
MapReduce高可用性的研究与优化
2014-12-20 06:53黄伟建周鸣爱
计算机工程与设计 2014年11期
黄伟建,周鸣爱
(河北工程大学 信息与电气工程学院,河北 邯郸056038)
0 引 言
云计算以高度的容错机制、高可靠性[1]及较低的成本[2]等优点吸引了许多使用者。由于云计算还不是很完善,因此开源云计算平台Hadoop[3]的核心技术之一MapReduce[4]必然存在许多需要优化之处,其中最重要的就是对MapReduce中单一Jobtracker 节点的优化。虽然单一的Jobtracker在很大程度上简化了逻辑控制流程,但是随着云计算的发展,却带来许多瓶颈问题,影响了MapReduce的可用性及可扩展性。许多学者对调度算法[5]、Map中间输出结果[6]、单一控制节点[7,8]等做了优化,还有的提出了支持MapReduce的管理系统[9,10],但都没有从根本上消除单点性能瓶颈,即没有从根本上提高该模型的可用性。本文尝试使用多个Jobtracker节点代替单一Jobtracker节点的优化方法,以便从根本上解决单一Jobtracker节点失效带来的系统崩溃问题,提高MapReduce的可用性。
1 单一Jobtracker节点失效问题
在MapReduce中,主要有2 种节点来管理作业的执行:一个Jobtracker 节点和多个Tasktracker 节点。Jobtracker通过调度Tasktracker来执行作业,Tasktracker执行任务并通过发送 “心跳”到Jobtracker来报告任务的执行进度,如果执行期间有任务执行失败,Jobtracker就会调用一个新的Tasktracker来执行失败的任务[11]。由作业调度过程[12]可知,Jobtracker节点的工作有很多,而Tasktracker节点只是负责执行任务。单一的Jobtracker虽然在很大程度上简化了逻辑控制流程,但却带来了性能瓶颈:一旦Jobtracker失效,整个集群将会陷入瘫痪状态;整个集群的可扩展性受到Jobtracker处理能力的限制。因此本文要提出一种能从根本上解决单一Jobtracker所带来的性能瓶颈的优化方案。
2 MapReduce的优化
优化方案要继承原模型并行计算、作业自动并行化的功能、高容错和易扩展的特点,解决原系统中单一Jobtracker节点的性能瓶颈、节点间的通信及作业均衡问题。
2.1 优化方案的选取
经研究分析,对单一Jobtracker节点性能瓶颈的优化有2种方案:一种是以多节点结构来替换单节点结构。另一种是将Jobtracker的部分功能下放到Tasktracker。对规模固定的系统2 种方案都可行。但对规模可扩展的系统,第2种方案中单一的Jobtracker仍是个问题。鉴于MapReduce易扩展的特点,本文采取第1种优化方案,设计一个具有分布式Jobtracker节点的MapReduce模型。
2.2 总体设计
分布式Jobtracker节点模型即是整个系统的主控节点,又是一个小型的分布式系统。有负责提供服务的普通节点,又有负责管理Jobtracker集群的特殊节点,并且这2 种节点都有相应的后备节点。从宏观上看,Jobtracker集群中的每个Jobtracker节点都是对等的,对整个文件系统提供一致的服务。然而从微观上看,在Jobtracker集群内部,为确保集群正常运行,必须有一个高性能的Jobtracker节点管理集群内的所有Jobtracker节点并监控它们的运行状态。总体结构如图1所示。

图1 Jobtracker节点集群结构
由图1可知在分布式Jobtracker集群中有3种类型的节点,它们分别承担着不同的任务。
(1)Jobtracker节点
集群中的Jobtracker与原MapReduce中的Jobtracker任务基本相同,但原模型中单一的Jobtracker负责调度全部的Tasktracker,而在分布式Jobtracker节点模型中,对Tasktracker的调度和管理是由集群中所有Jobtracker节点共同承担的。Jobtracker集群中不但包含普通的Jobtracker节点,还包含Leader节点和Second Leader节点,这2个节点除了负责普通Jobtracker节点所负责的工作外,还负责特殊的工作。
(2)Leader节点
Leader在整个Jobtracker集群中是唯一的,是集群中性能最好的节点,是根据选举机制选举出来的。一旦确定了Leader节点,只有在Leader失效的情况下才会更换,否则是不会更换的。Leader是负责管理整个Jobtracker集群的中心节点,但同时也具有普通Jobtracker的功能,主要负责的工作有:监控Jobtracker集群中每一个Jobtracker节点的工作状态;处理集群中失效的Jobtracker节点;转发Tasktracker节点的状态信息等。
