
多数据源冲突的主数据真值发现算法
2014-11-30 07:48王继奎李少波
计算机工程与设计 2014年1期
王继奎,李少波
(1.中国科学院 成都计算机应用研究所,四川 成都610041;2.贵州大学 现代制造技术教育部重点实验室,贵州 贵阳550003;3.兰州商学院 信息工程学院,甘肃 兰州730020)
0 引 言
数据冲突问题在数据处理领域中早就被提了出来[1],文献 [2-4]在解决数据冲突问题时,往往假设数据源都是独立的,相互之间没有关联。2007年Yin[5]等人首次提出了web环境下多数据源存在依赖的情况下冲突的问题,提出了数据值支持度的概念,就客观实体的单个属性如作者姓名的真值发现进行研究,提出了TruthFinder算法,该算法考虑了不同属性值之间的相互支持关系,通过不同数据值之间的支持度及数据源的准确度修正数据值的可信度,通过数据值的可信度重新计算数据源的准确度,进行迭代计算,设置数据源可信度变化阈值作为算法终止条件。2009年Dong[6,7]等人对数据源存在拷贝的进行了研究,并提出了考虑数据源存在拷贝的情况下数据源及数据值可信度的计算方法。文献 [8]考虑了动态数据的真值发现。2010年考明军[9]等人提出了数据源权威性的概念,采用不同的概率投票方法,将数据源的可信性和数据值的准确性之间的关系运用在投票的思想中,同时考虑不同数据值之间的影响。2012年张志强[10]等人在提出了NEWACCU算法,主要是采用的数据源的准权威度与数据值的投票率的均值作为数据源的可信度参与计算,并对数据值的不同表现形式进行了处理。
主数据集成的过程中经常会出现同一客观实体有不同描述的情况,应该综合考虑这些描述,并通过一定的算法生成最可信记录。目前的冲突数据解决算法关于数据值支持度的计算通常采用字符串相似度算法,由于数据值支持度的计算对整个真值发现算法的有效性有关键影响,数据值支持度的计算方法的改进会导致真值发现算法的改进。从主数据集成的业务角度出发,提出了一种非对称的数据值支持度算法,较好的解决了主数据冲突中常出现的简写、少写、位置调换、错误书写等问题;提出了TRFinder迭代算法,该算法考虑了数据源的可信度和冲突数据值非对称支持度;在TRFinder算法的基础上给出了主数据生成的算法。最后通过文献 [9]使用的books_authors数据集及模拟数据集对Vote算法、TruthFinder算法与TRFinder算法进行了对比实验,结果表明TRFinder算法可以发现更多的客观对象的真值;即使不是真值也保留了更多地真值信息;算法的准确度由Vote算法的42%、Truth-Finder算法的71%,提升到了81%,验证了算法的有效性。
1 TRFinder算法
1.1 主数据集成模型
主数据集成一般分为数据模式匹配、重复记录检测、主数据生成3个阶段。
(1)主数据管理系统与业务系统进行模式匹配,为数据抽取提供字段映射机制;
(2)检测组件在数据加载的过程中进行重复主数据检测;
(3)若存在重复主数据,根据主数据真值发现算法生成主数据。
主数据集成模型如图1所示。
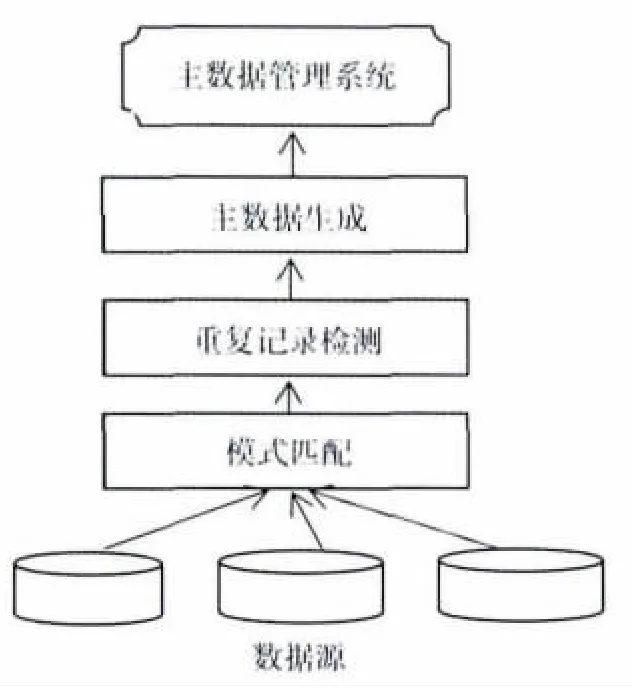
图1 主数据集成模型
1.2 规 则
1.2.1 符号及含义
符号、缩写及意义见表1。

表1 符号、缩写及意义
