
一种基于客户行为时序分析的反洗钱异常交易识别方法
2014-09-19 07:05:16刘卓军李晓明
中国管理科学 2014年12期
刘卓军,李晓明,2
(1.中国科学院数学与系统科学研究院,北京 100190;2.中国科学院大学,北京 100049)
一种基于客户行为时序分析的反洗钱异常交易识别方法
刘卓军1,李晓明1,2
(1.中国科学院数学与系统科学研究院,北京 100190;2.中国科学院大学,北京 100049)
可疑交易报告制度是打击洗钱活动的一项基本机制,如何有效甄别可疑交易是金融机构和金融情报中心面临的一个技术难点。为辅助反洗钱分析人员从海量金融交易信息中甄别客户异常交易,本文提出一种预测误差和统计处理综合法——CPEST,通过分析客户前后行为的一致性来发现异常。CPEST建立客户行为模型,根据预测误差对客户行为进行时点异常检验,并在此基础上构造一个窗口检验,以提高对涉嫌洗钱行为的识别能力。本文在支持向量回归和核密度估计等具体实现手段的基础上,运用CPEST对实际交易和仿真数据进行分析,结果表明该方法的有效性和可行性,具有应用推广价值。
反洗钱;异常点监测;时序;支持向量回归;核密度估计
1 引言
反洗钱工作以打击洗钱和恐怖融资犯罪为目标,在保卫国家安全、反腐败和维护经济金融稳定中发挥着重要作用。《中华人民共和国反洗钱法》对反洗钱的定义是,“为了预防通过各种方式掩饰、隐瞒毒品犯罪、黑社会性质的组织犯罪、恐怖活动犯罪、走私犯罪、贪污贿赂犯罪、破坏金融管理秩序犯罪、金融诈骗犯罪等犯罪所得及其收益的来源和性质的洗钱活动,依照本法规定采取相关措施的行为”。可疑交易报告制度是打击洗钱活动的一项基本机制,国际反洗钱组织金融行动特别工作组(FATF)在《打击洗钱、恐怖融资、扩散融资国际标准:FATF建议》(2012)中规定,如果金融机构有合理理由怀疑资金为犯罪收益,或与恐怖融资有关,则应立即按法规要求向金融情报中心报告。
如何高效地甄别可疑交易是各国反洗钱工作普遍面临的一个技术难点。金融机构要想从日常业务经营中发现洗钱分子的蛛丝马迹,除了做好客户尽职调查,了解客户的真正身份,摒弃基于简单规则的可疑交易筛选方式,强调通过人工分析判别可疑交易[1]之外,还应注意利用数据挖掘技术提高人工分析效率。我国承担反洗钱可疑交易报告义务的金融机构和承担洗钱线索分析任务的中国反洗钱监测分析中心,面临从海量原始客户和交易信息中筛选异常交易行为的艰巨任务。仅2010年一年,中国反洗钱监测分析中心接收的大额交易报告超过就2亿份,可疑交易报告超过6000万份[2],说明了这项工作的艰巨性,分析人员仅凭经验人工分析处理原始信息非常低效,难以保证既不漏报又不误报洗钱线索。这种工作现状激发了数据挖掘技术在反洗钱中应用研究的开展,研究人员力求构建合理数学模型识别客户交易行为特征,进而通过计算机软件对原始交易信息进行有效分析处理。
