
无线射频识别多标签防碰撞算法综述
2014-11-28 08:11刘金艳冯全源
计算机集成制造系统 2014年2期
刘金艳,冯全源
(西南交通大学 信息科学与技术学院,四川 成都 610031)
0 引言
无线射频识别(Radio Frequency IDentification,RFID)是一种非接触式自动识别技术,它通过射频信号自动识别目标对象并获取相关数据,识别工作无需人工干预,可工作于各种恶劣环境,在物联网、供应链、物流等领域中有着广泛的应用[1]。典型的RFID 系统主要由阅读器、标签和后台计算机应用系统三部分组成,标签具有唯一的识别码(IDentification code,ID),被贴附到待识别的物体上。
在RFID 应用系统的一个阅读器的天线作用范围内,常常同时存在多个标签,当阅读器发出查询命令后,往往会引起多个标签同时响应,这些响应信息在共享的无线信道上发生碰撞,使响应信号难以被阅读器辨认,从而引起多标签碰撞。阅读器为完成对所有标签的识别,应将这些发生碰撞的标签区分开来,再与它们逐个通信,阅读器完成这些工作所使用的算法就是多标签防碰撞算法[2-3]。
现有的多标签防碰撞算法主要分为三类[4]:①基于Aloha的算法,又称为随机性算法;②基于树的算法,又称为确定性算法;③混合算法,将基于Aloha的算法和基于树的算法相结合而产生的一种算法。
1 基于Aloha的防碰撞算法
基于Aloha的防碰撞算法的基本思想是:在阅读器发现多标签碰撞时,阅读器命令其作用范围内的所有标签随机延迟一段时间再进行响应,延迟时间的长度是以某种概率随机选择的。
1.1 基本的Aloha算法
早期的Aloha算法为纯Aloha算法,该算法采用“标签先发言”的方式,即标签一进入阅读器的作用区域就自动向阅读器发送其自身的信息,对同一个标签来说,其发送数据的时间是随机的。在标签发送信息的过程中,如果有其他标签也在发送数据,就会发生信号重叠,导致部分碰撞或者完全碰撞。阅读器检测信号并进行判断,一旦发现碰撞,阅读器将发送命令让标签停止发送数据,所有标签会随机延迟一段时间再发送数据,由于延迟的随机时间不同,再次发生碰撞的概率将明显降低。如果没有碰撞,则阅读器发送一个应答信号给标签,标签从此转入休眠状态。这种算法简单,但吞吐率低,最大吞吐率仅能达到18.4%[5]。
该算法效率低的主要原因是碰撞发生的时间是随机的,其中包括:当一个标签在与阅读器通信的过程中,有可能因其他标签的突然响应而被破坏,即存在部分碰撞问题。为此,人们提出时隙Aloha算法(Slotted Aloha,SA)[5],把时间分成多个离散时隙,标签只在每个时隙的开始时刻才能发送数据。算法的基本原理是:阅读器通过发送命令通知标签有多少时隙,标签随机选择发送信息的时隙。如果某个时隙只有一个标签响应,则阅读器可正确地识别标签;如果某个时隙有多个标签响应,则会发生碰撞,阅读器通知标签,标签便在下一轮循环中重新随机选择发送的时隙,直到所有的标签都被识别出来。
在SA 算法中,标签或成功识别或完全碰撞,避免了纯Aloha算法中出现的部分碰撞问题。SA 算法的最大吞吐率可达36.8%[5]。
1.2 FSA与DFSA
对于SA 算法,在发生碰撞时,标签延迟的随机性范围很大,影响了其平均响应速度。为此,规定若干个时隙为一帧,标签选择的随机延迟必须是帧内的某个时隙,这就是帧时隙Aloha(Framed Slotted Aloha,FSA)算法。
FSA 算法的缺点是帧长固定,这样当标签数量较少时,存在时隙浪费,而当标签数较多时,碰撞解决的效果又不是很好。因此,可以考虑根据标签数量动态地调整帧长,即动态帧时隙Aloha(Dynamic Framed Slotted Aloha,DFSA)算法[6-7]。
研究结果表明,最优的帧长应该等于标签数量[7],因此只要知道了标签数量,就可以确定帧长,然而当前帧需识别的标签数量通常无法预知,只能对其进行估算。因此在DFSA 算法中,非常重要的一项工作就是标签数量的估计,大多数方法都是根据上一帧的帧长、标签个数、冲突情况来估计当前帧中的标签数。典型方法包括:
(1)Vogt方法[8]设碰撞时隙数为Ck,碰撞时隙内至少有2 个以上的标签存在,则可以预测发生碰撞的标签数量至少为2×Ck。
(2)标签估计方法Ⅰ(Tag Estimation MethodⅠ,TEM Ⅰ)[7]将碰撞率Cratio定义为碰撞时隙数与帧长的比值,L 为帧长,n 为标签个数,则它们之间的关系为

由于上一帧的帧长L 和碰撞率Cratio已知,可以计算出标签个数n。
(3)TEMⅡ方法[7]设nest为估算的标签数量,Mcoll为上一帧中的碰撞时隙数,则

1.3 FSA的各种改进算法
在固定帧长的Aloha算法中,当标签数量太多时,冲突时隙较多;而当标签数量太少时,又会有大量的空闲时隙。基于这一点,各种改进算法被提出。
1.3.1 分群时隙Aloha算法
分群时隙Aloha算法[9]根据碰撞时隙在所分配时隙中所占的比例,来确定是否分群。如果碰撞时隙的比例(发生碰撞的时隙数/分配的时隙数)大于分群因子γ,则进行分群。分群后,第一个分群内的标签响应阅读器的查询命令,另一个分群内的标签处于等待状态。当第一个分群内的所有标签识别完毕后,第二个分群内的标签再进行响应,直至所有标签识别完毕。
仿真结果表明,分群时隙Aloha算法优于固定时隙Aloha算法,且随着标签数量的增加,算法的优越性更明显。同时,分群因子的选择是影响算法的关键因素,在标签数量较多时,分群因子宜选择较小值。
1.3.2 自适应的动态帧时隙Aloha算法
文献[10]考虑某些应用场合中阅读器需要对标签进行重复识别的要求,充分利用上一帧已识别标签的信息,提出自适应的动态帧时隙Aloha算法,该算法每成功识别一个标签就给标签分配一个时隙号,该时隙号规定了标签被阅读器识别的顺序。如果在下次识别过程中阅读器要重复识别这些标签,则可根据已分配的时隙号按顺序进行,从而避免标签间的冲突,减少识别时间。当离去标签和新到达标签数量较少时,系统效率较高,但是当有大量的新到达标签时,仅采用上述方法将导致冲突急剧增加。为减少冲突,阅读器应估计标签数,并根据标签数合理调整帧长。文献[10]提出了一种最优帧长方案,使系统获得了较大的吞吐量。
1.4 Q 值算法及其改进算法
DFSA 算法可采用各种方法预测待识别的标签数量,然后动态调整最优帧长,与FSA 相比,系统效率有明显改善,接近36.8%。但是,当标签数量较多(特别是标签数量大于500)时,采用由预测标签数量设置最优帧长的方案会使系统效率急剧下降[11]。因此,在标签数量较多的情况下,为了使系统效率得到提高,EPC Class1Gen 2标准[12]中采用了Q 值算法,该算法可以实时自适应地调整帧长。
