
基于JST模型的新闻文本的情感分类研究
2015-02-11 02:10潘云仙
郑州大学学报(理学版) 2015年1期
潘云仙, 袁 方
(1.河北大学 计算机科学与技术学院 河北 保定 071000;2.河北大学 数学与信息科学学院 河北 保定 071000)
基于JST模型的新闻文本的情感分类研究
潘云仙1, 袁 方2
(1.河北大学 计算机科学与技术学院 河北 保定 071000;2.河北大学 数学与信息科学学院 河北 保定 071000)
使用JST模型对中文新闻文本进行情感分析,相对于评论文本,新闻文本主观性比较弱,而且大多是长文本,会影响JST模型的分类性能.给出一种抽取情感主题句的方法,将抽取得到的情感主题句结合现有的JST模型对新闻文本的情感倾向进行了分析.实验表明,使用情感主题句进行情感分析,避免了与主题情感无关的句子对分析结果的影响,提高了分类准确率.
情感分析; JST模型; 褒贬义词典; 情感主题句抽取
0 引言
文本情感分析是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[1].情感分析的主要任务是处理网络上用户主动发布的与主题相关的文本,识别出文本中所包含的主观性句子,并对其情感趋势进行判断[2].这就引申出情感分析的研究重点:主客观文本分类和主观性文本的情感倾向性分类.文本的主客观分类是将文本分为主观文本和客观文本两类.主观文本带有感情色彩,客观文本陈述事实.Yu Hong等[3]提出了一个以词语为特征的朴素贝叶斯分类器来完成篇章级的主客观文本分类.Pang Bo等[4]采用基于图的最小割分类算法完成句子级的主客观分类.姚天昉等[5]对中文的主客观文本分类进行了研究分析.林慧恩等[6]初步探索了中文文本的主观性信息提取方法,采用了主观线索和主观模式相结合的方法来提取主观信息.
目前,主观性文本的情感倾向性分类主要有基于规则的方法和基于统计的方法.基于规则的情感分析方法,成本高、工作量大,并且由于新词的不断出现和表达方式的变化,使得这种方法可扩展性差.因此基于统计的情感分析方法更多地被学者采用.文[7]采用机器学习方法对电影评论进行分类,比较了朴素贝叶斯、最大熵、支持向量机方法的分类准确率,实验结果显示支持向量机取得了最佳分类效果,分类准确率最高达到82.9%.文[8]使用朴素贝叶斯和最大熵方法进行了基于情感的新闻文本分类研究,其中最大熵方法的准确率在多数情况下要高于贝叶斯方法.文[9]给出了一种新的基于网络评论语言学结构的固定情感词元模型,较为明显地提高了情感分类的效率和准确率.文献[10]在LDA模型基础上提出了联合情感/主题模型(joint sentiment/topic model,JST),对每个词采集情感标签和主题标签,最终得到文本的情感分类和潜在主题下的情感词汇.
朴素贝叶斯、支持向量机等方法是有监督的,而JST模型是无监督的.在有监督的机器学习方法中,分类器的训练需要一定数量经过标注的训练样本,然而人工标注过程相对耗时费力,成本高,而无监督的机器学习则无需标注训练样本.另外,有监督的学习方法构造的分类器依赖于训练样本, 当将一个领域中训练的情感分类器转移到另一个领域后,常常无法产生满意的效果,因为在不同的领域,情感的表达是不同的,对于待分类的新闻文本,往往不知道其所属的领域,无法事先用有监督的学习方法构造适应性良好的分类器.无监督的学习方法是对所有样本数据进行分析,不存在领域转移问题.朴素贝叶斯、支持向量机等方法只关注文档的整体情感,没有进行深入分析去探究潜在的主题和相关主题的情感.JST模型是主题情感混合模型,可以对文本进行情感分类和主题识别.因此,本文选用JST模型进行情感分析.
