
论高校“学生评教”结果的统计与应用——以昆明某高校为例
2015-01-15 06:21:30唐云张丽雯寸丽仙
亚太教育 2015年10期
文/唐云 张丽雯 寸丽仙
学生对任课教师教学水平(包括教学态度、内容、能力、效果等方面)的评价(简称“学生评教”)是高校教学管理工作中的一个重要环节,是高校教学质量评价的重要手段,对促进高校教学改革,提高教学质量具有十分重要的意义。
一、昆明某高校“学生评教”结果统计分析与应用的现状
(一)“学生评教”结果的应用
无论如何强调学生评教的重要性,一所学校是不是真的把握住了这个重要性的实质,关键就看学生评教结果有没有被使用,是如何被使用的——有没有真正把之看作衡量教师教学质量的重要指标;有没有将之向教师反馈,作为教师改进提升教学质量的依据;有没有将之与教师的有关评优评奖作恰当的关联。
经了解,在该校的学校层面,只有每年一次的红云园丁奖优秀课堂教学奖的评选要求有学生评教的结果,其他方面的评优评奖包括教师职称的晋升都没有此类要求。那么在各教学院系内部的有关评选中,学生评教结果的应用情况又如何呢?
我们在该校19 个教学院系中随机抽取了9 个院系,采用当面访谈或网络访谈的方式,了解了各院系对学生评教结果的应用情况,结果如下:
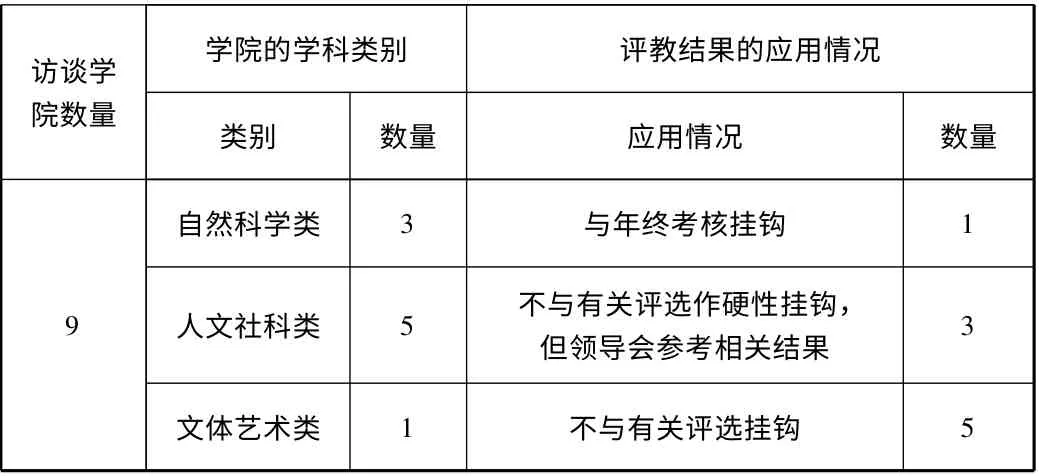
表1 访谈院系评教结果的应用情况
由上表可知,学校乃至教学院系对“学生评教”结果的应用并不充分,这种状况似乎体现了对此项工作的重视不够,但这仅仅是主观方面的原因吗?