1.4.1 Q 值算法
在Q 值算法中,阅读器首先发送Query命令,该命令中含有一个参数Q(取值范围0~15),接收到命令的标签可在[0,2Q-1]范围内(称为帧长)随机选择时隙,并将选择的值存入标签的时隙计数器中,只有计数器为0的标签才能响应,其余标签保持沉默状态。当标签接收到阅读器发送的QueryRep命令时,将其时隙计数器减1,若减为0,则给阅读器发送一个应答信号。标签被成功识别后,退出这轮盘存。当有两个以上标签的计数器都为0时,它们会同时对阅读器进行应答,造成碰撞。阅读器检测到碰撞后,发出指令将产生碰撞的标签时隙计数器设为最大值(2Q-1),继续留在这一轮盘存周期中,系统继续盘存直到所有标签都被查询过,然后阅读器发送重置命令,使碰撞过的标签生成新的随机数。
根据上一轮识别的情况,阅读器发送Query-Adjust命令来调整Q 的值,当标签接收到Query-Adjust命令时,先更新Q 值,然后在[0,2Q-1]范围内选择随机值。
EPC Class1Gen 2标准[12]中提供了一种参考算法来确定Q 值的范围,如图1所示。其中:Qfp为浮点数,其初值一般设为4.0,对Qfp四舍五入取整后得到的值即为Q;C 为调整步长,其典型取值范围是0.1<C <0.5,通常当Q 值较大时,C 取较小的值,而当Q 值较小时,C 取较大的值。

当阅读器发送Query命令进行查询时,若应答标签数等于1,则Q 值不变;若应答标签数等于0(空闲时隙),则减小Q 值;若应答标签数大于1(冲突时隙),则增大Q 值。
该算法在参数C 的辅助下对Q 值进行动态调整,但是C 太大会造成Q 值变化过于频繁,导致帧长调整过于频繁,C 太小又不能快速地实现最优帧长的选择。因此,研究者们对Q 值的调整进行了各种优化。
1.4.2 基于最大吞吐量调整Q 值的算法
文献[13]提出一种基于最大吞吐量对Q 值进行调整的算法,其中定义了以下变量:
Nt为已识别的标签个数;
N 为识别标签所需的总时隙数;
NC为冲突时隙的个数;
nu为上一轮未识别的标签个数;
e为冲突时隙中的平均标签个数;
PC为冲突时隙所占的比例。
这些参数之间的关系为PC=NC/N,e=nu/Nc,吞吐量=Nt/N。
由于Aloha 类算法的最大吞吐量为0.368(e-1)[5],该算法以此作为调整Q 值的依据。当系统吞吐量达到或接近0.368时,阅读器仅需调用2Q-1次QueryRep 命令,而不需要在接下来的盘存周期中调整Q 值。当吞吐量小于0.368时,根据未识别的标签个数nu来调整Q 值,具体方法如下:
(1)统计上一个盘存周期中的冲突时隙个数NC和总时隙数N,并计算出PC。
(2)根据e和PC的关系(式(3))[14]计算出e,

从而计算出nu=e×NC。
(3)根据“最优帧长等于待识别的标签个数”,可知2Q-1=nu,由此得出Q=[log2(nu+1)]。
该算法减少了对Q 值的调整次数,避免了标签频繁地在[0,2Q-1]范围内选择随机值,减少了标签的能量消耗。该算法的吞吐量基本可以达到最大值0.368,且识别标签所需的总时隙数和吞吐量均优于原Q 值算法。
1.4.3 基于分组的位隙Aloha算法
文献[15]提出一种基于分组的位隙Aloha算法,该算法采用位隙Aloha算法中的128位预定序列,代表128个位隙。若某个标签选择了第i个位隙,则将第i位置1,其余各位都置0。当标签数量为15 时,位隙Aloha 算法可获得最大吞吐率88.38%[15],但随着标签数量的增加,算法性能急剧下降。
因此,基于分组的位隙Aloha算法通过对标签进行分组来提高算法的性能。该算法在查询命令中设置了一个位隙计数器的参数Q(Q 为整数,且0≤Q≤15)[12],当标签收到阅读器发送的查询命令后,在[0,2Q-1]范围内生成一个随机数,即代表选择了相应的位隙,只有选择了0的标签才会立即响应。同时,该算法根据冲突位隙数动态地对Q 值进行调整:当冲突位隙数小于11时,Q 减1且最小为0;当冲突位隙数在11~20之间时,Q 保持不变;当冲突位隙数大于20时,Q 加1且最大不超过15。
综上所述,基于Aloha 的防碰撞算法原理简单、容易实现,对新到达的标签具有较好的适应性,尤其对于标签持续到达的情况有较好的解决方案[16],但该类算法存在几个明显的缺点:①响应时间不确定,即同一批标签在不同时刻进行识别所需要消耗的时间相差很大;②个别标签可能永远无法被识别;③Aloha算法达到最佳吞吐率的条件是其帧长等于标签数量,当需要识别的标签数量较多或选择的帧长与实际待识别标签数量不符时,系统性能将明显下降。而基于树的算法则很好地解决了这些问题。
2 基于树的防碰撞算法
基于树的防碰撞算法又可进一步分为树分裂(Tree Splitting,TS)算法和查询树(Query Tree,QT)算法两类。
2.1 树分裂算法及其改进算法
在TS算法中,将发生冲突的标签分成两个子集,第一个子集的标签在下一个时隙响应,若其内部又发生冲突,则再次进行分裂,如此递归地进行分裂操作,直到子集中只有1个标签为止,此时标签即可被唯一识别。待第一个子集的冲突全部解决后,再对第二个子集执行类似操作[3]。该算法要求标签具有随机数生成器,当发生冲突时,标签随机地生成二进制数0或1,从而将标签分成两个子集。
2.1.1 基本的树分裂算法
在TS算法中,最基本的是Hush[17]提出的基本树分裂(Basic Tree Splitting,BTS)算法。阅读器首先与其作用范围内的所有标签通信,标签对阅读器的查询作出响应,显然在当前时隙会产生冲突。每个冲突的标签都会生成一个二进制随机数0 或1,因此可以将冲突的标签集合分成两个子集L(生成的随机数为0的标签)和R(生成的随机数为1的标签),在下一个时隙,子集L 中的标签传输数据。如果子集L 中仍然存在冲突,则其中的标签又会生成一个随机数,对子集L 进行再次分裂。如此循环操作,直至子集中只有1个标签。
该算法实现简单,但由于冲突和空闲时隙较多,识别标签所需的总时隙数较多。
2.1.2 自适应二进制分裂算法
Myung等[18-19]提出一种自适应二进制分裂(Adaptive Binary Splitting,ABS)算法,该算法设置了两种时隙计数器:①进展时隙计数器PC,表示阅读器已经识别的标签数,其初始值为0;②分配时隙计数器AC(i),表示标签ti传送数据的时隙,即当PC=AC(i)时,允许标签ti在当前时隙发送数据。具有相同AC值的标签形成了一个集合,若一个集合中包含了多个标签,就会产生标签冲突。
根据阅读器反馈信息的不同,标签的识别过程如下:
(1)若成功读取一个标签,则PC加1。
(2)若为空闲时隙,则AC(i)减1。