(3)Second Leader节点
Second Leader是Leader的备份节点,是在选举Leader的同时被选出来的,性能仅次于Leader。
(4)Second Jobtracker节点
当Jobtracker集群中某个普通Jobtracker节点失效时,Leader会及时的选择一个Second Jobtracker来替换失效的Jobtracker。Second Jobtracker在真正成为Jobtracker之前,需加载失效节点中的信息后才能成为真正的Jobtracker。
2.3 通信方式优化
在原MapReduce中,节点间通信是通过相互发送与接收 “心跳”信息。“心跳”信息主要有两方面的作用:一方面Jobtracker根据 “心跳”信息了解Tasktracker的状态;另一方面Tasktracker的可用资源信息也通过 “心跳信息”传送。由于只有一个Jobtracker,因此Jobtracker与Tasktrackers间是一对多的通信。而在分布式Jobtracker节点模型中心跳信息的作用不变,只是它有多个Jobtracker节点,对于Jobtracker节点与Tasktracker节点间的通信就变成了多对多,因此,要对通信方式优化提高MapReduce 的可用性。
在分布式Jobtracker集群中,将节点状态信息和可用资源信息设计成2种独立的 “心跳”信息。Tasktracker周期性的向Leader发送资源 “心跳”信息,再由Leader将接收到的Tasktracker的资源信息转发给其余的Jobtracker节点。然后Jobtracker 根据资源 “心跳”信息调度相应的Tasktracker。这时,被调度的Tasktracker需向相应的Jobtracker节点发送状态 “心跳”信息。这样优化减轻了Tasktracker向Jobtracker集群广播 “心跳”信息所引起的网络负荷。
2.4 作业均衡优化
在分布式的Jobtracker集群中,当所有客户端将作业都集中提交到一些Jobtracker节点上时,会导致在整个集群中一部分Jobtracker节点 “饱和”甚至 “溢出”,而另一部分Jobtracker节点处于闲置状态,因此需要对作业均衡进行优化。本系统以Jobtracker上作业数量来衡量当前Jobtracker所承载的作业量。
Jobtracker集群实现作业均衡分配的前提是掌握整个Jobtracker集群中各节点所承载的作业量。因此必须先对各节点所承载的作业量信息进行收集。收集机制是每个Jobtracker节点周期性的发送它所承载的作业量到作业量均衡管理节点——Leader。Leader就需要维护一个各Jobtracker节点承载的作业量列表,然后将这个列表发送到每一个Jobtracker节点,再对作业实施均衡分配,使Jobtracker集群中各个Jobtracker所处理的作业量相近。客户端可以随机的向集群中的任何Jobtracker提交作业,这个节点根据作业量列表,将该作业移交到作业量最小的节点。以达到集群中各Jobtracker作业均衡。
由于Jobtracker与Leader的通信并不是实时的,当向某个Jobtracker提交作业时,这个节点可能已经不是作业量最小的节点,但这个消息还没传到每个节点,客户端还将继续向该节点提交作业,这就会导致短时间内作业量的不均衡,为避免这种情况,我们选择以下策略,来优化提交对象的选取。
(1)设置报警参数:当某个节点上的作业量变多时,设定的报警参数就触发该节点向Leader发送心跳,Leader就会将新作业量列表发送给每一个Jobtracker节点,从而对作业提交对象进行调整。
(2)设置保护参数:每个Jobtracker都设置保护参数,当某节点的作业量等于该参数时,将拒绝接收作业,同时查询本节点上的作业量列表,将该作业提交到除自身外作业量最小的Jobtracker。
3 实验及结果分析
本实验需将HDFS与优化的MapReduce组成新系统进行测试,根据文献 [13]将Tasktracker和Datanode运行在同一个节点上,Jobtracker和Namenode运行在同一个节点上,为了测试优化后的MapReduce,采用的元数据算法为散列算法[14]。
3.1 实验环境
本文所采用的实验环境结构如图2所示。
图2中每一个节点都是一台PC,所用软件为Hadoop-0.21.0。各节点的配置为:客户端:CPU Intel2.0GHZ内存1GB;Jobtracker集群:CPU Intel2.4GHZ内存2GB;Tasktracker集群:CPU Intel2.0GHZ 内存512 MB。其中网络硬件均为千兆以太网卡,操作系统均为Linux4。

