
一种基于信息复用的Boosting瀑布型分类器高效训练方法
2014-11-18 03:15:16闫胜业
电子与信息学报 2014年10期
闫胜业
(南京信息工程大学信息与控制学院 南京 210044)
1 引言
瀑布型分类器是模式识别领域的基本技术之一。一般来讲,瀑布型分类器能够在基本不损失分类性能的条件下,大幅度提高分类器的运行效率。因此,瀑布型分类器被广泛地应用在各种模式识别算法中,特别是在需要多次运行分类器、对分类运行时间要求比较高的场合,比如特定目标物体检测(人脸[113]-,人体[14,15],文本[16,17]等等)。
瀑布型分类器由多个顺序串联的层级分类器构成。在分类过程中,一个待分类图像窗口被顺序输入到各个层级分类器中,只有在待分类图像通过前一个层级分类器的基础上,它才会被输入到下一个层级分类器进行进一步的处理。一旦某个层级分类器将待分类图像判断为非物体对象,那么,待分类图像窗口将被最终决策为非物体图像。输入图像只有通过所有层级分类器,才被判决为目标物体。在瀑布型分类器中,各层级分类器的复杂度随层级增加递增,这就实现了使用简单分类器对大部分的简单图像窗口进行排除,而复杂的层级分类器只对少数复杂图像窗口进行判决,从而达到提高计算效率的目的。
一个具有典型意义的瀑布型分类器模型由Viola等人[2]在 2001年提出,并成为一个里程碑式的工作。文献[2]提出的瀑布型分类器学习模型因为其能够方便自动地完成训练并且性能良好而具有非凡的意义。在文献[2]提出的算法中,只需输入每个层级分类器要达到的最小检测率、最大误检率以及训练样本,训练算法就会自动地按照这个误检率和检测率标准对每个层级分类器进行学习。一旦某个层级分类器的误检率和检测率满足要求(误检率小于最大误检率,同时检测率大于最小检测率),则本层级的子分类器训练结束,进入下一个层级分类器的学习。下一个层级分类器的学习过程会收集前面层级分类器检测失败的反例训练样本,并重新迭代训练一个相同类型的层级分类器,继续训练一个在新的样本集上达到最小检测率和最大误检率的层级分类器。由于每个层级的子分类器都具有相同的构造,所以学习起来非常方便,并且由于Boosting学习算法[18]的引入以及大规模特征集的引入,还能够保证瀑布型分类器最终的分类性能。因此,继Viola等人在人脸检测问题上对此瀑布型分类器进行了尝试之后,孙锐等人[14]在人体检测中进行了尝试,Hanif等人[16]在文本检测中进行了尝试,另外,在人脸检测中围绕特征、学习算法等方面的改进方法还有很多,具体的介绍超出了本文的研究范围。
尽管Boosting瀑布型分类器已经展示了其易用性和有效性,此算法仍然存在一个缺点,那就是训练时间过长,以基于Haar特征的人脸检测瀑布型分类器的训练为例,在使用30000个Haar特征,20000个训练样本的规模下,训练时间在1个星期以上。然而快速训练对应用开发非常重要,在模型开发中,往往需要训练多个模型,以获得性能最好的分类器,如果分类器训练速度过慢的话,将造成明显的障碍。针对此,本文提出一种改进的基于Boosting的瀑布型分类器训练算法,在不影响分类性能的情况下,提高基于 Boosting算法的瀑布型分类器的训练速度。