(3)若为冲突时隙,则产生冲突的标签的AC(i)=PC,为将其分成两个子集,标签ti生成一个随机的二进制数并将它加到AC(i)上。因为PC不变,所以生成的随机数为0的标签构成第1个子集,它在下一个时隙重新发送数据;生成的随机数为1的标签构成第2个子集,它在第1个子集被识别后再发送数据。处于等待状态(即AC(i)>PC)的标签的AC(i)都加1。
识别过程结束后,所有标签都具有唯一的AC值。
为了在识别出所有标签后能立即终止识别过程,将阅读器看成是具有最大分配时隙数的一个标签,用RC(r)表示阅读器r的分配时隙数。当PC=RC(r)时,阅读器r认为所有标签已识别完毕,结束识别过程。
ABS算法比BTS算法有效地降低了冲突和空闲时隙数,因此效率有所提高。但是ABS算法对标签集合进行分裂时主要依靠标签产生的二进制随机数,并不能保证产生随机数0和1的概率总是等于50%(尤其当二进制序列较短时,如001,000,其中0和1出现的概率都不是50%),因此ABS算法不能获得最好的分裂结果。
2.1.3 增强型防碰撞算法
文献[20]对ABS算法进行了改进,提出增强型防碰撞算法(Enhanced Anti-collision Algorithm,EAA),该算法采用曼彻斯特编码,可以准确地判断产生冲突的位,因此当有冲突发生时,阅读器只接收到第2个冲突位,之后的数据不再接收。
EAA 算法仍然采用ABS算法中提出的PC和AC,并将时隙划分为:
(1)可读时隙 只有一个标签响应。
(2)冲突时隙 有多个标签的AC(i)=PC,且产生冲突的位大于等于2位。
(3)只有1位冲突的时隙(One Bit Collided Timeslot,OBCT)有多个标签的AC(i)=PC,并且产生冲突的只有1位。
对于OBCT,根据二进制数非0即1的特性,可以一次识别2个标签,从而大大提高算法性能。该算法不仅减少了识别标签所需的时隙数量,而且减少了时隙长度。
在文献[20]的基础上,文献[21]做了进一步改进,其主要内容为:①根据产生冲突的最高位是0还是1,决定对AC(i)加0还是1,从而对标签集合进行分裂,避免了ABS算法中根据随机产生的二进制数对标签集合进行分裂所产生的缺点(如所有标签产生的随机数都为1,将导致下一个时隙为空闲时隙);②利用栈和Tstring存放阅读器已接收到的响应信息。改进后的算法识别N 个标签所需的总时隙数为2 N-1-2k(k为OBCT 的个数)。
2.1.4 新增强型防碰撞算法
由于EAA 算法在一个时隙中最多只能识别2个标签,针对这一缺点,文献[22]做了进一步改进,提出新型增强型防碰撞算法(New Enhanced Anticollision Algorithm,NEAA),其主要思想如下:
(1)根据标签ID 中含1的位数,将标签分成n+1个子集set_i(0≤i≤n,n为标签ID 的长度),子集set_i中每个标签的ID 都有i个数位为1。例如,0000,0001,1111分别属于子集set_0,set_1和set_4。阅读器依次识别每个子集中的标签。
(2)在一个时隙中识别多个标签。子集set_1(或set_(n-1))中的标签的ID 只有一位为1(或为0),假设set_1 中有3 个标签,其ID 分别为0001,0010,1000,当3个标签同时响应时,阅读器接收到的响应为X0XX(X 表示产生了冲突的位),因为标签的ID 中只有一位为1,所以阅读器可以很容易地确定接收到的X0XX 是由3个标签产生的,只需依次将三个X 置1,就可以分别得到3个标签的ID,从而可以在一个时隙识别3个标签。
(3)仍然采用ABS算法中提出的PC和AC(i),并将时隙分为四种类型:
1)可读 只有1个标签的AC(i)=PC。
2)有多个标签可读 有多个标签的AC(i)=PC,并且这些标签属于集合set_1或set_(n-1)。
3)冲突 有多个标签的AC(i)=PC,并且这些标签不属于集合set_1或set_(n-1)。
4)空闲 没有标签的AC(i)=PC。
NEAA 算法可以在一个时隙中识别多个标签,从而减少了识别标签所需的时隙数量。另一方面,NEAA 算法也减少了标签与阅读器的信息传输量,从而减少了时隙的长度。
2.1.5 二进制矩阵搜索算法
文献[23]提出二进制矩阵搜索算法,该算法保持了后退式二进制树形搜索算法[24]的后退机理,当有碰撞发生时,根据碰撞的最高位跳跃式向前搜索;无碰撞时,采取后退策略实现标签的有序读取。与后退式二进制树形搜索算法相比,该算法主要在以下方面进行了改进:
(1)因为后退式二进制树形搜索算法发送的指令中,冲突位之后的低位部分全为1并没有任何实际意义,反而加大了阅读器和标签之间的通信量,所以本算法中的指令长度可以动态调整,只发送位数高于或等于冲突位的指令位。
(2)基于一位冲突直接识别,当只探测到一位碰撞位时,根据二进制数非0即1的特性,可直接识别出2个标签的ID 数据。
该算法所需的查询次数和通信量均优于后退式二进制树形搜索算法。
2.1.6 自适应分裂树算法
文献[25]提出自适应分裂树防碰撞算法,其核心思想是:在碰撞发生的时隙内,结合碰撞集规模估计(对标签反馈的脉冲信号进行强度叠加,然后阅读器根据信号幅值来判定碰撞集内的标签规模)的结果,确定碰撞标签的分裂规模SBC,并由阅读器将SBC 作为碰撞指令的参数反馈给标签。
该算法的具体实现流程为:在所有标签内实现一个计数器,将其初始化为0;阅读器发出查询指令后,仅计数器等于0的标签可以应答。若出现碰撞,则阅读器估计出当前碰撞标签规模N,根据线性模型SBC=factor×N(其中factor为分裂因子)计算出SBC 的值,并将其反馈给标签;所有计数器为0的标签(即上轮应答标签)都生成一个随机数,并对SBC 取余(结果用m 表示),然后将计数器值加上m,而其他标签的计数器值加上SBC-1。反复进行这一过程,直至出现唯一的应答标签。在成功识别标签或本轮没有标签应答时,所有标签计数器均减1。与此同时,已被成功识别的标签需置静默态,在本轮识别过程中不再响应阅读器。循环执行,即可以完成所有标签的识别。
当factor取值为0.8时[25],系统效率最高。该算法可根据产生碰撞的标签的数量来选择SBC 值,从而动态地调整分裂规模,加快标签分裂的过程,减少碰撞时隙。
2.1.7 自适应多叉树防碰撞算法
文献[26]提出一种自适应多叉树防碰撞算法,该算法通过统计碰撞比特出现的概率估计分支内标签的数量,根据搜索深度和分支内的标签数灵活地选择分叉数量。该算法中提出了碰撞因子μ 的概念,将其定义为:在碰撞时隙内碰撞比特占标签响应比特位的比值。通过理论分析确定了当μ≥0.75时,选择四叉树进行下一层搜素;当μ<0.75时,选择二叉树进行下一层搜素。仿真结果表明,从识别标签所需的总时隙数和吞吐率来看,该算法的性能优于其他算法。
