为LAK的概率为0),与前人得出了相同的结果。这表明,由于分析的关键变量(潜类别变量c1、c2和协变量X)都是分类变量,所以不仅协变量可以有调节作用,类别潜变量同样可以分析调节作用。除此之外,他们还在此基础上,添加另一个类别潜变量c作为高阶因子,从中概括出具有不同转换模式的群类[21]。同时,他们还将LTA与FMA模型结合,其结果比传统LTA模型拟合更好,且能发现与前人研究不太一致的地方,都是值得进一步思考的问题。
2.2.2 增长模型中的群:潜类别增长分析与混合增长模型
和LTA不同的是,潜变量增长模型(LGM)[13]侧重的并不是类别中个体随时间的转换,而是个体随时间的发展趋势。它是在追踪研究的范式下发展起来的以研究总体发展趋势为中心的一类统计模型。它建立在验证性因素分析的模型基础上,通过结构方程模型的视角,揭示指标变量、协变量与增长因子之间的关系,并且与多水平模型(MLM)[14]模型融会贯通,LGM模型和MLM之间有相互等价转换的关系[15]。
在增长模型中的一个很重要的假设就是个体发展的同质性。同样在实际的情景中,总体可能并非同质,且这种非同质性是无法测量的,即存在“观测不到的异质性”。在此情况下,需要对测量个体进行分类,结合LCA衍生出两种重要的模型:潜类别增长分析(LCGA)[16]和混合增长模型(GMM)[17]。图4中表示了潜变量的两种不同的假设(与图1类似)。其中,如果模型中包涵虚线部分即GMM,如果没有则为LCGA。不难发现,这两种模型最主要的区别就是是否允许类内存在变异。LCGA假设类别内是同质的,不存在变异;而GMM放宽了这种限定。此外,如果在图4中不考虑与潜变量c有关的路径,则该模型就是一个LGM模型。所以,LGM是只有1个类的GMM模型,而LCGA模型是限定潜类别变异为零的GMM模型,二者均是GMM模型的特例。一般地,LCGA假设观测变量也是类别变量,但是由于软件(如Mplus)的发展,LCGA也放宽了观测变量为类别变量的假设,只需限定GMM随机部分为零即可[4]。
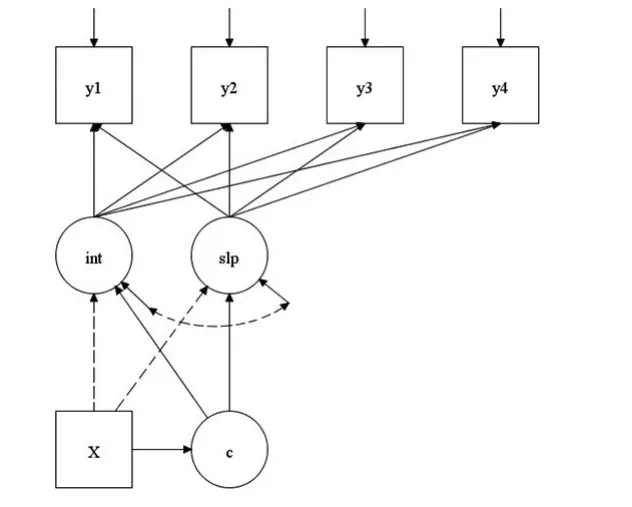
图4 潜变量(混合)增长模型的数据假设及其比较(包含虚线部分即混合增长模型)
2.2.3 多水平混合增长模型
在追踪数据的分析方法中,MLM方法也很常用。因为研究者可以把追踪数据看作测量嵌套于个体的模式,这样数据便有了多层结构。在追踪研究中,比如增长趋势类的研究,研究者可以将GMM与多水平数据相结合,衍生出多水平GMM模型(MGMM)。由此可知,MMM模型既可以应用于横断研究,也可以拓展到追踪研究中,但是由于追踪研究本身就存在一个嵌套数据结构(测量嵌套于个体),所以追踪研究模型的层数比横断研究的多。如图5所示,该模型中存在个体水平(第二水平)和组水平(第三水平)的协变量,且个体存在不同的类别,那么研究者就需要定义一个三水平的混合模型,其中iw和sw都是组内的增长因子,组内的协变量为x,组内类别为c;ib和sb为组间增长因子,组间协变量为w,w会对分类造成影响。Palardy和Vermunt(2010)使用MGMM的多阶段增长模式对学生的数学成绩进行分析。其研究中,由于既分析了增长曲线的类型,又考虑了个体水平(社会经济地位、是否为亚洲人、黑人或西班牙人等)与学校水平(平均社会经济地位、教师职业性等)的变量,故建立了三水平模型。按照一般多水平模型的思路,需要依次考虑不同截距和斜率的随机部分,所以该研究中发现,如果考虑不同水平的随机部分之后,其最后选择的类别数目也不同。
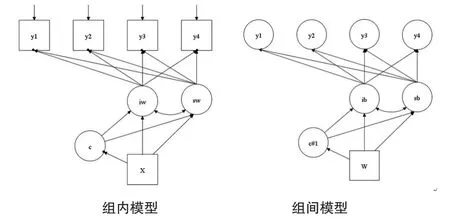
图5 多水平混合模型示意图
