
基于语义限制的模糊规则结构设计
2014-12-02 01:12张可佳李春生
计算机工程 2014年12期
张可佳 ,李春生 ,王 梅
(东北石油大学a.计算机与信息技术学院;b.现代教育技术中心,黑龙江 大庆163318)
1 概述
人工智能发展至今,各种混合智能方法层出不穷,如InterBay 方法[1]、不确定推理下的混合智能图像分割方法[2]等。由于知识是多数智能方法实现中最基本的组成元素,能够描述业务逻辑的表达内容,因此在智能化应用过程中起到决定性因素之一的依旧是知识[3]。模糊概念的提出解决了某些定性化知识无法定量转化的问题,降低了知识推理的唯一性限制,拓宽了知识应用领域,使知识推理的并发性和概率性更具意义[4]。以领域决策者和专家为代表的知识人对于知识的重要性体会颇深。虽然现在通过知识推理或模式匹配等智能化方法可以很好地解决领域内的故障诊断、危险评估、作业方案优选等问题,但是依旧或多或少地存在以下缺陷:(1)由专家组成的决策群体对于知识单体具有相同的判别倾向,但倾向程度会有不同,倾向程度反映了专家对于知识的深度认识和潜在经验,这对于模糊集下提高精细化计算至关重要[5],现有的多数知识结构往往忽略如何科学合理地统一专家倾向程度。(2)技术的快速发展导致知识自学习训练过程中影响因子繁多[6],计算过程复杂,对于知识自适应调整的因素考虑过于离散并依赖专业知识,导致很多专家系统的智能化自适应机制复杂,应用性较差。
针对上述问题,本文通过C-E 模型设计基于语义限制的模糊规则,改进有限集语义限制表达方法[6],将专家倾向进行定量化描述,作为知识结构的重要因素。采用非线性拟合、均方差收敛等数学手段实现规则自适应过程,以屏蔽自适应调整过程中复杂的专业因素,并由规则对象组成条件组构成基于类框架的知识结构,实现降低领域影响因子的影响、提高模糊知识的精细化准确程度、深度挖掘知识人与知识潜在关联的目的。
2 C-E 模型的引入
规则是知识的重要组成部分。将类型相同的规则进行聚类抽象得到C-E 模型。具体定义如下:
定义规则R可由表示支持其隶属度计算的属性及相关方法的集合C(核心集)与表示其他表征意义的属性及相关方法的集合E(扩展集)表示。其一般形式如下所示:

其中,R表示模糊规则;C表示直接参与隶属度计算的参数、函数及控制行为的集合,也称核心集合,C不为空;E表示描述R的其他属性及行为的集合,也称扩展集。声明间接参与隶属度计算、辅助非线性拟合过程的训练样本也属于E集。
C-E 模型将涉及隶属度计算的核心属性及行为抽象统一,与其他属性及方法分开,能够清晰地表述某抽象理论的实例化模型,提高结构的松散度,易于理解和深入研究。