训练时间过长的主要原因之一是层级分类器需要学习特征的数目过多,以上文中提到的人脸检测器为例,一般来讲,要学到一个分类性能良好的分类器,最后得到的层级分类器中往往包含上千个Haar特征,假设最后获得的瀑布型分类器中包含2500个 Haar特征,学习获得一个 Haar特征需要90 s的时间,那么,完成一个瀑布型分类器的训练要消耗至少2500×90 s=225000 s=2.6 d的时间。本文设计了一个算法,在瀑布型分类器训练过程中,将已获得的层级分类器的信息在后继分类器中进行复用,以减少需要学习新特征的次数,并最终提高瀑布型分类器总的训练速度。本文提出的训练算法在两个层次上复用共享信息:第1个层次,在分类器层次上,前一个层级的分类器在新的训练方法中成为第1个特征,并被应用在当前层级分类器的训练样本集上,进行弱分类器的学习;第2个层次,在特征层次上,所有前面层级分类器已经学到的特征重新在当前层级分类器的训练样本集上进行学习,获得新的弱分类器来适应新的样本。在正面人脸检测上的实验表明,本文提出的新算法相比传统方法能够大幅度提高层级分类器的训练速度,提高幅度近10倍,分类器的训练时间从3 d降到了8 h。
本文的前期工作已在文献[6]中发表,但文献[6]只提出了特征层次的信息复用方法,本文在分析了复用信息于训练速度提升的意义基础上,引入分类器层次的信息复用,提出两个层次(特征层次和分类器层次)信息联合复用的方法。另外,对新算法的实验也表明,同时复用两个层次的信息,能够进一步提高分类器的训练速度。
2 分类器层次的信息复用Nested 瀑布型分类器
文献[2]提出的瀑布型分类器分类流程如图1所示,图中各个层级分类器相互独立训练得到,没有采取任何形式的信息复用。在这种瀑布型分类器的训练过程中,每个层级分类器都在新收集的样本下重新使用Boosting算法训练的强分类器。如果使用来表示特征计算函数,使用来表示弱分类器函数,使用来表示Boosting中的强分类器函数,使用x来表示待分类图像。那么文献[2]提出的瀑布型中第n个层级分类器函数可以表示为

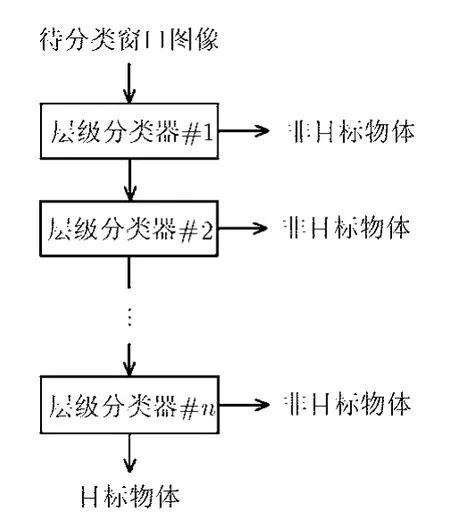
图1 文献[2]提出的瀑布型分类器结构
Nested瀑布型对文献[2]提出的瀑布型分类器进行了改进,在分类器的层次上对前面层级分类器中获得的分类信息在当前层级中复用,它由文献[3]提出。相比于文献[2]提出的瀑布型分类器,在Nested瀑布型分类器中,每个层级分类器中的第1个弱分类器不是由新挑出的特征构成,而是将前一个层级分类器学得的分类函数直接作为特征,使用自举法(Bootstrap)得到的反例样本和正例样本进行适应学习获得。然后,在此弱分类器的基础之上,才进一步添加新的特征。由于前个层级分类器对于新的“自举”得到的样本依然具有一定的分类能力,所以进一步需要添加的新的特征数目会减少。在基于Boosting的学习中,挑选特征的时间往往大大高于从一个固定特征学习弱分类器的时间,所以Nested在增加了一个小的时间代价同时(学习弱分类器),却减少了更大量的时间消耗(新添加特征的挑选),所以 Nested瀑布型分类器能够提高层级分类器的训练效率。Nested瀑布型分类器的层级分类器分类函数可以表示为
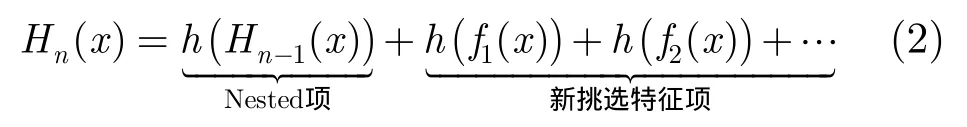
对比式(1),可以看出,相比文献[2]提出的瀑布型分类器,Nested瀑布型分类器的层级分类器函数多了“Nested项”。