应用时序异常点监测技术来帮助分析人员发现异常交易,是将数据挖掘技术应用于反洗钱监测分析的一个重要方面。已有研究方法主要有两种,一种是基于相似度核的监测方法,例如汤俊[3]提出基于拟合时序线段斜率比较的检测方法,Liu Xuan[4]提出基于欧氏距离对客户交易的资金序列进行匹配比较,以发现异常交易序列;另一种是基于交易网络的监测方法,例如喻炜[5]提出了基于交易网络特征向量中心度量的可疑洗钱行为检测方法。已有研究成果为数据挖掘方法在可疑交易甄别中的应用奠定了基础,但距满足实际工作需求仍有不足,主要表现在未充分考虑金融交易复杂性,算法效率不高;未重视分析人员与计算机软件系统的交互;虽然考虑了通过客户之间的行为比较来发现异常,对不同客户进行了正常和异常的区分,但对客户自身行为一致性研究不够;以及由于难以获得样本数据而未使用真实洗钱案例对所提方法进行验证等方面。本文从客户行为分析的角度出发,综合运用非线性时序分析和统计推断的相关理论,提出一种预测误差和统计处理综合法(Composition of Predictive Error and Statistic Treatment,简称CPEST),为依据客户自身行为一致性识别反洗钱异常情况这一重要的工作方式[6]提供了一个量化分析框架(如图1所示)。在该框架下,本文应用支持向量回归(Support Vector Regression,简称SVR)和核密度估计(Kernel Density Estimation,简称KDE),对实际交易和仿真数据进行实验,并与利用控制图识别异常的方法进行了比较,结果表明该方法是可行有效的,克服了常用方法的一些不足,具有推广应用价值。

图1 CPEST框架
2 问题的描述
洗钱分子的行为具有隐蔽性、智能性和流动性的特点,但绝大多数犯罪所得的“黑钱”都要通过银行等金融机构进行流转,在金融机构中必然留下大量的非法资金流动踪迹[7],所以可以通过分析交易信息来发现客户涉嫌洗钱等犯罪的蛛丝马迹。
本文研究针对一类典型的洗钱模式——客户以某种正常经营活动作为掩护,将非法所得混入正常经营收益进行清洗。这种洗钱模式属于常见典型的洗钱手法,例如《金融机构大额交易和可疑交易报告管理办法》第十一条(四)中规定的“平常资金流量小的账户突然有异常资金流入,且短期内出现大量资金收付”[8],即提示了这种模式的一类具体特征。针对这种洗钱模式的异常交易甄别需回答两个问题,一是客户交易行为是否有涉嫌洗钱的异常交易发生,二是如何对已经发现异常的时点或时段进行统计推断。例如,本文4.2中提及的B公司表面上开展正当经营,其在银行办理的交易大部分出于合法业务所需,但实际上却将少量涉及诈骗的非法经营混杂到日常活动中,因此需要分析人员根据整体交易记录对其行为是否存在异常做出判断,指出哪些交易异常,并对异常程度进行量化分析。
本文研究通过分析客户前后行为的一致性来发现异常。根据上述洗钱模式的固有特点,我们提出两方面假设:一是客户正常行为和异常行为所产生的交易时序,因内在机制(经营目的和经营方式等)不同,故可视为由不同动力系统产生;二是发生异常交易的客户,其正常交易行为仍占主导,异常交易仅为偶发行为,客户交易数据可被视为一个主体的动力系统产生的数据,被另一个动力系统在短时间内干扰。基于上述假设,我们认为CPEST在适当选取客户某一时段的交易数据作为训练集进行时序建模时,其中涉及异常交易的数据点相对少到可忽略不计,或者说可以通过利用这部分数据训练生成的模型来预测客户正常行为,即只要建模方法合理有效,CPEST建立的交易时序模型应能够对客户正常行为做出一定程度“准确”的预测,否则有理由怀疑客户行为可能发生了异常。
