
基于双哈希结构的整词二分词典机制
2014-12-20 06:52张贤坤李亚南
计算机工程与设计 2014年11期
张贤坤,李亚南,田 雪
(天津科技大学 计算机科学与信息工程学院,天津300222)
0 引 言
中文分词技术在信息检索、问答系统、文本挖掘等很多方面都有应用[1],其运行速度直接影响了后续处理的效率。机械分词是一类相对成熟的分词方法,该类方法实现和维护简单,准确率较高,新词识别能力却很低。目前,机械分词已发展成为一类重要的辅助方法,一般与其它方法结合使用[2]。分词词典是机械分词方法的基本构件,其查询速度直接影响着分词算法的性能[3]。传统的分词词典机制有整词二分、TRIE索引树和逐字二分。整词二分机制结构简单,内存使用较少,实施简单;TRIE树机制效率较高,但空间占用大,词典的构造、维护都相对困难;逐字二分机制是前二者的改进版,内存占用较小、查询速度较快,由于受到存储结构的影响,其性能很难再提高[4]。整词二分词典机制拥有简单易行的特点,较其它2种有很大的性能提升空间,本文将对该词典机制进行改进。
逆向最大匹配 (reverse maximum matching,RMM)算法和正向最大匹配 (forward maximum matching,FMM)算法是机械分词方法中2个主要算法。其中,RMM 的分词精度比FMM 高[5],使用时会根据需要选择算法,对2 种算法的研究同等重要。但是,传统的整词二分词典机制以词条首字作为索引项,对逆向扫描的RMM 不适用;该词典机制匹配词串时存在无效匹配次数过多,索引效率很低等问题。针对这些问题,本文提出了双哈希尾字词典结构,能够将RMM 的分词速率提高近一倍。
1 已有的词典机制
分词使用的词典由外部存储器调入内存,包含了大量供匹配的汉语词,词典规模较大,时间和空间的开销都很大。词查询速度、空间利用率和维护这3个要素可以限制词典的性能。丁振国[5]改进了整词二分词典结构,提出了哈希结构的分词词典,该词典中记录了首字下最大词长,同时为每一个长度的词条给出了索引指针,速率相对于原整词二分词典结构有所提高。彭焕峰[6]提出了一种基于全哈希的整词二分词典结构,将词条按字数存储,进行全词哈希,减少了词条匹配的次数,使用该词典进行分词拥有较高的效率。叶继平[7]利用哈希表提出了具有三级索引的新词典结构,并给出了对应的最大正向匹配的改进算法,降低了匹配过程的时间复杂度,提高了分词算法的速率。莫建文[8]构造了双字哈希结构,不但对词条的首字进行哈希查找,对于词语的次字也采用查找哈希,实验表明采用该词典机制的分词速度有一定的提高。
1.1 传统的整词二分词典结构
传统的整词二分词典结构[4]如图1 所示。该词典结构包括词典正文、词索引表和首字哈希表组成。词典正文是存储词条的有序表,词索引表是指向词典正文中每个词条的指针表。通过首字哈希表的哈希定位和词索引表可以轻易确定某个词条在词典正文中的可能位置范围[7]。