1 JST模型
1.1 模型简介

图1 JST模型框图
JST是文[10]提出的一种基于LDA的新型概率建模框架.JST模型是一个4层盘子模型:文档与情感标签关联,主题与情感标签关联,词与情感标签和主题标签关联,如图1所示.JST模型应用在评论数据集上有不错的效果,但是,目前还未见有人将其应用在新闻文本的情感分析中.本文使用JST模型对中文新闻文本进行情感分析.
JST模型的基本思想:假设语料库中有D个文档,记为C={d1,…,dD};语料库中每个文档用Nd个词的序列表示,记为d=(w1,w2,…,wNd);记语料库中去重后的词汇表中的词汇数量为V,则文档中每个词对应V中的一个索引项;不同的主题个数为T,不同的情感个数为S.生成文档中一个词的过程可归结为3个阶段:① 从带有情感的文档分布πd中选择一个情感标签l;② 在情感标签为l的主题分布θl,d中随机选择一个主题;③ 从带有主题和情感标签的词语分布φ中生成一个词语.
对应图1所示的层次贝叶斯模型,词的生成过程如下[10]:
1) 对每个文档,从参数为γ的狄利克雷分布中抽取多项式分布πd,即采样πd~Dir(γ);
2) 对文档d每一个情感标签,从参数为α的狄利克雷分布中抽取多项式分布θd,l,即采样θd,l~Dir(α);
3) 对文档中的每个词语wi:① 从πd中选择一个情感标签li,即采样li~πd;② 从θd,li中随机选择一个主题标签zi,即采样zi~θd,li;③ 从主题为zi,情感为li的分布φli,zi中选择一个词语wi.
1.2 结合褒贬义词典的JST模型
为了改善JST模型的分类性能, 文[10]通过种子情感词、极性词典等先验知识来提高文档情感分类的准确性.本文采用褒贬义情感词典作为JST模型的先验知识,词典使用HowNet情感词语集,其中中文正面情感词语836个,中文负面情感词语1 254个.
JST算法步骤[10]:
1) 初始化矩阵φ(词语×主题×情感,V×T×S)、矩阵θ(主题×情感×文档,T×S×D)和矩阵π(情感×文档,S×D);
2) 从m=1至M执行吉布斯抽样迭代:
① 从文档中读取一个词,随机赋给词主题标签和情感标签;② 根据
计算情感标签为k和主题标签为j的词语wi的概率;③ 根据②中估计的概率,重新选择一个主题标签j;④ 选择一个情感标签k;⑤ 根据新的抽样结果,更新矩阵φ、θ和π;⑥ 返回执行①,直到处理完所有的词.
采用褒贬义词典作为先验知识后,算法中步骤2)的①变为:从文档中读取一个词,随机赋给词主题标签,将词与褒贬义词典比对,若词与褒贬义词典中的某个词相同,则赋给词相应的情感标签;若不同,则随机赋给词情感标签.
2 情感主题句抽取
为去除与情感主题无关的句子对分析结果的影响,本文给出一种针对新闻文本的情感主题句抽取方法.① 给出适用于新闻的主观线索,对文档中每个句子进行主观句评分;② 使用主题句识别方法,对文档中每个句子进行主题句评分;③ 综合句子的主观句与主题句评分,抽取得分最高的前k个句子,作为此文档的情感主题句.
2.1 主观句评分
新闻具有主观性,是指在再现生活中真实发生的事件过程中,叙述者在新闻事件中表现出来的立场、态度和情感[11].由于受“真实性原则”的制约,新闻叙事总体表现出“低主观度”的特征.文[5]对中文的主客观文本分类进行了研究分析,总结出7条主观线索:情感形容词;第一或第二人称代词;不规范的标点符号;带有感情色彩的标点符号;感叹词;发表意见或看法的动词;不精确的数字和日期.由于新闻叙事的“低主观度”,使得这7条线索并不完全适用于新闻的情感分析.
通过对新闻句子的观察,参考文[11]对新闻叙事的主观性研究,总结出3条适用于新闻的主观线索:
1) 情感形容词集
在《汉语形容词用法词典》中所列的1 063个形容词的基础上,去除主观性强、主观量大的形容词(如卑鄙、自私、慈祥、豪爽等),剩余的707个形容词作为符合新闻特征的情感形容词集.
