
未知网络应用流量的自动提取方法
2014-10-27 11:53:50王变琴余顺争
通信学报 2014年7期
王变琴,余顺争
(1. 中山大学 东校区教学实验中心,广东 广州 510006;2. 中山大学 信息科学与技术学院,广东 广州 510006)
1 引言
网络流量的准确识别和分类是提供差异性服务质量(QoS,quality of service)保障、入侵检测(intrusion detection)、流量监控(traffic monitoring)及计费管理(accounting)等方面的基础。然而,面对网络应用的快速发展,传统的端口应用识别法逐渐失效,基于流(flows)统计特征的流量分类方法[1,2]不能进行应用的精确识别,利用载荷特征(signature)的应用识别方法[3,4]简单、准确度较高,在实际中被广泛应用,然而如何自动获取载荷特征是这种方法面临的主要问题,目前已有一些研究成果[5~11]。Byung-Chul 等人[5]提出一种基于LCS(longest common substring)的载荷特征提取方法——LASER;Wang等人[6]提出利用序列比对方法提取载荷特征;Ye等人[7]提出一种基于子树(subtree)结构的特征生成系统——AutoSig;赵咏等人[8]提出一种基于语义信息的协议特征自动发现方法——TPCAD;刘彬等人利用关联规则算法提取载荷特征。所有这些方法所需要的数据源都是同种应用协议的流量。获取已知应用的流量较为容易,可以通过特定的网络应用进程生成或从混合流量中获取(对于端口固定的应用,利用端口从中提取其流量;对于非固定端口的应用,则可以利用支持这种应用流量识别的系统或工具提取其流量)。如果要将这些载荷特征自动提取方法扩展到未知网络应用,则需要获得单一未知应用的流量,然而在实际中获取的未知流量通常是一种或几种未知应用协议流量的混合。因此,首先需要将混合流量进行分离、归类,使得每类中的流量属于同一种应用,目前这方面的研究极少。Zhang等人[12]提出利用分组的五元组信息对会话进行聚类,但由于五元组和应用类别没有直接关系,使得这种方法不太可靠;在协议逆向工程(protocol reverse engineering)研究领域,学者利用聚类方法[13,14]对报文进行归类,用于同类报文格式的提取,这些研究还只是一些初步探索。
本文利用聚类方法对未知混合应用流量进行分离,首先选择会话行为特征(一种流量统计特征)对混合流量进行聚类。实验评估发现,在不同应用会话行为特征相似情况下,这种方法不能有效分离不同应用流量。为此提出一种基于载荷信息的流量聚类方法,该方法通过对载荷中的字节进行编码,利用不同于传统距离函数的 Jaccard系数作为相似性度量对流量进行聚类。实验评估表明,这种基于载荷信息的方法比利用会话行为特征的流量聚类方法更为有效。
2 相关研究
利用聚类方法对流量进行聚类的研究已有将近十年历史,目前研究主要是基于流量的各种统计特征的聚类,期望实现在线流量分类或识别[15~18]。Mcgregor等人[15]利用流的统计特征和EM(expectation maximization)算法将流聚成不同应用类型(Bulk transfer,single and multiple transactions and interactive traffic),这是聚类方法在本领域的最早尝试。Zander等人[16]利用顺序前向选择(SFS,sequential forward selection)策略对流的统计特征进行优化,利用AutoClass算法(EM算法的一种拓展,通过反复使用EM算法以便找到全局最优解)识别应用(FTP、Telnet、SMTP、DNS、HTTP、AOL Messenger、Napster、Half-Life)。Erman1 等人[17]则比较了3种聚类算法在流量分类时的性能,评估结果显示K-means和DBSCAN算法的性能均好于AutoClass算法,其中DBSCAN算法聚类效果最好。董仕等人[18]利用端口统计特征的差异对 P2P流量进行聚类。
