
对答结构的标注与应用研究
——以汉语(二语)教学会话体语料为例*
2015-02-14 02:01:52杨丽姣徐丽芳北京师范大学中文信息处理研究所北京00875中国专利信息中心北京00088同方知网北京技术有限公司北京009
云南师范大学学报(对外汉语教学与研究版) 2015年3期
杨丽姣, 熊 文, 徐丽芳(.北京师范大学 中文信息处理研究所,北京 00875;.中国专利信息中心,北京 00088;.同方知网(北京)技术有限公司,北京009)
对答结构的标注与应用研究
——以汉语(二语)教学会话体语料为例*
杨丽姣1, 熊 文2, 徐丽芳3
(1.北京师范大学 中文信息处理研究所,北京 100875;2.中国专利信息中心,北京 100088;3.同方知网(北京)技术有限公司,北京100192)
研究针对汉语(二语)教学会话体语料语义功能的检索需求,基于汉语国际教育动态语料库,探讨了一种语料库语言信息标注框架。围绕日常口语交际的主要目的以及教学范围,提出19类对答结构,刻画了引发语与应答语的基本形式。以此为基础,开展对答结构的自动识别算法研究,选取问候、感谢、祝贺、赞扬、介绍5个类别进行试验,实验测试在准确率和召回率上均取得较好的成绩。对答结构的标注框架对于会话体语料相关表达式的抽取具有较好的适应性,自动识别算法可用于语言信息的自动抽取以及语料库扩展应用软件研发等。
汉语二语教学;标注框架;对答结构;语义功能;自动识别
一、引 言
口语交际是二语教学的关键内容。在教学上,人们不仅关心如何说(即语法)以及说什么(即词汇)的问题,还关心怎样得体地表达(即交际运用)。程棠(1996)*程棠. 关于 “结构—功能—文化相结合”的教学原则的思考[J]. 世界汉语教学,1996,(4).提出,汉语(二语)教学的基本任务是培养外国学生用汉语进行社会交际的能力,要获得社会交际能力,除了掌握相当的词汇量、语法构式外,学生要懂得在特定语境中如何正确而得体地使用汉语。*关于语境(Context)概念,一直以来,具有不同研究背景与研究目的的学者不断给其下定义。大体而言,可以从两个维度理解语境所包含的信息。从纯语言学的维度出发,语境信息指向言内,涉及与一个词或句子的上下文有关的语言材料。从语用学或话语取向研究出发,语言的理解要结合语言发生的情景,语境信息指向言外,这也就是所谓的言内语境和言外语境之分。他们需要了解,中国人在一般日常交际场合下,如何根据不同交际目的选择或调整会话内容?比如,对于他人的夸奖,是以“哪里、哪里”式的自谦作为回应,还是以感谢、回赞等表达作为应答。交际目的、交际场合、交际对象、交际心理等语境差异对于会话开始、结束时的语言表达往往形成了一些模式。这些模式在二语教学大纲中以功能项目列表的方式进行解释,但交际功能项目是对句子的语言表达功能的静态抽取,在动态的交际进程中,如何根据对话的推进或变化模式进一步审视语言的表达功能?