Nested瀑布型分类器的结构见图2。图中弱分类器使用圆圈表示,Nested弱分类器使用半圆表示,特征使用矩形框表示。每个虚线圆角矩形框中都是一个层级分类器。Nested项使得相邻的层级分类器内部相互连接,形成一个“嵌入式”的结构,所以此分类器结构被命名为Nested瀑布型分类器。如果去除Nested弱分类器项,Nested瀑布型分类器与文献[2]提出的瀑布型分类器完全一样。

图2 Nested瀑布型分类器
3 特征层次的信息复用Fea-Accu瀑布型分类器
Nested瀑布型分类器在分类器的层次上实现了不同层级分类器之间的共享信息复用,但忽略了在更细节的特征级别的信息共享。实际上,位于前面的层级分类器中每个已经学习获得的特征对于后继层级分类器来说依然具有很大的通用性。本节简要介绍特征层次的信息复用,详见文献[6]。
特征层次的信息复用实现方式如下:对每个层级分类器的学习,在开始添加新的特征之前,对前面所有层级分类器已经学习得到的所有特征,在新的当前样本集上重新进行适应性学习,获得新的弱分类器。这些特征的更新顺序采用了一种非常简单的方式,顺序更新。然后,在这些弱分类器的基础上,根据需要,学习新的特征,添加新的弱分类器。由于特征层次往往包含巨大的共享信息,所以在适应性学习之后,需要新挑选的特征数目往往大量减少。如上面提到的,在Boosting学习框架下,从固定特征学习弱分类器的时间要远远小于挑选新特征的时间,所以从训练时间上来讲,层级分类器总的训练时间大大减少。
这种从特征层次进行不同层级分类器信息共享的瀑布型分类器如图3所示。图中黑色矩形表示特征,Ki表示第i个层级分类器的特征数目, h表示弱分类器,H表示层级强分类器,每个层级的弱分类器拥有双下标,其中第1个下标表示层级序号,第2个下标表示在本层级中本弱分类器的序号,每个层级的强分类器拥有单下标,表示层级序号。图中,每个特征下面的弱分类器都来自于同一个特征,但是隶属于不同的层级分类器函数,比如对于特征f1,在第1个层级分类器H1中,作为新挑选出的特征学习得到的分类器是h11,而在第2个层级分类器中,此特征被重新使用学习了一个新的弱分类器h21,依次类推。由于特征在每个层级分类器中都呈现一种累加的结构,所以此瀑布型分类器结构被命名为Fea-Accu瀑布型分类器,其中“Fea”是英文单词“Feature”的缩写,“Accu”是英文单词“Accumulating”的缩写。
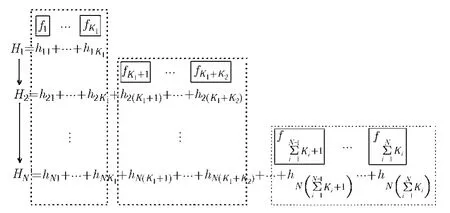
图3 Fea-Accu瀑布型分类器
采用前面的符号定义,Fea-Accu瀑布型分类器函数可以表示为

4 分类器层级及特征层次的信息联合复用Nested Fea-Accu瀑布型分类器
前面两节分别描述了 Nested瀑布型分类器和Fea-Accu瀑布型分类器。Nested瀑布型分类器从分类器层次对瀑布型分类器已经获得的层级分类器进行复用,Fea-Accu瀑布型分类器从更细节的特征层次出发,对瀑布型分类器中已经获得的层级分类器中每个特征都进行复用。从复用信息的角度来说,对前面层级分类器中已获得的信息复用程度越高,训练代价才可能越低。而分类器层次复用的信息和特征层次复用的信息还是有所不同的,因此,本节进一步提出了Nested Fea-Accu瀑布型分类器结构,将两种层次的共享信息复用进行联合。
