
基于暗原色先验及运动检测的视频去雾方法
2014-11-30 07:48刘东辉兰时勇杨红雨吴树霖朱超军
计算机工程与设计 2014年1期
刘东辉,兰时勇+,杨红雨,吴树霖,朱超军
(1.四川大学 计算机学院,四川 成都610065;2.四川大学 视觉合成图形图像技术国家重点学科实验室,四川 成都610065)
0 引 言
近年来基于大气散射物理模型的单幅图像去雾方法成为去雾领域研究的热点,并且取得了很大的进展。如Fattal[1]假定雾霭天气下大气透射率和表面阴影在局部是不相关的,通过估计场景的反射率,进而求得透射率,Fattal的算法对于薄雾图像的处理效果很好,但是当雾很浓时效果很差,并且算法复杂度高。He[2]等人提出了一种暗原色先验的物理统计规律,结合大气散射模型和soft matting[3]修复进行去雾,该算法不仅在物理上有效,并且可以处理浓度较大的有雾图像,不过He的缺点也是算法复杂度高、处理速度慢。Jean-Philippe[4]对原彩色图像进行最小值滤波,然后对滤波后的图像用中值滤波计算局部均值和标准差,进而求得大气光幕,恢复出场景的无雾图像,这种方法对存在景物深度突变的区域去雾效果很差,去雾后的图像在该区域还存在较多残雾,而且会产生光晕。
目前,在视频实时去雾方向的研究还比较少且不够成熟,视频实时去雾方法主要在背景、前景分割的前提下,分别利用相关的去雾算法进行复原处理,再将两者处理后的结果进行融合得到完整的无雾视频。如Jisha-John[5]等采用小波融合的方法对雾天视频进行增强,虽然这种方法处理效率很高,但是需要人工设置不同视频中的相关阈值,并且处理后的视频图像中会有块状噪声。Xu Zhiyuan[6]等人通过对比度约束的自适应直方图均衡化的方法对背景、前景进行去雾,这种方法的缺点在于处理后的视频图像颜色不够自然。
单幅图像去雾算法处理效果好,但是效率太低,达不到实时要求;现存的视频实时去雾算法处理速度满足了,但是在效果上又不够理想。总之,鱼与熊掌不能兼得。
针对以上问题,本文提出了一种结合He的暗原色先验理论与背景、前景差分的实时高清视频去雾方法,并且改进了He方法中求取大气光的过程。在保证处理效果的前提下,提高了处理速度,达到实时去雾的目的。
1 暗原色先验单幅图像去雾
1.1 大气散射物理模型
在计算机视觉和图形学中,雾化图像被广泛地描述为方程
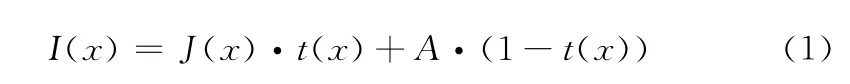
式中:I——雾化图像的强度值,J——场景无雾情况下得强度值,A——空气强度值而t则是场景强度在各个区域通过程度的描述 (也称作透射率)。去雾的本质就是从I中获取J、A和t。
1.2 暗原色先验理论
暗原色先验理论是经过对大量室外无雾图像的观察统计得到的:在大部分非天空的局部区域里,存在一些像素它的3个通道中至少有一个通道颜色值很低。也就是说,在该局部区域里景物光线的强度值的最小值趋于零。对于图像J有
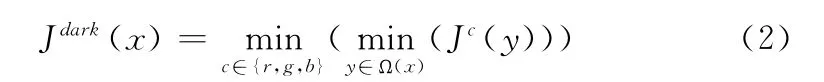
式中:Jc——J的一个颜色通道,Ω(x)——以x为中心的局部区域。通过观察统计得到,Jdark的强度值很低且趋于零。假设J是室外的清晰图像,我们将Jdark称作图像J的暗通道。
1.3 求取透射率
对式 (1)两边取最小值操作,并在3个颜色通道中取最小值运算。假设A是一个定值,根据暗原色先验理论可知Jdark接近0,把式 (2)代入式 (1)可求得初始透射率t,由于在局部区域内透射率t不是一个定值,所以这样求得的透射率包含一些块状效应。由于雾图形成模型方程 (1)和抠图方程I=F×α+B×(1-α)在形式上很相似。透射率t的分布其实就是α的分布,所以He使用了一种软抠图算法来完善透射率。最优的t通过求解下面的方程得到
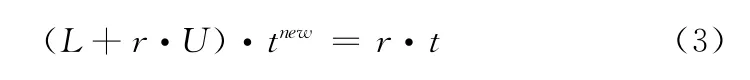
