
稳健性因子分析在股票评价中的应用
2015-01-03 07:31张应应
统计与决策 2015年16期
张应应
(重庆大学 数学与统计学院,重庆 401331)
0 引言
异常值实质上存在于任何应用领域的任一数据集。为了避免异常值的影响,需要使用稳健性估计量。多元均值和协方差阵的经典估计量是样本均值和样本协方差阵。如果数据来自正态总体的话,它们是最优的估计量,但是它们对异常值非常敏感。如果数据中有异常值,异常值会影响样本均值和样本协方差阵,从而会影响依赖于它们的经典因子分析[1]。因此有必要考虑使用样本均值和样本协方差阵的稳健性估计量。
本文所采用的数据是上证A股2013-09-30三季度财务数据,共有957只股票(样本),10个财务指标(变量),数据下载自免费的大智慧软件。为了更加客观地对待每一个样本点,本文采用稳健性因子分析。使用的上市公司财务量化指标包括:主营业务收入(x1,元)、主营业务利润(x2,元)、利润总额(x3,元)、净利润(x4,元)、每股收益(x5,元)、每股净资产(x6,元)、净资产收益率(x7,%)、总资产收益率(x8,%)、资产总计(x9,元)、股本(x10)。需要说明的是,大智慧软件中没有总资产收益率这个指标,但它可以由公式
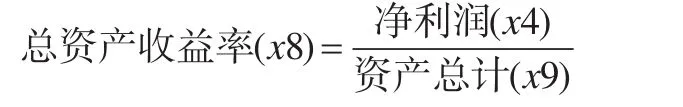
计算得到。本文采用R软件[2]进行计算。
1 实证
从图1可以看出异常点在经典因子分析中的影响。我们所采用的数据是经典的Hawkins,Bradu and Kass(hbk)数据集,它来自软件包robustbase[3],有75个样本,4个变量(一个响应变量,三个解释变量)。前10个样本是坏的杠杆点,11~14样本是好的杠杆点(即:它们的x部分是异常的,但是它们的y部分对模型拟合得很好)。在这里我们只考虑hbk数据集的x部分。左图显示的是经典因子分析前两个因子的散点图,前两个因子解释了总方差的99.4%。异常点(1~14)被有效地区分了出来,但是正常点远离原点(因子得分的样本均值理应在原点,因为因子得分是从样本相关阵出发计算的)。此外,97.5%的置信椭圆没有覆盖正常点,这表明置信椭圆被异常点严重地影响了(注意:经典因子分析的置信椭圆并不一定要比稳健性因子分析的置信椭圆大,置信椭圆的大小由特征值的大小确定)。右图显示的是稳健性因子分析前两个因子的散点图,前两个因子解释了总方差的71.5%。我们发现稳健性因子得分的样本均值没有受到异常点的影响,并且异常点被97.5%的置信椭圆很好地区分开来。进一步计算因子得分的样本均值,我们发现:经典因子分析的因子得分在所有点的样本均值为0(3.700743e-18,4.302114e-18),而在正常点上不为0(4.545664,1.874009);稳健性因子分析的因子得分在所有点的样本均值不为0(-0.3613164,-0.3013054),而 在 正 常 点 上 为 0(1.069557e-16,2.832434e-17)。
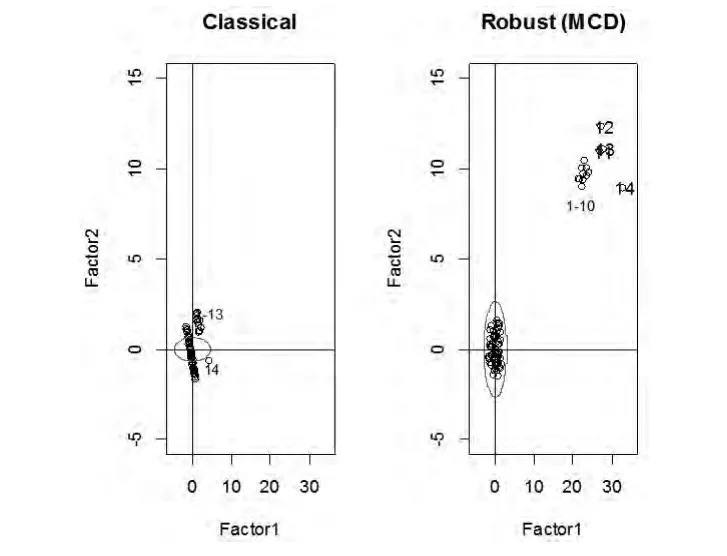
图1 hbk数据集前两个因子的散点图:经典的和稳健性的
下面我们利用FaCov()函数计算稳健性因子分析。它的一般使用格式为:FaCov(x,factors=2,cor=FALSE,cov.control=CovControlMcd(),method=c(“mle”,“pca”,“pfa”),scoresMethod=c(“none”,“regression”,“Bartlett”),...)
其中x是一个数值矩阵或者是一个可以强制为数值矩阵的对象(如数据框)。factors是因子个数,默认值为2。cor是一个逻辑变量,如果cor=TRUE则用相关阵进行计算,如果cor=FALSE(默认值)则用协方差阵进行计算。cov.control用来确定用什么样的稳健性估计量来计算稳健性样本均值和稳健性样本协方差阵,它的取值为类为CovControl的对象,默认值为CovControlMcd(),这时所取的稳健性估计量为MCD。如果cov.control=NULL,则用经典的估计量来计算样本均值和样本协方差阵。method是因子分析所用的方法,它的取值为“mle”(默认值,极大似然法),“pca”(主成分法)和“pfa”(主因子法)。scoresMethod表示计算因子得分的方法,默认值是“none”(即不计算因子得分),“regression”表示用回归法计算Thompson因子得分,“Bartlett”表示用加权最小二乘法计算Bartlett因子得分。
既然计算因子分析的方法有“mle”,“pca”和“pfa”3种,而cov.control的取值有CovControlOgk(),CovControlMcd(),CovControlMest(),CovControlMve(),CovControlSde(),Cov-ControlSest()等6种。那么哪一种配对是最佳的呢?我们采用的准则是选择使残差矩阵E的元素平方和Q(E)最小的方法。见文献[5]。其中