2.2 查询树算法及其改进算法
在TS及其改进算法中,要求标签具备随机数生成器和计数器,增加了标签的设计复杂度,从而提高了设计成本[2]。为此,人们研究出了QT 算法,该算法仅要求标签具有前缀匹配电路即可,大大降低了标签的设计复杂度。
2.2.1 基本的查询树算法
在基本的QT 算法[27]中,阅读器首先向所有标签广播一个前缀,标签将接收到的前缀与自己的ID进行比较,若匹配,则进行响应,将自己的ID 号的未匹配部分发送给阅读器。如果有多个标签响应,就会出现冲突,此时阅读器在前缀后面增加一位(0或1),生成新的前缀,再用新前缀进行查询。如此重复,直到只有一个标签响应为止。
由于基本的QT 算法每次只对前缀扩展一位,冲突时隙较多,算法运行时间较长;而在每一次产生冲突时,标签都要将其ID 传送给阅读器,但实际上,此时传输的信息并没有意义,导致传输的信息量大。为此,人们对QT 算法进行了各种改进,主要集中在两方面:①如何一次使前缀扩展的位数尽量多,从而减少识别标签所需的总时隙数;②如何使标签和阅读器间传输的信息量尽量少。
2.2.2 shortcutting QT,QT-sl和QT-im
为了缩短QT 算法的运行时间,文献[27]提出shortcutting QT 算法。若阅读器在查询前缀q 时发现了冲突,则将在q后面加上0或1后,继续查询新的前缀。如果阅读器先查询q0,没有标签响应,则前缀为q1的标签就至少有2 个,肯定会产生冲突,因此可以跳过前缀q1,直接查询前缀q10和q11,由此形成了shortcutting QT 算法。
为了减少传输的信息量,文献[27]提出短长QT(QT short-long,QT-sl)算法和增量匹配QT(QT incremental-matching,QT-im)算法。在QTsl算法中,阅读器的查询分为短查询和长查询两种,对于短查询,标签只需以一位进行响应;而对于长查询,标签以其完整ID 号进行响应。阅读器确定只有一个标签与前缀匹配时,才会进行长查询。在QTim 算法中,要求标签记住阅读器上一轮发送的前缀,而在当前查询中,阅读器只发送前缀中新增加的部分。例如:假设上一轮的查询前缀为q,则在接下来的查询中,阅读器只发送0或1,而不是发送q0或q1,从而减少了传输的信息量。
2.2.3 跳跃式动态树形防碰撞算法
在跳跃式动态树形防碰撞算法[28]中,标签ID采用曼彻斯特编码,并以标签ID 发生碰撞的最高位作为下一次查询的依据。假设标签ID 的长度为m,第1位为最高位,第m 位为最低位,并假设发生碰撞的最高位是第x 位。
阅读器首先发送一个查询前缀ID1~x(标签ID值的第1~x 位)给所有标签,与之匹配的标签应答,返回剩余的m-x 位信息(第x+1~m 位),将这一操作用命令request(ID1~x,x)表示。
算法的基本思想是:
(1)阅读器首先发送request(NUL,0)命令,要求区域内所有标签响应。
(2)检测有无碰撞发生,若有,则确定碰撞的最高位。
(3)将碰撞的最高位置0,高于该位的数值位不变,可得ID1~x值,得到下一次request命令所需的两个参数。
(4)若无碰撞发生,则可识别出一个标签。标签ID 值为原ID1~x和应答时返回的IDx+1~m的组合,处理完后,将该标签设为哑状态。同时,采用回跳策略从其父节点获得下一次request命令所需的两个参数。
(5)重复以上过程,直到执行request(NUL,0)时无碰撞发生为止。
与传统的QT 算法相比,该算法识别标签所需的询问次数明显减少,阅读器识别N 个标签所需的询问次数为2 N-1[28]。
2.2.4 碰撞树算法
文献[29]中提出碰撞树(Collision Tree,CT)算法,其基本思想与跳跃式动态树形防碰撞算法[28]有一定相似之处,都是以标签ID 发生碰撞的最高位作为下一次查询的依据。但CT 算法在检测到碰撞发生的最高位(假设为第x 位)时,不是简单地将碰撞的最高位置0,而是将其分别设为0和1,由此产生两个新的查询前缀ID1~(x-1)0和ID1~(x-1)1,对之后的查询过程进行分裂。以前缀ID1~(x-1)0进行查询时,其过程与文献[28]相同,但在进行下一次查询时,所需的前缀已确定为ID1~(x-1)1,并不需要采用回跳策略从父节点获取。
与QT 算法相比,该算法在性能上有了很大的提升,其性能仅依赖于待识别的标签数量,与标签ID 的分布无关,并且当标签数量较多时,平均时间复杂度、平均通信复杂度、吞吐率都接近常数[30]。
但是,该算法也存在一定的缺点,即检测到碰撞发生的最高位时,会产生两个新的查询前缀ID1~(x-1)0和ID1~(x-1)1,这两个前缀的前x-1位都相同,只有最后一位不同,在接下来进行的两次查询中,传输的信息存在很大的重复,因此阅读器可以将两次查询合并为一次,只发送查询前缀的前x-1位,与之匹配的标签,第x 位为0则在第一个时隙响应,第x 位为1则在第二个时隙响应。
2.2.5 自适应的查询分裂算法
与QT 算法相似,自适应的查询分裂(Adaptive Query Splitting,AQS)算法[19,31]也是由阅读器广播一个前缀,标签将接收到的前缀与自己的ID 进行比较,若匹配,则进行响应。但是,AQS算法从上一帧建立的查询树的叶节点开始查询,而不是从根节点开始查询。其中,“帧”由若干个询问周期构成,在一个帧中,阅读器可识别出其作用范围内的所有标签。
AQS考虑了标签的移动,将标签分为驻留标签(在上一帧中已被识别的标签)、新到标签和离开标签三类。若能消除由驻留标签引起的冲突,则将大大缩短在当前帧中识别标签所需的时间。因此,AQS算法跳过上一帧建立的查询树的中间节点(对应的都是引起冲突的查询前缀),直接从叶节点(对应的是空闲周期或可识别单个标签的周期)开始查询。为此,阅读器需要维护两个队列:
(1)叶节点队列(Leaf node Queue,LQ)存放阅读器在当前帧中进行查询所需要的前缀,其初始值是上一帧建立的查询树中所有叶节点对应的前缀。
(2)候补队列(Candidate Queue,CQ)存放当前帧中的空闲周期和可识别周期(即只有一个标签响应)对应的前缀,为下一帧的查询做准备。
当一个新的帧开始时,用CQ 初始化Q,并将CQ 清空。若CQ 为空(如:阅读器被复位后),则用前缀0和1来初始化Q。
由于CQ 中存放的是上一帧中没有引起冲突的前缀,在新的帧中,阅读器可以跳过冲突周期。
当有新标签到达时执行插入操作,将新标签加入查询树;当有标签离开后,其对应的叶节点就会变成空闲周期,因此用删除操作来删除该节点,以便减少下一帧中不必要的查询。
