
Hadoop 下多模式并行分类算法及其应用研究
2014-12-02 01:12李玉丹郑晓薇
计算机工程 2014年12期
李玉丹,郑晓薇
(辽宁师范大学计算机与信息技术学院,辽宁 大连 116081)
1 概述
BP 神经网络(Back Propagation Neural Network,BPNN)具有高度的非线性映射能力,通过构建合适的网络,可以以任意精度逼近任何非线性映射函数,因而在众多领域得到广泛应用,如文献[1]使用BP 神经网络来识别复杂背景下的各种手势;文献[2]利用BP 神经网络对医学图像进行分类;文献[3-4]分别将BP 神经网络应用于泥石流和电力价格的预测系统中。传统的BP 神经网络训练方法,是将搜集到的全部资料样本作为一个整体训练集,在单机上串行处理。然而,在图像检索等应用领域中,此方法针对大规模杂乱无序的图像样本的多语义分类问题,往往表现出2 个方面的不足:(1)由于不同语义模式的样本特征值存在明显的差异性,这些特征值作为BP 神经网络的输入数据会使输入层的输入值发生较大跳跃,使BP 网络很难学习到样本数据的内在特征和规律,导致网络迭代时间长、训练精度低;(2)随着样本规模的不断增大,算法的串行训练方式内存开销成为瓶颈问题,通信耗时增长、系统效率低。
为解决上述问题,本文提出一种SOM-MBP(Selforganizing Mapping Multi-back Propagation Neural Network)多模式并行分类算法。该算法将自组织映射(Self-organizing Mapping,SOM)网络和多个并行BP 网络相结合,由自组织网络对全部样本进行初期自动聚类,再用不同的BP 网络训练不同的聚类样本集,改善了数据多样性的样本训练对BP 性能的影响。基于云计算平台Hadoop 中MapReduce 编程模型设计了多作业并行处理机制,实现SOM-MBP 神经网络自身及多个BP 神经网络间的并行处理,并缩短了训练时间。
2 SOM-MBP 多模式并行分类算法
2.1 自组织映射网络
自组织映射网络是一种无监督神经网络,它模拟了生物神经网络中神经元之间的兴奋、抑制与竞争机制,即一个神经元兴奋后,通过它的分支会对周围其他神经元产生抑制,实现优胜劣汰的选择过程[5],其结构如图1 所示,由输入层和竞争层两部分组成。假如输入层有n个神经元,竞争层有m个神经元,每个样本对应于输入层第i个神经元的输入值表示为Xi,竞争层第j个神经元的输出值表示为Yj;输入层与竞争层之间的连接权值表示为Wij,依据式(1)所示的学习规则,求得该输入样本的输出值Yj,规定Yj中最大值所在的神经元为获胜神经元。

图1 SOM 网络结构
SOM 网络只能实现单种模式的归类判别,当样本数据由输入层进入SOM 网络模型,通过一定的学习规则,竞争层仅有一个神经元为获胜者,将仅与获胜神经元相联系的各连接权值朝着有利于竞争的方向调整,其他权值保持不变。获胜神经元代表已定义的样本数据模式中的一种,使用式(2)调整网络权值。SOM 网络不是以一个神经元的状态矢量反映分类结果,而是以若干神经元同时反映分类结果,因此其存在需要高度训练的缺点。
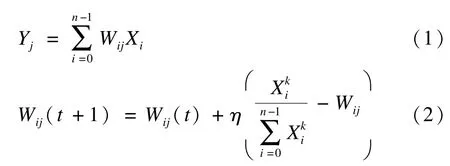
其中,η∈(0,1]为学习率为权值Wij所对应的权值增量;t为迭代次数。
2.2 MBP 并行神经网络
BP 网络与SOM 网络不同,它需要期望信号,是一种有监督的神经网络。其结构与SOM 类似,不同的是在输入层和输出层中间存在一或多个隐藏层[6]。BP 神经网络的主要思想是:首先输入样本数据,根据给定的学习规则从输入层至输出层,正向计算网络的实际输出,学习规则如式(3)所示。神经网络中各神经元的激发函数表示为f(x),第k层第j个神经元的实际输出值表示为然后将实际输出与期望信号进行比较,得到的误差从输出层至输入层反向传播,对网络权值沿着使误差缩小的方向进行修改,权值调整见式(4):