2) 情态词
情态与主观性是两个密不可分的概念,因此将情态词作为新闻主观线索之一,主要包括以下30个情态词:幸亏、可惜、多亏、竟然、居然、本来、怪不得、难怪、原来、其实、碰巧、偏偏、仿佛、好像、似乎、大概、或许、恐怕、一定、务必、必须、毕竟、反正、当然、的确、果然、确实、到底、千万、难道.
3) 人称指示词
受新闻“还原事实的真实性”要求的制约,新闻中人称指示词“我”的使用受到限制,而代之以第一人称第三人称化的词语“记者”、“采访者”、“目击者”等词语.
采用以上主观线索来对句子进行评分,步骤如下:
1) 对于给定的待测试的句子si,先对其进行分词和词性标注.本文所采用的分词和词性标注工具是由哈尔滨工业大学信息检索实验室开发的LTP中分词及词性标注IRLAS模块;
2) 计算句子si的主观得分.句子si的主观得分等于句子中包含的每一个主观线索的权重之和,
其中,wk表示主观线索k的权重,nk表示句子si中含主观线索k的词汇数.
2.2 主题句评分
使用王伟等人[12]对中文新闻关键事件的主题句识别方法,对主题句进行评分.设新闻中有n个句子, 首先分别计算出特征分量为相对词频(term)、句子位置(loc)、句子长度(len)、命名实体(ne)、句子与标题重合度(ht)的得分.假设句子的特征相互独立,每个句子si(i≤n)的总分是各个特征分量的线性组合.
其中,Scoreht(si)和wht分别是句子与标题重合度的得分和权重,参数λ表示标题分类的结果,它作为开关决定是否使用标题特征.Scorek(si)和wk分别是各个特征分量的得分和权重,其中k∈{term,loc,len,ne}.
2.3 抽取情感主题句
综合主观句与主题句的评分情况,得到句子的最终得分,选取每篇文章中得分最高的前k个句子代替该篇文章,进行情感分析,
Score(si)=μScores(si)+νScoret(si).
3 实验结果及分析
3.1 数据集
由于目前没有针对中文新闻文本进行情感分析评测的标准数据集, 所以本文从网易新闻中下载了400篇关于动物、儿童、环境、教育的新闻,并采用人工标注的方法对这400篇新闻进行情感标注,构造了本文的评测数据集.评测数据集包含正面新闻265篇,负面新闻135篇.
3.2 情感分类
本文实验的情感只考虑褒义和贬义两种,不考虑中性情感.
根据多次实验观察:
当参数α=50/主题数,β=0.01,γ=0.01时,正面效果最好.
当参数α=50/主题数,β=0.01,γ=5时,负面效果最好.
完整文档的语料库中,不同的词语总数为13 471;抽取情感主题句后,语料库中不同词语的总数降为8 675.在没有任何先验知识的情况下,全文和情感主题句的情感分类的正面准确率分别为60.4%和63.9%,负面准确率分别为70.4%和72.2%.将褒贬义词典作为先验知识与JST结合后,全文和情感主题句的正面准确率分别为80.9%和82.3%,负面准确率分别为85.6%和89.0%.从以上数据可以看出,抽取情感主题句后的文档在分类准确率上都有了一定的提高.将抽取得到的情感主题句代替全文进行分析,实际只是保留每篇文档的带有情感的并且与主题相关的句子,故准确率有了提高.
3.3 主题情感发现
发现文本中的主题情感词,根据这些词可以推测潜在的主题和情感,了解语料库中的主题情感分布情况.新闻语料的主题情感发现,不仅可以帮助人们从海量的互联网新闻数据中找到所关注的信息,也可以宏观掌握某段时间的新闻主题和情感倾向,为正确决策提供参考.
使用抽取情感主题句后的文档进行实验,根据词属于相应主题情感标签的概率,分别选取主题1和主题2排名前15的正面词语和负面词语,并给出其对应的概率,见表1.从表1中的词语可以看出,主题1是关于环境的,正面描述词多与环保相关,负面描述词多与污染相关;主题2是关于动物的,正面描述词多与动物保护相关,负面描述词多与动物伤害相关.