当然,并不是所有研究都偏向于将被试进行分类。Yampolskaya等人[18]的研究便采用MMM的方法在对儿童的研究中拒绝了两类别的模型,得出其研究样本同质性的结论。该研究同时也指出,使用MMM模型不单可以分类,同样可以根据统计指标(如AIC、BIC)判断被试是否同质(关于类别选择的问题会在下文进行探讨)。尽管MMM应用价值正在逐步体现出来,但多水平模型本身比较复杂,加入各层的协变量后,交互作用特别是跨级交互作用也较为繁琐,不易解释,所以研究者需要对数据驱动的模型进行较为深刻的理论解释。但是,可以推断,在统计技术逐渐发展的当今社会,多水平模型会成为蓬勃发展的一个分支,对实证研究做出更大的贡献。
前文描述的诸多潜变量分析技术,按照潜变量的数字特征和研究类型可以总结成表1,研究者可以根据研究的内容和数据特征灵活选用不同的潜变量分析技术,从而得到合理的可以推广的研究结论。
3 潜类别模型中待解决的问题和展望
3.1 模型的选择
在潜类别模型中,模型选择是一个比较复杂而且一直存在争议的问题。同样由于混合模型数据驱动嫌疑较大,所以研究者一般都采用探索性的方法对实际数据进行分析。比如在追踪研究中,研究者们同时使用GMM和LCGA对数据进行拟合,并且从1个类别开始,逐步增加类别,以“数据说话”代替繁琐的理论辩解,通过鉴定指标来判断最终模型应该取多少个类别。大多数研究者偏向使用BIC,LRT以及熵值来判断类别的拟合情况和模型的分类情况。也有一部分研究者对数据驱动的模型提出质疑,建议运用协变量纳入模型中进行模型选择,并强调实际意义应该是研究者在分类中需要重点考察的和关心的问题。
此外也有研究者偏向使用“返回指数”(如ARI)来选择模型。因为返回指数在计算方法上不同于其他拟合指标,其可以评价不同指标的优劣。Steinley和Brusco[19]的研究中就使用了ARI去判断比较使用BIC分类结果和CH指数分类结果的好坏。其他一些研究者也采用ARI来判断各种分类指数分类结果和真实类别之间的返还程度。由此可知在研究者面临多个选择指标的时候,ARI可以考察这些分类指标,而非仅仅考察数据。有了这个指标之后,研究者在考虑使用何种指标进行最后的模型选择就有了更有说服力的依据。
对于模型选择问题,未来的研究应该几种在模拟和实证研究基础上,为研究者们提供实际的证据。在众多的拟合指标中,研究者应该先看什么,再看什么,最后再根据什么指标进行调整。特别是对于潜在距离不大的数据,使用GMM和LCGA的两难选择问题,以及模型的拟合(如BIC)与分类结果(如熵)确定性之间可能存在的相悖关系,需要进一步深入研究讨论。
3.2 协变量对分类的影响
在上述模型中也看到了,对于潜类别c的分类效果,研究者往往希望考虑协变量的影响而并非纯粹的指标变量的影响。比如在CACE效应中,研究者往往会在模型中直接加入协变量X,这样的c的分类结果就不能由纯粹的指标变量所导致。研究者就会有疑惑,潜在类别应该是由固有的指标变量决定的,还是由其他协变量相互影响而决定的?对于带有协变量的LCA模型,也一直存在争论:是否应该加入协变量来决定最终分类的问题?由于LCA模型固有的数据驱动之嫌,研究者也在不断探索出较为合理的分析步骤。一般研究者认为,确定最终分类应采用指标变量。有两种较为传统的手段:一种是“三步法”,即先用指标变量分出类别,再根据分类结果判断出外显的类别指标,最后再在此基础上分析协变量;另一种是“一步法”,即在模型估计的时候就加入协变量对类别的影响。对于后者,研究者们进行了反驳,认为加入协变量之后,模型的估计会发生变化,但是前者却只考察了正确分类的类别,并没有将错误类别的概率考察在内,故这种直接判别类别的方法没有充分利用LCA模型的信息。