
基于人脸角度估计的多观察视频合并*
2015-01-12 09:04武晓康罗武胜
传感器与微系统 2015年9期
鲁 琴, 武晓康, 罗武胜
(1.国防科学技术大学 机电工程与自动化学院,湖南 长沙 410073;2.海军工程大学 电力电子技术研究所,湖北 武汉 430033)
基于人脸角度估计的多观察视频合并*
鲁 琴1, 武晓康2, 罗武胜1
(1.国防科学技术大学 机电工程与自动化学院,湖南 长沙 410073;2.海军工程大学 电力电子技术研究所,湖北 武汉 430033)
对特定人物进行观察记录时,由于被观察对象处于运动状态,需要通过布置多个观察源来充分采集其行为信息,这导致大量冗余信息的存储,同时不利于后续对视频的检索和对被测对象行为的分析。为此,提出了一种基于人脸角度估计的多观察视频合并方法,通过对多个观察视频的拆分、人脸检测、人脸角度估计和重组,获得单一的包含被观察对象正面行为的观察视频,然后进行存储。通过实验验证了算法的可行性,同时讨论了多观察源采集视频不同步带来的影响。
视频观察; 人脸角度估计; 视频合并
0 引 言
观察是人们认识世界、获取知识的一个重要途径。与传统基于观察者人眼的方式相比,视频观察能够让被观察对象的行为模式和顺序“冻结”,这样能够反复观看而不会丢失任何原始数据[1],但同时视频观察带来一个新的严峻问题,即视频观察获得的是包含大量冗余的数据,如果不对其进行有效分析处理,仅仅是“囫囵吞枣”式的存储,不仅难以从中得到观察结果,也使后来的信息查阅者无从下手。为此,视频分析处理技术是实现视频观察记录的关键环节[2]。
由于被观察对象处于运动状态,布置多个观察源能始终保持该人物的正面表情和行为处于一个观察源监控之下。为了便于后续对视频的检索和对被测对象行为的分析,本文提出一种基于人脸角度估计的多观察视频合并方法,即通过对多个观察视频的拆分、人脸检测、人脸角度估计和重组,获得单一的包含被观察对象正面行为的观察视频,然后进行存储。本文主要研究多个观察源下的人物观察记录应用。
1 人脸角度检测与估计
美国加利福尼亚计算机科学学院的研究人员采用真实世界中杂乱图片来进行人脸检测、姿态估计,建立了基于带有部分共享池的混合树结构的模型[3]。基于混合结构树的人脸角度估计算法的输出结果有六个标识,包括眼睛中心、鼻尖、两个嘴角、嘴的中心、偏航方向的离散角度(-90°~90°,以15°为间隔)[4]。该模型虽然只用了几百张脸进行训练,但是取得了很好的效果[5]。为了检测算法在观察记录中的可行性,对视频观察数据中一幅帧图像进行人脸检测和角度估计的处理,如图1所示。图片尺寸大小为360 p×640 p。角度估计结果为偏转60°,处理时间为9.3 s。

图1 人脸角度估计实现
为了检验算法的通用性,本文对100张具有不同场景的图片进行了处理。表1中给出了对不同尺寸图片的处理效果,该算法检测正确率达到90 %以上,且平均处理时间尚可接受。通过对表1中的处理结果分析可知,在图片尺寸缩小后,图片的处理时间也相应倍数地减少,但单位区域的处理时间相差不大,这是因为算法是采用全局匹配的方式估计姿态;在原始图像对应须采样的2s.jpg,3s.jpg,5s.jpg,6s.jpg中人脸姿态估计的正确率明显下降,说明在进行人脸姿态估计时,对图像尺寸缩减来减少处理时间的方式要合理使用。
表1 人脸角度估计算法测试结果
Tab 1 Test results of face angle estimation algorithm