(二)“学生评教”结果的统计
该校的“学生评教”是由多个学生按统一指标体系对不同教师进行评价打分,对每一位受评教师而言,自己得到的评价结果需要在这些给自己打的分数的基础上统计分析得到,而统计质量会影响到评教结果的价值,继而影响其应用性。这可能是学校对“学生评教”结果整体应用不充分的另一个原因。
在上文提到的对“学生评教”结果应用的两种情况——全校优秀课堂教学奖的评选和个别院系的年终考核中,对“学生评教”结果的要求是参与对某个教师评价的各个学生所打分数的平均数。平均数无疑是应用最广泛的集中统计量,充分使用了各观测值(指各个学生所打的单个分数)的信息,综合体现了各参评学生对受评教师的评价,将其值大小作为评判教学质量的标准似乎也是应有之义。但在这里,直接使用原始观测值的平均数作为评判标准却有着其实很明显的缺陷。
其一,对各位受评教师而言,他们的评价者(参评学生)在很大可能是完全不一样的。不同的评价者意味着不同的评价尺度,而不同的评价尺度下相同分数的“含金量”也很可能是不一样的。如可能存在这样的情况:Z 老师在某个学期获得的学生评教分数的平均值是93 分,Y 老师在同一学期获得的评教分数均值是91 分,以“分高者优”的标准判断,应是Z 老师的教学更受学生认可。但要得出这个结论有一个隐含的前提是每个班对教师打出的每一分的“含金量”是相等的,问题是如果两位老师授课的对象并不是同一个班级——假设Z 老师的授课班级为A 班,且A 班同一学期内的授课老师共有5 位,除Z 老师外其余几位老师获得的评教分数分别是98、97、95、85,Y 老师的授课班级为B 班,B 班的授课老师也有5位,除Y 老师外其余几位老师获得的评教分数分别是90、89、86、83,在这样的情况下,刚才的结论还能成立吗?首先,可以得到两个关键信息:一是A 班授课教师获得的评教分数普遍比B 班授课教师所获分数要高;二是Y 老师在B 班各位老师所获分数中排名高居第一,而原始平均分高其两分的Z 老师在A 班各位授课老师中所获分数中排名仅为第四。对于第一条信息,我们是不是能简单地解释为A 班授课老师的教学水平普遍更受学生认可?显然不能。因为我们无法说明“更受学生认可”的学生是哪些,是A 班的?还是B 班的?似乎都不妥。不妥的本质是将不处于同一参照系下的分数强行放在一起比较,便好似硬要将驴唇对上马嘴。所以我们不能用A 班学生对本班授课教师打出来的分数,与B 班学生对B 班的授课教师打出来的分数直接比较。在此基础上,第二条信息蕴藏的内涵就很直白了,即不同的班级在整体上的评分尺度可能有较大差异,而不同评分尺度下原始分数的差异并不一定代表教师受学生认可程度的高低,就像持不同评分尺度的教师对同一份作业或同一张试卷打出的分数也可能有所不同一样(因为不同的评价尺度下每一分的“含金量”是不一样的)。上述的例子恰是一个“分高者优”的反例。在一个有十几二十个甚至数十个班级的二级学院的内部比较中,这样的反例非但是不可避免,很可能是并不鲜见。在范围更大的全校性比较中,如上文提到的优秀课堂教学奖的评选,学生评教的原始分数可以说是几乎完全失去了作为评选依据的价值。