Nested Fea-Accu瀑布型分类器采用了一种简单的串联方式实现两种层次共享信息的同时复用。首先,每个层级分类器的训练都先进行分类器层次信息的复用,也就是学习Nested瀑布型分类器中的Nested项,然后进行特征层次的信息复用,就是学习Fea-Accu瀑布型分类器中的Fea-Accu项,最后,再根据需要添加新的特征。这种同时使用Nested瀑布型分类器和 Fea-Accu瀑布型分类器的思想进行不同层级分类器信息共享的分类器结构,被命名为Nested Fea-Accu瀑布型分类器。采用前文中的符号定义,Nested Fea-Accu瀑布型分类器的层级分类器函数表示为
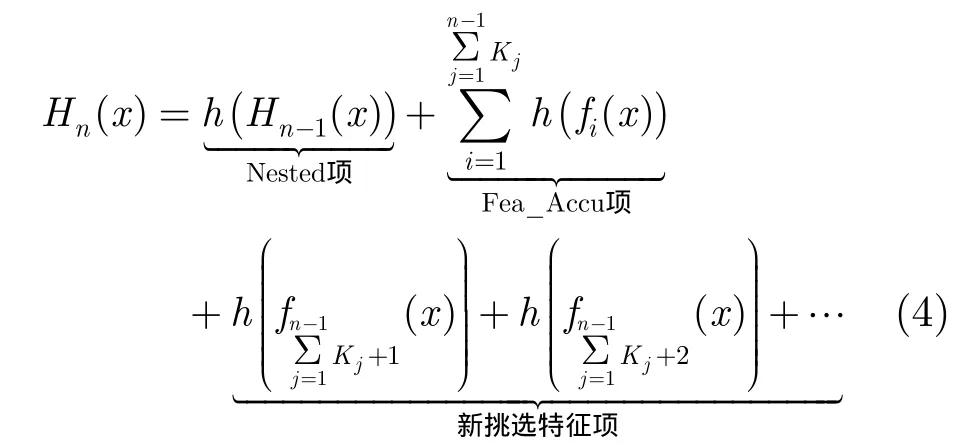
对比式(4)和式(2),式(3),可以观察到Nested项和Fea-Accu项被同时添加到了Nested Fea-Accu的层级分类器函数中。
5 实验
本节对Nested 瀑布型分类器,Fea-Accu瀑布型分类器和Nested Fea-Accu瀑布型分类器在提高训练效率方面进行了专项和综合评估,具体调查了包括:复用信息的分类能力、信息复用之后需新选特征数目、训练时间等等。另外,还对 Nested Fea-Accu瀑布型分类器的分类性能进行了评估,下面从评估过程中使用的实验配置开始陈述。
实验在正面人脸检测问题上进行,其中正例训练样本集包括20000个人脸训练样本,每个层级分类器使用10000个非人脸样本作为直接的反例样本训练集,这 10000个非人脸训练样本从一个包含30000幅图像的图像集合中收集得到。这30000幅图像中的每幅图像都进行了人工检查,以确认不包含人脸图像。每个训练样本图像的大小为24×24。Haar特征被用来进行强分类器的学习。对于这样的一个训练图像大小,均匀采样得到 31728个 Haar特征,这个特征集合被用来进行特征的挑选及弱分类器的学习。RealBoost学习算法[14]用来学习强分类器。
第 1组实验调查 Nested瀑布型分类器、Fea-Accu瀑布型分类器和Nested Fea-Accu瀑布型分类器复用信息的效果。具体来说,实验调查了Nested项,Fea-Accu项和Nested Fea-Accu项在当前训练样本集上的信度分布曲线。实验选择在第10层的层级分类器上进行,其它层级的情况是类似的。图 4给出了在新“自举”得到的反例样本集上和正例样本集上3个分类器的信度-样本数目分布曲线。其中纵坐标是人脸数目和非人脸数目,横坐标是3个分类器响应值量化一致后的信度。人脸信度分布曲线和非人脸信度分布曲线分得越开越好。从图中可以得出3个结论:(1)3种复用的分类器对当前样本都具有一定的分辨能力;(2)Fea-Accu 和Nested Fea-Accu瀑布型分类器对当前样本的分辨能力都要明显好于Nested瀑布型分类器;(3)Nested Fea-Accu瀑布型分类器对当前样本的分辨能力要略好于 Fea-Accu瀑布型分类器。以上是直接观察获得的结论,为了更严谨地对区分性进行探讨,我们还对3种瀑布型分类器情况下的人脸分布和非人脸分布的 Bhattacharyya 距离[19]进行了计算。Bhattacharyya 距离是一种判断两个连续概率分布分离性的重要衡量指标,连续情况下的概率密度函数的Bhattacharyya 距离计算需要进行微积分操作,这里由于分布函数形式未知,所以采用了一种离散情况下 Bhattacharyya距离近似计算方法,使用累加代替积分来进行Bhattacharyya距离计算。计算过程中将分布函数划分为41个bin,获得Nested瀑布型分类器,Fea-Accu分类器和Nested Fea-Accu分类器的 Bhattacharyya 距离分别为201.56, 243.80, 249.42。这些数据得到的结论和图4观察得到的结论一致,Nested Fea-Accu瀑布型分类器的区分性最好。