3 基于语义限制的模糊规则设计
通常由专家组对于某规则的结论判别具有相同的倾向,但是倾向程度不同。例如:∀模糊规则R,描述为X隶属度为V。专家们对于R的判断均可能为真,但会出现不同的判断倾向程度[7],于是引入语义限制进行判断倾向程度描述。
很多人工智能方法试图引入语义限制进行倾向性描述,在自然语言学的原型中,对于语义限制进行过定量化分析,但是分析结果仅为有限的非连续映射点集,对于准确度存在一定影响。针对这一问题,提出一种语义限制的描述方法,以连续有界的非线性函数描述语言变量的倾向程度,称该函数为语义限制函数。
以上文所述C-E 模型作为模糊规则的载体,设计基于语义限制的模糊规则结构,表示如下:
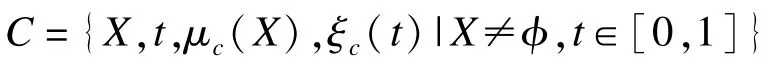
其中,C是C-E 模型中的核心集;X表示需要进行隶属度计算的隶属因子;μc(X)表示计算规则隶属度的特征函数;t表示语言变量;ξc(t)表示计算该隶属度倾向程度的语义限制函数,语义限制变量t的取值范围为[0,1]。规则默认类型为模式匹配。
定义初始状态的原始语言变量集Go={t}来自于专家组的不同倾向度,表示为有限集Gexis={t1,t2,…},根据枚举的边界性得到Gexis∈[min(t),max(t)],t∈[0,1],Gexis的边界一定落在[0,1]区间,根据专家的分析特点,∀相对狭小区域Glim,满足Gexis⊂Glim,Gexis是语义限制函数初始化过程的重要组成部分。
3.1 规则表达式
通常特征函数μc(X)∈[0,1],为了保证取值范围不会过小,递增率保持较低,令规则采用幂函数法表达。取模糊规则R的核心集C,规则的匹配度PR的表达式如式(1)所示:

令μc(X)≠0,公式可变形为:

式(2)表示了规则R的核心集内元素的相互关联关系。实现用语义限制函数对规则的匹配度进行衡量。值得注意的是,当令t≡u,u为常数时,规则R的匹配度将不再受语义限制影响。
3.2 语义限制函数的计算
语义限制函数ξc(t)用来描述语言变量的倾向程度,通过分析大量事实数据可知,在规则前项一定时,t与PR构成的点集分布相对趋近于正态分布,且Gexis为有限集,可以不予考虑ξc(t)的不定积分形态,所以采用高斯函数的标准形式作为ξc(t)的表达式,并将其引入语义限制函数,可表示为式(3):

将式(2)带入后得到式(4):
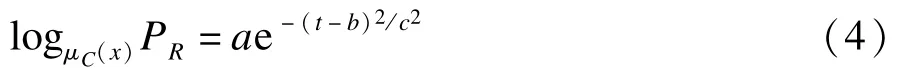
当假设a=0,μc(X)=1 时,规则R将可以表示为经典(清晰)规则。当令c2=2 时,高斯函数变为傅里叶变换的特征函数[8],可以考虑引入量子计算方法进行深入研究。而用于拟合的函数形态也可以根据实际环境择情选取。