其中,η为学习率,一般介于0~1 之间;t为迭代次数。
BP 神经网络学习的目的是修改网络的权值,当学习结束时,该权值反映了同种模式输入样本的共同特征;对预测的样本数据,通过学习规则实现一种或多种模式分类。在实际应用中,要达到较好的分类效果,BP 神经网络需要进行大量的样本训练,这就需要预先获取有代表性的训练样本集。此外,由于网络的所有输出神经元的误差均影响各层之间的权值调整量,在多模式分类的情况下,不同的输出误差将产生不同的权值调整方向,会对调整效果产生不利影响。
本文设计的MBP 并行神经网络,采用多个BP网络并行集成方法,可有效地避免权值的调整效果被相互抵消的问题。在本系统中,每个并行的BP 神经网络各自训练一种语义模式,这样每个BP 网络就可最大限度地逼近其所代表的语义模式函数,充分学习各语义模式间的细微差别,提高训练精度。
2.3 SOM-MBP 多模式并行分类模型
SOM-MBP 多模式并行分类模型结构如图2 所示。本文实验选用图像样本做分类,首先对样本进行特征值提取的预处理,得到能够代表样本的特征数据,然后利用SOM 网络对样本数据进行自组织聚类,将具有相似特征和规律的样本划分为N个样本集。该N个样本集作为BP 神经网络的训练样本,这样既为BP 神经网络提供了有代表性的含有期望信号的样本数据集,同时由于同一样本集内的样本数据具有相似性,克服了因输入值跳跃造成的BP 神经网络学习效果差的问题。依据SOM 样本聚类集的个数,在N个单输出的并行BP 神经网络中,每个BP 网络独立训练一个样本集。在多语义类综合判断阶段,汇总N个BP 网络的结果,依据规定的阈值判断所属的多个模式,这样就弥补了SOM 单模式归类的不足,方便地实现多种语义模式的分类。

图2 SOM-MBP 模型结构
3 MapReduce 并行的SOM-MBP 多模式分类
目前,云计算是处理大规模数据的主流平台,Hadoop 是开源云计算平台的典型代表,Hadoop 平台下采用的并行化技术主要是MapReduce 模型[7],该模型根据分而治之的思想,将并行计算简化为Map和Reduce 过程,同时隐藏很多繁琐的细节[8],如自动并行化、负载均衡和灾备管理等[9-10]。Map(映射)函数用来把一组键值对映射成一组新的键值对;Reduce(化简)函数用来保证所有映射的键值对中的每一个共享相同的键组。
在图像分类检索的应用中,由于人工神经网络在样本学习过程中,对每一个样本均要遍历迭代所有神经元,因此当图像样本个数较多、每个样本的特征数据维数较大时,往往会出现内存开销大、通信耗时长、分类效率低的现象。本文在Hadoop 平台下将SOM-MBP 多模式并行分类模型通过MapReduce 编程模型予以并行化设计,采用Map 函数和Reduce 函数实现SOM-MBP 神经网络内部的自动并行化,同时利用MapReduce 提供的多作业并行处理机制实现多个BP 神经网络间的并行执行。此设计能大大缩短SOM-MBP 算法的样本聚类和训练时间,提高训练的精度。
3.1 SOM 子模型的MapReduce 并行方法
自组织映射网络算法由网络权值修改量的精度控制迭代次数,在每次迭代过程中,需要对所有样本数据判断其获胜神经元的位置,并修改与获胜神经元连接的权值。在MapReduce 并行中针对每一次迭代,Map 阶段判定获胜神经元,计算其相应的权值修改量。Reduce 阶段对相同的获胜神经元,统计与其连接的每个权值的总体更新量,然后对权值更新。算法如下:
(1) Map 阶段
1) 输入键值对<key,value >,其中,key 表示样本序号;value 表示样本的特征值集合;每个<key,value >对代表一个样本记录。
2) 根据学习规则计算竞争层的输出值。
3) 判定获胜神经元,将其输出状态设为1,其他所有神经元状态设为0。设定获胜标志flag 为获胜神经元在竞争层的位置。
4) 计算与获胜神经元相连接的各权值更新量,其他权值保持不变。
5) 输出键值对<key,value >,其中,key 表示flag 获胜标志;value 表示与获胜神经元相连接的各权值更新量。
(2) Reduce 阶段
1) 接收Map 阶段的结果作为输入键值对<key,value >,其中,key 表示flag 获胜标志;value表示list <与获胜神经元相连接的各权值更新量>,即具有相同获胜标值的权值更新列表作为value 值。
2) 累计每个权值的总体更新量,求得平均更新量。
3) 调整相应的网络权值。
4) 输出键值对<key,value >,其中,key 表示权值更新状态;value 表示更新后的网络权值。
5) 更新全局文件,使文件中对该网络的权值为reduce 的输出值。
重复以上MapReduce 过程,直到各权值的调整量趋近于规定的精度值。
3.2 MBP 子模型的MapReduce 多作业并行方法
本文中SOM-MBP 网络模型的BP 神经网络部分是将多个单输出的BP 并列集成,在Hadoop 云计算平台下,将每个BP 神经网络加载为一个独立的作业,由MapReduce 框架提供的submit()方法并行提交作业,实现多个BP 神经网络作业的并行执行。同时,每个BP 神经网络由Map 函数和Reduce 函数实现其自身内部的并行处理。Map 阶段计算每个样本数据其对应的所有权值变化量。Reduce 阶段统计整个网络中每个权值的总体更新量,然后对权值进行更新,写入Hadoop 文件系统,供下一次迭代使用。
(1) MBP 子模型的Map 阶段
首先将SOM 算法的聚类结果,即样本的特征值集合+类别信号,作为BP 神经网络输入键值对<key,value >的value 值,样本序号作为key 值,输入到网络中。根据式(3)的学习规则向前逐层计算网络的输出值。与SOM 不同,在网络输出层无需判定获胜神经元,而是将输出层的实际输出值与期望的类别信号比较,逐层计算学习误差。然后根据学习误差计算网络中每个权值的更新量。将每个样本所对应的所有权值更新量作为Map 输出键值对<key,value >的value 值,输出给Reduce 阶段使用。
(2) MBP 子模型的Reduce 阶段
接收来自Map 阶段的输出结果,即每个样本所对应的所有权值更新量。然后累计所有样本相同权值的总体更新量,得到每个权值的总体平均更新量并更新网络中的各权值。将更新后的网络权值作为Reduce 阶段的输出写入到HDFS 上指定的权值文件中,以供下一次迭代使用。
重复以上Map-Reduce 过程,直到误差达到定义的精度或达到最大迭代次数。
4 实验结果与分析
为验证SOM-MBP 多模式并行分类算法在Hadoop 云计算平台下对大量数据集的分类效率,对自然风景图像进行了多种语义模式分类的测试实验。
4.1 实验环境及数据
硬件配置:Hadoop 集群平台由55 个节点机构成,各节点机均为Intel(R) Core(TM) i3-3240 CPU @3.40 GHz,4.00 GB 内存,64 位操作系统。
软件:Linux 操作系统Ubuntu13.04;编程环境为MapReduce 类库和Eclipse 编译器;程序设计语言为Java 语言。