研究基于汉语(二语)教学会话体语料,梳理汉语二语教学大纲的基本交际功能项目,在会话进程中描述对答结构的内涵,提出对答结构的标注框架,并抽取语言特征与识别模式,开展对答结构自动识别的实验研究。
在自然语言处理研究中,词义以及句法结构语的标注与自动识别算法相对成熟,语用层面的研究较为薄弱,针对什么样的目的和内容,在什么单位上进行语用信息的标注与自动识别,相关研究不多见。对答结构的语义功能属于语用层面的语言信息,是语境要素的构成,本文的讨论是对这方面研究的一个粗浅尝试。
在应用上,对语义功能的标注可以丰富语料库语言信息的标注层次,可供语料库检索与交际情景密切相关的各类语言表达以及关键词。在语料达到相当规模时,还可以统计语义功能的出现频率及多样性,获取更多研究数据。对答结构的自动切分以及自动识别算法研究,也可用于语料自动抽取,以及汉语(二语)教材编写辅助系统、自主学习系统等语料库扩展应用工程的研发。
二、动态语料库概况
研究的基础是汉语国际教育动态语料库(简称动态语料库)*汉语国际教育领域的语料库建设一直集中于各类中介语语料库。中介语语料库关注学习者的语言使用信息,针对学习者语言应用中的偏误情况进行标注,内容包括字、词、句、篇各级单位中的各类错误。要了解正确的、不同层次的语言信息,无论是学生和教师,可供选用的语料库尚待研发。现有一些语料库或数据库以教材中典范的文本资源为语料采集对象,供用户检索的内容仅仅是语料的字频、词频以及句长、教材背景等粗略的信息等。(可参看“全球汉语教材库”(http://www.ctm-lib.com/);“国际汉语教学数据库”(http://tpi.cie.muc.edu.cn/),该语料库以经典汉语(二语)教材为主要采集对象,收录了国家汉办发布的部分HSK考题文本语料。还收录少量经典中小学语文教材以及通用自然语料以供对比之用。经过自动分词以及词性校对,目前入库的句子数据库接近20万句。构成比例见表1:
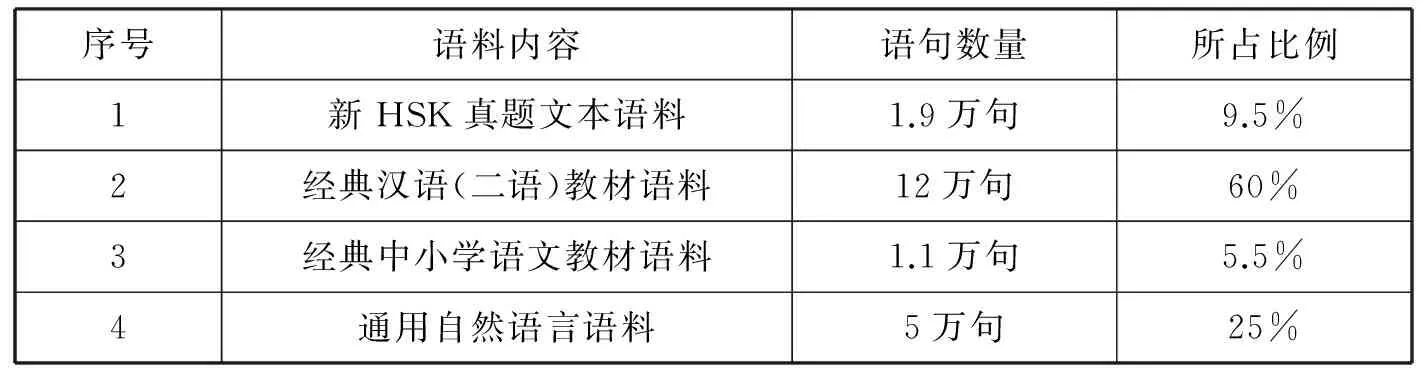
表1 语料库的语料构成
动态语料库由3个子库组成:生语料库、熟语料库、元数据库。
生语料库以句子的形式存储所收集的全部语料。以教材语料为例,每个句子的属性信息包括ID号、句子内容、段落号、课文名、单元名以及教材名。在生语料库中,可以通过ID找出句子的上下文、相关段落或语篇,因此,语言特征的抽取或语料标注范围可以跨越句子进行。
熟语料库是在人工标注与计算机辅助标注基础上,再经人工校对的语料。用户可以根据需要,检索词义、句法语义综合信息以及语用层面的相关语言信息。
元数据库以教材为例,属性信息包括书名、责任者、出版时间、出版社、适用对象、适用水平、教材类型。
汉语(二语)经典教材语料是语料库的核心组成,语料采集考虑教材类型、适用水平、出版年代、影响因子等属性特征。从教材类型上说,以通用型、综合类教材为主,这类教材多采用书面化的口语,反映汉语(二语)教学典范的语言形式。此外,也补充以听、说、读、写单项技能训练为主要目标的教材以及少量专门用途教材(如医用汉语教材、商务汉语教材)、文化教材等以反映特定领域的教材用语面貌。