结果见表1。同时我们也计算了3种因子分析方法下经典估计量的Q(E)。在表1中Q(E)最小的组合是(pfa,Classic),但是由经典估计量计算的样本均值和样本协方差阵严重地受到了异常点的影响,所以我们在剩下的稳健性估计量中选择最小的Q(E ),它就是组合(pfa,Sde),此时的Q(E)=0.09865221。注意:表1中的结果是在set.seed(2)下得到的,如果不set.seed,则每次运行的结果会稍有不同,但是对此数据集在绝大多数情况下,组合(pfa,Sde)得到的Q(E)都是最好的。并且对某些set.seed,method=“mle”会报错,比如当set.seed(5)时,method=“mle”且cov-Control=CovControlMve()会报错。

表1 各种因子分析方法和估计量下的Q(E)
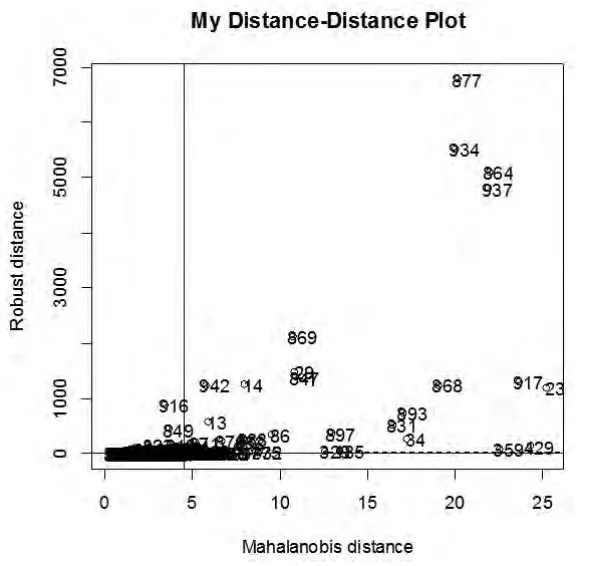
图2 Stock数据的distance-distance图
现在我们利用robustfa[4]软件包中plot-utils.R中的myplotDD()函数来画类为Cov的对象,如图2所示。此处使用的稳健性估计量是Sde估计量,从表1可以看出,组合(pfa,Sde)可以使残差矩阵的元素平方和达到最小。我们发现稳健性马氏距离比经典马氏距离要大得多。异常点的稳健性马氏距离非常大。myplotDD()是rrcov软件包中plot-utils.R中的.myddplot()函数的改进版。在myplotDD()中,id.n和ind显示出来了。其中id.n是异常点数,并且用记号把它们标志出来。默认状态下,id.n是稳健性马氏距离大于cutoff的样本点数,其中默认状态下cutoff=sqrt(qchisq(0.975,p))。ind是稳健性马氏距离大于cutoff的样本点的标号。
从结果可以看出cutoff=4.525834。有id.n=371个样本点的稳健性马氏距离大于cutoff,即有id.n=371个异常点。sort.y是一个列表,它包含了y的升序排列,y就是稳健性马氏距离向量。sort.y$x是y的升序排列,sort.y$ix是sort.y的样本点序号。ind显示的是异常样本点的序号。
可以计算由经典估计量和稳健性Sde估计量计算的样本相关阵。它们的差异非常大,说明异常点严重地影响了经典的样本相关阵。
表2给出由经典估计量和稳健性Sde估计量计算的旋转后的因子载荷矩阵、共性方差、因子F对原始变量的贡献、贡献率和累积贡献率。从表2可以看出对于由经典估计量计算的因子载荷矩阵,因子1解释x2、x3、x4、x9、x10,并且在x1上面有中等偏小的载荷,因此该因子可称为股票的规模因子;因子2解释x5、x6、x7、x8,因此该因子可称为股票的收益率因子;因子3解释x1,并且在x2上面有中等偏小的载荷,因此该因子可称为股票的主营因子。对于由稳健性Sde估计量计算的因子载荷矩阵,因子1解释x3、x4、x5、x7、x8,并且在x2、x6上面有中等偏小的载荷,因此该因子可称为股票的收益率因子;因子2解释x10,并且在x1、x2、x3、x4、x9上面有中等偏小的载荷,因此该因子可称为股票的规模因子;因子3解释x1、x2、x6、x9,并且在x3、x4、x5上面有中等偏小的载荷,因此该因子可称为股票的资产主营因子。因此经典估计量的因子1(因子2)与稳健性Sde估计量的因子2(因子1)相似。在以后的画图和按因子得分的数值大小由高到低排序中有所体现。注意到在表2中,对于共性方差,在由经典估计量计算的因子载荷矩阵中,有3个变量(每股净资产x6、净资产收益率x7、总资产收益率x8)的共性方差小于0.5,而在由稳健性Sde估计量计算的因子载荷矩阵中,只有1个变量(每股净资产x6)的共性方差小于0.5。