与现有方法不同,本文的目标是实现对未知混合流量的分离,以期获得同种应用流量的聚类,用于载荷特征自动提取前的数据预处理。这种方法的一般框架如图1所示,首先采集未知应用流量,这种流量由网络中部署的流量识别系统(例如L7-filter)不能识别应用生成的混合流量,然后通过聚类分析获得同种未知应用流量,在此基础上,完成未知应用协议特征的自动提取。

图1 未知应用特征提取框架
通常对未知混合流量没有先验知识,只能根据流量自身内在特点、规律以及相似性原则对其进行归类。聚类分析(cluster analysis)是处理这类问题的一种有效方法,它根据“物以类聚”的规律,将数据集划分为若干簇(cluster),这些簇是事先未知的,其形成完全由数据驱动。本文进行聚类的对象是会话(与连接或双向流的概念相同),因其不仅包含通信双方在2个方向上独立的网络流特征,还包含2个单向流之间的关联特征,具有更强的特征描述能力。未知混合流量可以被处理成由会话组成的集合,据此本文研究的问题描述为:给定一个会话集S={s1,…,sn},定义一个映射f:S→C,其中第i个会话被映射到第j个簇Cj中,Cj由所有被映射到该簇中的会话组成,即=Cj,1≤j≤k ,且si∈S },每个簇 Cj(1≤j≤k)代表一种未知应用流量,问题的求解视为产生一个簇集 C={C1,…,Ck}的过程。
聚类方法的性能与特征选择以及聚类算法有关。本文根据未知混合流量的特点,分别选择统计特征和载荷信息进行聚类,并通过实验评估不同聚类算法的性能。
3 基于会话行为特征的未知流量聚类方法
现有流量聚类方法大都是基于分类对象的统计特征。会话行为特征是指会话内报文(不含载荷)的各种统计特征。Moor等人[19]对可能存在的多种候选特征进行了深入研究。在实际应用中,特征选择具有挑战性,需要结合实际情况。考虑到通常获得的未知流量是流量识别引擎无法识别的流量,只是实际聚合流量的部分数据,已经不再具有聚合流量的特征。因此关于多个会话之间的统计特征不再可靠。此外,实际中的流量识别系统,例如,L7-Filter,一般只保留会话的部分数据,而非完整会话数据。Bernaille1[20,21]等人提出利用会话的前N个分组长度和方向作为特征具有一定的根据,因为许多基于TCP协议的应用层协议(少数除外,例如HTTP协议)在完成3次握手后,进入应用层协议的协商过程,例如,SSL协议密钥协商过程,FTP协议认证密码过程等,这些不同协议有不同的协商过程,并且协商过程是双向的,因此还需要区分报文的不同方向。Bernaille1等人提出2种特征选择方案:文献[20]中根据观察会话内报文的大小分布,把报文大小(字节数)映射为4个级别{1,2,3,4}(其中,{1=[0,150],2=[150,700],3=[700,1300],4=[1300,1500]}),并结合分组方向(利用符号表示分组方向:“+”代表客户端报文,“−”表示服务器端报文)将会话表示成 ∑={±1,±2,±3,±4}上的一个序列,每个会话表示为Si=(v1,…,vli),其中,li为序列长,vt∈∑代表序列的第 tth个分组,生成所有会话的集合 S={si},然后利用变换生成的序列进行聚类,本文称这种特征选择方案为会话映射策略;另一种特征选择方案[21]则将每个会话的前 N个报文的精确长度与方向作为特征。上述这2种方案均符合未知混合流量特点,本文通过实验评估基于这2 种特征的不同算法 k-means[22]、EM[23]和DBSCAN[24]对未知混合流量的聚类。评估结果发现,当不同应用的会话行为特征比较相似时(例如FTP、POP3协议),基于会话行为特征的聚类方法则不能有效区分它们。