汉语(二语)教学在2000年前后进入发展的快速通道,相应地,汉语(二语)教材数量激增。动态语料库以2000年以后的教材为主,并收录少量20世纪60年代至20世纪90年代的经典教材,以供历时考察比较的需要。
动态语料库建设面向汉语(二语)教学与研究的信息检索需求,结合计算机语言信息自动识别的探索,设定标注框架。标注体系分为词义标注、句法语义综合标注、语境信息标注三个层次。对答结构的语义功能是语境信息标注的重要内容。一般而言,语料标注的过程也就是是对语料中语言单位的特征进行解释的过程,不同的人可能会有不同的解释结果。(崔刚等,2000)*崔刚,盛永梅.语料库中语料的标注[J]. 清华大学学报(哲学社会科学版),2000,(1).对答结构语义功能的标注针对动态语料库中的会话体语料进行,抽取交际进程过程中反映特定交际目的,体现话语交际合作原则、礼貌原则等基本原则的句子。
三、对答结构的内涵及标注内容
(一)对答结构的内涵与边界
要实现对答结构的标注与自动识别,首先要研究会话的单位,明确对答结构的语言范围。对答结构研究是会话研究的子课题。早期进行会话研究的美国学者Sacks、Schegloff和Jefferson提出过话轮、邻近对和序列等概念,俄罗斯语言学家雅库宾斯基提出了“对语”这一概念。他认为“言语交际的对话形式是指相互作用的个人行动和反应的相对迅速的交替”,每一次交替就是一个对语。*徐翁宇.俄语对话分析[M]. 北京:外语教学与研究出版社,2008:27~28.实际上,大多数学者都倾向将毗邻应对当作会话的基本单位,它由两个前后相邻的话轮构成,两个话轮要由不同的参与者说出,第一个话轮要求有特定的第二个话轮与它相配,比如提问—回答。在汉语(二语)教学领域,刘虹(2004)描写了领域内对答结构的基本面貌。*刘虹.会话结构分析[M]. 北京:北京大学出版社, 2004:103~140.在本研究中,对答结构是指以会话体语料为标注对象的,主要由邻近对构成、展现了基本交际功能的语言表达框架,如问候、介绍、欢迎、建议及其不同的回应。有时,对答结构也会跨越一个邻近对,由两组以上不同话轮构成的连续语句构成。例如:
医生:你哪儿不舒服?
病人:我全身都不舒服。
医生:全身都不舒服?说具体一点。
病人:没胃口,吃不下。
上例中医生的引发语是询问“结果或情况”,病人作了说明性回应,接下来医生继续追问,病人进一步作说明性回应。对话的前两个话轮和后两个话轮,在作对答结构自动切分时,容易被处理为两个单位,因为它们在结构上是完整的,都包括引发语和应答语,在语义上也是完整的,都有询问和结果。但在上下文语境中,后一组对话与前一组关系密切,推进了前一组对话引发的话题。理想的状态是将4个话轮切分为一个对答结构,统一标注其语义功能:询问“结果/情况”(引发语)——说明性回应(应答语)。在处理这类对答结构时,要重点考虑句子的常规焦点在话轮中的复现,以此作为跨越邻近对的对答结构自动切分的重要激活因子。