图4 信度-样本数目曲线
以上以第10个层级分类器为例,对3种复用方法的复用效果进行了对比调查。另外,我们还对Nested Fea-Accu项在Nested Fea-Accu瀑布型分类器中各个层级分类器中的复用效果进行了调查。仍然使用 Bhattacharyya距离来考察层级分类器中Nested Fea-Accu项的可区分性指标,图 5给出了在Nested Fea-Accu瀑布型分类器中,从第1个层级分类器到第15个层级分类器中计算得到的Bhattacharyya距离。从图5中可以看出,在第1个层级分类器中,Bhattacharyya距离为0。在后面所有的层级分类器中,Bhattacharyya距离变化不大,保持在一个比较好的水平。这表明,本文算法能够持续提供良好的信息复用,即使在层级分类器的增加,反例样本变得越来越复杂的情况下。这个现象可以这样解释,对于第1个层级,由于Nested Fea-Accu新增加特征项包含特征个数 0,导致正负样本完全混叠,Bhattacharyya 距离也为0。对于从第2个层级开始的层级分类器,随着层级的增加,虽然反例样本变得越来越复杂,对反例样本和正例样本进行区分需要更多的特征,但是由于相应Nested Fea-Accu项从前面层级分类器中继承的特征数目也越来越多,分类器适应更复杂样本的能力也越来越强,所以Nested Fea-Accu项的可区分性能够始终保持在一个比较好的水平。
第 2组实验调查 Viola经典瀑布型分类器,Nested瀑布型分类器,Fea-Accu瀑布型分类器和Nested Fea-Accu瀑布型分类器中需要新添加特征的数目。实验分别训练了4个检测器,4个检测器都训练至目标误检率在百万分之一以下。4个瀑布型分类器中每个层级分类器中新添加的特征数目如图 6所示,从图中可以看出,随着层级的增加:(1)Nested 瀑布型分类器需要添加的新的特征的数目少于Viola 经典分类器;(2)Fea-Accu分类器需要添加的新的Haar特征的数目明显少于Nested瀑布型分类器;(3)Nested Fea-Accu瀑布型分类器相对于 Fea-Accu瀑布型分类器能够更进一步地减少新添加的特征的数目。对于Viola经典瀑布型分类器,Nested瀑布型分类器,Fea-Accu瀑布型分类器和Nested Fea-Accu瀑布型分类器,总的需要新添加的特征数目分别为1236个,788个,213个,162个。
第3组实验结果汇报在同一机器上训练4个瀑布型分类器的所需的时间。训练Nested瀑布型分类器需要约 62 h,训练 Nested瀑布型分类器需要约40 h,训练Fea-Accu瀑布型分类器需要约10 h,而训练Nested Fea-Accu瀑布型分类器需要的时间最短,只要约8 h。