4 基于载荷信息的未知流量聚类方法
据研究,会话的前m个报文中包含载荷特征,并且多分布在报文开始和结束的固定位置处。特征由不同字节序列组成,通过对字节编码,可以将其作为不同类别字符,不同协议会话报文载荷则包含不同字符组合。假设选取每个会话的前m个报文,每个报文的前n个字节,然后按照偏移对报文中的字节进行编码处理:规定报文首字节偏移为零,则该字节标注为b0,偏移为i的字节标注为bi,编码后的字节当成不同类别字符对待,这样会话s可以表示为s=m1m2m3,…,mm,其中mi=b0b1b2…bn,通过度量会话间的相似度来区分不同协议的会话。
Guha等人[25]提出一种面向类别数据的聚类算法——ROCK(robust clustering algorithm for categorical attributes using link),其突出贡献是采用基于全局信息的公共邻居(链接)作为评价数据对象间的相似性(similarity)度量标准,受此启发,提出一种基于载荷信息的ROCK流量聚类方法,引入的概念如下。
定义1 2个会话之间的相似度由Jaccard系数(coefficient)定义,令 si,sj为2个会话,则

当函数sim(si,sj)=0时,表明2个会话完全不同;sim(si,sj)越大,表明会话si和sj越相似,当sim(si,sj)=1时,表明2个会话相同。
例如,会话 s1=“220-HeUSER a331 UsPASS a”,会话s2=“220 WeUSER a331 UsPASS b”,对应位置相同的字符有 21个,则 sim(s1,s2)=21/(21+2·(24−21))=0.778。
定义2 设θ为给定相似度阈值,称 si,sj互为邻居,当且仅当

定义3 令 si,sj为2个会话,称 si,sj的公共邻居数目为其链接,即

其中,Ni和Nj分别为si,sj的邻居表。
定义4 2个簇间的链接定义为
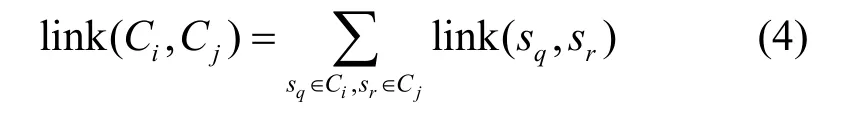
定义5 指导合并的Goodness函数定义为
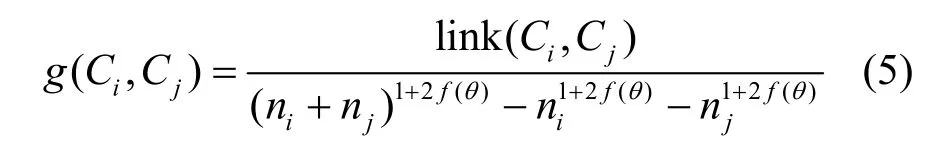
其中,分子是Ci、Cj之间的实际链接数目。
函数 link(Ci,Cj)是 2个簇之间的链接数目,ni和nj分别是2个簇中的点数目。大簇有较多链接,用分母来归一化链接数。当相似性度量的阈值为θ时,在Ci中点对之间链接数的估计值为。函数f(θ)的具体形式取决于数据,但它满足一条性质,即在簇Ci中的每一个成员大约有个邻居。显然,如果簇中的所有点相互邻接,则 f(θ)=1,进而得出簇Ci中的点对之间的连接数。实验中,选择 f(θ)=(1-θ)/(1+θ)。
ROCK算法的核心思想为:给定会话集 S、期望得到的簇数 k,计算任意两点间的相似度,进而求出两点间的链接数,每次合并g值最大的2个簇集,直到达到给定的簇数 k为止。与距离函数相比,链接不全局信息的度量,其过程描述见算法1。
算法1 procedure cluster(S,k)
输入:

输出:
begin
1)link :=compute_links(S)// 计算两样本间共同邻居数
2)for each s∈ S do
3)q[s]:=build_local_heap(link,s)// 初始时,对每个簇创建局部堆q[s]