对答结构的特点可以归纳为:
(1)由两个或两个以上分属不同话轮的连续语句构成。
(2)这些连续语句分别由两个或两个以上的人说出。
(3)连续语句中的引发语和应答语相互关联,引发语对应答语的生成和选择有一定的制约。
这些对答结构又可分为毗邻双部式和毗邻多部式。毗邻双部式由相邻的引发语和应答语两个部分构成,是对答结构的基本形式。毗邻多部式对答由分属不同话轮的两个以上的相邻语句构成的,结构中部分话轮兼有上一部分应答语的功能和下一部分引发语的功能,起到了承上启下的作用。
(二)对答结构的标注内容
根据国家汉办《高等学校外国留学生汉语言专业教学大纲》功能项目列表以及汉语(二语)教学会话研究成果,研究初步确定对答结构的标注框架,然后在一定范围进行语料试标,检验框架的适应性。*国家对外汉语教学领导小组办公室. “高等学校外国留学生汉语言专业教学大纲”附表四,功能项目表[S]北京:北京语言文化大学出版社,2002.根据标注反馈,区分19种核心的对答结构,其引发语分别是:问候/寒暄、介绍、欢迎、告别、建议/商量、邀请、请求、要求、感谢、赞扬、祝贺、祝愿、责怪、通知/转告、提醒/警告、道歉、抱怨、询问。而这些引发语的对答语各不相同,见表2示例。
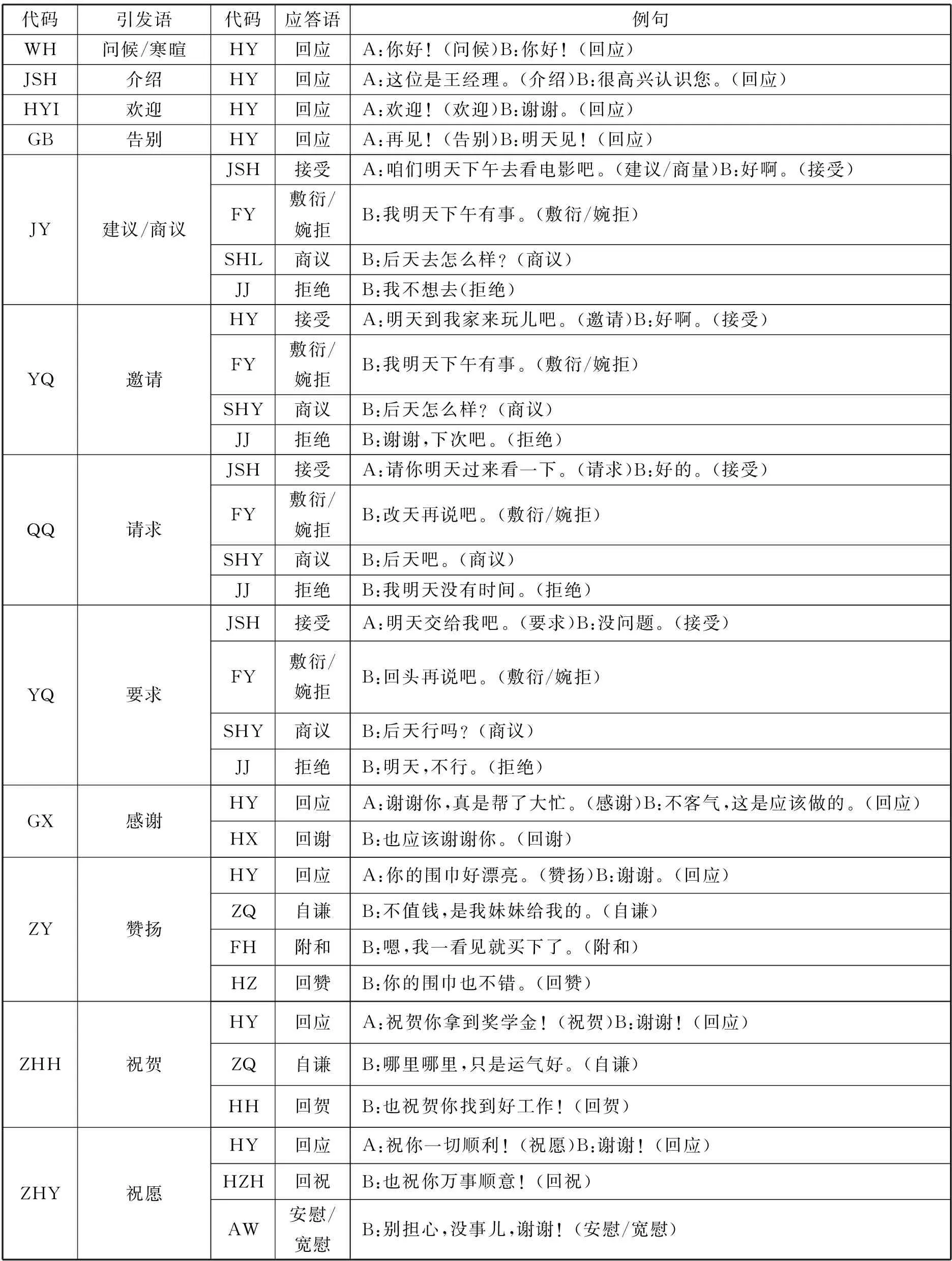
表2 对答结构的标注框架
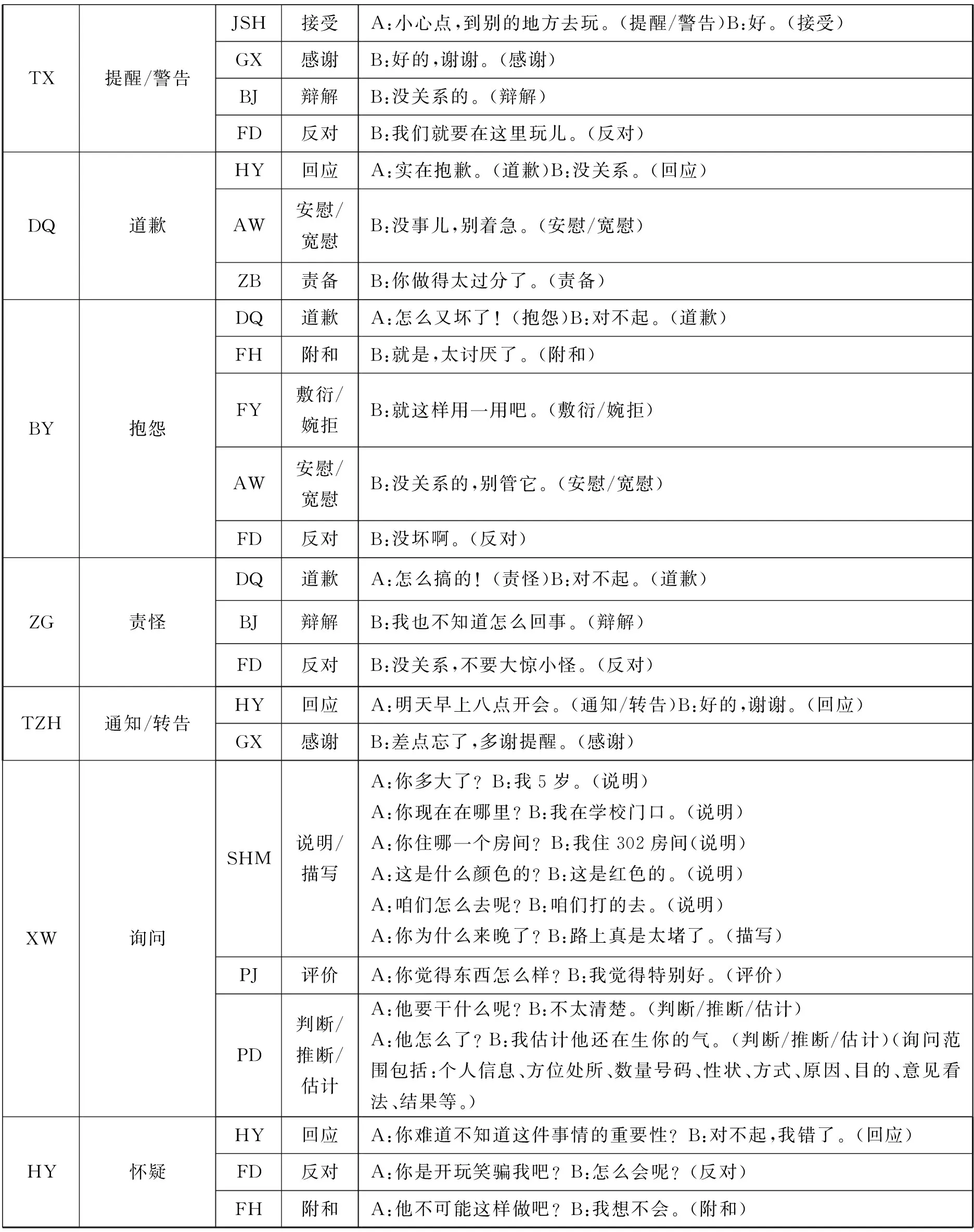
TX提醒/警告JSH接受A:小心点,到别的地方去玩。(提醒/警告)B:好。(接受)GX感谢B:好的,谢谢。(感谢)BJ辩解B:没关系的。(辩解)FD反对B:我们就要在这里玩儿。(反对)DQ道歉HY回应A:实在抱歉。(道歉)B:没关系。(回应)AW安慰/宽慰B:没事儿,别着急。(安慰/宽慰)ZB责备B:你做得太过分了。(责备)BY抱怨DQ道歉A:怎么又坏了!(抱怨)B:对不起。(道歉)FH附和B:就是,太讨厌了。(附和)FY敷衍/婉拒B:就这样用一用吧。(敷衍/婉拒)AW安慰/宽慰B:没关系的,别管它。(安慰/宽慰)FD反对B:没坏啊。(反对)ZG责怪DQ道歉A:怎么搞的!(责怪)B:对不起。(道歉)BJ辩解B:我也不知道怎么回事。(辩解)FD反对B:没关系,不要大惊小怪。(反对)TZH通知/转告HY回应A:明天早上八点开会。(通知/转告)B:好的,谢谢。(回应)GX感谢B:差点忘了,多谢提醒。(感谢)XW询问SHM说明/描写A:你多大了?B:我5岁。(说明)A:你现在在哪里?B:我在学校门口。(说明)A:你住哪一个房间?B:我住302房间(说明)A:这是什么颜色的?B:这是红色的。(说明)A:咱们怎么去呢?B:咱们打的去。(说明)A:你为什么来晚了?B:路上真是太堵了。(描写)PJ评价A:你觉得东西怎么样?B:我觉得特别好。(评价)PD判断/推断/估计A:他要干什么呢?B:不太清楚。(判断/推断/估计)A:他怎么了?B:我估计他还在生你的气。(判断/推断/估计)(询问范围包括:个人信息、方位处所、数量号码、性状、方式、原因、目的、意见看法、结果等。)HY怀疑HY回应A:你难道不知道这件事情的重要性?B:对不起,我错了。(回应)FD反对A:你是开玩笑骗我吧?B:怎么会呢?(反对)FH附和A:他不可能这样做吧?B:我想不会。(附和)