3.2.1 拟合过程
拟合过程包括初态拟合和测试拟合,前文已述辅助非线性拟合过程的训练样本存在E集中,在规则被定制时收集原始训练样本Gexis及Iexis,Gexis为初始语言变量t的集合,Iexis为在初始语言变量t作用下专家评估的规则匹配度PR的集合,μc(X)作为计算涉及领域影响因子的模糊隶属度可视为已知量,做Gexis与Iexis的映射关系,获取初态训练样本M:M={(t1,PR1),(t2,PR2),…,(tn,PRn) |tn∈Gexis,PRn∈Iexis}通过M对语义限制函数ξc(t)进行拟合的过程称为初态拟合,也称为规则的初始化。考虑原始训练样本与拟合函数间的可能关系如图1 表示。
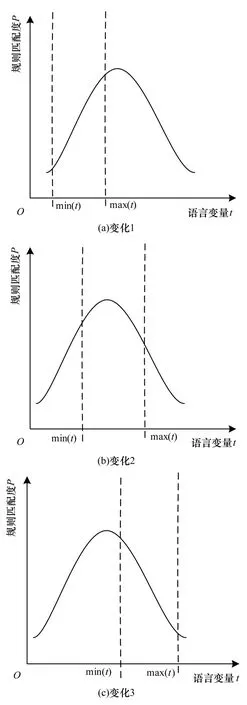
图1 原始训练样板的散落形态图
A,B,C描述的3 种表征,对于表征B,C在曲线拟合后取区间的ξc(max(Gexis)),ξc(min(Gexis))为最优值解,对于表征A需要在测试训练过程中经过不断校正获取最优(峰值)解。考虑有限集Gexis的实际状态会出现污染点,为了提高拟合精度,根据亚像素边缘检测算法[9]进行Gexis校正和拟合,根据函数取亚像素值η=b/2a,详细过程不做赘述。
在规则被选用并进行匹配的过程中,取以往所有训练样本集合G,I。其中,G={t}表示训练样本中t的集合,令Gexis⊂G,I={PR}表示训练样本中t值下规则R的最终匹配度,令Iexis⊂I,做G与I的映射关系,获取测试训练样本N并进行拟合的过程称为测试拟合,测试拟合过程本质上是对专家综合意见的校正。
3.2.2 自适应机制
在规则的匹配过程中,应用系统希望规则可以自行进行细微的误差调整,实现自适应和自校正的过程[10]。以可自适应调整的模糊规则结构为基础,提出一种自适应机制。具体过程如下:
Begin 当规则进行匹配时触发:
Step 1计算命题:当前ξc(tn+1)计算与上次结果微分差极小,当命题为假时以tn带入原ξc(t)进行规则匹配。
Step 2若Step 1 命题为真,计算下一次语义变量tn+1。
Step 3若Step 1 命题为真,重新拟合修正语义限制函数ξc(t)。
Step 4若Step 1 命题为真,将tn+1带入修正后的ξc(t)中进行规则匹配度计算。
在上述过程中,通过拟合重新计算ξc(t)过程。tn+1的获取方法如下:将已进行n次训练的集合G={t}中的t均值的表达式表述为:

根据均方差收敛法则,样本个数n足够大时,t将逐渐收敛为接近恒定数值,于是采用标准差作为误差距离测定方法。考虑每次实际P′R与PR的差距P′R-PR过小,于是用平方放缩法进行差值干扰,进行tn+1描述表示为:

在式(6)中,下次语言变量tn+1的取值与历次训练的语言变量及匹配度差P′R-PR有关。取ξc(tn)的最优解,考虑ξc(t)函数历次变形后临近两点的变化率近似为0,于是当满足条件:ξ′c(n)(tn) -ξ′c(n-1)(tn-1)=Δs,Δs→0 时,自适应过程终止。
4 模糊规则结构设计原理
4.1 知识结构
框架作为一种知识表达技术具有结构化清晰、表达简化的优点,采用框架表示法的思想设计知识的结构,定义类框架FC表示知识,FC内包含一组用于计算知识吻合度的条件,条件包括条件因子及界定条件因子影响程度的影响权重。采用规则的实例化对象表示条件因子,定义实数v作为条件因子的影响权重,于是有:
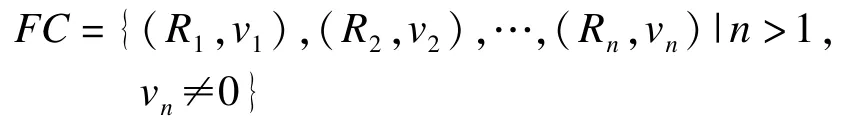
其中,(Rn,vn)用于描述条件单体;基于语义限制的模糊规则的实例化对象Rn表示条件因子;vn表示在Rn作用下的影响权重。条件因子间相对独立,且满足
4.2 知识结构的吻合度计算
默认基于语义限制的模糊规则知识结构中FC的条件关系为And,根据知识表达式有:
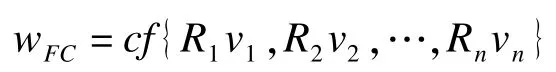
其中,wFC表示某基于语义限制的模糊规则知识的最终吻合度;cf为计算公式;Rnvn为算子,根据类框架FC关系可建立最终吻合度与算子的关系:
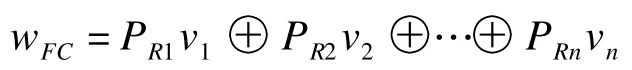
根据条件因子的独立性及定量统计法原理得到吻合度计算公式:

式(7)也称为充分性吻合度公式,可以直观描述所属知识与事实的吻合度情况。根据论据累积的Bayes 思想[11],也可以采用式(8)描述吻合度情况:

式(8)也称为必要性吻合度公式,计算结果可作为在知识推理过程的咨询解释参考标准之一。
5 设计实例
以基于语义限制的模糊规则结构为基础,设计故障诊断专家系统模型,通过模式匹配进行异常井原因诊断分析,应用在某采油厂地质大队。为了避免地质师的初次理解障碍,通过与语言专家交流和反复推敲,对50 余种常规自然语义限制词定量化,通过此方法让专家们理解应用过程,如表1 所示。

表1 语义限定词的定量化映射
在表1 中,t表示在专家理解后可忽略自然语义限制根据实际情况按需粒度化细分。
以某异常井故障病症,即抽油机长期停转为例[12]。对应自然描述为油井月生产时间正常的情况下,冬天寒冷时,含油饱和度适中,但产油量下降严重,井壁温度低,认为可能发生抽油机长期停转。通过油藏数值、抽油机技术等知识结合专家对该知识进行模型构造,如图2 所示。