4)Q :=build_global_heap(S,q)// 创建全局堆Q
5)while size(Q)>k do {
6)u :=extract_max(Q)// 抽取Q中g(u,max(q[u]))最大的簇u
7)v :=max(q[u])// 抽取 u的局部堆q[u]中g(u,v)最大的簇v
8)delete(Q,v)
9)w :=merge(u,v)// 合并簇u和簇v为簇w
10)for each x∈ q[u]∪ q[v]do { // 完成包含簇u,v的局部堆与创建簇w的局部堆
11)link[x,w]:=link[x,u]+ link[x,v]
12)delete(q[x],u); delete(q[x],v)
13)insert(q[x],w,g(x,w)); insert(q[w],x,g(x,w))
14)update(Q,x,q[x])
15)}
16)insert(Q,w,q[w])
17)deallocate(q[u]); deallocate(q[v])// 释放簇u与簇v的局部堆q[u]、q[v]
18)}
end
算法分析:第1)步由函数compute_links(S)计算2个样本间共同邻居link,其过程描述如算法2所示;第2)步和第3)步创建局部堆,最初各个样本各自为一个簇,对于每个簇i,创建对应的局部堆q[i],对于簇j,若link[i,j]不为0,则q[i]中包含簇j,并且计算簇i与簇j的优良度g(i,j),按g(i,j)的降序排列;第4)步创建一个包含所有簇的全局堆Q,计算g(j,max(q[j]))(max(q[j])为与簇j最优合并的簇,即q[j]的第一个元素),同样按g(j,max(q[j]))降序排列,全部簇加入后,此时,Q的第一个元素簇j与q[j]的第一个元素为最佳合并的簇;第5)~18)步不断地合并簇,直到簇的数目为k或者剩下簇间的link等于0,其中,第6)步抽取Q中g(u,max(q[u]))最大的簇u;第7)步对应抽取q[u]中g(u,v)最大的簇v;第8)步由于簇u与簇v合并,删掉对应Q中的簇u与簇v;第9)步合并簇u与簇v并创建簇w;第10)~15)步对于每个局部堆中包含簇u或簇v的簇x,都要在它的局部堆q[x]中用w代替,并按优良度排序,创建簇w的局部堆q[w],第16)步q[w]创建完成,并将w插入到Q中;第17)步释放簇u与簇v的局部堆q[u]、q[v]继续循环。
算法2 procedure compute_links(S)
begin
1)Compute nbrlist[i]for every point i in S //计算样本i相似度得其邻居列表nbrlist[i]
2)Set link[i,j]to be zero for all i,j
3)for i :=1 to n do {
4)N :=nbrlist[i]; // N为i邻居列表
5)for j :=1 to |N|−1 do // |N|为i邻居列表邻居个数
6)for i :=j+1 to |N| do
7)link[N[j],N[i]]:=link[N[j],N[i]]+ 1// 邻居对N[j]与N[i]
8)}
end
该算法的时间复杂度和空间复杂度分别为O(n2logn)和O(n2)。2个会话之间的链接数目link由它们共同的邻居数目来定义,聚类算法的目标是将具有更多链接的点聚成簇,属于层次聚类方法(hierarchical method),其相似度度量采用的是链接数目。与距离度量相比,使用链接度量提供一种全局的方法,因为两点之间的相似度也受其他点的影响。
5 实验评估