实验数据:实验数据选自互联网百度图像库。选取涵盖日光、河海、高山、树木、花朵5 种类别的自然图像,图像总数多达30 000 000 幅,图像分辨率是300 ×210 像素。
模型结构:由于本文实验是对自然风景图像进行5 种语义模式的多语义分类,因此自组织映射网络的竞争层神经元个数为5 个,相应地,构建5 个单输出的BP 神经网络。图像样本预处理阶段,在OpenCV 环境下对每幅图像样本从颜色、纹理、形状3 个方面进行底层特征的提取,其中,颜色特征64 维、纹理特征48 维、形状特征7 维,即每幅图像特征向量共计119 维,因此,对SOM 和每个单独的BP神经网络而言,依据所提取的图像样本底层特征数量,输入层节点个数Ni取119,每个单独的BP 神经网络其输出层节点个数No为1,隐藏层节点个数依据经验公式,经过反复实验取15 效果较好。
4.2 实验结果
实验结果具体如下:
(1) 文献[11]采用单BP 多个输出的网络模型对自然图像进行多种语义的分类,本文将该分类算法引用到本文实验环境中并通过Java 予以实现,选取5 000 幅作为测试样本,30 000 幅为训练样本,将其分类测试结果与本文提出的SOM-MBP多模式并行分类算法测试结果进行对比,如表1所示。

表1 不同分类算法测试结果对比 %
由表1 数据可计算出,文献[11]单BP 多输出分类算法的总体平均查全率为79.1%,平均准确率为81.0% ;SOM-MBP 多模式分类算法的总体平均查全率为88.2%,平均准确率为87.6% 。
(2) 单BP 多输出神经网络分类算法、SOM-MBP顺序串行与MapReduce 并行的SOM-MBP 多模式分类算法,在图像样本总数从3 000 幅~30 000 000幅数据量下的运行时间对比如表2 所示。

表2 算法运行时间对比 s
(3) 为检测并行优化的结果,对程序运行的并行加速比进行对比,加速比的定义如下[12]:
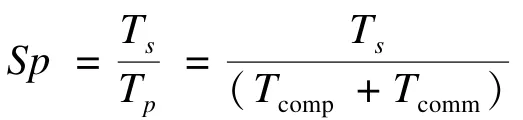
其中,Ts为单个处理器上求解问题所花的时间;Tp为p个相同处理器并行计算机求解同一问题所花时间;Tcomp为计算时间;Tcomm为通信时间。
Hadoop 下并行SOM-MBP 多模式分类算法的加速比随节点个数、样本数量变化趋势如图3 所示。
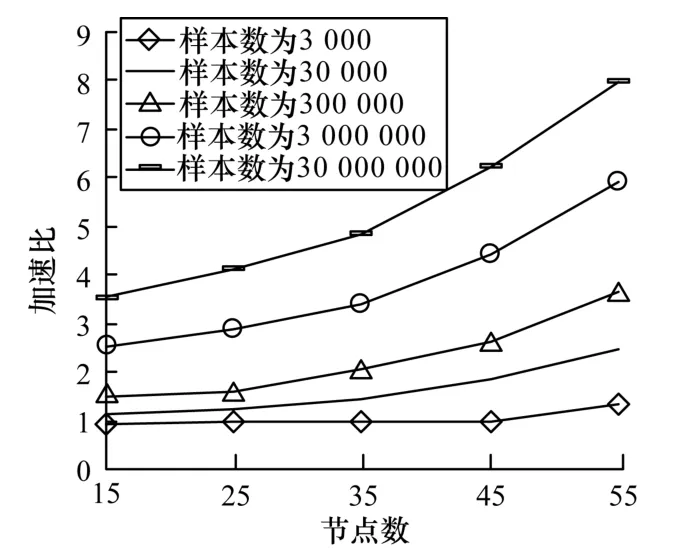
图3 Hadoop 下并行SOM-MBP 多模式分类算法的加速比
4.3 结果分析
从表1 的实验结果可知,由于SOM 阶段将具有相似特征和规律的图像划分为一个样本集,每个BP神经网络训练一个样本集时能够充分学习该类图像间的细微特征差别,因而与文献[11]提出的单BP多输出分类算法相比,本文的SOM-MBP 多模式并行分类算法表现出了更高的查全率和准确率,表明了采用MapReduce 并行的SOM-MBP 多模式分类算法在自然图像多模式分类中的高效性。
由表2、图3 可见,MapReduce 并行的SOM-MBP多模式分类算法在样本数为3 000 时,由于Hadoop 自身系统开销等原因的影响,并行处理速度并不如串行SOM-MBP 算法,但当样本个数达到30 000以上后,由于采用并行化及Hadoop 分布式文件存储,降低了数据网络传输的开销和内存开销,并行效率开始显现,随着数据量的增大并行处理速度逐渐提高、加速比逐渐增长;当样本个数达到300 000后,加速比增长趋势更明显,这充分体现了该Hadoop 下并行SOM-MBP多模式分类算法在处理大规模数据时的优越性,说明了该算法是有效可行的。
5 结束语