式中:U——一个与L具有相同大小的单位矩阵,r——一个具有较小值的修正系数,L——抠图拉普拉斯矩阵。式(3)具体定义请参见文献 [3]。
1.4 估测大气光强度值与去雾
首先选取暗原色中亮度值最大的0.1%的像素。在这些像素中,原有雾图像I中强度值最大的像素点的值作为大气光A的值。根据A、tnew代入式 (1)就可以得到复原后的图像。
He的算法中最大的问题在于优化透射率t的过程中需要构建大小为图像高度乘以图像宽度的抠图拉普拉斯矩阵,且每一个像素值都要计算,耗时太多,后来He使用Christophe Clienti[7]的快速算法来实现求局部区域最小值的操作,并且使用引导滤波[8]来优化透射率大大提高了处理速度,但是还达不到实时的要求。
2 背景差分实时高清去雾
对于监控相机来说,视频各帧的背景一般是固定不变的,尽管针对单幅图像采用暗原色先验求得透射率然后进行去雾的效果比较好,但是如果每一帧都计算背景的暗原色、透射率,势必会浪费大量时间,无法满足实时要求[9]。本文的思想就是将背景与前景运动目标分离出来,对于背景,每隔一定的帧数求一次背景透射率,对于前景运动目标的透射率,每一帧都进行计算,然后将两者的透射率融合起来进行去雾。
2.1 改进大气光的估计方法
He的暗原色先验去雾中大气光A值求取是首先选取暗原色中亮度最大的0.1%的像素。在这些像素中,原图像I中强度值最大的像素点的值作为大气光A的值[2]。当图像中有大片白色物体时,这种方法会产生误差,求得的大气光的位置会落在白色物体上。本文在求取大气光A值的时候是取这些像素对应在原图I中的平均值作为大气光值,经过测试,这样求取的大气光值更准确,去雾效果更自然。
2.2 算法流程
如图1所示。首先提取前N帧的图像求像素平均值作为初始背景图像。公式如下
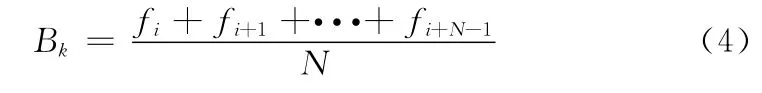
式中:N——重建的图像帧数,Bk——重建的初始背景图像,fi——第i帧图像,N帧图像每一个像素点的值累加平均构成了背景图像中对应的像素点的值[10]。
根据创建好的背景图像用改进的暗原色先验法求大气光强度值A及背景透射率tk。设置一个全局的标记值num,初始化为1,创建一个新的线程,每当num=2的时候这个新线程就计算一次背景透射率。然后在主线程中,如果num=1就将计算好的背景透射率复制过来,同时将当前更新好的背景复制给新线程,然后进行背景差分来检测运动目标,计算运动目标的透射率,将两者透射率融合起来,进行去雾,然后num值加1,如果num值大于阈值M的话就把num重新设置为1,也就是说每隔M帧算一次背景透射率,这样既保证了效果,又能满足实时的要求。M值的选取要根据算一次背景的透射率需要多长时间及主线程中处理一帧需要的时间有关

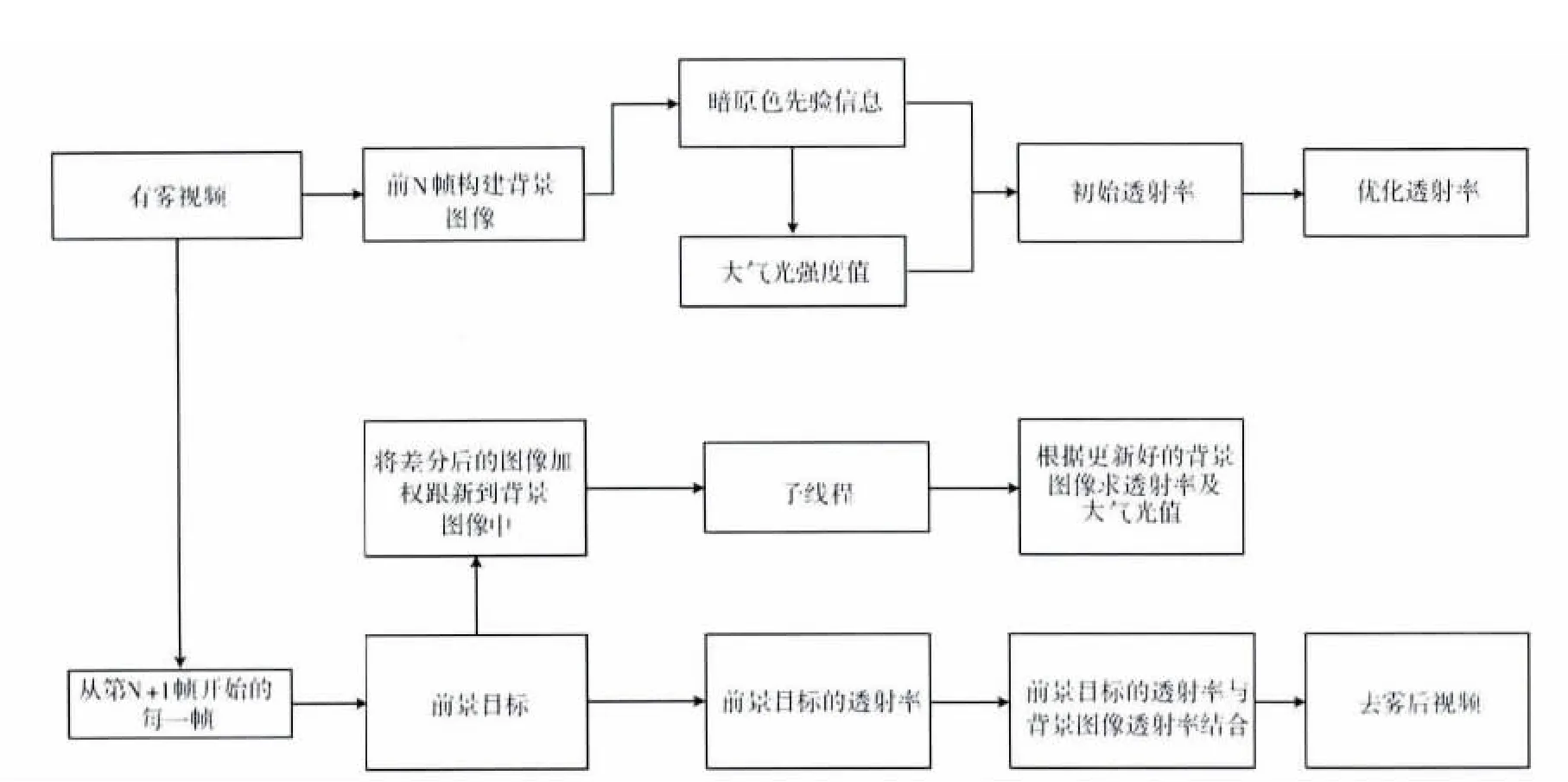
图1 去雾算法流程
式中:t1——新线程中计算背景透射率需要的时间,t2——主线程中处理一帧需要的时间,同时1/t2也是本去雾方法的实时帧率。最后要进行背景更新,本文采用Surendra[11]背景更新算法。主要思想就是通过帧差法找到运动区域,对运动区域内的背景用之前的背景覆盖,非运动区域的背景用当前帧进行加权更新。
并且在去雾过程中利用CUDA (compute unified device architecture)技术,构建CPU和GPU协同工作的编程模型。CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题,传统的GPU架构受其硬件架构的影响不能有效利用资源进行通用计算,而利用CUDA可以使GPU不仅能执行传统的图像计算,还能高效地执行通用计算,大大提高了处理速度[12]。
3 实验结果和分析
求取大气光A时,局部区域的大小为15*15;在Visual Studio 2008平台上使用C++、OpenCV编程实现。硬件配置环境为:显卡 (NVIDIA GeForce GTX 690 2GB),CPU (Intel?CoreTMi7-3770K @3.50GHz),内 存 (4GB RAM)。