1.2.2 假设
假设4:t(s)=g(f),f∈F(s)。假设1表明客观实体属性真值唯一;假设2表明真值来源于数据源;假设3说明不同数据源提供的错误值不一样;假设4说明数据源的准确度取决于其提供的数据值的可信度。
1.3 imp (fi->fj)的计算
目前的真值发现算法均是基于投票的思想,后来的算法考虑了数据源准确度、数据源可能存在拷贝关系、不同数据值的相似度的因素改进了朴素的投票算法,取得了显著的成果。
数据值的可信度取决于提供数据值的数据源的准确度、其它数据值对其的支持度。文献 [5,6]把所有类型看作字符串,采取了对称的相似度计算Simth-Waterman算法[11],以相似度代替支持度;本文采取非对称的算法计算字符串的支持度,并针对不同的数据类型设置了不同的阈值。
(1)数值日期型
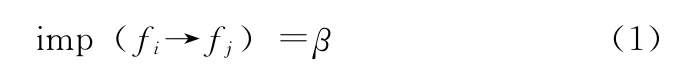
式中:β∈{0,1},对于数值做以下处理,若两个数值相等,则支持度为1,否则为0。这种情况下数据值可信度的计算是对称的。
对于日期型的计算首先要统一数据格式。目前日期型的数据是最容易出现不同数据格式的。
(2)字符串型:β取值为字符串相似的阈值。其它的数据类型统一处理成字符串型进行处理。通过分析目前不同数据值多是因为缩写、少写、或者错写造成的。目前算法使用的字符串相似度计算函数为传统的非恒定相似度系数评价方法 (Jaccard系数)即
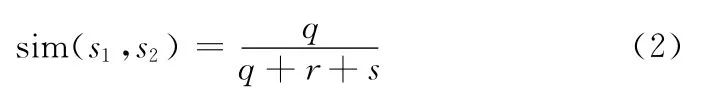
式中:q——两个字符串共有的单词数,r——字s2种存在,s1中不存在的单词数,s标识字符串s1存在,s2中不存在的单词数。但是在现实中 (中国,中华人民共和国)是相同的概念,如果将每个字符看作一个词,计算的结果将是2/(2+5)=28.6%,显然与其实际的相似度相差甚远;又如 (广东省经纬网络科技有限公司,山东省经纬网络科技有限公司)完全是不同的实体,但是通过计算相似度为12/(12+1+1)=85.7%,与实际情况也相去甚远。文献[11]专门针对中文提出了一种新的计算公式
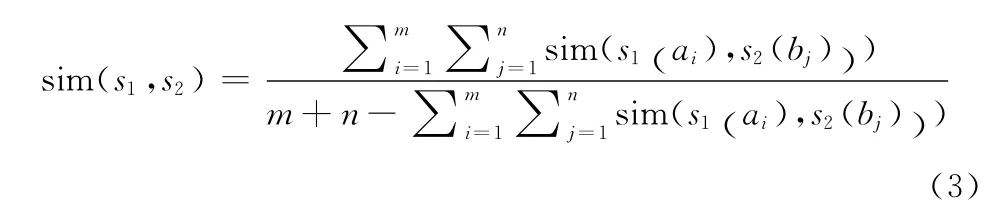
这个公式与英文计算方法是完全相同的,令
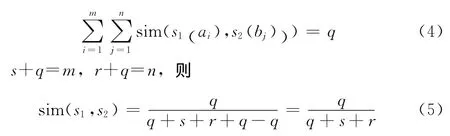
所以文献 [11]提出的中文计算方法与英文计算方法是一样的。实践中发现相似数据主要由简写、少写、错误拼写造成的,针对这3种情况,提出了一种非对称的支持度算法
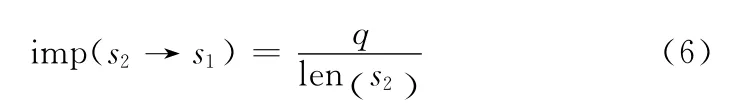
比如供货范围s1= “软件、硬件”,s2= “软件”,则imp(s2→s1)=1,而imp (s1→s2)=0.5,所以支持度的计算是非对称的。该算法比较好的解决了少写、简写、错误拼写的问题。若采用文献 [9]采用的算法,imp (s2→s1)=imp (s1→s2)=2/(5+2-2)=0.4。从直观上来看s1更加可信。
算法1:计算义原词的相似度。
使用前首先对两个字符串按照一定的规则进行分词,然后排序,将每个分词看作一个义原词。
输入:待比较的两个义原词a1,a2
输出:相似度比较结果
f1Array,f2Array为a1,a2的字符串数组;k与m为指向f1Array,f2Array的指针,初始值为0,count统计字符相同的结果,初始值位0。