从产生冲突的次数和通信开销方面来看,AQS都明显低于QT,当驻留标签数量较多时,优势更为明显。但在查询周期方面,AQS的优势并没有那么明显,尤其是当驻留标签数量较少(即有大量标签离开)时,AQS的查询周期反而多于QT,其原因是大量的标签离开从而形成了大量的空闲周期。
2.2.6 BSQTA 和BSCTTA 算 法
在QT 算法中,若查询前缀q时发现了冲突,则下一次的查询前缀为q0和q1,这两个前缀的前n-1位都相同,只有最后一位不同。为了减少传输信息量,阅读器可以将两次查询合并为一次,只发送查询前缀的前n-1位(即前缀q)与其匹配的标签,若第n位为0,则在第一个时隙响应;若第n位为1,则在第二个时隙响应。因此,时隙的编号就代表了第n位的值。基于这一思想,文献[32]提出基于位隙的QT 算法(Bi-Slotted Query Tree Algorithm,BSQTA)和基于位隙的碰撞跟踪树算法(Bi-Slotted Collision Tracking Tree Algorithm,BSCTTA)。
对于BSQTA,标签将其ID 号的第n+1 位至最后一位作为响应发送给阅读器;对于BSCTTA,标签也是从ID 号的第n+1位开始响应,但当阅读器检测到冲突后,会给标签发送一个ACK 命令,标签收到ACK 命令后,停止发送其ID 号。因此,在有冲突的情况下,BSCTTA 比BSQTA 发送的标签ID号的位数要少一些,从而减少了传输信息量。
2.2.7 基于16位随机数的查询树算法
文献[33]提出基于16 位随机数的QT 算法(16-bit Random Number aided Query Tree Algorithm,RN16QTA),在该算法中,每个标签都会产生一个16 位的随机数(16-bit Random Number,RN16),阅读器采用基本的QT 算法对这个RN16进行识别。当某个标签产生的RN16被识别后,阅读器给该标签发送一个ACK 命令,标签将其电子产品码(Electronic Product Code,EPC)作为响应发送给阅读器,完成一个标签的识别过程。
由于基于树的防碰撞算法的性能主要取决于树的高度,而标签的EPC一般都比较长(大于16位),采用基本 QT 算法时,树的高度都较大,而RN16QTA 采用的是16位随机数,可以大大减少查询树的高度,提高了算法的性能。但是该算法也存在明显的缺点:①通过RN16识别出标签后,还需要再传输一次标签的EPC,这无疑增加了阅读器与标签之间的通信负载;②16位二进制数能表示的数据范围有限,当标签数量较多时,多个标签可能会产生相同的随机数,导致标签无法被识别。
2.2.8 基于变长ID 的防碰撞算法
对于2.2.7 节提到的RN16QTA 算法的第一个缺点,文献[34]提出了基于变长ID 的防碰撞算法,该算法采用EPC global定义的RFID 标签EPC长度(96位),如图2所示。
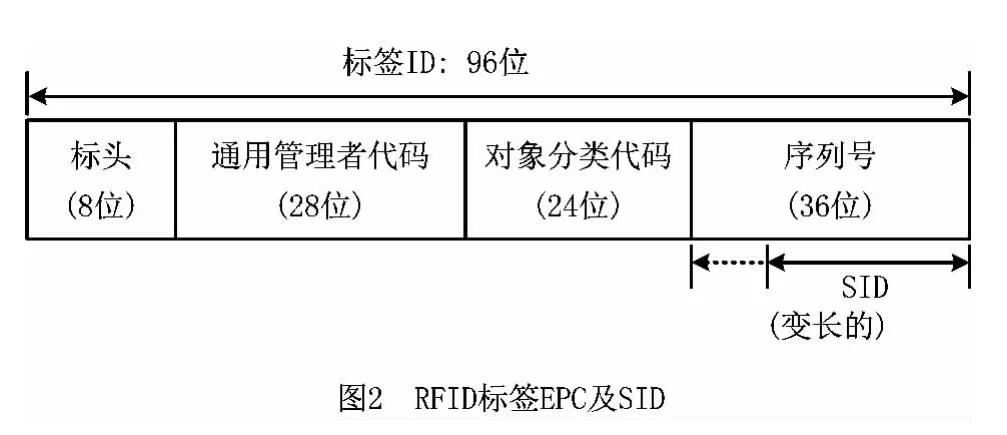
该算法利用标签EPC 中的缩短ID(Shortened ID,SID)(共36 位),将SID 最右边的位作为第1位,让其向左扩展,并根据未被识别的标签数量自适应地调整SID 的长度(假设为N 位,其初始值设为4)。采用QT 算法进行识别,阅读器首先生成一个n位的前缀(第一个前缀只有1位,其值为0)进行查询,若标签SID 的前n位与之匹配,则标签将其SID的剩余部分(共N-n 位)作为响应发送给阅读器,阅读器进行判断:
(1)若产生冲突,则阅读器采用QT 算法重新生成新的前缀,再次查询。
(2)若未产生冲突,说明可能只有一个标签,也可能有多个具有相同SID 的标签,则阅读器给标签发送一个ACK 命令,接收到该命令的标签将余下的96-N 位(即除了SID 部分以外的EPC 号)发送给阅读器。如果有多个标签具有相同的SID,则阅读器收到的96-N 位信息必然有冲突,此时需将SID 再扩展D 位,然后阅读器生成新的前缀再次进行查询。
(3)若没有标签响应,则说明未被识别的标签数量已经很少(例如当查询前缀为010时,无标签响应,可推测前缀为011的标签数量也不多),此时可以进一步减小查询树的高度,故将SID 减少D 位,但须满足条件N-D>n。
仿真结果表明,D=4 时算法的性能最好[34]。通过D 值的设置,该算法可以根据未被识别的标签数量自适应地调整SID 的长度,因此降低了标签识别过程中总的信息传输量。
2.2.9 增强型的RN16QTA 算法
对于2.2.7节提到的RN16QTA 算法的第二个缺点,经证明,当标签数大于300时,多个标签可能会产生相同的RN16[35],此时RN16QTA 算法将失效。虽然未被识别的标签可以再次生成RN16,并再次采用QT 算法进行识别,但是这种方法需要多次生成随机数,而且标签被成功识别后,还要再一次发送其EPC,这无疑增加了识别标签的时延及信息传输量。因此,文献[35]提出增强型的RN16QTA 算法,在该算法中,标签只需产生一次RN16;同时将标签的96位EPC 分为6段,即EPCi(1≤i≤6,其中EPC1为高位部分,EPC6为低位部分);通过与RN16进行异或操作产生RXEi(1≤i≤6),并将其作为临时ID 用于标签的识别过程。考虑在某些应用场合标签EPC的高位部分相同,在进行异或操作时,采用反向的EPC,即RXE1=RN16⊕EPC6,RXE2=RN16⊕EPC6⊕EPC5,…。
若采用RXEi能成功识别标签,则阅读器给标签发送一个ACK 信号,然后标签将RN16,EPC1~EPC6-i发送给阅读器,阅读器收到后,根据EPC6=RXE1⊕RN16,EPC5=RXE2⊕RXE1,…重新计算出EPC6,EPC5,…,最终得出标签的完整EPC。
该算法减少了标签识别过程中的信息传输量。
3 混合算法
基于Aloha算法和基于树的算法各有优缺点。基于Aloha算法的优缺点已在第1章进行了论述;基于树的算法虽然可以100%地识别标签、不会发生标签饥饿,但阅读器与标签之间交互次数多、通信数据量大。因此,可以将这两类算法的优点相结合,由此产生了混合算法。
3.1 基于鲁棒估计和二叉选择的FSA 算法
文献[36]对DFSA 算法中的标签数量估计方法进行了改进,提出基于鲁棒估计和二叉选择的FSA 算法(FSA with robust Estimation and Binary selection,EB-FSA),该算法由两个阶段构成:
(1)估算阶段 阅读器准确地估计标签数量,从而确定最佳帧长。EB-FSA 首先使用固定帧长Lest,如果发生冲突的概率大于阈值Pcoll_th,则阅读器按照因子fd减少响应的标签数量。重复这一过程,直至冲突的概率Pcoll≤Pcoll_th,然后根据Pcoll和Lc=Lest以及式(4)估算出标签数量n。