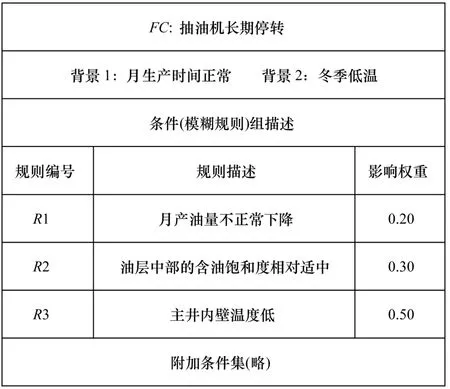
图2 描述抽油机长期停转的模型结构
为了节约篇幅,以R3 进行详细分析:取样15 名不同矿区及厂级地质师依据以往的不同环境下的实际经济,结合主井内壁温度低的影响程度与低温程度进行分析,在背景2 影响下各井所处地表环境温度几乎相同,各井位处同一大地质层,外因因素影响差别极其微弱,同时由于地表低温影响导致内壁温度散热快,时间轴表达较为清晰,分析结果的差异性较为明显。根据领域知识,获取时间与温度的特征函数T(x),取15 位专家在同业务环境下相互独立的意见,如表2 所示。其中,t,p为专家初始提供的语言变量和匹配度数据;t′,p′为经过数据清洗和整理后获得的数据。
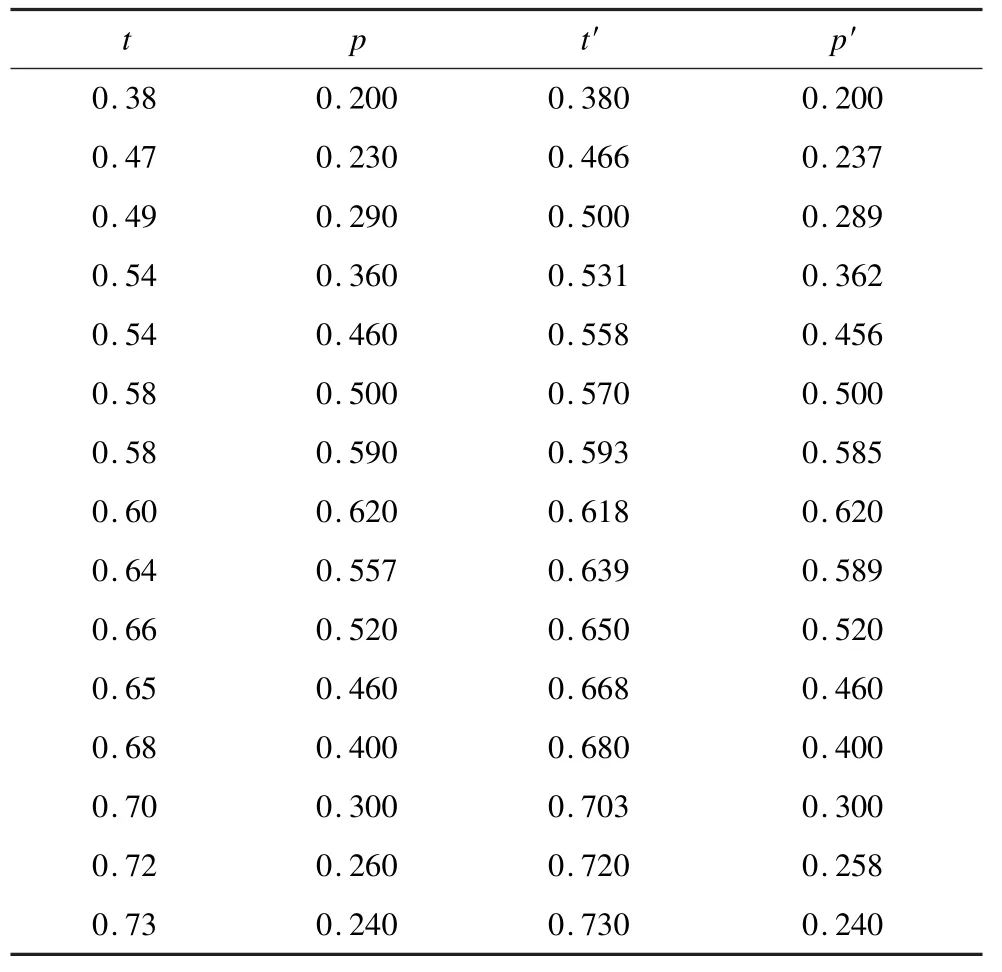
表2 专家意见定量化结果
将数据进行分布后,得到如图3 所示的结果。
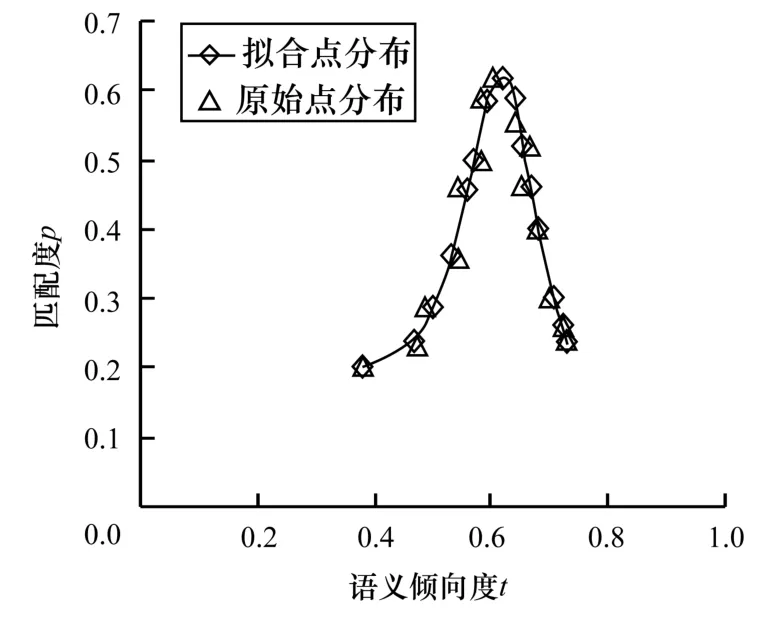
图3 针对专家意见的曲线拟合结果
经过初始化拟合得a=2.8,b=2.5。在测试训练中,根据x的取值进行特征函数计算,取业务特征函数T(x)的隶属度为0.8,初次将带入得到ξc(t)=2.1,于是有总的匹配度为PR=(0.8)2.1≈0.626,专家意见经过拟合后初始规则的匹配度为0.626,匹配权重为PRvR=0.626 ×0.5=0.313。表3 表示通过对葡萄花油层南2 区多口异常井诊断的实际测试训练后的结果。
经过上述分析统计可知,误差精度差约5%,同时可以发现,壁温影响的概率越高,误差精度越小,所以,基于语义限制的模糊规则结构表达高匹配度规则的效果更好。
矫正后得到t=0.631 时,该规则的匹配度将最大,同理对R1,R2 进行训练。最终评估某井N2-4-216,计算最终结果为:

即有73.2% 的可能该井发生抽油机长期停转。经过作业大队的检修,确定该井抽油机已经停转42 h,根据该型号抽油机故障参数评估,认为该井已属于长期停转范畴,同时由历史检修数据记录,该井区同期检修28 次,发生抽停20 次,抽停概率约为71.4% 。
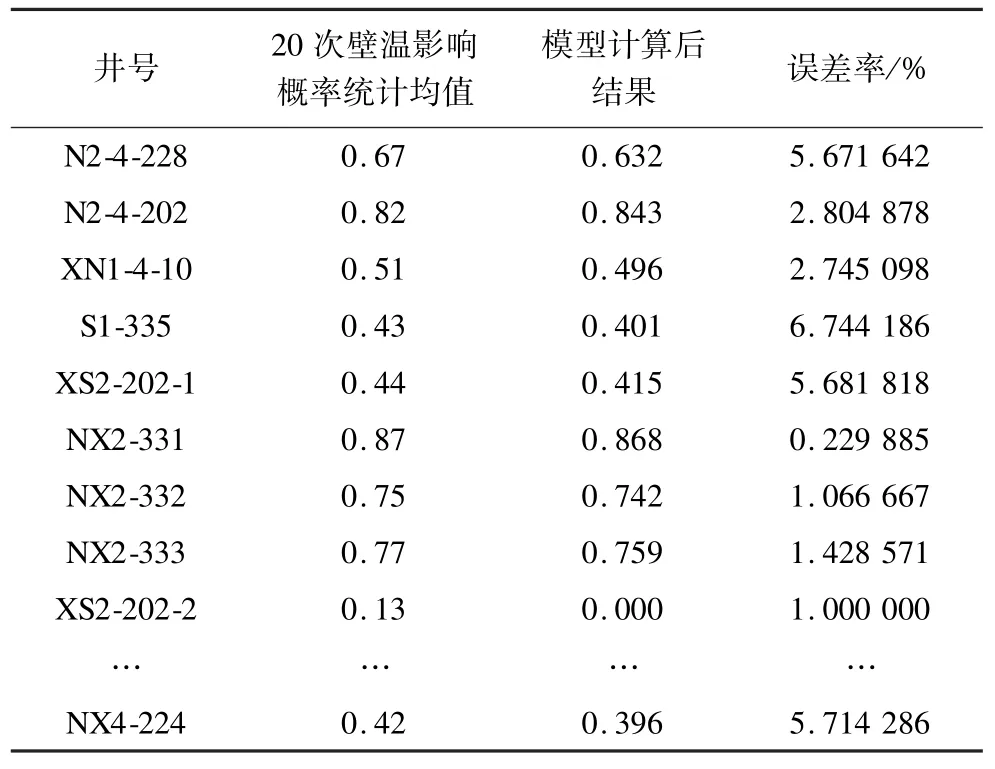
表3 针对抽油机长期停转的测试训练对比结果
根据基于语义限制的模糊规则模型开发的故障诊断系统,动态分析辅助系统已经正常工作,因为其对专家意见的深度合理分析、较好的自适应性和相对简单的应用过程受到了应用单位的较好评价。
6 结束语