图片名称图片尺寸(p)人脸数目估计到人脸角度的数目检测耗时(s)单位耗时(s)1.jpg640×4262231.21.141s.jpg214×142224.91.612.jpg1024×6773377.91.122s.jpg342×2263110.51.363.jpg1600×120066214.71.123s.jpg534×4006323.21.094.jpg1034×6466667.31.014s.jpg620×9916677.11.255.jpg1205×90244133.11.235s.jpg402×3014319.41.606.jpg1711×76555158.01.216s.jpg856×3835341.91.28
2 基于人脸角度估计的多观察视频合并算法设计
当得到多方视频观察数据后,希望对多方数据融合使用,但又不希望对每一个观察源的数据都做处理,事实上也没有必要对每一个视频源数据进行处理。为此,设计了基于人脸角度估计的多方视频重组记录算法。算法的具体流程如下:
假设观察记录拥有m为观察源数目、n个被观察对象。使用n型人脸库,建立n+1个分类集合即n个被观察对象检测结果{R1,R2,…,Rn}和一个未识别人员(unknow)集合Tn+1。
1)首先把m个视频段{V1,V2,…,Vm} 分解为帧图片到对应的集合{A1,A2,…,Am}中。
2)在保证视频同时性的情况下,从{V1,V2,…,Vm}主选一段视频Vmain作为关键观察数据。在一般情况下,不同观察源得到的观察记录数据不是均匀分布的。显然,正对观察对象的摄像机会记录更多的信息。将其作为主要的分析视频,可以减少角度检测的次数,从而可以减少数据处理时间。
3)对帧图像集合{A1,A2,…,Am}分别对集合Ai中帧图做背景减除和帧差除去冗余信息得到关键帧集合M={M1,M2,…,Mn}。
其中,Mi=Fx(Ai)={fkey1,fkey2,…}⊆Ai,选取其中一个集合为Mmain。
4)对Mmain中的帧图fi按顺序进行人脸检测[6]和角度估计。
5)根据角度估计的结果和摄像机布置的拓扑结构,切换到对应的帧图集合Mi。
6)对Mi和Mmain中相同序号的帧图再做检测,得到正面的人脸框图。
7)对人脸框图归一化处理,提取人脸特征ν。
8)和观察对象人脸库进行人脸特征U={u1,u2,…,un}匹配,把该帧分到对应的结果集合Ri中。
9)循环上述步骤,直到帧图片处理结束。
根据上节实验中得到的人脸角度估计的时间,如果对视频每帧都进行处理,会占用大量时间,为了提高实验效率,检验算法可靠性,做了一定的精简,每秒钟先只选取一张关键帧。具体的算法流程如图2所示。
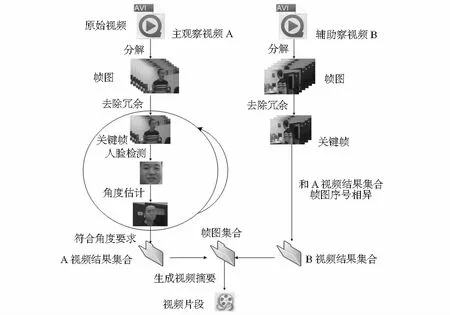
图2 多观察视频重组记录算法流程
3 测试与实验结果
实验中,使用了两个观察源为1 080 p的200万像素摄像头A,B。观察源采用矩形布置的方式,两者的视场相互垂直。场景中只有一个观察对象。图3和图4展示两个观察源下同时刻的画面。算法实现基于32位的Matlab 2010b平台。由于Matlab的程序为解释执行,在处理速度方面和其他高级程序有一定差距。为此,在某些计算环节使用了C++作为混合编程[7]。
实验模拟了对人室内活动进行观察记录的情景,共进行了3次视频观察,观察对象分别为Suliang,Sunbei,Tangshu。因为有2个观察源,所以共有6段视频。视频尺寸均为1 080 p×1 920 p。表2中展示了3组实验6段视频的基本信息,包括每1段视频的时长、帧图像数目、关键帧数目、关键帧中估计到人脸的帧图像数目、处理时间。从表2中看出同一实验下的2段视频的延时在2~3s,这表明两个观察源得到的视频并没有达到完全同步,这在物体移动速度较慢时候影响不大,但在速度移动较快时会造成一定影响。为了弥补视频数据不同步带来的误差,只能对每个观察源下的视频数据进行人脸角度估计,表3给出了实验中多观察源均做处理的结果。表3中人脸角度数据的单位为(°),人脸角度数据中void表示没有检测到人脸。没有检测到人脸的原因可能是图片中没有人物出现,也可能是人脸完全背对镜头。从检测到人脸角度的数据上看,角度变化具有一定的连贯性,说明提取的关键帧能够代表视频整体信息,可以很好地表达人在时间轴上的行为变化。
表2 实验视频信息
Tab 2 Information of experimental videos

实验名称视频名称时长(s)总帧数关键帧数目检测到人脸角度数目处理时间(s)实验一Suliang1Suliang220.2419.04506476201820151612.51455.9实验二Sunbei1Sunbei244.2041.2011051030444026373556.23239.3实验三Tangshu1Tangshu230.3027.40758684302624242431.42876.0
表3 实验结果
Tab 3 Experimental results