分别评估基于会话行为特征和基于载荷信息的未知流量聚类方法的性能。利用工具 Wireshark在CERNET某小区网络出入口处采集包含载荷(payload)数据的真实网络流量,采集时间为2009年1月8日~15日,分别随机选择3个不同时段(每个时段持续5 min)数据,从中提取目前流行的7种应用(HTTP、FTP、SMTP、POP3、SSL、MSN、BT)的会话(如表1所示)进行测试,它们的会话数不等,这也符合未知混合流量的实际情况,因为在采样的时间段内常常仅有某种或某几种未知应用流量的出现,各种应用的流量分布不均,可能某一种或几种流量较多,而其他则较少。每种应用的数据平均分成3组分别进行3次测试,所得实验结果是其平均值。
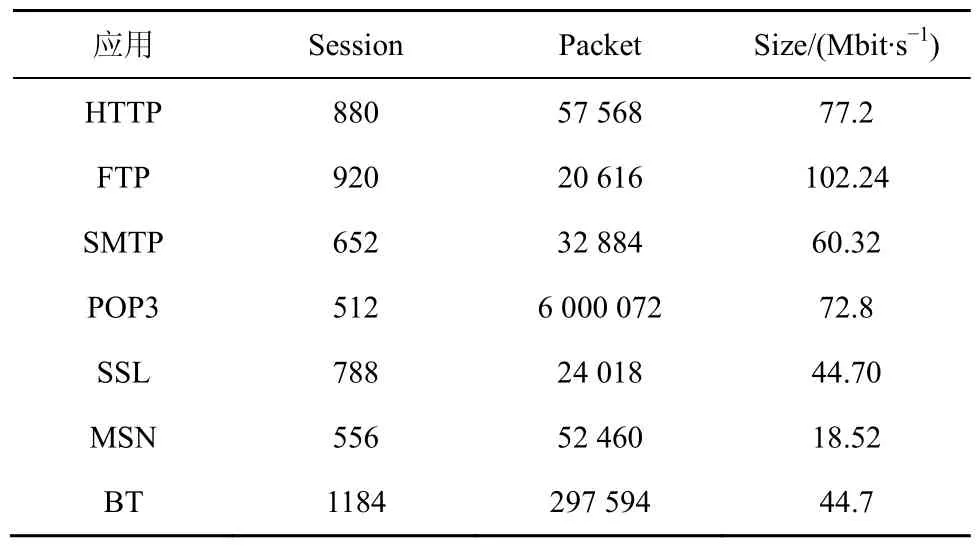
表1 样本会话集
实验机为PC机(CPU:Intel Core 2 Duo E65502.33 GHz,内存:0.99 GB),其操作系统为Windows,ROCK算法用 C++语言实现,其余算法利用Weak3.6.5[26]测试。
聚类效果的评价指标:漏报率(FNR,false negative rate)和误报率(FPR,false positive rate),它们可表示为
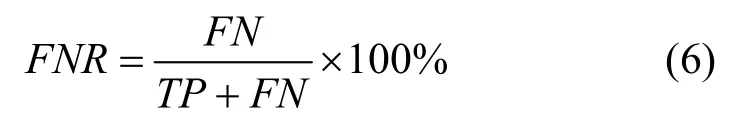
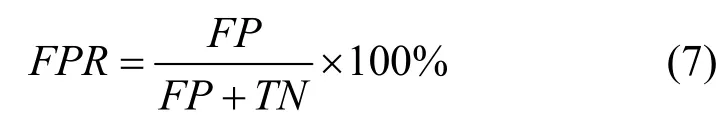
理论上,k-means和DBSCAN算法的时间复杂度分别为O(n)、 O(n2),而EM是基于统计模型的聚类算法,其时间复杂度一般比 DBSCAN高,实验获得的3种算法的耗时长短为:k-means (16 ms)<DBSCAN(50 ms)<EM (64 ms),这与理论分析结果是吻合的。对于同一种算法,2种特征选择策略的运行时间几乎一样。由于数据量不大,测出的耗时可能有误差,但也能反映3种算法在同一数据集上的时间差异。
其中,TP(true positive)是被预测为正的正样本;TN(true negative)是被预测为负的负样本;FP(false positive)是被预测为正的负样本;FN(false negative)是被预测为负的正样本。
5.1 会话行为特征的流量聚类方法评估
一般会话的前4个报文正好处于应用协议的协商阶段,这个阶段的报文序列是预定义好的,不同应用之间有差异,因此,选择会话建立阶段的前 4个报文大小和方向作为特征,分别利用 k-means、DBSCAN和EM 3种聚类算法进行测试。
实验1 比较2种会话行为特征选择方案:1)会话的精确报文大小和方向;2)会话映射策略。选择会话行为特征差异较为显著的3种协议的流量进行测试,其结果如表2所示。
从表2可知,对于第1种特征选择方案,3种算法都能产生较好的聚类效果,相比之下,DBSCAN算法的聚类效果最好,具有低漏报和误报,虽然它忽略某些样本,但从数据预处理的角度看,只是减少样本数,不大会影响应用特征的提取结果。第2种特征选择方案的聚类效果普遍比第1种稍差,这是由于将报文大小映射到有限的区间,屏蔽了协议报文的某些差异,使其不能精确反映协议之间的区别。

表2 2种不同特征选择方法比较
实验 2 评估不同数据集上各种算法的性能。在实验1的数据集中分别混入MSN、BT以及POP3协议的流量来评估3种算法的聚类效果。MSN协议比较特别,它有3种连接,分别是连接到DS服务器,获得NS服务地址;连接到NS服务器,用于身份验证、得到个人信息、上线通知,或者发送、接受聊天请求;连接到SB服务器,用于发送或接收聊天消息。3种连接的会话形式不同,实验数据只取其连接到DS服务器的会话来做聚类处理。测试结果如表3~表5所示。
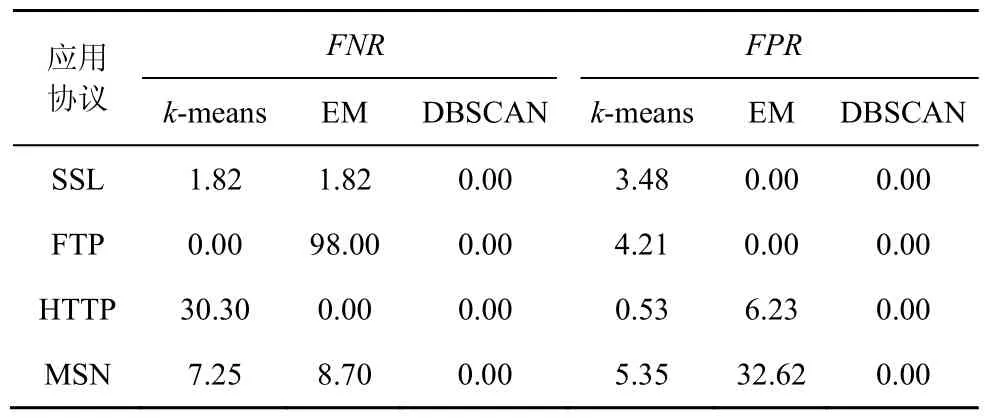