在标注实践中,引发语或应答语最多可以标注两个语义功能项目。比如“你真是太棒了,谢谢!”既表达赞扬,也表示感谢,二者均需标注出来。
明确对答结构的边界特征以及“引发语—应答语”的构成类型,为对答结构的自动识别算法奠定了基础。对答结构的自动识别算法可用于在更大的范围内检索同类语料,实现汉语国际教育语料库检索信息的动态更新。
四、对答结构的自动识别算法及实验
会话体和叙述体是汉语(二语)教材的基本语体。此前的研究针对叙述体语料提出了话题标注框架以及自动识别话题的算法(杨丽姣、熊文,2014)*Lijiao Yang,Wen Xiong. Topics Tagging and Automatice Identification of TCSL corpus, 2013 Asian Conference on the Social Sciences(ACSS 2013)[A].Singapore:先进社会与行为科学(ISSN:2339-5133),2014,(4).。针对会话体语料,研究提出对答结构语义功能的标注体系以及如下基于规则的、上下文相关的语义功能自动识别算法。
具体算法如下:
1.加载n条自动识别规则
2.加载语义特征知识库
3.对输入的m条会话体对答句进行分词和语义特征项加载
4.对内存中的每一条规则rule[i],i=0,...,n
(1)对会话体对答句中的每一句sentence[j],j=0,...,m,判别所属的类别category[j]
(2)累加所有句子的类别,取出现次数最多的类别作为最终的类别
下面,本文以类别“邀请”(代码为YQ)为例,给出自动识别规则:
YQ=[YQ1]+{JSH}+{FY}+{SHY}+{JJ}
YQ1={时间词}+[到|来]+[语气词]+<。>
JSH=<好>+[语气词|的]+<。>
FY={代词}+[<有>+<事>|<忙>]+<。>
SHY={时间词}+[怎么样]+<。>
JJ=<谢谢>+<时间词>+<吧>+<。>
上述算法中,符号“[ ]”表示其中内容至少出现一次,符号“{ }”表示其中内容出现零次到多次,符号“< >”表示其中内容只出现一次,符号“+”表示中间可出现其他词语。
本文采用了前向最大分词算法对句子进行分词,同时根据知识库中的词条所对应的语义项,给每个分词单位一个或多个词性。以下以“邀请”对答结构为例,介绍具体的处理过程。其过程如下:
1.输入内容为:
A:明天到我家来玩儿吧。
B:我明天下午有事。谢谢,下次吧。
(其中,A:表示说话者甲,B:表示说话者乙)
2.分词和语义特征加载,内容为:
A:明天<时间词/>到我<代词/>家来玩儿吧<语气词/>。