在模式识别及样本分类中,由于同种模式内的样本特征值存在相似性,异种模式间的样本特征值差异性较大,因此对复杂无序的样本进行多种语义模式的分类时,BP 神经网络通常很难学习到样本数据的内在特征和规律,同时随着数据规模的不断扩大,在对大数据的存储和处理过程中会产生内存溢出、数据解析时间长、磁盘与内存之间传输过大等问题,导致BP 网络很难达到较好的分类效率。本文根据人工神经网络自组织和高度并行的特点,提出一种云计算环境下MapReduce 并行的SOM-MBP 多模式分类算法,并在Hadoop 集群上进行了应用测试。实验结果表明,该算法相比传统单BP 多输出算法训练速度更快、分类精度更高,验证了该算法的有效性和可行性,为神经网络在多模式分类中的应用提供了借鉴。
[1]王先军,白国振,杨勇明,等.复杂背景下BP 神经网络的手势识别方法[J].计算机应用与软件,2013,30(3):247-249,267.
[2]孙君顶,李 琳.基于BP 神经网络的医学图像分类[J].计算机系统应用,2012,21(3):160-162,212.
[3]Chang Tung-Chueng,Chao Ru-Jen.Application of Backpropagation Networks in Debris Flow Prediction[J].Engineering Geology,2006,85(3/4):270-280.
[4]Meng K,Dong Z Y,Wong K P.Self-adaptive Radial Basis Function Neural Network for Short-term Electricity Price Forecasting[J].IET Generation,Transmission &Distribution,2009,3(4):325-335.
[5]肖 婧,郑更生,方 勇,等.基于自组织神经网络的分簇成链协议[J].计算机工程,2013,39(7):148-151.
[6]肖会敏,郭 鹏.基于主成分分析与BP 神经网络的供应商选择模型[J].计算技术与自动化,2013,32(1):130-133.
[7]贾瑞玉,刘范范,潘雯雯,等.基于MapReduce 模型的并行量子进化算法[J].计算机工程,2012,38(8):180-182,188.
[8]Jeffrey D,Sanjay G.MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM,2008,51(1):107-113.
[9]李建江,崔 健,王 聃,等.MapReduce 并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[10]刘 义,景 宁,陈 荦,等.MapReduce 框架下基于R-树的k-近邻连接算法[J].软件学报,2013,24(8):1836-1851.
[11]谢文兰,石跃祥,肖 平,等.应用BP 神经网络对自然图像分类[J].计算机工程与应用,2010,46(2):163-166.
[12]陈国良.并行计算:结构,算法,编程[M].北京:高等教育出版社,1999.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
自然杂志(2021年6期)2021-12-23
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
电子制作(2019年19期)2019-11-23
现代装饰(2018年5期)2018-05-26
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
电源技术(2015年5期)2015-08-22