表2 经典估计量和稳健性Sde估计量计算的旋转后的因子载荷矩阵等结果
两种估计量相关阵的特征值的碎石图的差别不是特别明显,这里省略。
图3画的是两种估计量前两个因子得分的散点图和97.5%置信椭圆。可以看出经典的置信椭圆包含了异常点,而稳健性Sde估计量的置信椭圆有效地区分了正常点和异常点。

图3 经典估计量(左图)和稳健性Sde估计量(右图)前两个因子得分的散点图和97.5%置信椭圆
下面分别按因子得分的数值大小由高到低排序列于表3、表4和表5,限于篇幅,每张表只列出了排在前两位和后两位的股票。在表3中,各股票的顺序反映了股票的收益率由高到低的排序。同样,表4的股票顺序反映了股票的规模由大到小的排序,表5的股票顺序反映了股票的主营/资产主营由多到少的排序。
2 讨论
经计算,在表3至表5的前10名和最后10名中(共60只股票),经典估计量的所有股票均为异常点,稳健性Sde估计量除了安信信托以外的所有股票也均为异常点。这种现象是正常的,因为因子得分取极大/小值的样本点很可能是异常点。
由于经典估计量的样本均值和样本相关阵极大地受到了异常点的影响,所以由经典估计量计算的因子得分结果不可信赖。以下我们只分析由稳健性Sde估计量计算的因子得分。对于稳健性Sde估计量,由表3、表4和表5可知,三个因子得分的取值范围分别是 -135.824≤Factor1≤31.410,-10.185≤Factor2≤860.061,-8.047≤Factor3≤1624.999,虽然各因子得分的最大值和最小值关于零不对称,甚至很不对称,但因子得分在正常点的平均值都是零。若得分值接近零,则表明该股票在这个因子上的得分接近于平均水平。从表3至表5可见,Factor1值越大,表明该股票的收益率越高;反之,则越低。Factor2值越大,表明该股票的规模越大;反之,则越小。Factor3值越大,表明该股票的资产主营越多;反之,则越少。在表3中,贵州茅台、中国神华、中国石油的Factor1值较大,它们都是非常优秀的上市公司,值得投资者长期持有;最后10只股票的Factor1值为负,表明它们是收益率特别低的股票,都是些严重亏损的上市公司股票,注意国内四大商业银行排名最后,收益率最低,且最后10名中有8家银行。从表4可见,在规模排名最后的那些Factor2值都较为接近,并未出现异常小的值,这是因为按有关规定股票上市的公司都必须具备一定的规模,这样就不会出现规模特别小的上市公司;规模排名前10的股票的Factor2值特别大,表明有规模特别大的上市公司,它们就是国内四大商业银行和中国石油、中国石化、交通银行、中国神华、中信银行、招商银行。在表5中,有取正值且绝对值特别大的Factor3值,但没有取负值且绝对值特别大的Factor3值,表明有资产主营特别多的股票,但没有资产主营特别少的股票。