B:我<代词/>明天<时间词/>下午<时间词/>有事。谢谢,下次<时间词/>吧<语气词/>。
3.规则匹配过程:
A:明天<时间词/>到我<代词/>家来玩儿吧<语气词/>。
根据“时间”、“到”、“来”、“吧”,匹配上规则“邀请”,代码为YQ1。
B:我明天<时间词/>下午<时间词/>有事。
根据“我<代词/>”、“有+事+。”,匹配上“敷衍/婉拒”规则,代码为FY。
谢谢,下次<时间词/>吧<语气词/>。
根据“谢谢”、“时间+吧+。”,匹配上“拒绝”规则,代码为JJ。
由于上面3句匹配上了“邀请”的规则,这3句被识别为“邀请”的对答结构。根据它们匹配的不同规则A被输出YQ,表明其是邀请的引发语。B的第一句被标为FY,第二句被标为JJ,表明B的应答是敷衍和拒绝。算法中规则是判断的关键,只要匹配上规则就可以判断句子是属于哪种对答结构。
为验证算法的有效性,研究从18种对答结构框架中选取问候、介绍、感谢、祝贺、赞扬5种作为测试对象,并随机抽取汉语国际教育动态语料库中5000个句子为测试语料。
测试对象的选择主要考虑以下因素:第一,常用性。即该对答结构与留学生的学习生活息息相关,使用频率高;第二,差异性。由于文化的差异带来交流沟通方式以及言语表达的差异,在测试对象中具有较好的体现;第三,可行性。研究首选有语言规律可循、易结合具体算法实现较大范围自动识别的对象展开研究。
具体步骤如下:第一,对5000句语料进行人工标注,将其中的问候、介绍、感谢、祝贺、赞扬对答结构标注出来,做好记录并将其作为参考答案;第二,用自动识别算法对测试语料进行识别与标注;第三,将自动识别与标注的结果与人工标记的结果作对照,记录识别的数量、正确识别数量。根据公式1与公式2计算识别的正确率与召回率。
公式1:正确率=正确识别数/识别数
公式2:召回率=正确识别数/应识别数
5000句的实验结果如下表所示:

表2 实验数据
从最终的测试结果来看,问候、感谢、祝贺、赞扬这4种对答结构自动识别的正确率都达到80%,召回率都达到70%以上,效果较好。而介绍类对答结构识别率偏低,这与该类结构中的核心表达式语义功能的泛化有较大关联(如“是”字句)。总体而言,研究提出的算法对这五类对答结构的自动识别有较好的适应能力和处理效果。由于试验的基础语料数量较少,未来有相当的空间可以扩充语料,改进知识库,细化规则,进一步提高自动识别成绩。
五、应用分析
研究利用汉语(二语)教材会话体语料,分析日常交际情境下的主要会话模式,描述了18类对答结构的语言框架,选择其中的5个类别,在对答结构自动切分基础上开展语义功能的自动识别算法试验,检测结果表明相关算法的有效性。