表3 增加MSN流量时不同聚类算法的聚类效果

表4 增加BT流量时不同聚类算法的聚类效果
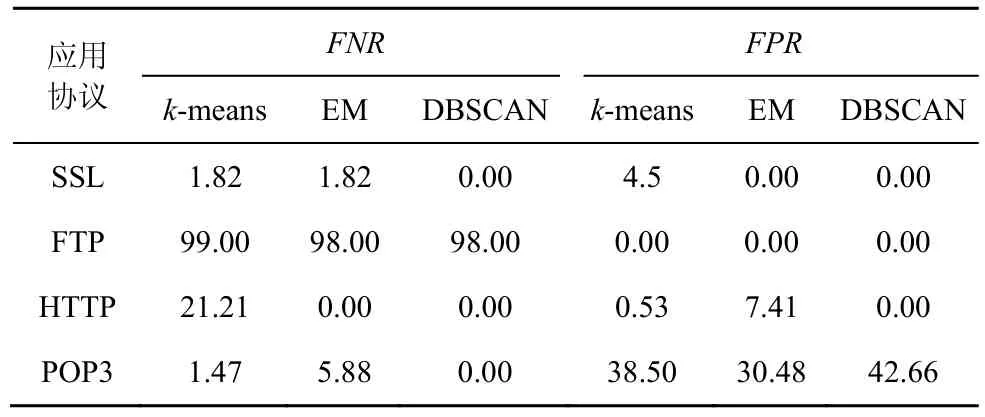
表5 增加POP3流量时不同聚类算法的聚类效果
从结果可知,当混入MSN协议或BT协议的流量时,相比其他2种算法,DBSCAN算法最好,具有低误报和低漏报,但当混入POP3协议的流量时,DBSCAN也同样不能区分POP3和FTP协议的流量,它将绝大部分的FTP协议流量误报为POP3协议的流量,这缘于2种协议交互过程产生的会话行为特征比较相似。
5.2 基于载荷信息的ROCK流量聚类方法评估
分别取会话前4个报文(不包括TCP返回的ASK报文)的前6个字节拼接成24个字节的字节序列作为特征,利用ROCK算法对混合流量进行聚类。
ROCK算法对于离群点(outliers)的处理有2种方法:1)在聚类前得到每对会话的 link值时,通过设定阈值来去除没有或较少邻居的样本;2)通过设定一个大于实际簇数k值来实施聚类,在聚类之后再去除离群点。本实验采用第1种方法(丢掉link=0的点)。
ROCK算法有2个重要参数:相似度阈值θ和聚类簇数 k。在实现算法时,当簇没有邻居或剩下的簇数目等于k时,停止聚类,因此最后的聚类数目大于等于 k。由于实际的混合流量中包含未知流量的种类有限,因此在设置簇数k时,可以设定一个稍大的k值来去除一些离群点来获得较纯的簇;θ对聚类结果的影响将通过实验评估。
实验3 选择行为相似的3种协议的流量,评估基于载荷信息的ROCK流量聚类方法的性能,并测试不同θ值对结果的影响,同时与基于会话行为特征的DBSCAN方法进行比较,其结果如表6所示。

表6 基于载荷信息的ROCK算法的流量聚类效果
由表 6可知,当θ=0.4,没有误报率;但当θ=0.2时,则存在一定程度的误报,说明θ对ROCK算法聚类结果有很大影响。选择小的θ可以减少样本的丢弃,但很有可能会引起误报,导致簇纯度降低,而选择大的θ会使邻居数减少,从而减小数据点间的链接数量,降低误报。基于会话行为特征的 DBSCAN方法在最佳参数时的聚类效果明显差于基于载荷信息的ROCK方法,原因在于这3种协议具有相似的会话行为特征,但其载荷信息有差异。
理论上,ROCK算法的时间复杂度为O(n2logn),高于 DBSCAN算法的时间复杂度O(n2),实验中它们的实现方法不同,无法直接比较其效率。作为载荷特征自动提取方法的数据预处理,一般采用离线式处理方法,因此,方法的效率和效果相比,后者更为重要。
6 结束语
本文研究了未知混合流量中不同应用流量的自动归类问题。通过对会话的各种候选特征进行分析,最终选择会话的前4个报文大小和方向作为区分特征,利用适合于此特征的3种不同聚类算法(k-means、EM、DBSCAN)对来自真实网络上的混合流量进行聚类分析,实验结果表明,基于密度的 DBSCAN聚类算法具有较低的漏报率与误报率,其效果明显好于其他2种算法。但在不同应用的会话行为较为相似时,这种基于会话行为特征的方法仍不能有效地分离不同应用的会话。为此本文提出一种基于载荷信息的 ROCK流量聚类方法,通过对载荷中字节进行编码,利用Jaccard系数作为相似性度量,评估结果显示,这种方法具有较好的效果。然而,当它完全面对未知应用流量、在缺乏评判标准时,如何能够自适应选择参数,达到未知应用的自然分类仍需要进一步研究。
[1]BERNAILLE L,TEIXEIRA R,AKODKENKUT I,et al. Traffic classification on the fly[J]. ACM SIGCOMM Computer Communication Review,2006,36(2): 23-26.