该词典结构有以下三点不足:①第一层哈希表保存了所有词条的首字,在分词过程中,以首字表为入口,得到词典正文的索引指针,进而进行词条检索。但是,对于逆向最大匹配算法来说,在对某字符串检索失败时,会将第一个汉字去掉,再对余下的字符串进行检索,这时,就不得不重新检索首字哈希表,若是仍然检索失败会继续删除为首的汉字,检索哈希表,直至分词结束[9]。②在传统的机械分词算法中,匹配字符的最大长度一般设置为词表中词的最大词长。但是,据统计,汉语中词的出现频率较高的主要是二 字词,其次是三字词和四字词,更长的词的出现频率非常低[10],而大多数词表中的最大词长至少为5,因此这种字符串长度的选择的方法增加了算法无效匹配的次数[9]。③词典正文以有序表进行存储,检索速度很慢。
1.2 记录词长的哈希结构尾字词典结构
针对传统的整词二分词典结构在用于逆向最大匹配算法时出现的问题,文献 [9]对上述词典结构做出了改进,提出了记录词长的哈希结构尾字词典,如图2所示。该词典由三部分组成:

图1 整词二分词典结构

图2 记录词长的哈希结构尾字词典结构
(1)记录词长的尾字哈希表
每个词条的尾字哈希表都包含其尾字下的最大词长,和指向以该汉字C为词尾的词条在词汇索引表中的初始位置的指针。
(2)词汇索引表
表中每条记录包含一个指向词典正文中对应词汇首地址的指针,和一个记录词典正文中除去尾字的词条长度。词汇索引项按各词词长进行降序排列。
(3)词典正文
词典正文为以字C 作为词尾的所有词条的有序表,依序存储各词条中不包含尾字C的剩余汉字。
该词典结构的优势:①在哈希表中保存了词条的尾字,以尾字作为检索入口,在逆向匹配算法分词的过程中,只须检索哈希表一次,节省了时间。②为每一个尾字保存了以该字结尾的词条的最大长度,这样,在字符串长度选择时,可以以该值作为基准,减少了无效匹配次数。③在词典正文中,只保存不包含尾字的剩余汉字,节省了空间。④为不同长度的词条分别设立了索引,在一定程度上节省了检索时间。
该结构有两点不足。第一,文献 [9]提出的词典结构,解决了传统的整词二分词典结构在逆向匹配算法中的不适用问题。但是词典正文仍然使用有序表存储,虽然为不同长度的词条分别设立了索引,但是有序表是不适合用于检索数据的,若是相同长度的词条非常多,在检索时非常耗时。在3.1节中,将会对该词典结构和传统的整词二分词典结构的性能进行分析,有分析结果可知,在最坏情况下,2种词典结构匹配同一个汉字串的时间复杂度是同阶的。所以该尾字词典结构对提高分词算法速率的意义并不是很大。第二,该词典的实现比较复杂。
上述尾字词典使用有序表存储词条,影响了词典的性能,本文在该词典结构的基础上,改进了词典正文的存储结构,提出了双哈希结构尾字词典。
2 双哈希结构尾字词典
2.1 词典设计
双哈希结构尾字词典的词典结构如图3所示。词典由2个部分组成:记录词长的尾字哈希表和词典哈希表,哈希函数均由国际区位码得出。
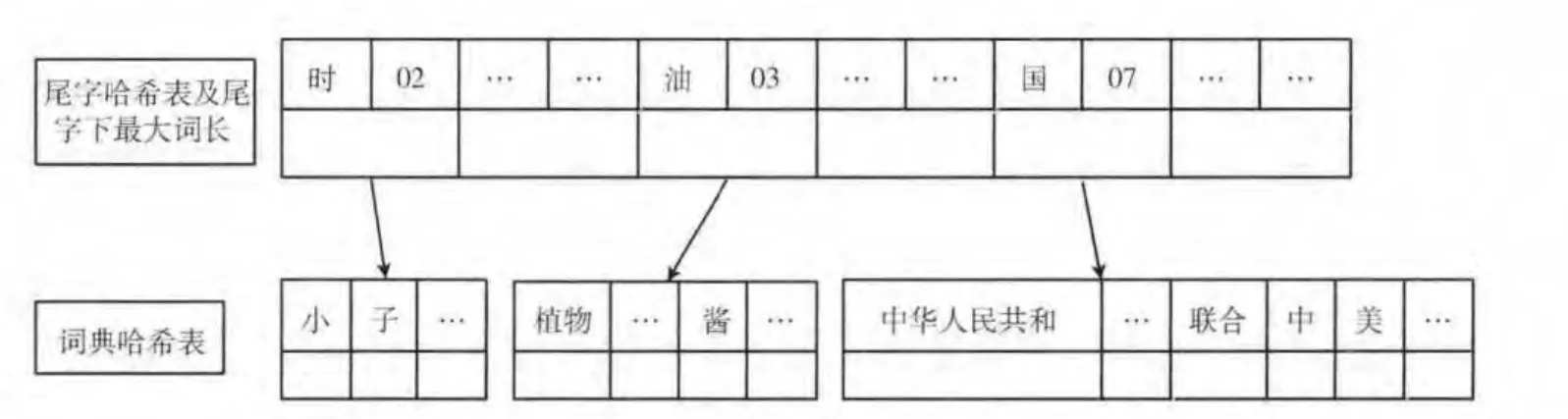
图3 双哈希结构尾字词典
(1)记录词长的尾字哈希表
每个词条的尾字哈希表都包含其尾字下的最大词长,和指向以该汉字C为词尾的所有词条组成的哈希表的指针。
(2)词典哈希表
以哈希表存储数据。以字C 结尾的所有词条都作为哈希表的健存储在哈希表中,对应的值都是一个常数,在算法中不会被使用。