(1)char[]f1Array=a1.toCharArray();
(2)char[]f1Array=a2.toCharArray();
(3)int k=0;
(4)int m=0;
(5)int count=0;
(6)while(k<f1Array.length){
(7)int l=m;
(8)while(l<f2Array.length){
(9)if(f1Array [k]==f2Array [l]){
(10)m++;
(11)count++;
(12)break;
(13)}else{
(14)l++;
(15)}}
(16)k++;
(17)}
return(double)count/f2Array.length;
算法分析:将a1转化为字符数组,每个字符即为s1的义原词,将a2转化为字符数组,扫描一遍两个数组,统计相同字符的个数。设:a1对应的数组长度为m,a2,对应的数组长度为n,最好情况需比较min(m,n),最坏情况需要比较 max(m,n)。
算法2:非对称支持度算法
输入:数据值s1,s2
输出:s2对s1的支持度
(1)将字符串s1,s2进行分词,构成义原词集合w1,w2。采用算法1进行义原词相似度计算。
(2)采用非恒定相似度系数评价方法计算式 (6)的q。
(3)采用式 (6)计算imp(s2→s1)。
1.4 算法模型
由于主数据来源的业务系统数据是独立的业务系统,不存在业务系统之间相互拷贝的情况;在进入主数据系统这一刻的业务数据应该各业务系统的最可信数据,这一点由各提供数据的业务系统保证,所以不考虑数据的动态特性。算法模型主要关注不同数据值之间的支持度、数据源的准确度及主数据 (golden record)的生成。attr表示主数据属性数组,t为数据源准确度矩阵,imp为属性值相似度矩阵,j表示当前计算的为第j个属性,α为数据源可信度变化阈值。
TRFinder模型如图2所示。
1.5 TRFinder算法
1.5.1 算法3:支持度矩阵imp的算法
算法依据为文献 [5]式 (6)、式 (11)
输入:给定属性的数据值数组values,数据源可信度数组c,可信度调节参数r
输出:支持度矩阵imp
(1)double [][]imp=new double [values.length][values.length];
(2)for (int i=0;i<values.length;i++)
(3){
(4)for (int j=0;j<values.length;j++)
(5){
(6)ret[i][j]=FieldImpValue (values [i],values[j])*c [i]*r;
(7)}}
(8)return imp;
1.5.2 算法4:数据可信值算法
输入:数据值矩阵A,支持度矩阵B,数据源可信度矩阵t,迭代次数times
输出:数据值可信度数组ds
参数:数据源可信度向量T,修正后的数据源可信度数组fixT,修正后的可信度值数组fixt
(1)for(int j=0;j<t.length;j++){
(2)T [j]=-java.lang.Math.log (1-t [j]);}
(3)int count=0;
(4)while(count<times){