[2]CROTTI M,DUSI M,GRINFOLI F,et al. Traffic classification through simple statistical fingerprinting[J]. ACM SIGCOMM Computer Communication Review,2007,37(1): 1-16.
[3]SEN S,SPATSCHECK O,WANG D M. Accurate,scalable in-network identification of P2P traffic using application signatures[A]. Proceedings of WWW2004[C]. New York,2004.512-521.
[4]Application layer packet classifier for linux[EB/OL]. http://17-filter.Sourceforge.net,2012.
[5]PARK BC,WON YJ,KIM MS,et al. Towards automated application signature generation for traffic identification[A]. Proceeding of the IEEE/IFIP Network Operations and Management Symposium[C].Salvador da Bahia,2008.160-167.
[6]WANG Y,XIANG Y,ZHOU W L,et al. Generating regular expression signatures for network traffic classification in trusted network management[J]. Journal of Network and Computer Applications,2011,17:1-9.
[7]YE M J,XU K,WU J P,et al. Autosig-automatically generating signatures for applications[A]. Proceeding of the IEEE Ninth International Conference on Computer and Information Technology[C]. Xiamen,China,2009.104-109.
[8]赵咏,姚秋林,张志斌等. TPCAD: 一种文本类多协议特征自动发现方法[J]. 通信学报,2009,30(10A): 28-35.ZHAO Y,YAO Q L,ZHANG Z B,et al. TPCAD: a text-oriented multi-protocol inference approach[J]. Journal on Communications,2009,30(10A): 28-35.
[9]刘兴彬,杨建华,谢高岗等. 基于 Apriori 算法的流量识别特征自动提取方法[J]. 通信学报,2008,29(12): 51-59.LIU X B,YANG J H,XIE G G,et al. Automated mining of packet signatures for traffic identification at application layer with Apriori algorithm[J]. Journal on Communications,2008,29(12): 51-59.