(2)识别阶段 阅读器根据估算的标签数量n确定最优帧长L。每个标签都有一个计数器,其初值为一个随机值,每个时隙、标签都递减自己的计数器,当计数器为0时,标签发送其ID 号。当有冲突发生时进行二叉选择,冲突的标签随机选择0或1作为其计数器值,其余标签的计数器值加1。
EB-FSA 算法在第一阶段通过对标签数量的准确估算来确定最佳帧长,从而降低了标签冲突的可能性。当有冲突发生时,在当前帧中通过二叉选择(而不是通过增加额外的帧)来解决冲突,从而快速识别标签。因此,EB-FSA 算法在性能上有了较大的提高,但其缺点是仍然需要额外的帧,以便对标签数量进行估计。
3.2 基于引导帧和二叉选择的FSA算法
基于引导帧和二叉选择的FSA 算法(FSA with Pilot frame and Binary selection,FSAPB)[37]通过使用位掩码将响应的标签分成M 个分组,用一个引导帧(长度为Lp)估计识别第一个分组内的标签所需的帧长。将标签分成更小的分组可以有效降低Lp的值,从而节约估计标签所需时隙。
第一分组中的标签在Lp内随机选择时隙发送其ID,同时阅读器记录冲突时隙的个数c,估算冲突的概率Pcoll=Lp-1max(0,c-1/2),并与冲突概率的阈值Pth比较。
若Pcoll>Pth,则只需要一个单一的识别帧。根据Pcoll和Lp估算出标签个数n1,其方法可参考式(4)。当Pcoll较大时,用“n1-Lp中识别出的标签个数”来估计识别帧L1的长度。在帧L1中,阅读器采用二叉树选择的方法对Lp中冲突的标签进行识别。
若Pcoll≤Pth,则表明只有少量的冲突,不需要增加额外的帧,可以在引导帧结束后增加额外的时隙Ladd,并直接应用二叉树选择法,此时在Lp中冲突的标签重新选择新的随机计数器值(根据在Lp冲突的顺序和Lp中的剩余时隙数进行选择)。
假设标签为均匀分布,则用位掩码分组后的每个分组也为均匀分布,因此对于第2~M 个分组,不再需要引导帧来估算标签个数。第k 组的帧长Lk=γ·nk-1,其中:γ为一个常数,文献[37]中确定的γ值为0.87;nk-1为第k-1个分组的标签个数。在Lk中,当产生冲突时,采用二叉树选择法解决冲突。
3.3 交织二进制树搜索算法
文献[38]将帧时隙Aloha算法和返回式二进制搜索算法的优点相结合,提出交织二进制树搜索算法,该算法将所有待识别标签进行随机分组,产生多棵由部分标签组成的子树,再针对每棵子树中的标签,使用返回式二进制树搜索方法进行识别,提高了多标签识别的效率和安全性,减少了标签发送ID的次数。算法的基本思想为:阅读器发起一个长度为Lint的交织帧,并等待标签响应;标签生成一个小于等于Lint的随机数k,并将其存储在标签存储器中,标签在当前帧的第k个时隙发送其ID 号。交织帧结束后,时隙将会被分成空闲时隙、单标签响应时隙、冲突时隙三种。对于冲突时隙,阅读器将会接收到类似于X01X 的信息(X 为发生碰撞的比特位),阅读器据此建立相应的碰撞信息表。发生碰撞的标签将其所选择的时隙编号ki存入碰撞信息表中的对应位置,然后阅读器按照ki从小到大的顺序对每个碰撞时隙内的标签进行识别,采用的识别方法为返回式二进制搜索算法。仿真结果表明,该算法的吞吐率达到60%以上。
3.4 动态时隙冲突跟踪树算法
文献[39]提出动态时隙冲突跟踪树算法(Dynamic Slots Collision Tracking Tree Algorithm,DSCTTA),该算法借用Aloha算法中时隙的概念对BSCTTA 算法[32]进行了改进,算法核心思想是:设置一个数值N,表示阅读器可以接收的响应信息中连续冲突位的长度。若N=2,则表示:若阅读器已接收到两个连续的冲突位(如0010XX),则给标签发送一个ACK 命令,标签停止发送其ID 号的剩余部分;然后阅读器将0010作为新的前缀查询与其匹配的标签,若其ID 未匹配部分的最高两位为00,01,10,11,则分别在第1,2,3,4个时隙响应,时隙的序号即为其最高两位的值。若N=1,则DSCTTA退化为BSCTTA 算法。
4 结束语
RFID 多标签防碰撞算法大致可分为基于Aloha的算法、基于树的算法以及前两者的混合算法三类。基于Aloha算法的通信复杂度低,动态适应性强,但是算法随机性大,性能不稳定,甚至可能出现标签饥饿的问题;基于树的算法不存在标签饥饿问题,但是阅读器与标签之间的交互次数多,通信数据量大,标签识别效率较低;混合算法正好结合了前两者的优点,是未来的研究方向之一。
本文提出的QT 算法及其改进算法所构建的查询树的深度与标签ID 的长度有密切关系,因此当标签的ID 长度增加时,算法的时延肯定会增加。针对这种情况,少量文献[33,35]提出了基于随机数的方法,降低了查询树的深度。因此,对基于随机数的QT 改进算法的性能进行详细分析,并在此基础上提出更为完善的算法,也是未来的一个研究方向。
除了多标签碰撞问题以外,在RFID 系统中还存在阅读器碰撞问题,目前已有部分文献[40-44]对该问题提出了解决方法。在此基础上,考虑阅读器与标签之间的通信特点,设计更具针对性的阅读器防碰撞算法,并尽量降低算法的复杂度,也是今后的研究方向之一。
[1]LI Minbo,JIN Zuxu,CHEN Chen.Application of RFID on products tracking and tracing system[J].Computer Integrated Manufacturing Systems,2010,16(1):202-208(in Chinese).[李敏波,金祖旭,陈 晨.射频识别在物品跟踪与追溯系统中的应用[J].计算机集成制造系统,2010,16(1):202-208.]
[2]LI Hua.Research and performance analysis of UHF RFID multi-tag anti-collision algorithms[D].Jinan:Shandong University,2011(in Chinese).[栗 华.UHF RFID多标签防碰撞算法的研究与性能分析[D].济南:山东大学,2011.]
[3]SHIH D H,SUN P L,YEN D C,et al.Taxonomy and survey of RFID anti-collision protocols[J].Computer Communications,2006,29(11):2150-2166.
[4]KLAIR D K,CHIN K W,RAAD R.A survey and tutorial of RFID anti-collision protocols[J].IEEE Communications Surveys &Tutorials,2010,12(3):400-421.