其二,课程类别的影响。课程类别可以从多个层面理解,(1)指课程的学科领域和专业来源,如数学范畴下的线性代数、概率论、解析几何等,美术范畴下的素描、水彩、国画、油画等; (2)指课程在专业培养方案中的定位和要求,如通识类课程、专业必/选修课、公共必/选修课等;(3)指课程主要的授课形式与学习要求,如理论课、技能课、实践课等。一个大学生在整个大学学习中必定需要学习各个类别的课程,而不同类别的课程对不同的学生可能有着不一样的吸引力。所以无论在哪个层面考虑,不同的课程类别都有可能成为与教师教学质量相对独立的一个因素,影响着学生对教师教学质量的客观评价。
其三,来自学生和教师个体的影响。如课程难度,不同的学生对同一门课程会有不同的难度感受,当学生个体认为一门课程过难或过易时,也可能会导致其失去学习该门课程的信心或兴趣,继而影响到对授课教师的客观评价。同理,不同的学生对同教师的授课风格会有不同的接受程度,这也可能影响到对该教师教学质量的客观评价。
总之,即便是对同一班级授课的几位老师之间的比较,也存在课程类别、课程难度、教师授课风格等影响因素,使得“学生评教”分数并不是仅仅反应了教师教学质量这个我们最想了解的变量的水平,而成为了多种因素混合的反映。简言之,就是评教分数被“污染”了。
二、改进的建议
从对该校“学生评教”结果统计分析与应用现状的讨论中,我们可以知道,要使学生评教的结果得到更有效的运用,就必须在对评教分数的统计手段上做出改进。对于改进的方法,我们首先想到的是:
(一)引入标准分数
对于直接使用原始评教分数的弊端我们已了然于胸,那么标准分数有何特点可以弥补这些不足?我们先看其定义——标准分数,又称基分数或Z 分数,是以标准差为单位表示一个原始分数在团体中所处位置的相对位置量数。离平均数有多远,即表示原始分数在平均数以上或以下几个标准差的位置,从而明确该分数在团体中的相对地位的量数。计算公式为:
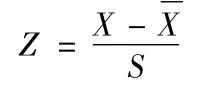
式中:X 代表原始数据(在这里代表某班各参评学生对某位教师评价分数的平均数);X 代表一组数据的平均数(在这里代表某班对为自己班级授课的各位老师评价分数平均数的平均数,即班级范围内的X 的平均数);s 为标准差(即班级范围内的X 的标准差)。其优点是[1]:
1、可比性。标准分数以团体平均分(X)作为比较的基准,以标准差为单位。因此不同性质的成绩,一经转换为标准分数(均值为零,标准差为1),相当于处在不同背景下的分数放在同一背景下去考虑,具有可比性。