以上从不同角度对本文提出的 Nested Fea-Accu瀑布型分类器的在提高训练效率方面进行了调查,下面进一步调查Nested Fea-Accu瀑布型分类器的分类性能。性能测试在 CMU正面人脸测试集上[1]进行。图7给出了Nested Fea-Accu瀑布型分类器的ROC曲线,一起还列出了在CMU正面人脸检测集上其它研究者报告的结果,可以看出,本文方法的结果是最好的。另外,值得说明的是,虽然在图中没有展示Nested瀑布型分类器和Fea-Accu瀑布型分类器的ROC曲线,性能对比中,Viola经典瀑布型分类器,Nested瀑布型分类器,Fea-Accu瀑布型分类器和Nested Fea_Acuu瀑布型分类器获得的测试结果非常接近,这是因为这4种分类器使用了相同的训练样本。图 8展示了一些使用 Nested Fea-Accu瀑布型分类器在实际视频图像中的一些检测结果,这些检测结果还展示了存在旋转情况下的正面人脸检测结果,这是通过多次旋转图像,并应用Nested Fea-Accu瀑布型分类器多次实现。
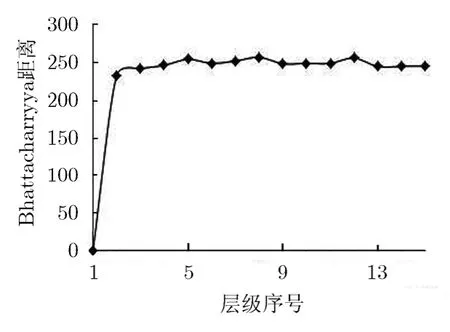
图5 Nested Fea-Accu瀑布型分类器中每个层级Nested Fea-Accu项的可区分性调查
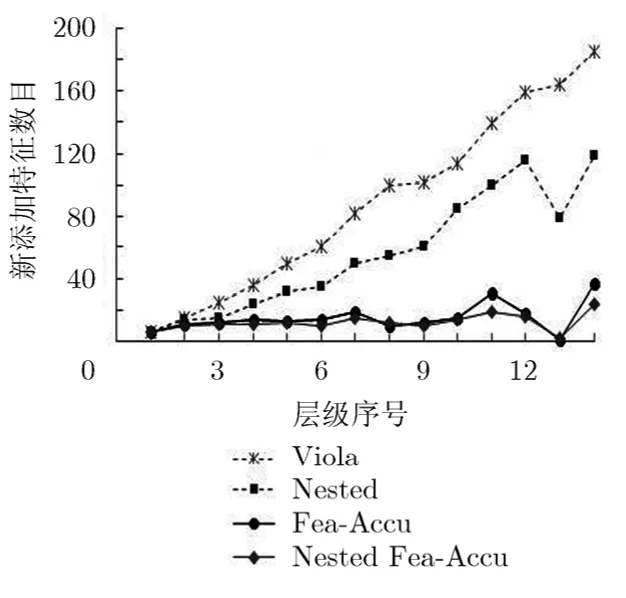
图6 4种瀑布型分类器新 添加特征数目的对比图
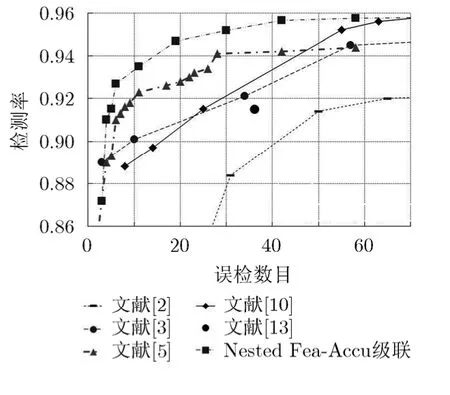
图7 CMU正面人脸测 试集上的ROC曲线

图8 正面人脸检测结果示例
最后,关于检测速度,这4种瀑布型分类器的检测速度非常接近,对于一副320×240的图像,在一个Intel Core™ 2.00 GHz的机器上,检测时间都在1 s左右。考虑到本文重点是设计一个训练Boosting瀑布型分类器的高效算法,将不针对如何提高检测速度的问题进行详细讨论。在拥有一个高性能的瀑布型分类器之后,有很多预处理算法可以提高瀑布型分类器的检测时间,比如基于LAB预处理分类器的算法[20]。
6 结束语
本文提出了一种利用信息复用思想提高 Boosting瀑布型分类器训练速度的方法,文中提供了详细的实验。实验结果表明本文方法能够在保持瀑布型分类器分类性能的同时,大幅提高训练速度,对基于Boosting瀑布型分类器相关的模式识别算法开发具有很强的借鉴意义。
[1] Rowley A H, Baluja S, and Kanade T. Neural network-based face detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(1): 23-38.
[2] Viola A P and Jones J M. Rapid object detection using a boosted cascade of simple features[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Kauai, 2001: 511-518.
[3] Huang Chang, Ai Hai-zhou, Wu Bo, et al.. Boosting nested cascade detector for multi-view face detection[C].Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, 2004: 415-418.