研究是利用语料库语言信息,提升数字化汉语(二语)教学水平的一种尝试。纵观目前已经建成并有限度开放的大型汉语语料库,如CCL语料库、国家语委语料库等,这些语料库主要为用户提供目标字词的检索功能,服务于语言学学术研究、词典编撰以及语言信息处理。要满足汉语(二语)教师对语言信息的多层次、细化的需求,就需要思考语料库语言信息的标注层次与标注框架,建设专门用途语料库或对现有语料库资源进行深度挖掘,并结合自然语言处理自动算法研究,面向汉语(二语)教学活动、教材编写、自主学习等领域需求,搭建语言信息综合检索以及应用研发平台。当前,利用语料库语言资源开发汉语(二语)教学资源平台的研究方兴未艾*林进展等.数据驱动(Data driving)汉语(二语)学习应用平台的研发,数字化汉语教学[A].北京:清华大学出版社,2014.。
对答结构的标注与自动识别,主要服务于汉语国际教育动态语料库语言信息的多维标注、自动抽取以及语料库扩展应用系统研发等,但不仅限于此。概括如下:
(1)对答结构的标注框架是对日常交际中发话与应答基本模式的概括,为汉语(二语)教材编写或教学活动中的功能项目表达式提供了新的框架。在标注框架下抽取关键词及常用表达式的特征,可细化现有教学大纲中的功能项目说明。
(2)对答结构的标注框架,可用于计算一定规模语料库中,语言表达式与交际对象、交际场合、典型情景之间的适应关系。比如“问候—回应”结构,区分不同对象,熟人与陌生人、长辈与平辈;区分不同场合,正式与非正式场合;区分不同情景,节日情景、人际关怀情景等,在不同语境条件下,其互动模式有何特点。相关数据不仅是二语教学所关心的,也可作为话语分析研究的内容。
(3)“感谢”等5类对答结构的实验结果,将为全面的对答结构语义功能自动识别算法的研究提供基础数据。
(4)对答结构的自动切分以及自动识别可以服务于汉语国际教育动态语料库语言信息的动态更新,语料库扩展应用如教材编写辅助系统、自主学习系统等软件研发。
[责任编辑:张黎玲]
A tagging frame of the question-answer structure and its application: A study of the TCSL conversation corpus
YANG Li-jiao1, XIONG Wen2& XU li-fang3
(1. Institute of Chinese Information Processing,Beijing Normal University,Beijing 100875, China; 2. Chinese Patent Information Center, Beijing 100088, China; 3. TTKN, Beijing 100192, China)
With a consideration of the retrieval requirement of the semantic functions for the conversation style in the dynamic corpus of the international Chinese education, this paper explores a tagging frame for the corpus-based language information. Focusing