Bolck,Croon和Hagenaars[20]就讨论过这两种方法的区别,针对第二步的分类误差提出了“BCH三步法”对传统三步法方法进行矫正;在此基础上,Vermunt[21]总结了前人的研究并提出了更优化的“ML三步法”,认为研究者需要考虑类别变量的分类概率的影响,利用后验概率的信息对外显的分类结果进行矫正。在“ML三步法”中,第一步估计仍然做传统的LCA,不添加协变量,但是需要记录其分类后验概率的结果;第二步根据分类的概率,计算出每个类别的发生比;第三步是在固定每个类的阈值等于发生比的基础上,再考察协变量对预测变量的影响,这又体现了类别c的调节作用。之后,Asparouhov和Muthén[22]提出添加“辅助变量”的方式得以软件的实现和方法的改进。
Asparouhov和Muthén认为,潜类别c和协变量X存在两种不同的关系。一种是Vermunt[21]的“ML三步法”,X作为潜类别c的一个预测指标去预测c的分类,此时研究者需要做c对X的逻辑回归,即潜类别回归分析;而另一种情况是c作为预测变量对一组外显的X预测,被称为远端变量。在添加了辅助变量的估计中,最后根据模型的熵值来决定应该怎样选择模型。他们根据模拟研究结果建议,在熵值<0.6的时候应该使用传统的一步法,熵值介于0.6到0.8之间时应该考虑传统的分类方法以及Vermunt的“ML三步法”,而当熵值>0.8的时候,三种方法都尚可[22]。
当然,这个规则也只是“拇指法则”。Asparouhov和Muthén在其模拟研究中,生成数据的时候使用了包涵了协变量的模型,所以该模拟结果势必会偏向添加了辅助变量的结果。如果模型改变,辅助变量是否能继续有效,比如在模拟的时候,生成的数据模型就不包涵协变量的数量关系,得到的结果是否还能一致的指向辅助变量的结果?对于这种刚刚兴起的方法,还需更多的探索。
3.3 小结
潜变量量尺的拓展使得潜类别模型千变万化,衍生出各式各样的新的模型。研究者如何在众多模型中保证选择恰当的模型应用到自己的研究中,需要对以下方面有所关注。
(1)潜变量和观测变量。研究者需要清楚的了解所研究对象是否可以观测,如果是潜在特质,需要通过哪些外显的行为指标,这些指标是否可靠(如是否需要考虑辅助变量)。(2)连续变量和类别变量。分别从潜变量和观测变量的角度去确定变量的性质,不同的数据特点对应了不同的统计方法(如LCA与IRT的选择)。如果是连续变量,需不需要考虑个体差异(如LCGA与GMM的选择,LCA和MIRT的选择)。(3)是否含有多水平数据。如果被试存在嵌套结构,那么多水平模型便成为研究者的首选;如果这种嵌套结构不明显(随机效应不显著),那么仍然可以使用原有的模型(如CFA和MCFA的选择)。
有了上述的思想,研究者可以进一步的根据自己的研究,选择合适的模型。在横断研究中,探讨总体分群的问题主要采用LCA的方法,以及将LCA与传统的因素分析、IRT相结合的FMA、MIRT等混合的方法;在纵向研究中,LTA解决群间个体的转换规律的问题,而探讨增长趋势的类别则用LCGA或GMM等。除此之外,多水平模型的框架下同样可以探讨横断或追踪研究中的分群,解决嵌套数据结构中总体不同质的问题。
当然,由于该领域还十分年轻,还有很多值得研究者探讨的地方。比如在类别数量的确定上一直存在的争论,以及协变量对分类的影响,都有待进一步的讨论。潜类别模型会成为统计模型发展的一大趋势,对于连续变量无法解决的分群的问题,以及群的转换的问题,潜类别模型会有巨大的发展空间。
[1]张洁婷,焦璨,张敏强.潜在类别分析技术在心理学研究中的应用[J].心理科学进展,2010,18(12).