该词典使用了哈希表存储词典正文,而不再使用有序表,避免了有序表不适合检索数据的问题,同时,因为哈希表是通过哈希值直接定位数据的,检索速度非常快。由于只使用两层哈希表存储数据,词典的实施和维护以及添加、删除数据都非常简单方便。
在加载词典时,对于词长为1的词并不加载到词表中,原因是如果一个字并不和其他字组成词,或者没有一个词条以该字作为词尾,那么在分词过程中,如果一个匹配字符串是以该字作为结尾,是无需在词典哈希表中进行检索的。所以,不需要为该字分配尾字哈希表位置。该词典机制提高了空间利用率,避免了无效的存储造成的空间浪费。
2.2 分词算法
在算法调用前,需要对待切分文本进行预处理,包括去除停用词和对数字、字母等的处理。双哈希结构尾字词典对应的逆向最大匹配算法流程图如图4所示,对应算法见算法1。
算法1:
(1)待分词字串S=C1C2…Cn (n∈N),S 长度为Length,若Length=0,算法结束;若Length>1,转向(2);否则将Cn作为单字词,切分出去,算法结束;
(2)判断外层哈希表中是否存在键Cn,若存在,则转向 (4);不存在转向 (3);
(3)将Cn作为单字词,切分出去,若length>0,剩下字串作为新的S字串,转向 (1);否则算法结束;
(4)检索外层哈希表得到以Cn 为键的键值对End-Char,由EndChar得到以Cn 为词尾的最大词长Lm,若Length≥Lm,则令L=Lm;若Length<Lm,则令L=Length;
(5)取S 字串的最末L 个字串得到S (L),以End-Char为入口,查询内层哈希表,判断S (L)是否匹配词典中的词条;若不匹配,转向 (7);若匹配则继续;
(6)将字串S (L)作为一个词切分出去,Length=Length-L;若length>0,剩下字串作为新的S字串,转向 (1);否则算法结束;
(7)L=L-1,若L>1转向(5);若L=1,将Cn作为单字词,切分出去,剩下字串作为新的S字串,转向(1)。

图4 算法流程
3 性能分析与实验
3.1 词典性能分析
假设待匹配字串为S=C1C2…Cn (n∈N),S 长度为n,假设以Cx 为首字的词条数目为mx(x=1,2…,n),令m 等于mx最大值;以Cn为尾字的词条数目为g。则在3种词典数据结构下对该字串进行逆向最大匹配分词,且分出一个词的时间复杂度如下:
(1)传统的整词二分词典结构
访问首字哈希表的时间复杂度为O(1),在词典正文中二分查找该词条的时间复杂度为O(m1)。最坏情况下进行n次查找和匹配,所以分词的时间复杂度为:O(n)+O(nm)≈O(nm)。
(2)记录词长的哈希结构尾字词典
访问尾字哈希表的时间复杂度为O(1),在词汇索引表中查找到词典正文中词长为n 的指针的时间复杂度为O(1),最坏情况下,所有以Cn为尾字的词条具有相同长度,则在词典正文中匹配该字串的时间复杂度为O(g)。在最坏情况下,值访问尾字哈希表一次,要在词典正文中匹配n-1次,分词时间复杂度为:2O(1)+O((n-1)g)≈O(ng)。
(3)双哈希结构尾字词典
访问外层尾字哈希表的时间复杂度为O(1)。由于不包含重复的词条,没有再哈希现象,所以在内层哈希表词典正文中索引字串的时间复杂度为O(1)。在最坏情况下,值访问外层哈希表一次,需要索引内层哈希表n-1次,分词的时间复杂度为O(1)+O(n-1)≈O(n)。