2、可加性。标准分数是一个不受原始分数单位(这里的单位可以理解为不同评分尺度下原始分数的“含金量”)影响的抽象化数值,能使不同性质的原始分数具有相同的参照点,因而可以相加。
3、明确性。知道了某一被试(这里指受评教师)的标准分数,利用标准正态分布函数值表,可以知道该分数在全体分数中的位置,即百分等级,也就知道了该被试分数在全体被试分数中的地位。所以,标准分数较原始分数意义更明确。
4、稳定性。原始分数转换成标准分数后,规定标准差为1,保证了不同性质的分数在总分数中的权重一样,避免了在多个分数汇总时因标准差不一造成的权重不一致的情况,使汇总的分数能更稳定、更真实地反应被试的水平。这在学科测验和人事选拔中尤为重要,有利于录取的公平性,在学生评教中也是一样。
现在,我们就以上文提到的例子来说明标准分数在学生评教中应用的步骤:
(1)计算A 班各授课教师评教分数(这里的“评教分数”指某班各参评学生对某位教师评价分数的平均数,即X)的平均数(即XA),和标准差SA:
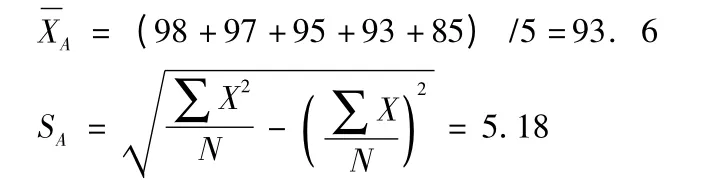
(2)按公式计算A 班5 位授课教师各自的标准分数:
98、97、95、93、85 五个原始分数对应的标准分数依次是:0.85、0. 66、0. 27、-0. 12、-1. 66。可知Z 老师的标准分数为-0. 12,根据标准分数的定义,值为负表示Z 老师受学生认可的程度甚至达不到A 班5 位老师受学生认可的平均水平,与平均水平的差距是0. 12 个标准差(5. 18)。
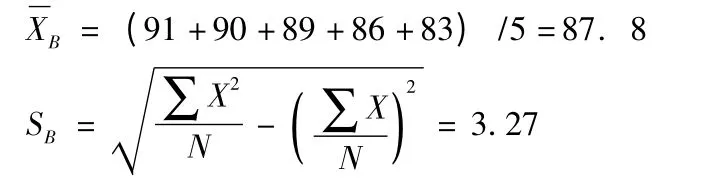
(4)按公式计算B 班5 位授课教师各自的标准分数:
91、90、89、86、83 五个原始分数对应的标准分数依次是0.98、0. 67、0. 37、-0. 55、-1. 46。可知Y 老师的标准分数为0. 98,表示Y 老师受学生认可的程度在B 班高居第一,高出平均水平近1 个标准差(3. 27)。
(5)根据标准分数的可比性进行比较,Y 老师受评成绩的标准分明显比Z 老师的标准分要高,可得结论,Y 老师的教学受其授课班级学生认可的程度,比Z 老师的教学受其授课班级学生认可的程度要高。
(二)线性转换
由上文可知,标准分数可用于比较几个分属性质不同的观测值在各自数据分布中相对位置的高低,因此标准分数的引入很好地解决了不同班级学生对本班授课教师打出来的评教分数相互比较的问题。但从结果来看,我们也会发现计算出来的标准分数普遍存在小数、负数的情况,内涵不直观,不便于理解。对此,我们可以通过线性转换的方式来解决这一问题。
转换公式为:Z' = aZ + b (a、b 为常数)
标准分数经线性转换后,使得原标准分数变成了正数,方便比较,同时仍保持原始分数的分布形态,并具有原来标准分数的一切优点。如:
A 班5 位教师原标准分数在取a =10,b =100 时,经转换后分别为:108. 5、106. 6、102. 7、98. 8、83. 4,B 班的5 位教师也可作同样的转换,得:109. 8、106. 7、103. 7、94. 5、85. 4。Y老师的Z’分数为108. 5,同样比Z 老师的Z’分数98. 8 要高,不改变原比较结果。
(三)“多对多”的处理
之前的例子是在一个特定的条件下来讨论的,即比较是在两位分别只对一个班级授课的教师间进行的。实际中当然会有这样的情况,但更多时候,情况要比这复杂一些。因为大多数老师在同一学期会对不只一个班进行教学。前面我们提过一位教师某门课程的评教要由上这门课的多位学生参与完成,那么当这位教师上的不只有一门课或一个班时,就形成了“多对多”的情境。如下例:
假设P 老师在某学期一共上了4 个班的课,Q 老师在同一学期上了共5 个班的课,怎么比较他们的教学在该学期受学生认可的程度?
假设两位老师从各班获得的原始评教分数以及各班为本班各位授课教师评分后计算得到的平均数和标准差分别为:
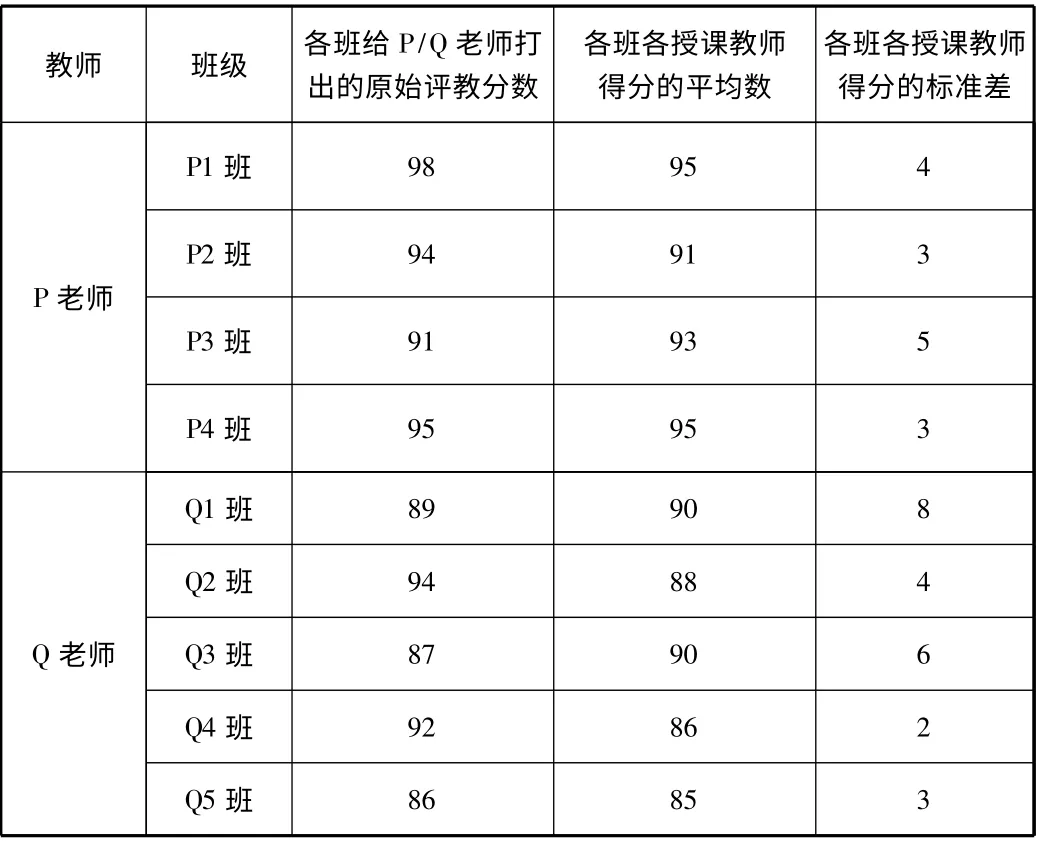
表2 P/Q 两位老师从各教学班获得的原始评教分数及各班评教分数的平均数和标准差
如果不采用标准分数,可分别计算各人的平均分,可知P 老师得分为94. 5,Q 老师得分为89. 6,似乎显示P 老师更受认可。
但如果我们可按前面提到的方法分别计算P、Q 两位老师各教学班评教分数的标准分数,并进一步计算各人的标准分总和及标准分平均数,可得:
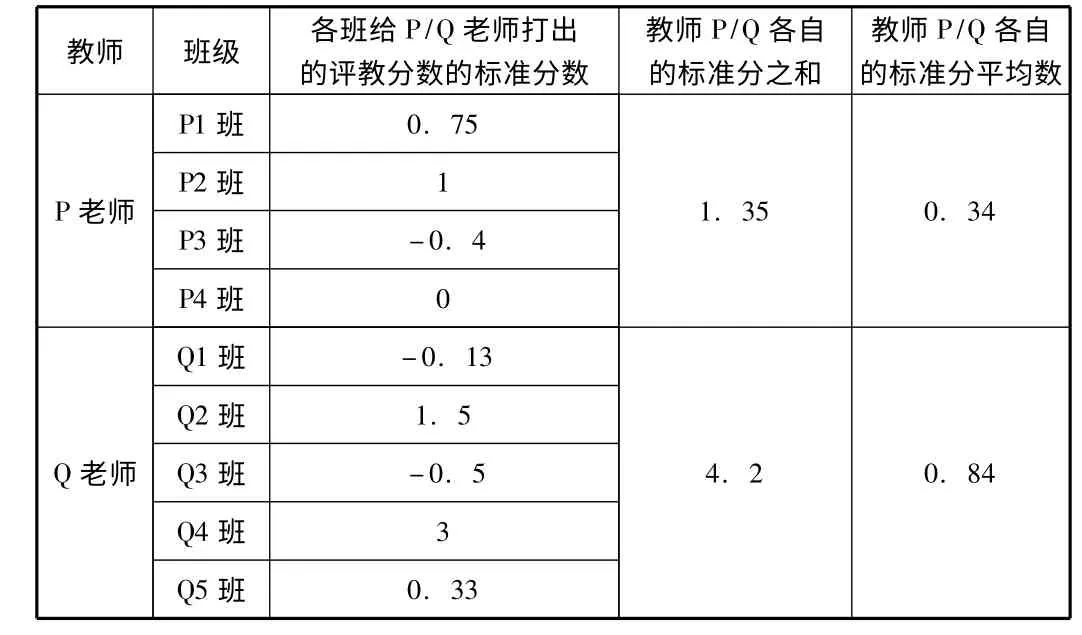
表3 P/Q 两位老师从各教学班获得的评教标准分数及各自的标准分之和及平均数
显然,同样的数据按给定的均值和标准差转换后,得到的标准分平均数是Q 老师更高,结果再一次出现了反转。这里我们应用的实际是上文提到的标准分数的可加性和稳定性,保证教师间比较的公平性和科学性。当然,如有需要,仍然可以对标准分平均数进行线性转换。
(四)对干扰因素的应对
对于前面提到的来源于师生自身或课程类别等方面的干扰因素,我们有一个统一的应对建议——增大样本量(参评学生的人数)。此类干扰因素的影响程度和方向因人而异,在实际中难以精确控制,可视为随机误差。而根据经典测量理论,测量误差服从平均数为零的正态分布,误差分数的期望值为0[2]。也就是说,当参评学生的人数足够多,随机误差的正负值就会相互抵消,其平均数就会为0。在访谈中我们了解到个别院系安排学生填评教表时每位教师的评价学生人数只有15 人或甚至5 人。样本量太小,个体间的随机误差难以相互抵消,形成的抽样误差就可能较大,就是说这5或15 人打出的分数可能有失偏颇,很难真正反映全班学生对受评教师的评价。所以建议每次评教还是尽可能增加参评学生人数,理论上来说最理想的情况是每个任课教师的所有教学班,每个教学班的所有学生都能参评。