(5)fixT=calMatrix (B,T);
(6)for(int k=0;k<fixT.length;k++){
(7)ds [k]=1-java.lang.Math.exp (-fixT [k]);
(8)ds [k] =1/ (1+java.lang.Math.exp (-ds[k]));}
(9)preT=t;
(10)t=calMatrix (A,ds);
(11)for(int j=0;j<t.length;j++){
(12)T [j]=-java.lang.Math.log (1-t [j]);}
(13)count++;}
(14)return ds;
1.5.3 算法5:TRFinder算法
输入:数据值数组FValues[][],数组的列数i代表属性个数,数组的行数j代表数据源数量
输出:可信记录数组tRecord[]
(1)for(int k=0;k<j;k++)
(2)利用算法3计算k属性的可信度值数组可信度值最大的数据值添加到tRecord
(3)输出可信记录tRecord
2 实验验证
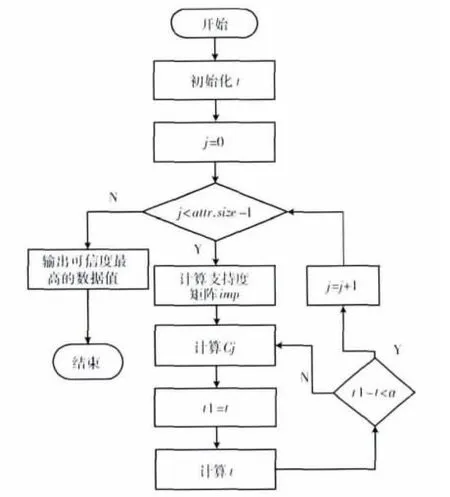
图2 TRFinder模型
2.1 初始化参数对算法的影响
提供基建系统s1、物资系统s2、营销系统s3这3个数据源的一条重复供货范围数据:
f(s1)= {计算机软件系统开发及应用服务;计算机网络工程、系统信息安全服务;计算机及智能综合布线、技术咨询;电子电器设备、计算机及其配件、消耗品、软件产品销售}。
f(s2)= {计算机及智能综合布线、技术咨询;电子电器设备、计算机及其配件、消耗品、软件产品销售}。
f(s3)= {电子电器设备、计算机及其配件、消耗品、软件产品销售}。
初始化参数令t(s1)=t(s2)=t(s3)=r,修正系数设置为0.3,迭代次数设置为10次。
r与ρ对数据源可信度的影响见表2。
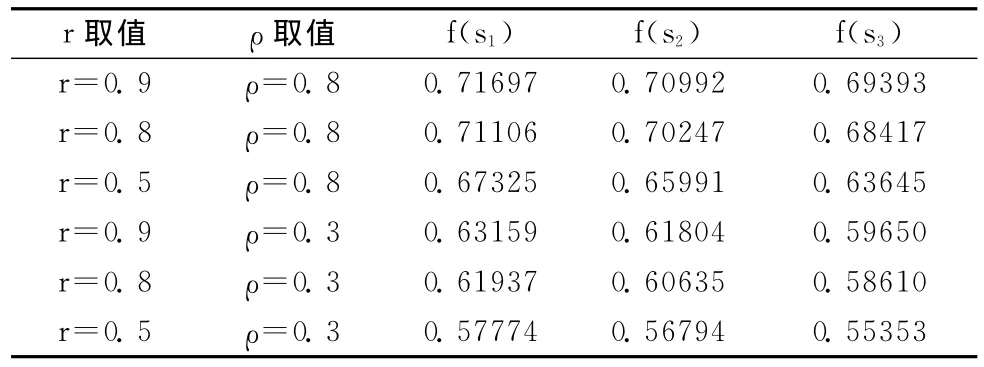
表2 r与ρ对数据源可信度的影响
从以上结果可以看出不同的初始值对可信度记录的生成没有影响,体现了算法具有很强的鲁棒性。
2.2 迭代收敛的情况
r=0.9,ρ=0.8,迭代次数为8次,其余条件采用2.1的。
迭代次数对数据源准确度的影响见表3。
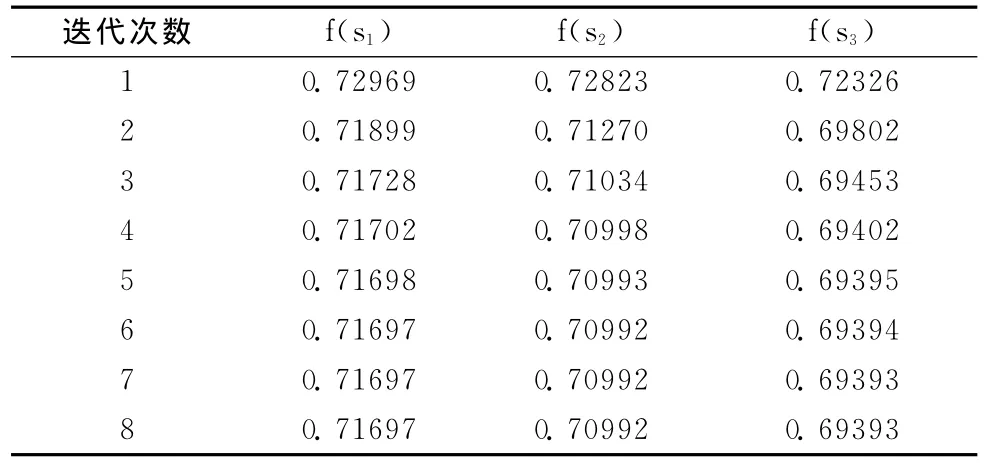
表3 迭代次数对数据源准确度的影响
表3显示算法收敛的很快,在第8次迭代,精确到10-5方的情况下s1,s2,s3的可信度变化情况为0,小于10-5,算法终止。在仅仅提供一个值的情况下,数据源的可信度及为数据值的可信度,最可信的数据应该为s1提供的数据即 “计算机软件系统开发及应用服务;计算机网络工程、系统信息安全服务;计算机及智能综合布线、技术咨询;电子电器设备、计算机及其配件、消耗品、软件产品销售”,从直观上看,这个数据比另两数据更加全面,也携带了更多的信息。通过这个例子也展示了文中提出的不对称支持度计算方法的优越性。
2.3 与其他算法比较
TRFinder主要是针对主数据管理系统的需求思考产生的,TRFinder算法与TrustFinder及NEWACCU等算法的不同之处主要体现在两点:
(1)字符串支持度计算上,实现上TRFinder采用了非对称的支持度计算算法。