因为O(ng)≈O(nm),所以记录词长的哈希结构尾字词典时间复杂度稍低于传统的整词二分词典结构,二者时间复杂度同阶;又因为g 值远大于n 值,所以O(n)远小于O(ng),所以双哈希结构尾字词典的时间复杂度最低。
通过上述分析可知,前2种词典结构均需对有序表进行顺序匹配,词典中词条数目对匹配的效率影响很大;而本文提出的双哈希结构尾字词典完全利用了哈希表的快速查找优势,降低了查找的时间复杂度。根据分析也可以看出,双哈希结构尾字词典的使用和维护都比其它2 种词典简单。
3.2 实验结果分析
本文实验的语料是1998 年1 月的人民日报分词语料(北大语料),分成四份 (Data1,Data2,Data3,Data4)分别进行分词实验,实验中采用的词典共104951个词条。对每个语料分别使用本文提出的双哈希结构尾字词典、文献[9]提出的记录词长的哈希结构尾字词典和传统的整词二分词典进行逆向最大匹配分词实验,上述3种词典依次命名为dic1、dic2和dic3。对于dic3使用传统的逆向匹配算法;由于dic2 和dic1 均为尾字词典,可用同一种调用策略,为了客观地进行比较,对这2种词典结构都使用上一节提到的算法1进行实验。
每个语料进行10次实验,计算平均时间。实验语料大小见表1,语料大小单位是字节 (b)。分词结果统计如表2所示,时间单位是毫秒 (ms),平均速率单位是字节/毫秒(b/ms)。评估分词结果好坏程度的标准是准确率P 与召回率R 的调和平均值F[11],F=2RP/ (R+P),其中准确率是分词的结果集中正确切分的词数占分词结果总词数的比例,召回率是分词结果中正确切分的词数占标准答案中总词数的比例。根据表1和表2得到3种词典的分词速率如图5所示。
由图5可以看出,在不降低分词结果F值的条件下,2种使用尾字词典 (dic1 和dic2)的逆向最大匹配分词算法明显比使用传统的整词二分词典的逆向匹配算法分词效率高,分词速率比较稳定。使用本文提出的双哈希结构词典的分词速率较使用文献 [9]提出的尾字词典结构有很大的提高,并且相对于使用传统的整词二分词典结构的算法速率提高了将近一倍。

表1 实验语料

表2 分词结果统计

图5 分词速率比较
4 结束语
本文介绍了传统的整词二分词典结构和文献 [9]提出的记录词长的尾字词典,对这2种词典结构做出了全面的分析,指出了二者的不足,并提出了双哈希结构词典和其对应的逆向最大匹配分词算法。实验证明,本文提出的算法在不降低分词结果F 值的条件,很大程度上提高了分词算法的性能。
本文只对词典机制做了改进,对于逆向最大匹配算法的分词歧义问题并没有给出解决办法,下一步的工作是提出一种有效解决分词歧义的算法,结合本文提出的词典机制,进一步提高分词算法的分析效率。
[1]Fu Guohong,Chunyu Kit,Jonathan J Webster.Chinese word segmentation as morpheme-based lexical chunking [J].Information Sciences,2008,178 (9):2282-2296.