[5]FINKENZELLER K.RFID handbook:fundamentals and applications in contactless smart cards and identification[M].New York,N.Y.,USA:John Wiley &Sons,2003:200-219.
[6]SCHOUTE F C.Dynamic frame length ALOHA[J].IEEE Transactions on Communications,1983,31(4):565-568.
[7]CHA J R,KIM J H.Novel anti-collision algorithms for fast object identification in RFID system[C]//Proceedings of the 2005 11th International Conference on Parallel and Distributed Systems.Washington,D.C.,USA:IEEE,2005:63-67.
[8]VOGT H.Efficient object identification with passive RFID tags[J].Lecture Notes in Computer Sciences,2002,2414:98-113.
[9]HWANG T W,LEE B G,KIM Y S,et al.Improved anti-collision scheme for high speed identification in RFID system[C]//Proceddings of the 1st International Conference on Innovative Computing,Information and Control.Washington,D.C.,USA:IEEE,2006:449-452.
[10]WU Haifeng,ZENG Yu.ADFA protocol for RFID tag collision arbitration[J].Journal of Computer Research and Development,2011,48(5):802-810(in Chinese).[吴海峰,曾玉.自适应帧Aloha的RFID标签防冲突协议[J].计算机研究与发展,2011,48(5):802-810.]
[11]HAN Zhenwei,SONG Kefei.Improved anti-collision Q-algorithm for RFID system[J].Computer Engineering and Design,2011,32(7):2314-2318(in Chinese).[韩振伟,宋克非.射频识别防碰撞Q 算法的分析及改进[J].计算机工程与设计,2011,32(7):2314-2318.]
[12]EPC Global Inc.EPCTMradio-frequency identity protocols class-1generation-2UHF RFID protocol for communications at 860 MHz-960MHz,Version 1.0.9[EB/OL].(2005-01-26)[2012-10-09].http://www.gs1.org/gsmp/kc/epcglobal/uhfc1g2/uhfc1g2_1_0_9-standard-20050126.pdf.
[13]DENG Huifang,LIU Jinqiao,DENG Chunhui,et al.RFID multi-tags anti-collision algorithm with adaptive Q leading to the maximum throughput[C]//Proceedings of the 3rd Pacific-Asia Conference on Web Mining and Web-based Application.Washington,D.C.,USA:IEEE,2010:166-169.
[14]DENG Xiao,HE Yigang,XIANG Yang,et al.Novel tags quantity estimation method for anti-collision in RFID systems[J].Computer Engineering and Applications,2008,44(31):142-144(in Chinese).[邓 晓,何怡刚,向 阳,等.一种新的RFID标签数目估算方法[J].计算机工程与应用,2008,44(31):142-144.]
[15]WONG C P,FENG Q Y.Grouping based bit-slot ALOHA protocol for tag anti-collision in RFID systems[J].IEEE Communications Letters,2007,11(12):946-948.
[16]CHEN Yihong,FENG Quanyuan.RFID anti-collision algorithms for tags continuous arrival in Internet of things[J].Computer Integrated Manufacturing Systems,2012,18(9):2076-2081(in Chinese).[陈毅红,冯全源.物联网中标签持续到达的RFID 防碰撞算法研究[J].计算机集成制造系统,2012,18(9):2076-2081.]
[17]HUSH D R,WOOD C.Analysis of tree algorithms for RFID arbitration[C]//Proceedings of IEEE International Symposium on Information Theory.Washington,D.C.,USA:IEEE,1998:107.
[18]MYUNG J,LEE W,SRIVASTAVA J.Adaptive binary splitting for efficient RFID tag anti-collision[J].IEEE Communications Letters,2006,10(3):144-146.