(五)小结
引入标准分数及相关的后续处理后,教师无论在特定学期是上一门或多门课,上一个或多个班,都可实现相互之间在学生评教成绩这一指标上科学、公正、无障碍地比较。这使得各教学院系及学校有关部门在评估教师教学质量、与教学相关的评优评奖等工作中有了更加可靠的参考指标。
三、后续研究展望
(一)组织成本。上文提到为求客观准确,最好尽可能增加参评学生人数,但从另一角度来说,参评的学生越多,前期组织投入的人力物力、后期统计分析的工作量等组织成本也必将随之上升,如何解决这一矛盾需要再作研究。
(二)学生评教的组织方式。在访谈中了解到各院系在安排学生填写评教表时的方式不一。有的在学生上课时教务员将评教表送到班上现场测评,有的是安排各班班委自行组织本班同学填评教表,有的是由任课老师在自己的教学班组织学生对自己填写评教表,还有的是收教务员将各班参评学生统一召集之后进行评教。那么不同的组织方式会不会成为影响学生打分的一个额外变量,如由任课老师在自己教学班组织学生进行评教时,学生会不会碍于“面子”或有所顾虑而没有给出真实的分数?这需要研究证实。
另外,该校的学生评教工作目前还是通过纸表完成的,这也涉及到组织成本的问题,如果能实现网络媒体的评教,必然能降低成本,提高效率。其实学院教务处已作了有关的尝试,但也发现如一个班的评教由少数几个学生代全班完成的问题,如何解决此类问题可使得网络评教得以全面推广?
(三)评教指标体系。这是整个评教工作的关键,现有的指标体系是否有可改进之处,值得认真研究。
[1]张厚粲 徐建平. 现代心理与教育统计学(M). 北京:北京师范大学出版社,2009:97.
[2]顾海根. 应用心理测量学(M). 北京:北京大学出版社,2010:199.
猜你喜欢
中学生数理化·七年级数学人教版(2023年6期)2023-09-06 20:12:00
科教导刊(2023年2期)2023-02-23 14:30:12
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:07:06
考试周刊(2016年69期)2016-09-21 21:32:31
中学生数理化·八年级数学人教版(2016年5期)2016-08-23 10:08:32
中学生数理化·八年级数学人教版(2016年5期)2016-08-23 10:08:32
中学生数理化·八年级数学人教版(2016年5期)2016-08-23 10:08:32
大学教育(2016年7期)2016-07-27 00:08:48
科教导刊·电子版(2016年8期)2016-06-27 17:26:21
大学教育(2016年3期)2016-04-08 23:46:02