on the major goals in daily conversations and the relevant teaching domains, this frame brings up nineteen categories of question-answer structures and describes the basic forms of questions and answers. With this, it discusses an automatic recognition algorithm for the question-answer structures by selecting five categories such as greeting, thanking, congratulating, praising, and introduction as the research objects. The results show that it is fairly satisfactory in terms of accuracy and recall rate as well as applicable in the automatic retrieval of the language information and related studies.
Teaching Chinese as Secondary Language; tagging frame; question-answer structure; semantic function; automatic recognition
国家高技术研究发展计划(863计划)“海量文本多层次知识表示及中文文本理解应用系统研制”(2012AA011104)。
杨丽姣,女,白族,云南个旧人,北京师范大学副教授,博士,研究方向为汉语国际教育、语料库语言学研究。
H195
A
1672-1306(2015)03-0045-08
猜你喜欢
特别健康(2018年3期)2018-07-04 00:40:18
海外华文教育(2016年1期)2017-01-20 08:21:58
发明与创新(2016年26期)2016-08-22 03:23:28
外语教学理论与实践(2016年2期)2016-06-11 01:49:46
电测与仪表(2016年6期)2016-04-11 12:06:38
疯狂英语(双语世界)(2016年2期)2016-02-27 10:11:16
疯狂英语(双语世界)(2015年1期)2016-01-08 06:07:21
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
华北水利水电大学学报(社会科学版)(2015年3期)2015-02-28 15:08:12
民族古籍研究(2014年0期)2014-10-27 08:24:34