图2 实验环境结构
3.2 系统测试及结果分析
为了更全面测试优化后的MapReduce,做了3 种不同的实验。为使集群正常工作,首先要完成对各节点的配置,然后可以通过ping命令测试系统是否能正常工作。
(1)系统容错性测试
情况1:重启Leader,模拟Leader失效。
情况2:重启Jobtracker,模拟Jobtracker失效。
两种情况使用的测试用例均为在一组随机生成的数中找出最大值。将数据块的数量设置为一个可变的参数,每个块的大小为64 MB。实验结果如图3所示。
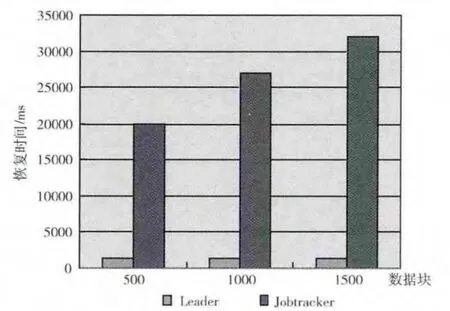
图3 系统容错性测试结果
由测试结果可知,Leader失效后需要的恢复时间很短,这是因为Second Leader周期的向Leader发送 “心跳”,一旦得不到响应,就认为Leader失效,然后迅速接替Leader的工作。同时可以看到Jobtracker失效后需要的恢复时间比Leader多好多,且随着数据块的增加而增加。这是因为Second Jobtracker接替Jobtracker需要加载原Jobtracker的信息且需要通知系统中的其它节点。这个过程需要一定的时间。
(2)系统执行效率测试
情况1:客户端对系统发出写5000、10000、15000 个文件的请求,先在优化后的系统上测试其执行效率,然后再搭建一个原Hadoop架构 (Jobtracker集群中只剩下一个节点,同时去掉Second Jobtracker),重新配置后[15],使用同样的测试用例进行测试,测试结果如图4所示。

图4 一个客户端的测试结果
由测试结果可知,随着文件数的增加2种系统的执行时间都会增加,但优化后的系统在有些情况下比原系统所需要的作业执行时间要长,而有些情况下又和原系统的作业执行时间差不多,这种结果是在预料之中的,因为当客户端向Jobtracker集群提交作业时,对节点的选择是随机的,可能此时选择的节点刚好就是集群中该时刻作业量最小的Jobtracker节点,这样就和原系统的作业执行时间差不多,但可能提交的节点不是集群中该时刻作业量最小的节点,需要对提交对象重新选取,这样就增加了执行时间的开销。
情况2:分别在情况1的两个系统中添加客户端,测试两个客户端同时提交并发写入2500、5000、7500个文件的请求,(采用默认的调度策略FIFO)测试结果如图5所示。
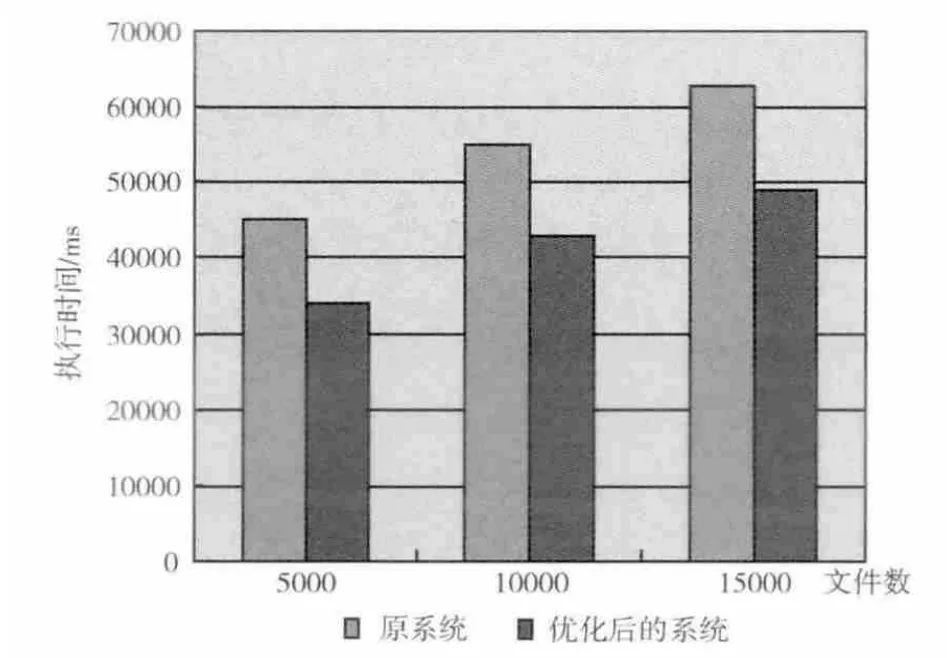
图5 两个客户端的测试结果
将图5与图4的结果对比发现,客户端增多时,两个系统的执行时间都增加了,但是从图5可以看到优化后的系统执行效率要高于原系统,且文件数越多这种优势就越明显。这主要是因为FIFO 的调度策略且优化后的系统有多个Jobtracker,这样多个客户端可以同时向不同的Jobtracker提交作业请求从而提升系统的效率。而原系统只有一个Jobtracker,当有多个客户端提交作业时,只能排队等待,这样就增加了时间开销。
综上所述,从总体性能来看,优化后的系统具有高可用性。
4 结束语
MapReduce作为Hadoop的关键技术之一,存在单一Jobtracker节点瓶颈问题,影响了MapReduce 的可用性,本文提出了分布式Jobtracker节点模型,该模型是对目前MapReduce架构的优化和改进,优化的出发点是扩充Jobtracker节点,以便从根本上消除单点性能瓶颈。
系统容错性测试实验说明在优化后的MapReduce中Jobtracker节点失效是不会影响系统正常运行的。这样从根本上提高了MapReduce的可靠性及可用性。同时系统执行效率测试实验结果表明,当有多个客户端同时提交作业时,优化后的系统执行效率要高于原系统,但当只有一个客户端提交作业时,与原系统相比优化后的系统作业执行效率的高低是不确定的,这是新系统仍需优化的地方。此外还存在2个待优化之处:一是HDFS中元数据的分布算法优化;二是如何缩短Jobtracker节点失效后系统恢复正常的时间。在大规模集群中,通过对这些地方的优化能在一定程度上进一步提升MapReduce的可用性及集群性能。这也本文是今后的研究重点。
[1]CHEN Haibo.The research of cloud computing platform credibility enhancement technique[D].Shanghai:Fudan University,2009:1-150 (in Chinese).[陈海波.云计算平台可信性增强技术的研究 [D].上海:上海复旦大学,2009:1-150.]