视频名称检测到的人脸角度(°)Suliang1[-90,-60,-30,-30,0,45,75,90,90,75,15,-30,-30,-45,-60,-30,0,0,60,45]Suliang2[void,-90,-75,-45,-30,0,0,15,-30,-60,-90,-90,void,void,-60,-45,-30,0]Sunbei1[-30,-30,-15,-15,0,0,0,0,0,30,30,45,60,90,90,90,90,void,void,void,void,void,void,void,void,void,void,void,void,void,void,void,void,90,90,90,45,0,0,-30,0,90,void,void]Sunbei2[void,-90,-90,-90,-90,-60,-60,-60,-45,-45,-30,0,0,0,0,0,30,30,30,60,60,90,90,90,60,30,30,30,0,0,0,0,-30,-60,-75,void,void,-90,-30,90]Tangshu1[-30,0,0,-15,0,30,45,45,60,75,void,void,void,void,void,void,-30,90,30,30,30,0,0,0,0,15,60,60,90,90]Tangshu2[void,void,-90,-90,-90,-60,-30,0,0,0,0,30,30,-15,-45,-45,-45,-45,-60,-60,-60,-60,-45,-15,0,0]
图3(a)检测人脸为90°,图3(b)是没有检测到人脸为void情况。图4是对Sunbei1,Sunbei2两个视频处理后融合的效果。从处理结果看,图4前11张小图是在摄像机A下得到的正面信息,在图4第12张小图时,因观察对象人脸角度偏转超过一定区域范围,被切换到另一个摄像机上。基于角度估计的视频重组记录算法能够检测出帧图像中存在角度偏转的人脸,通过分析观察源之间的空间几何关系,能够使两个观察源下的视频达到很好的融合效果。图4中小图的序号为001,026,051,076,101,126,151,176,201,226,251,251(2),276,301,326,351,376,401,426,451。重组记录算法对数据处理的采样间隔是25帧,图4中的图像序号表明算法对两个观察源的数据没有漏检。

图3 人脸角度估计处理结果
4 结 论
本文描述了为了观察记录的全面性而存在的多源视频数据处理的现实问题,分析了用户对视频重组记录的需求,介绍了加利福尼亚大学研究人员的人脸角度估计算法,采用该成果,设计并完成了基于人脸角度估计的多视频重组记录算法,在实验室现有的硬件条件下设计了实验过程,展示并分析了算法的测试结果。
[1] 雷玉堂.安防&智能化—视频监控系统智能化实现方案[M].北京:电子工业出版社,2013.
[2] 谢剑斌,陈章永,刘 通,等.视觉感知与智能视频监控[M].长沙:国防科学技术大学出版社,2012.
[3] Zhu Xiangxin,Ramanan D.Face detection,pose estimation, and Landmark localization in the wild[C]∥2012 IEEE Conference on Computer Vision and Pattern Recognition,RI,USA,2012:2879-2886.

图4 视频合并处理结果
[4] Herbst E,Ren X,Fox D.Object discovery via multi-scene analy-sis[C]∥2011 IEEE International Conference on Intelligent Robots and Systems,2011:4850-4856.
[5] Yang Y,Ramanan D.Articulated pose estimation using flexible mixtures of parts[C]∥CVPR 2011,2011:1385-1392.
[6] Wu Xiaokang,Xie Chenggang,Lu Qin.Algorithm of video decomposition and video abstraction generation based on face detection and recognition[C]∥2014 International Conference on Machine Tool Technology and Mechatronics Engineering,2014:4620-4623.
[7] 赵小川.Matlab图像处理:程序实现与模块化仿真[M].北京:北京航空航天大学出版社,2014.
Combination of multiple observation videos based on face angle estimation*
LU Qin1, WU Xiao-kang2, LUO Wu-sheng1
(1.College of Mechatronics Engineering and Automation,National University of Defense Technology,Changsha 410073,China; 2.Research Institute of Power Electronics Technology,Naval University of Engineering,Wuhan 430033,China)
While observing and recording specific people,multiple videos are needed for sufficient information gathering,which leads to storage of abundant useless data and results in difficulty for searching and analyzing of observation videos.A combination method of multiple observation videos based on face angle estimation is proposed to solve this problem.A single video which only contains facing scenes of moving people is obtained and stored by splitting multiple observation videos,detecting face and recombining based on the face angle estimation.Experiments verify the feasibility of this method and the influence of asynchronous videos is discussed.
video observation; face angle estimation; video combination
2015—06—13
国家自然科学基金资助项目(61171136)
10.13873/J.1000—9787(2015)09—0017—03
TP 391
A
1000—9787(2015)09—0017—03
鲁 琴(1980-),女,湖北武汉人,博士,讲师,主要研究方向为无线多媒体传感器网络、视频感知与智能处理。
猜你喜欢
作文小学高年级(2022年3期)2022-04-20
重庆科技学院学报(自然科学版)(2022年6期)2022-02-04
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
微型电脑应用(2020年12期)2020-12-25
福建中学数学(2018年1期)2018-11-29
动漫星空(2018年9期)2018-10-26
37°女人(2017年8期)2017-08-12
大连理工大学学报(2017年4期)2017-08-07
滇池(2017年7期)2017-07-18