[19]MYUNG J,LEE W,SRIVASTAVA J,et al.Tag-splitting:adaptive collision arbitration protocols for RFID tag identification[J].IEEE Transactions on Parallel and Distributed Systems,2007,18(6):763-775.
[20]CHEN W C,HORNG S J,FAN Pingzi.An enhanced anticollision algorithm in RFID based on counter and stack[C]//Proceedings of the 2nd International Conference on Systems and Networks Communications.Washington,D.C.,USA:IEEE,2007:1-4.
[21]HE M X,HORNG S J,FAN P Z,et al.A fast RFID tag identification algorithm based on counter and stack[J].Expert Systems with Applications,2011,38(6):6829-6838.
[22]CHEN Y H,HORNG S J,RUN R S,et al.A novel anticollision algorithm in RFID systems for identifying passive tags[J].IEEE Transactions on Industrial Informatics,2010,6(1):105-121.
[23]DENG Huifang,LIU Jinqiao.Binary-matrix search in anticollision of RFID system[J].Microcomputer Information,2009,25(10-2):4-5,3(in Chinese).[邓辉舫,刘金桥.RFID系统防碰撞中的二进制矩阵搜索[J].微计算机信息,2009,25(10-2):4-5,3.]
[24]YU Songsen,ZHAN Yiju,PENG Weidong,et al.An anticollision algorithm based on binary-tree searching of regressive index and its practice[J].Computer Engineering and Application,2004,40(16):26-28(in Chinese).[余松森,詹宜巨,彭卫东,等.基于后退式索引的二进制树形搜索反碰撞算法及其实现[J].计算机工程与应用,2004,40(16):26-28.]
[25]WEN Chao,OU Ruofeng,LING Li.RFID anti-collision algorithm based on adaptive splitting tree[J].Computer Engineering,2011,37(24):287-289(in Chinese).[文 超,欧若风,凌 力.基于自适应分裂树的RFID 防碰撞算法[J].计算机工程,2011,37(24):287-289.]
[26]DING Zhiguo,ZHU Xueyong,GUO Li,et al.An adaptive anti-collision algorithm based on multi-tree search[J].Acta Automatica Sinica,2010,36(2):237-241(in Chinese).[丁治国,朱学永,郭 立,等.自适应多叉树防碰撞算法研究[J].自动化学报,2010,36(2):237-241.]
[27]LAW C,LEE K,SIU K Y.Efficient memoryless protocol for tag identification[C]//Proceedings of the 4th International Workshop on Discrete Algorithms andMethodsfor Mobile Computing and Communications.New York,N.Y.,USA:ACM,2000:75-84.
[28]YU Songsen,ZHAN Yiju,WANG Zhiping,et al.Anti-collision algorithm based on jumping and dynamic searching and its analysis[J].Computer Engineering,2005,31(9):19-20,26(in Chinese).[余松森,詹宜巨,王志平,等.跳跃式动态树形反碰撞算法及其分析[J].计算机工程,2005,31(9):19-20,26.]
[29]JIA X L,FENG Q Y,MA C Z.An efficient anti-collision protocol for RFID tag identification[J].IEEE Communications Letters,2010,14(11):1014-1016.
[30]JIA X L,FENG Q Y,YU L S.Stability analysis of an efficient anti-collision protocol for RFID tag identification[J].IEEE Transactions on Communications,2012,60(8):2285-2294.
[31]MYUNG J,LEE W,SHIH T K.An adaptive memoryless protocol for RFID tag collision arbitration[J].IEEE Transactions on Multimedia,2006,8(5):1096-1101.
[32]CHOI J H,LEE D,LEE H.Bi-slotted tree based anti-collision protocols for fast tag identification in RFID systems[J].IEEE Communications Letters,2006,10(12):861-863.
[33]CHOI J H,LEE D,LEE H.Query tree-based reservation for efficient RFID tag anti-collision[J].IEEE Communications Letters,2007,11(1):85-87.
[34]YEO W Y,HWANG G H.Efficient anti-collision algorithm using variable length ID in RFID systems[J].IEICE Electronics Express,2010,7(23):1735-1740.
[35]YANG C N,HE J Y.An effective 16-bit random number aided query tree algorithm for RFID tag anti-collision[J].IEEE Communications Letters,2011,15(5):539-541.
[36]PARK J,CHUNG M Y,LEE T J.Identification of RFID tags in framed-slotted ALOHA with robust estimation and binary selection[J].IEEE Communications Letters,2007,11(5):452-454.
[37]EOM J B,LEE T J,RIETMAN R,et al.An efficient framed-slotted ALOHA algorithm with pilot frame and binary selection for anti-collision of RFID tags[J].IEEE Communications Letters,2008,12(11):861-863.
[38]HONG Weijun.Research on serveral key technologies on implementation and application of ultra high frequency radio frequency identification[D].Beijing:Beijing University of Posts and Telecommunications,2009(in Chinese).[洪卫军.超高频射频识别系统实现与应用中的若干关键技术研究[D].北京:北京邮电大学,2009.]
[39]LIANG C K,LIN H M.Using Dynamic slots collision tracking tree technique towards an efficient tag anti-collision algorithm in RFID systems[C]//Proceedings of the 9th International Conference on Ubiquitous Intelligence and Computing and 9th International Conference on Autonomic and Trusted Computing.Washington,D.C.,USA:IEEE,2012:272-277.
[40]YU J,LEE W,DU D Z.Reducing reader collision for mobile RFID[J].IEEE Transactions on Consumer Electronics,2011,57(2):574-582.
[41]KONSTANTINOU N.Expowave:an RFID anti-collision algorithm for dense and lively environments[J].IEEE Transactions on Communications,2012,60(2):352-356.
[42]DENG H F,HU C Y.Tackling RFID reader collision using a non-color metric minimum graph coloring method and Boltzmann machine model[C]//Proceedings of the 2nd International Conference on Intellectual Technology in Industrial Practice.Washington,D.C.,USA:IEEE,2010:598-602.
[43]ESSIA H,NATHALIE M,DAVID S R.Reader anti-collision in dense RFID networks with mobile tags[C]//Proceedings of the IEEE International Conference on RFID-Technologies and Applications.Washington,D.C.,USA:IEEE,2011:327-334.
[44]CHEN B Y,DENG H F,DENG C H.DPC-EDiCa:a RFID reader anti-collision algorithm for dense RFID system[J].International Journal of Automated Identification Technology,2013,5(1):21-32.
猜你喜欢
电子设计工程(2022年15期)2022-08-17
煤气与热力(2022年2期)2022-03-09
中等数学(2021年8期)2021-11-22
英语世界(2020年10期)2020-11-06
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
东北师大学报(自然科学版)(2018年3期)2018-09-21
湖北师范大学学报(自然科学版)(2015年1期)2016-01-10
现代计算机(2015年17期)2015-09-26
河南科技(2014年10期)2014-02-27