本文提出的基于语义限制的模糊规则知识结构,以C-E 模型构建规则结构,引入并改进语义限制方法表达模糊规则,并将规则实例化为条件。结合知识的框架表达方式和条件组概念清晰明了地描述知识的结构,同时经过数据提取和分析给出科学合理的计算方法,更加符合当前专家知识的获取模式,达到深度挖掘知识人与知识的关联关系、提高精细程度的目的。
[1]吴立辉,颜丙生,张 洁.一种混合智能的InterBay 系统调度方法[J].计算机工程,2012,38(22):228-231.
[2]Negnevitsky M.人工智能智能系统指南[M].陈 薇,译.北京:机械工业出版社,2012.
[3]何新贵.知识处理与专家系统[M].北京:国防工业出版社,1990.
[4]向 艳,王洪元.基于模糊推理模型的专家系统的研究与应用[J].计算机工程,2005,31(10):179-182.
[5]潘正华.模糊知识的三种否定及其集合基础[J].计算机学报,2012,35(7):1421-1423.
[6]高雅田,李春生,富 宇.基于关系数据分析的知识服务模型[J].计算机工程,2011,37(5):56-59.
[7]曾文雄.模糊限制语的语言学理论与应用研究[J].外语教学,2005,26(5):27-30.
[8]赵学智,陈文戈,林 颖,等.基于高斯函数的小波系及其快速算法[J].华南理工大学学报:自然科学版,2001,29(1):94-97.
[9]尚雅层,陈 静,田军委.高斯拟合亚像素边缘检测算法[J].计算机应用,2011,31(1):179-180.
[10]王亚南.专家系统中推理机制的研究与应用[D].武汉:武汉理工大学,2006.
[11]Alavi M,Leidner D E.Knowledge Management and Knowledge Systems:Conceptual Foundation and Research Issues[J].Management Information System Quarterly,2001,25(1):107-136.
[12]李春生,高雅田.基于主词网的油田施工方案辅助设计模型[J].东北石油大学学报,2010,34(5):138-144.
猜你喜欢
石油石化节能(2022年12期)2022-12-30
开放教育研究(2020年2期)2020-03-31
科技创新与应用(2020年6期)2020-02-29
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
中国煤层气(2014年6期)2014-08-07
河南科技(2014年16期)2014-02-27