[2]FENG Guohe,ZHENG Wei.Review of Chinese automatic word segmentation [J].Library and Information Service,2011,55(2):41-45(in Chinese).[奉国和,郑伟.国内中文自动分词技术研究综述[J].图书情报工作,2011,55 (2):41-45.]
[3]CHEN Ping,LIU Xiaoxia,LI Yajun.Chinese word segmentation based on dictionary and statistic [J].Computer Engineering and Applications,2008,44 (10):144-146 (in Chinese).[陈平,刘晓霞,李亚军.基于字典和统计的分词方法 [J].计算机工程与应用,2008,44 (10):144-146.]
[4]ZHOU Chengyuan,ZHU Min,YANG Yun.Research on Chinese word segmentation algorithm based on the dictionary [J].Computer & Digital Engineering,2009,37 (3):68-71 (in Chinese).[周程远,朱敏,杨云.基于词典的中文分词算法研究 [J].计算机与数字工程,2009,37 (3):68-71.]
[5]DING Zhenguo,ZHANG Zhuo,LI Jing.Improvement on reverse directional maximum matching method based on hash structure for Chinese word segmentation [J].Computer Engineering and Design,2008,29 (12):3208-3211(in Chinese).[丁振国,张卓,黎靖.基于Hash结构的逆向最大匹配分词算法的改进 [J].计算机工程与设计,2008,29 (12):3208-3211.]
[6]PENG Huanfeng,DING Songtao.Binary-seek-by-word dictionary mechanism based on all-Hash [J].Computer Engineering,2011,37 (21):40-42 (in Chinese). [彭焕峰,丁宋涛.一种基于全Hash的整词二分词典制 [J].计算机工程,2011,37 (21):40-42.]
[7]YE Jiping,ZHANG Guizhu.Research and improvement of Chinese word segmentation dictionary [J].Computer Engineering and Applications,2012,48 (23):139-142 (in Chinese). [叶继平,张桂珠.中文分词词典结构的研究与改进[J].计算机工程与应用,2012,48 (23):139-142.]
[8]MO Jianwen,ZHENG Yang,SHOU Zhaoyu,et al.Improved Chinese word segmentation method based on dictionary[J].Computer Engineering and Design,2013,34 (5):1802-1807(in Chinese).[莫建文,郑阳,首照宇,等.改进的基于词典的中文分词方法[J].计算机工程与设计,2013,34 (5):1802-1807.]
[9]LIANG Zhen,LI Yusheng.Reverse backtracking research of Chinese segmentation based on dictionary of Hash structure[J].Computer Engineering and Design,2010,31 (23):5158-5161 (in Chinese).[梁桢,李禹生.基于Hash结构词典的逆向回溯中文分词技术研究 [J].计算机工程与设计,2010,31 (23):5158-5161.]
[10]WANG Ruilei,LUAN Jing,PAN Xiaohua,et al.An improved word maximum matching algorithm for Chinese word segmentation [J].Computer Applications and Soft Ware,2011,28 (3):195-197 (in Chinese). [王瑞雷,栾静,潘晓花,等.一种改进的中文分词正向最大匹配算法 [J].计算机应用与软件,2011,28 (3):195-197.]
[11]HUANG Changning,ZHAO Hai.Chinese word segmentation:A decade review [J].Journal of Chinese Information Processing,2007,21 (3):8-19 (in Chinese).[黄昌宁,赵海.中文分词十年回顾 [J].中文信息学报,2007,21 (3):8-19.]
猜你喜欢
电脑爱好者(2021年8期)2021-04-21
校园英语·月末(2021年13期)2021-03-15
电脑爱好者(2020年20期)2020-10-22
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
知识经济·中国直销(2016年5期)2016-11-07
工业设计(2016年8期)2016-04-16
电脑爱好者(2015年13期)2015-09-10
信息安全研究(2015年3期)2015-02-28
中学生英语·外语教学与研究(2008年4期)2008-03-18