[2]Masyn K E,Henderson C E,Greenbaum P E.Exploring the Latent Structures of Psychological Constructs in Social Development using the Dimensional-categorical Spectrum[J].Social Development,2009,19(3).
[3]邱皓政.潜在类别模型的原理和技术[M].北京:科学技术出版社,2008.
[4]Muthén L,Muthén B.Mplus User's Guide(Seventh Edition)[M].Los Angeles,CA:Muthén&Muthén,2012.
[5]焦璨,张洁婷,关丹丹等.2007~2009年研究生心理学专业基础综合考试的潜在类别分析[J].中国考试,2010,(4).
[6]De Meyer G,Shapiro F,Vanderstichele H.DIagnosis-independent Alzheimer Disease Biomarker Signature in Cognitively Normal Elderly People[J].Archives of Neurology,2010,67(8).
[7]Muthén B.Should Substance use Disorders be Considered as Categorical or Dimensional?[J].Addiction,2006,101(Supplenent S1).
[8]Thomas M L,Lanyon R I,Millsap R E.Validation of Diagnostic Measures Based on Latent Class Analysis:A Step Forward in Response Bias Research[J].Psychological Assessment,2009,21(2).
[9]Maij-de Meij A M,Kelderman H,Van Der Flier H.Fitting a Mixture Item Response Theory Model to Personality Questionnaire Data:Characterizing Latent Classes and Investigating Possibilities for Improving Prediction[J].Applied Psychological Measurement,2008,32(8).
[10]Muthén B.Latent Variable Modeling in Heterogeneous Populations[J].Psychometrika,1989,54(4).
[11]Asparouhov T,Muthén B.Multilevel Mixture Models,in Advances in Latent Variable Mixture models[R].Hancock G R,Samuelson K M,Editors.Charlotte,NC:Information Age Publishing,2008.
[12]Muthén B,Muthén L,Asparouhov T.Latent Variable Modeling using Mplus[R].Beijing:National Survey Reserach Center at Renmin University of China,2012.
[13]Muthén B O.Beyond SEM:General latent Variable Modeling[J].Behaviormetrika,2002,29(1).
[14]Raudenbush S W,Bryk A S.Hierarchical Linear Models:Applications and data Analysis methods(2nd ed)[M].Thousand Oaks,California:Sage Publications,2002.
[15]Willett J B,Sayer A G.Using Covariance Structure Analysis to Detect Correlates and Predictors of Individual Change Over Time[J].Psychological Bulletin,1994,116(2).
[16]Nagin D S.Analyzing Developmental Trajectories:A Semiparametric,Group-based Approach[J].Psychological Methods,1999,4(2).
[17]Muthén B,Brown C H,Booil Jo K M,et al.General Growth Mixture Modeling for Randomized Preventive Interventions[J].Biostatistics,2002,3(4).
[18]Yampolskaya S,Armstrong M T,King-Miller T.Contextual and Individual-levelPredictors ofAbused Children's Reentry Into out-of-home care:A Multilevel Mixture Survival Analysis[J].Child Abuse&Neglect,2011,35(9).
[19]Vermunt J K.Latent Class Modeling with Covariates:Two Improved Three-step Approaches[J].Political Analysis,2010,18(4).
[20]Steinley D,Brusco M J.Evaluating Mixture Modeling for Clustering:Recommendations and Cautions[J].Psychological Methods,2011,16(1).
[21]Bolck A,Croon M,Hagenaars J.Estimating latent Structure Models with Categorical Variables:One-step Versus Three-step Estimators[J].Political Analysis,2004,12(1).
[22]Asparouhov T,Muthén B.Auxiliary Variables in Mixture Modeling:A 3-step Approach using Mplus[R].in Mplus Web Notes,No.15,2012.
猜你喜欢
河池学院学报(2021年1期)2021-07-10 05:14:02
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
英语文摘(2019年2期)2019-03-30 01:48:40
中华手工(2018年6期)2018-07-17 10:37:42
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
新校长(2016年8期)2016-01-10 06:43:59
中国卫生(2015年7期)2015-11-08 11:09:50
商事法论集(2014年1期)2014-06-27 01:20:42