(2)针对不同的数据类型提供了不同的支持度算法。
2.3.1 不同字符串支持度算法对结果影响
主要比较TrustFinder、ACCU、NEWACCU算法所使用的编辑距离的对称算法与本文使用的基于统计与位置的改进PCM算法。
对于书籍 《web数据挖掘》,通过百度搜索,从不同的网站获取作者信息如下,数据源初始准确度均为0.8,可信度调节参数设为0.9。web世界的数据见表4。
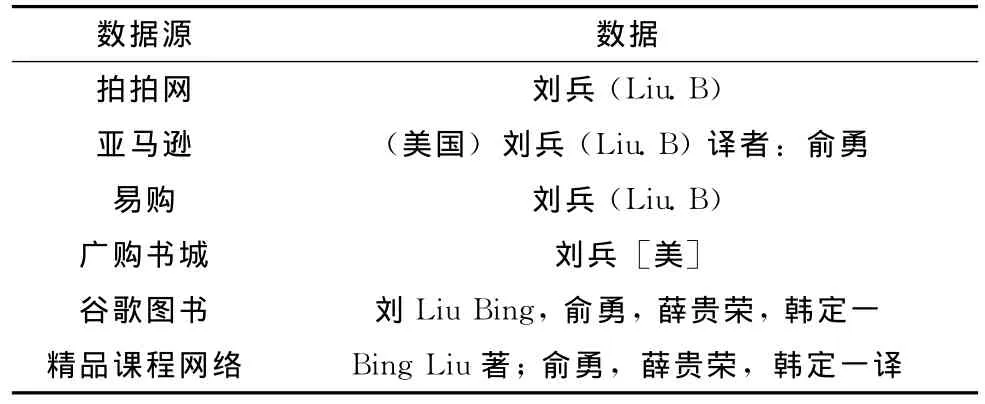
表4 web世界的数据
不同算法准确度对比见表5。
开始运行时,每个数据源只提供一个数据,所以数据值的可信度与数据源的可信度是一致的。程序运行结果显示TrustFinder选择 {刘兵 (Liu.B)}作为可信数据,而TRFinder算法选择了 {(美国)刘兵 (Liu.B)译者:俞勇}作为可信数据,而通过查看原书的封面发现 {Bing Liu著 ;俞勇,薛贵荣,韩定一译}才是真值,尽管如此,直观的来看TRFinder选择的真值依然比TrustFinder算法信息更加全面,更加可信。为验证缩写、少写,及位置调换对算法的影响,用以下模拟数据进行实验。模拟数据见表6。
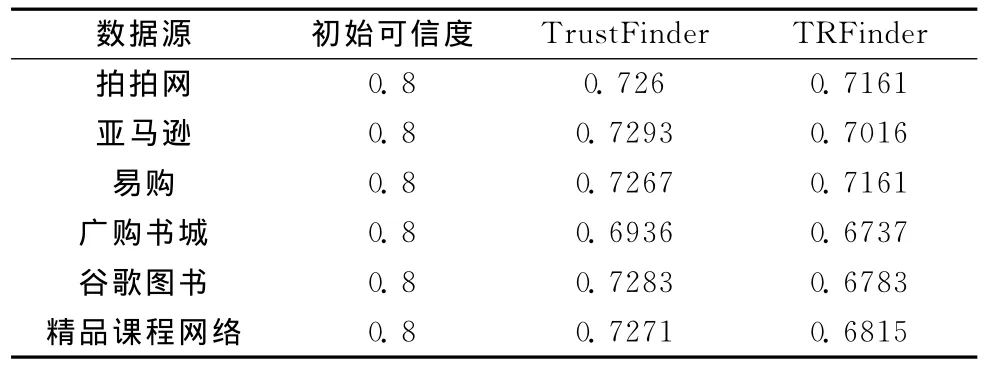
表5 不同算法准确度对比
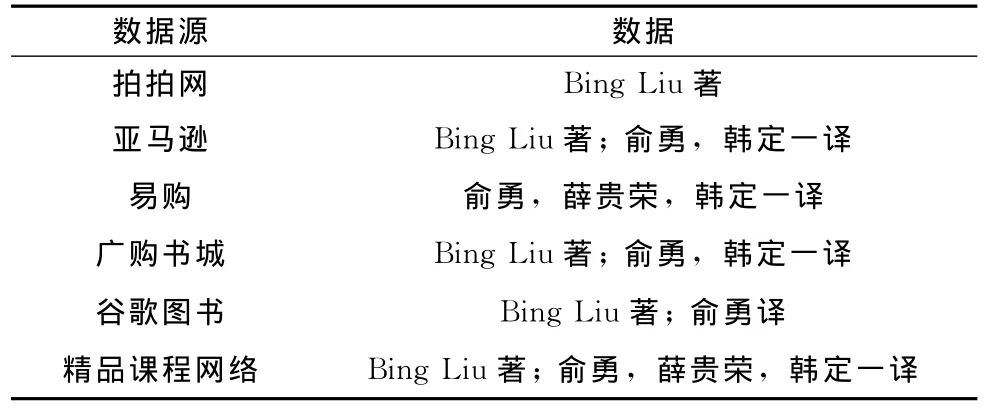
表6 模拟数据
运算结果显示:TrustFinder算法选择了 {Bing Liu著;俞勇,韩定一译}做为可信数据,而TRFinder算法选择了{Bing Liu著;俞勇,薛贵荣,韩定一译}做为真值,实验验证了TRFinder算法比TrustFinder等算法使用的对称算法更容易发现真值。也保留了更多地真值信息。
2.3.2 算法准确率比较
为了使实验结果具有可比性,算法准确性验证采取与原实验相同的books_authors数据集 (特别感谢哈工大张志强教授提供的验证数据集)。设置数据源初始可信度为0.8,相似度支持因子为0.7。
books_authors数据集上的部分实验结果见表7。

表7 books_authors数据集上的部分实验结果
通过查看书籍的封面,确定真值为:{{o'leary,timothy j.; o'leary,linda i.};{yacht,carol; crosson,susan};{haag,stephen; perry,james t.; sosinsky,barrie;estevez,efren};{scambray,joel; mcclure,stuart};{courage,catherine; baxter,Kathy}; {goldman,ron;gabriel,richard p.}; {makofske,david; almeroth,kevin}; {dann,wanda p.; cooper,stephen; pausch,randy};{geary,david; horstmann,cay};{shaffer,clifford a.};}
不同算法books_authors数据集上准确率对比见表8。

表8 不同算法books_authors数据集上准确率对比