[4] Li Z S and Zhang Z Q. FloatBoost learning and statistical face detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(9): 1112-1123.
[5] Bourdev D L and Brandt J. Robust object detection via soft cascade[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, 2005:236-243.
[6] Yan Sheng-ye, Shan Shi-guang, Chen Xi-lin, et al.. Fea-Accu cascade for face detection[C]. Proceedings of the International Conference on Image Processing, Cario, 2009: 1217-1220.
[7] Cheng X, Ruan L, Fookes C, et al.. Efficient real-time face detection for high resolution surveillance applications[C].Proceedings of the 6th International Conference on Signal Processing and Communication Systems, Queensland, 2012:1-6.
[8] Wu Di and Cao Jie. Face detection in video sequences using a novel local normalization technique and simplified Gabor features[J]. Journal of Computational Information Systems,2012, 8(11): 4789-4796.
[9] Ahmad F, Najam A, and Ahmed Z. Image-based face detection and recognition: “state of the art”[J]. IJCSI International Journal of Computer Science, 2012, 9(1):169-172.
[10] Wu Zheng-wang, Liu Yue-hu, Du Shao-yi, et al.. A save-fail mechanism for face detection validation[C]. Proceedings of the IEEE Intelligent Vehicles Symposium, Xi’an, 2009:490-493.
[11] Chen Shi-gang, Ma Xiao-hu, and Zhang Shu-kui. AdaBoost face detection based on Haar-like intensity features and multi-threshold features[C]. Proceedings of the International Conference on Multimedia and Signal Processing, Guilin,2011: 251-255.
[12] Wei Zhe, Dong Yuan, Feng Zhao, et al.. Face detection based on multi-scale enhanced local texture feature sets[C].Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, 2012:953-956.
[13] 蔡灿辉, 朱建清. 采用 Gentle AdaBoost 和嵌套级联结构的实时人脸检测[J]. 信号处理, 2013, 29(8): 956-963.Cai Can-hui and Zhu Jian-qing. Real-time face detection using Gentle AdaBoost and nesting cascade structure[J].Journal of Signal Processing, 2013, 29(8): 956-963.
[14] 孙锐, 陈军, 高隽. 基于显著性检测与HOG-NMF特征的快速行人检测方法[J]. 电子与信息学报, 2013, 35(8): 1921-1926.Sun Rui, Chen Jun, and Gao Jun. Fast pedestrian detection based on saliency detection and HOG-NMF features[J].Journal of Electronics & Information Technology, 2013, 35(8):1921-1926.
[15] Benenson R, Mathias M, Timofte R, et al.. Pedestrian detection at 100 frames per second[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Rhode Island, 2012: 2903-2910.
[16] Hanif M S and Prevost L. Text detection and localization in complex scene images using constrained AdaBoost algorithm[C]. Proceedings of the Tenth International Conference on Document Analysis and Recognition,Barcelona, 2009: 1-5.
[17] Neumann L and Matas J. Real-time scene text localization and recognition[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Rhode Island,2012: 3538-3545.
[18] Schapire R E and Singer Y. Improved Boosting algorithms using confidence-rated predictions[J]. Machine Learning,1999, 37(3): 297-336.
[19] Theodoridis S, Pikrakis A, Koutroumbas K, et al..Introduction to Pattern Recognition: A Matlab Approach[M].Burlington: Academic Press, 2010: 119-120.
[20] Yan Sheng-ye, Shan Shi-guang, Chen Xi-lin, et al.. Locally Assembled Binary (LAB) feature with feature-centric cascade for fast and accurate face detection[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, 2008: 1-7.
猜你喜欢
疯狂英语·新读写(2021年8期)2021-11-05 08:44:26
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
小学阅读指南·低年级版(2021年3期)2021-03-19 20:40:29
航天工业管理(2020年9期)2020-12-28 00:38:02
军事运筹与系统工程(2020年1期)2020-09-11 06:41:00
动漫星空(2018年9期)2018-10-26 01:17:14
小天使·一年级语数英综合(2018年1期)2018-06-22 10:05:16
系统工程与电子技术(2016年2期)2016-04-16 05:17:09
小朋友·快乐手工(2015年6期)2015-07-01 00:48:26
发明与创新(2015年33期)2015-02-27 10:40:09