3.1 实验结果
通过图2、图3两帧不同分辨率的视频图像的去雾结果可以看出,Jean-Philippe在景深突变区域去雾效果不好,存在较多残雾,且有光晕现象。在图2中按照He的方法求得的大气光在左边较亮的建筑物上,如图中矩形框标记处,大气光位置不准确,所以图2用He的方法去雾效果不好,天空部分失真。而在图3中由于用He的方法求得的大气光的位置正好在左上角的天空部分,如图中矩形框标记处,所以图3用He的方法能够取得很好的效果。相比来说本文算法在效果上要好于另外两种方法。

图2 图像分辨率为800*457的去雾结果对比

图3 图像分辨率为1280*720的去雾结果对比
3.2 处理速度
对于800*457像素的彩色图像和1280*720的高清图像的处理时间表1给出了3种方法的对比结果,从表中可以看出本文方法对于高清视频图像每秒可以处理22帧,达到了实时去雾的要求。

表1 不同方法的处理时间对比
4 结束语
本文在改进了He的暗原色先验去雾中对大气光的估计的同时,结合背景差分运动目标检测算法进行视频去雾,该方法在保证去雾效果的基础上,大幅度的提高了处理度速度,达到了实时去雾的要求,不过由于复杂场景下的背景模型不好建立,对于复杂的运动场景,提出一种更好更精确的背景模型建立及运动目标检测方法是下一步要解决的问题。并且因为暗原色先验是一种统计规律,当图像中的景物和大气层接近且没有阴影遮挡,或者存在大片灰白色区域时,暗原色先验理论是无效的,去雾效果就比较差。更加先进的去雾模型能够描述复杂的场景,像阳光对大气光的影响等,这也是下一步我们需要研究的内容。
[1]Fattal R.Single image dehazing [C]//Proceedings of ACM SIGGRAPH Conference.Los Angeles:ACM,2008:1-9.
[2]He K M,Sun J,Tang X O.Single image haze removal using dark channel prior [C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Florida:IEEE,2009:1956-1963.
[3]Levin A,Lischinski D,Weiss Y.A closed form solution to natural image matting [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2008,30 (2):228-242.
[4]Tarel J P,Hautiere N.Fast visibility restoration from a single color or gray level image [C]//Proceedings of IEEE International Conference on Computer Vision.Tokyo:IEEE,2009:2201-2208.
[5]Jone J,Wilscy M.Enhancement of weather degraded video sequences using wavelet fusion [C]//Proceedings of the 7th IEEE International Conference on Cybemetic Intelligent System.London,UK:IEEE Computer Society,2008:1-6.