对比以上数据可以发现,TRFinder算法的准确率比TruthFinder算法提高了10个百分点,比Vote算法提高了39个百分点。通过针对部分数据进行实际分析发现,不对称支持度算法使具有更多信息量的值留了下来。多数的网站只列出了部分作者,没有完全的作者信息,所以使用Vote算法选出的很多不是真值;而TruthFinder使用了基于编辑距离的字符串相似度算法替代支持度算法,计算的结果经常遗漏作者;而TRFinder算法考虑了支持度计算的非对称特性,计算的结果虽然也有与书籍封面不一致的数据,从选出的部分数据来看,没有遗漏任何作者信息,特别是针对经常出现的简写、少写及位置调换等常见现象真值发现的准确度更高。
3 结束语
针对主数据管理中出现的多业务系统数据冲突的问题,总结了目前典型的解决数据冲突的方法,结合主数据管理的业务需求及应用场景,提出了一种新的计算不同数据值支持度的非对称算法,较好的解决了目前主数据集成中常出现的简写、少写、位置调换、错误书写等问题,并提出了用于解决主数据生成的TRFinder算法。从实验效果上看,TRFinder比Vote算法及TrustFinder算法具有更高的准确率,较全面地保留了真值的信息。目前的实现算法中没有考虑数据的动态特性,拟进一步就数据的动态特性进行研究。
[1]Bleiholder J,Naumann F.Conflict handing strategies in an integrated information system [C]//Edinburgh,UK:Proceedings of the International Workshop on Information Integration on the Web,2006:36-41.
[2]Naumann F,Bilke A,Bleiholder J,et al.Data fusion in threesteps:Resolving schema,tuple,and value inconsistencies[J].IEEE Data Engineering Bulletin,2006,29 (2):21-31.
[3]Whang Steven Euijong,Menestrina David,Koutrika Georgiaet al.Entity resolution with iterative blocking [C]//Rhod.Rhode Island,USA:Proceedings of the 35th SIGMOD Internatational Conference on Management of Data,2009:219-231.
[4]Panse F,keulen M V,Keijzer A D,et al.Duplicate detection in probabilistic data [C]//LongBeach,CA:Proceedings of 26th International Confernece on Data Engineering Workshop,2010:179-182.
[5]Yin X,Han J,Yu P S.Truth discovery with multiple conicting information providers on the Web [J].IEEE Transactions on Knowledge and Engineering,2008,20 (6):796-808.