[2]LIU Jing.The research of cloud computing platform cost effectiveness[D].Beijing:Beijing University of Posts and Telecommunications,2010:1-73 (in Chinese).[柳敬.云计算平台的成本效用研究 [D].北京:北京邮电大学,2010:1-73.]
[3]Apache.Apache hadoop [EB/OL]. [2013-10-01].http://hadoop.apache.org/core/.
[4]Apache.Hadoop mapreduce[EB/OL].[2011-12-01].http://hadoop.apache.org/mapreduce/.
[5]XUAN Ji.Research and improvement of MapReduce scheduling mechanism on cloud computing [D].Changchun:Jilin University,2013:1-48 (in Chinese). [玄吉.云计算中对于MapReduce调度机制的研究与改进 [D].长春:吉林大学,2013:1-48.]
[6]HE Rongbo.The optimization and performance for the MapReduce performance in Hadoop [D].Beijing:Beijing University of Chemical Technology,2011:1-76 (in Chinese).[何荣波.MapReduee模型在Hadoop中的性能优化及改进 [D].北京:北京化工大学,2011:1-76.]
[7]Murthy AC.The next generation of apache hadoop MapReduce[EB/OL]. [2011-12-01].http://developer.Yahoo.com/blogs/hadoop/posts/2011/02/mapreduce-nextgen/.
[8]Murthy AC.Proposal for redesign/refactoring of the jobtracker and tasktracker [EB/OL]. [2011-12-01].https://issues.apache.org/jira/browse/MAPREDUCE-278.
[9]Apache.Mesos:Dynamic resource sharing for clusters [EB/OL].[2011-12-01].http://www.mesosproject.org/.
[10]Hindman B,Konwinski A,Zaharia M,et al.Mesos:A platform for fine-grained resource sharing in the data cent[C]//Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation.Boston:USENIX Association Berkeley,2011:22-30.
[11]White T.Hadoop-the definitive guide [M].1st ed.America:O’Reilly Media,2009:153-174.
[12]TAO Tao.MapReduce-based resource scheduling model and algorithm research in cloud environment[D].Dalian:Dalian Martime University,2012:17-22 (in Chinese). [陶韬.云计算环境下基于MapReduce 的资源调度模型和算法研究[D].大连:大连海事大学,2012:17-22.]
[13]WANG Peng.The key techonology and application of cloud computing [M]Beijing:The People’s Posts and Telecommunications Press,2010:66-78 (in Chinese).[王鹏.云计算的关键技术与应用实例 [M].北京:人民邮电出版社,2010:66-78.]
[14]WU Wei.The research on metadata management of massive storage system [D].Wuhai:Huazhong University of Science and Technology,2010:1-107 (in Chinese).[吴伟.海量存储系统元数据管理的研究 [D].武汉:华中科技大学,2010:1-107.]
[15]LIU Gang,HOU Bin,ZHAI Zhouwei.Hadoop-the open source platform of cloud computing[M].Beijing:Beijing University of Posts and Telecommunications Press,2011:95-101 (in Chinese). [刘刚,候宾,翟周伟.Hadoop——开源云计算平台[M].北京:北京邮电大学出版社,2011:95-101.]
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11
传媒评论(2019年5期)2019-08-30
电子制作(2018年11期)2018-08-04
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
传媒评论(2018年2期)2018-06-06
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
新课程·上旬(2015年12期)2016-01-27
集装箱化(2014年10期)2014-10-31