[6]Xu Zhiyuan,Liu Xiaoming,Chen Xiaonan.Fog removal from video sequences using contrast limited adaptive histogram equalization [C]//Proceedings of International Conference on Computational Intelligence and Software Engineering.Wuhan,China:IEEE Computer Society,2009:1-4.
[7]Christophe Clienti,Michel Bilodeau,Serge Beucher.An efficient hardware architecture without line memories for morphological image processing [G].Lecture Notes in Computer Science 5259:10th International Conference on Advanced Concepts for Intelligent Vision Systems,2008:147-156.
[8]He Kaiming,Sun jian,Tang Xiaoou.Guided image filtering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012 (99):1-14.
[9]GUO Fan,CAI Zixing,XIE Bin.Video defogging algorithm based on fog theory [J].ACTA Electronica Sinica,2011,39(9):2019-2025 (in Chinese).[郭璠,蔡自兴,谢斌.基于雾气理论的视频去雾算法 [J].电子学报,2011,39 (9):2019-2025.]
[10]ZHANG Jianfei.Detection and tracking of moving object in traffic video based on OpenCV [J].Electronic Test,2012(1):50-53 (in Chinese).[张建飞.基于 OpenCV 的交通视频运动目标检测与跟踪 [J].电子测试,2012(1):50-53.]
[11]XU Fangming,LU Guanming.Moving object detection based on ameliorative surendra background update arithmetic [J].Shanxi Electronic Technology,2009 (5):39-40 (in Chinese).[徐方明,卢官明.基于改进surendra背景更新算法的运动目标检测算法 [J].山西电子技术,2009 (5):39-40.]
[12]LIANG Liang.CUDA based moving object detection [D].Beijing:Beijing Jiaotong University,2012:16-30 (in Chinese).[梁良.基于CUDA加速的运动目标检测 [D].北京:北京交通大学,2012:16-30.]
猜你喜欢
武汉工程大学学报(2022年2期)2022-05-05
成都信息工程大学学报(2019年3期)2019-09-25
测控技术(2019年4期)2019-09-20
中国眼镜科技杂志(2018年13期)2018-08-11
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年4期)2016-11-07
诗潮(2016年5期)2016-05-14
现代计算机(2016年17期)2016-02-28
探测与控制学报(2015年4期)2015-12-15
中国火炬(2015年11期)2015-07-31