[6]Dong X L,Berti Equille L,Srivastava D.Integrating conflicting data:The role of source dependence[J].PVLDB,2009,2 (1):550-561.
[7]Dong X L,Naumann F.Data fusion resolving data conflicts for integration [J].PVLDB,2009,2 (2):1654-1655.
[8]Dong X L,Berti Equille L,Srivastava D.Truth discovery and copying detection in a dynamic world [J].PVLDB,2009,2(1):562-573.
[9]KAO Mingjun,ZHANG Wei,GAO Hong.Truth discovery methods in conflict data integration [J],Journal of Computer Research and Development,2010,47 (Suppl.):188-192 (in Chinese).[考明军,张炜,高宏.冲突数据中的真值发现算法 [J].计算机研究与发展,2010,47 (增刊):188-192.]
[10]ZHANG Zhiqiang,LIU Lixia,XIE Xiaoqin,et al.Information evaluation based on source dependence [J].Chinese Journal of Computers,2012,35 (11):2392-2402 (in Chinese).[张志强,刘丽霞,谢晓琴,等.基于数据源依赖关系的数据源信息评价方法研究 [J].计算机学报,2012,35 (11):2392-2402.]
[11]Nawaz Z,Al-Ars Z,Bertels K,et al.Accelerationa of simth-waterman using recursive variable expansion [C]//Parma,Italy:Proceedings of the 11th EUROMICRO Conference on Digital System Design Architectures,Methods and Tools,2008:915-922.
猜你喜欢
电脑报(2022年13期)2022-04-12
无线互联科技(2020年11期)2020-12-01
电脑报(2020年24期)2020-07-15
电子制作(2017年1期)2017-05-17
林业调查规划(2017年6期)2017-03-27
智能系统学报(2015年5期)2015-12-03
轴承(2015年3期)2015-07-25
初中生之友·中旬刊(2015年4期)2015-06-10
浙江大学学报(工学版)(2015年2期)2015-05-30
燕山大学学报(2014年1期)2014-03-11