表3 按第1列(收益率因子)得分的排序

表4 按第2列(规模因子)得分的排序

表5 按第3列(主营因子/资产主营因子)得分的排序
从表3至表5中可以看出,有这样一些财务指标数值特殊的股票:收益率大且规模大(中国神华、中国石油),收益率大且规模小(*ST国药),收益率小且规模大(中国石化、中信银行、交通银行、建设银行、工商银行、中国银行、农业银行),收益率小且规模小(无);收益率大且资产主营大(中国石油),收益率大且资产主营小(*ST国药),收益率小且资产主营大(中国石化、兴业银行、浦发银行、交通银行、建设银行、工商银行、中国银行、农业银行),收益率小且资产主营小(无);规模大且资产主营大(工商银行、建设银行、农业银行、中国银行、中国石油、中国石化、交通银行、招商银行),规模大且资产主营小(无),规模小且资产主营大(无),规模小且资产主营小(*ST国药)。还有一些股票,它们同时出现在三组中:中国石油、*ST国药、中国石化、交通银行、建设银行、工商银行、中国银行、农业银行,具体表现为:收益率大且规模大且资产主营大(中国石油),收益率大且规模小且资产主营小(*ST国药),收益率小且规模大且资产主营大(中国石化、交通银行、建设银行、工商银行、中国银行、农业银行)。
利用稳健性因子分析方法可以对上市公司财务报表中的众多指标进行降维,本文中利用3个因子得分指标来代替原始10个财务指标,而损失的信息却不多。通过对3个因子得分指标的分析,投资者对上市公司的财务状况能够有一个明确、简洁和清晰的认识,有利于他们对股票作出正确的评价。在实际应用中,投资者还可结合财务报表的原始数据作出自己正确和明智的判断。
[1]Pison G,Rousseeuw P J,Filzmoser P,et al.Robust Factor Analysis[J].Journal of Multivariate Analysis,2003,(84).
[2]Rousseeuw P J,Croux C,Todorov V,et al.Robustbase:Basic Robust Statistics.R Package Version,URL http://CRAN.R-Project.org/Package=Robustbase,2013.
[3]Zhang YY.Robustfa:An Object Oriented Solution for Robust Factor Analysis.R Package Version,URL http://CRAN.R-Project.org/Package=Robustfa,2013.
[4]Team R C.R:A Language and Environment for Statistical Computing.R Foundation for Statistical Computing,Vienna,Austria.URL http://www.R-Project.org/.2015.
[5]薛毅,陈立萍.统计建模与R软件[M].北京:清华大学出版社,2007.
猜你喜欢
统计与信息论坛(2022年7期)2022-07-12
哈尔滨商业大学学报(自然科学版)(2021年6期)2021-12-20
温州大学学报(自然科学版)(2021年1期)2021-06-08
计算机应用与软件(2019年2期)2019-04-01
商情(2019年3期)2019-03-29
财讯(2018年22期)2018-05-14
雷达学报(2017年3期)2018-01-19
现代营销·学苑版(2016年12期)2017-01-23
考试周刊(2016年54期)2016-07-18
自动化学报(2016年8期)2016-04-16