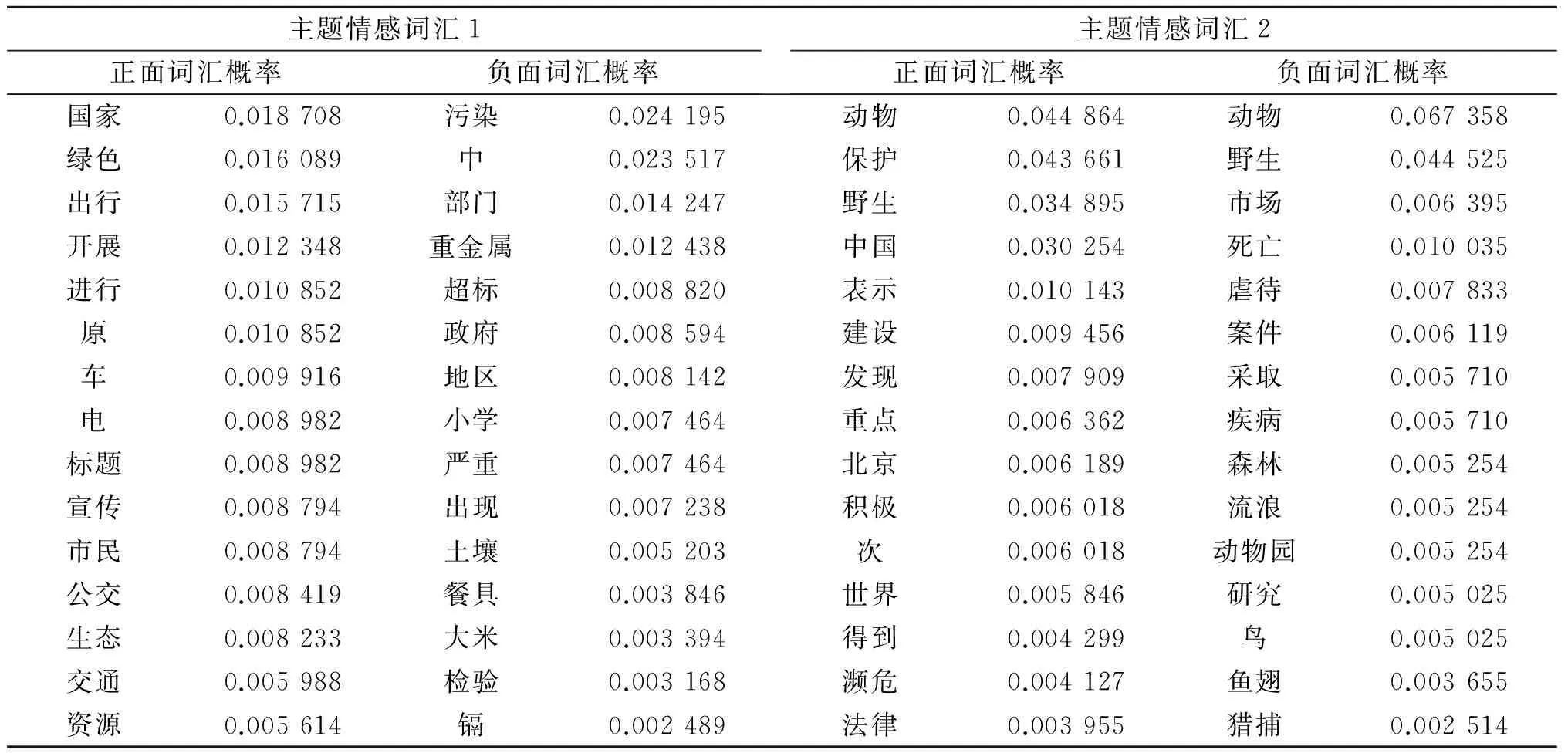
表1 主题情感词汇表Tab.1 Topic/sentiment vocabulary table
4 总结
本文给出一种新闻文本的情感主题句抽取方法,针对抽取得到的情感主题句,结合JST模型对新闻文本进行了情感分类和主题识别.实验验证了JST模型在中文新闻数据集上的可用性,使用抽取到的情感主题句进行情感分析,避免了与主题情感无关的句子对分析结果的影响,有效提高了新闻情感分析的准确性.