[10]龙文,马坤,辛阳等. 适用于协议特征提取的关联规则改进算法[J].电子科技大学学报,2010,39(2): 302-305.LONG W,MA K,XIN Y,et al. Improved association rules algorithm for protocol signatures extracting[J]. Journal of University of Electronic Science and Technology of China,2010,39(2): 302-305.
[11]王变琴,余顺争. 一种自适应网络应用特征发现方法[J]. 通信学报,2013,34(3): 127-137.WANG B Q,YU S Z. Adaptive extraction method of network application signatures[J]. Journal on Communications,2013,34(3): 127-137.
[12]ZHANG M W,LIU D P. Scalable and accurate application signature discovery[A]. Proceeding of the IEEE Pacific-Asia Workshop on Computational Intelligence and Industrial Application[C]. 2008.482-487.
[13]MA J,LEVCHENKO K,KREIBICH C,et al. Unexpected means of protocol inference[A]. Proceeding of the 6th ACM SIGCOMM Conference on Internet Measurement[C]. New York,NY: ACM,2006:313-326.
[14]李伟明,张爱芳,刘建财等. 网络协议的自动化模糊测试漏洞挖掘方法[J]. 计算机学报,2011,34(2): 242-254.LI W M,ZHANG A F,LIU J C,et al. Automatic network protocol fuzz testing and vulnerability discovering method[J]. Chinese Journal of Computers,2011,34(2): 242-254.
[15]MCGREGOR A,HALL M,LORIER P,et al. Flow clustering using machine learning techniques[A]. Proceedings of PAM’04[C]. Antibes Juan-les-Pins,France,2004.205-214.
[16]ZANDER S,NGUYEN T,ARMITAGE G. Automated traffic classification and application identification using machine learning[A]. Proceeding of LCN’05[C]. Sydney,Australia,2005.
[17]ERMAN J,ARLITT M,and MAHANTI A. Traffic classification clustering algorithms[A]. Proceedings of SIGMETRICS’06(MineNet)[C]. Pisa,Italy,2006.281-286.
[18]董仕,王岗. 基于UDP流量的P2P流媒体流量识别算法研究[J]. 通信学报,2012,33(12): 25-34.DONG S,WANG G. Research on P2P streaming media identification based on UDP[J]. Journal on Communications,2012,33(12): 25-34.
[19]MOORE A W,ZUEV D. Discriminators for Use in Flow-based Classification[R]. Intel Research,Cambridge,2005.
[20]BERNAILLE L,TEIXEIRA R,AKODKENOU I,et al. Traffic classification on the fly[J]. ACM SIGCOMM Computer Communication Review,2006,36(2): 23-26.
[21]BERNAILLE L,TEIXEIRA R,SALAMTIAN K. Early application identification[A]. Proceedings of CoNEXT’06[C],Lisboa,Portugal,2006.
[22]JAIN A K,DUBES R C. Algorithms for clustering data[M]. Prentice-Hall,Inc,1988.
[23]DUMPSTER A P,PAIRD N M,RUBIN D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society,1977,39(1): 1-38.
[24]ESTER M,KRIEGEL H P,SANDER J,et al. A density-based algorithm for discovering clusters in large spatial database with noise[A].Proceedings of the International Conference on Knowledge Discovery in Databases and Data Mining[C]. Portland,Oregon,1996.226-231.
[25]GUHA S,RASTOGI R,SHIMK. ROCK: a robust clustering algorithm for categorical attributes[J]. Information System,2000,25(5):345-366.
[26]WEKA[EB/OL]. http://www.cs.waikato.ac.nz/~ml/weka/index.html.
猜你喜欢
汽车电器(2022年9期)2022-11-07 02:16:24
铁道通信信号(2020年4期)2020-09-21 09:15:24
中国外汇(2019年11期)2019-08-27 02:06:30
疯狂英语(双语世界)(2017年4期)2017-04-28 09:10:37
电子制作(2017年23期)2017-02-02 07:17:06
海外华文教育(2016年3期)2017-01-20 08:22:18
铁道通信信号(2016年8期)2016-06-01 12:10:21
西北工业大学学报(2015年4期)2016-01-19 03:31:47
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