[1] 赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848.
[2] 周立柱,贺宇凯,王建勇.情感分析研究综述[J].计算机应用,2008,28(11):2725-2728.
[3] Yu Hong,Hatzivassiloglou V. Towards answering opinion questions:separating facts from opinions and identifying the polarity of opinion sentences[C]//Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing.USA:Morristown,2003:129-136.
[4] Pang Bo,Lee L. A sentimental education:sentiment analysis using subjectivity summarization based on minimum cuts[C]//Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. USA: Stroudsburg,2004:271-278.
[5] 姚天昉,彭思崴.汉语主客观文本分类方法的研究[C]//第三届全国信息检索与内容安全学术会议.苏州,2007:117-123.
[6] 林慧恩,林世平.中文情感倾向分析中主观句子抽取方法的研究[C]//全国第20届计算机技术与应用学术会议(CACIS·2009)暨全国第1届安全关键技术与应用学术会议.南宁,2009:379-384 .
[7] Pang Bo,Lee L,Vaithyanathan S. Thumbs up? sentiment classification using machine learning techniques[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing.USA:Philadelphia,2002:79-86.
[8] 徐军,丁宇新,王晓龙.使用机器学习方法进行新闻的情感自动分类[J].中文信息学报,2007,21(6):95-100.
[9] 张素智,樊得强,李宝燕.基于网络评论语言学结构的情感倾向识别模型[J].郑州大学学报:理学版,2011,43(1):80-84.
[10] Lin Chenghua,He Yulan. Joint sentiment/topic model for sentiment analysis[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management. USA: New York,2009:375-384.
[11] 李凌燕.新闻叙事的主观性研究[D].上海:复旦大学,2010.
[12] 王伟,赵东岩,赵伟.中文新闻关键事件的主题句识别[J].北京大学学报:自然科学版,2011,47(5):789-796.
News-text Sentiment Classification Research Based on JST Model
PAN Yun-xian1, YUAN Fang2
(1.SchoolofComputerScienceandTechnology,HebeiUniversity,Baoding071000,China;2.CollegeofMathematicsandInformation,HebeiUniversity,Baoding071000,China)
JST model was used to analyze sentiment of Chinese news text. Compared with that of comment text, the subjectivity of news text was relatively weak. And most of the news text was long.To meet these challenges in the classification performance of JST model, a method was presented to extract the sentiment topic sentence, and then combined the extracted sentences with the existing JST model to analyze sentiment tendencies of news texts.The experimental results showed that analyzing sentiment in the extracted sentences avoided the influence of irrelevant sentences. Therefore, precision of classification was improved.
sentiment analysis; JST model; appraise dictionary; sentiment topic sentence extraction
2014-11-08
国家自然科学基金资助项目,编号61170039;河北省软科学研究计划项目,编号12457206D-11, 12457202D-63.
潘云仙(1989-),女,河北鹿泉人,硕士研究生,主要从事数据挖掘研究,E-mail:panyunxian@126.com;通讯作者:袁方(1965-),男,河北安新人,教授,博士,主要从事数据挖掘、社会计算研究,E-mail:yuanfang@hbu.edu.cn.
TP181
A
1671-6841(2015)01-0064-05
10.3969/j.issn.1671-6841.2015.01.014
猜你喜欢
客联(2022年3期)2022-05-31
中共云南省委党校学报(2022年1期)2022-04-26
中国新闻周刊(2021年26期)2021-07-27
小学生优秀作文(低年级)(2020年4期)2020-07-24
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
电脑爱好者(2017年7期)2017-05-06
北极光(2016年6期)2016-08-17
Coco薇(2015年11期)2015-11-09