本文认为通过上述方法筛选出的异常交易还需经过分析人员进一步的人工识别,有合理理由怀疑与洗钱等犯罪行为相关后,才能作为可疑交易提交金融情报中心等单位。
3 CPEST模型
CPEST可分为三大部分:一是建立客户行为模型;二是根据客户行为模型的预测误差进行时点检验;三是基于时点检验结果进行窗口检验,指出具有洗钱嫌疑的时段。
3.1 建立客户行为模型
为排除自相关等系统非随机模式对异常判别的干扰[9],CPEST第一部分对客户行为进行建模预测。由于金融时序内在的噪声、非平稳性和混沌性,过短的金融时序难以预测,但长度足够的金融时序是可建模预测的[10],部分学者应用神经网络和支持向量机等方法已经取得了一定研究成果,例如在股指研究方面[11]。
3.1.1 客户行为特征属性时序
建立客户行为特征属性时序(以下简称“特征时序”)是对客户交易行为进行分析的基础。特征属性应能随时间推移反映客户行为在反洗钱所关注方面的性质,并可被量化表示,以便用于建立数学模型。由于反洗钱核心问题是判别被客户支配资金的合法性,所以应优先考虑与交易金额相关的行为属性,例如日(周)收款金额、日(周)付款金额、日(周)收付款总额、日(周)平均每笔交易金额等。在选定特征属性后,依据时间的推移采集相应数据即得到特征时序{kt}。
反洗钱工作对及时性要求没有一般的实时在线监测系统那么强,因此在建模时不仅可以按照从前往后的时间顺序构建特征时序,也可按照从后往前的时间顺序构建特征时序,以便增加一个分析视角。
3.1.2 基于相空间重构和SVR的非线性时序建模
利用非线性时序建模方法对标量时序进行分析的基础是重构与系统原相空间等价的相空间[12],此方面广泛应用的方法是延迟坐标相空间重构法。按照伪邻近点法和互息法[13]确定嵌入维数m和延迟时间τ后,根据特征时序{kt}可构建延迟向量:
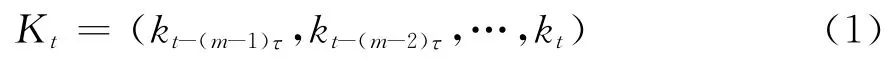
在特征时序具有混沌属性的假设下,该时序的一步预测可表示如下:

(2)式中映射M可选择神经网络、支持向量回归和多项式等。本文根据混沌系统建模的已有研究成果,采用目前应用较广的SVR解出M,原因是考虑到SVR有如下特性[14]:
1)只要选择适合的核函数,通过SVR得到的回归函数可以模拟输入变量和输出值之间的任意非线性关系;
2)SVR有较好的泛化能力;
3)SVR能够有效地处理高维数据。
SVR基本思想[15-16]是,给定训练数据{(x1, y1),…,(xl,yl)}⊂×,这里表示d维输入变量空间(χ=d)。SVR的目标是找到一个回归函数f(x)=ωTφ(x)+b,要求该函数尽量光滑,并且与训练集中目标值有最大为的误差(允许有一定的误差)。ω是高维特征空间F中的向量,φ(x)表示将x由映射到F中,ω和φ(x)可通过解下列优化问题求得:

其中,i=1,…,l,常数C表示f(x)光滑性与误差大于∈的数量之间的权衡取舍。为解决该问题引入拉格朗日乘子αi≥0≥0,μi≥0≥0,并求解下列拉格朗日函数的优化问题:

引入核函数k(x,x′)=φ(x)Tφ(x′)后,上述问题的对偶问题为对{αi}和},求下列函数最大化:
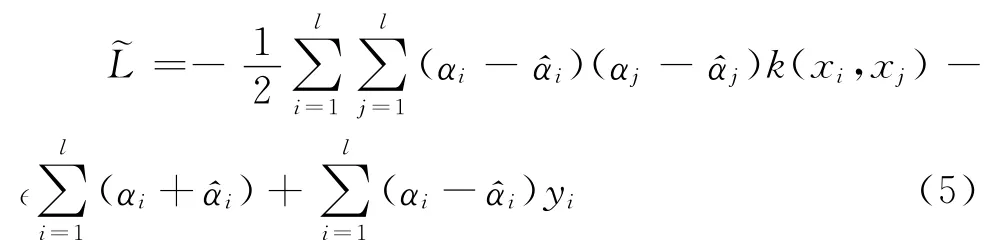
要求满足条件0≤αi≤C,其中i=1,…,l,并且。求得该问题的解{αi}和{}后,得到:
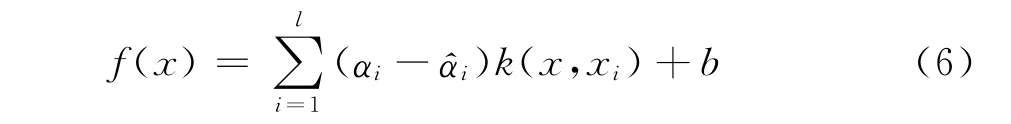
其中,对于每个样本xi,αi或(或者两者都)为0,当αi或不为0,即αi-≠0时,对应的样本xi称为支持向量。
在实际操作中,SVR参数∈和C的取值可通过交叉验证确定[15]。
3.1.3 特征时序建模预测流程
步骤1 由分析人员给出初始训练集容量s后,按时点顺序将{Kt}中的前s个元素作为初始训练集{Kt}train,将其余元素归入检测集{Kt}test。
步骤2 使用{Kt}train中的数据作为SVR的训练集{(xt,yt)}:xt=Kt,yt=kt+1,生成SVR模型M(x)。
步骤3 将{Kt}test中按时点顺序排在第一位的Kf作为SVR模型M(x)的输入值,得到一步预测f+1=M(Kf)。
步骤4 将Kf加入{Kt}train,并从{Kt}test中剔除Kf。如{Kt}test非空,则转步骤2,否则建模预测结束。
3.2 异常交易的时点检验
为利用客户行为模型预测误差对客户行为是否异常做出合理判断,CPEST第二部分将判断客户行为在一个时点是否异常的问题转化为一个假设检验问题。首先提出如下假设:
H0:客户交易行为在时点t正常
然后将et=|kt-|作为预测误差ξ的观察样本,并对如何根据时点t的样本et对客户行为进行时点检验做出规定:分析人员事先给定预设值α,当概率Pr(ξ>et)<α时,则认为客户行为在时点t存在异常,此时否定H0。按照这种方式对客户行为进行检验,必须先解决两个问题:一是估算概率Pr(ξ<et),二是合理给出预设值α。
由于没有依据认定ξ总是符合正态分布等某一特定参数分布,这给分析带来很大难度,因此本文提出使用现代统计学一项重要的新成果——KDE,对ξ的概率密度函数进行估计。KDE是一种非参数检验方法[17],设x1,x2,…,xn为变量ξ的样本,ξ的概率密度函数f(x)的KDE定义为:
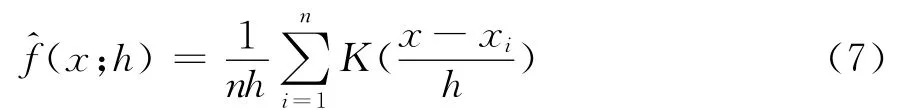
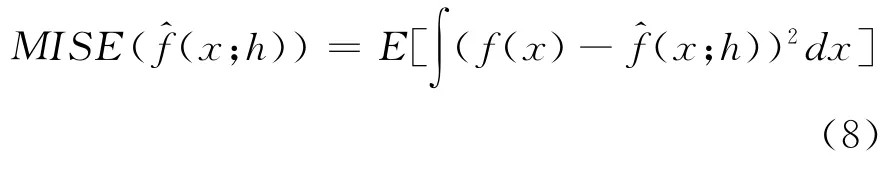
由于α可作为该假设检验犯第一类错误概率的估计,即客户在时点t行为实际正常,但经过检验后被判定为异常的可能性,因此分析人员可以依据这一点给出适当的预设值。
3.3 异常交易的窗口检验
为了进一步提高异常交易识别能力,CPEST第三部分在时点检验的基础上构造了一个窗口检验,考察包含连续M个时点的窗口内客户交易行为是否存在异常。在上述时点检验的基础上,分析人员可选择通过该窗口检验,将对异常交易的关注时间单位由时点扩大到时段。窗口检验首先定义一个长度为M的窗口:
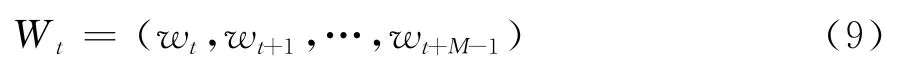
其中,wt表示客户行为在时点t的时点检验结果,当被判定为异常时wt为1,否则为0。
定义|Wt|为窗口对应的时段内被时点检验判定为异常的时点个数之和:

窗口检验提出如下假设:
H0:客户交易行为在窗口Wt内正常
基于窗口内时点检验结果,对窗口检验做出规定:分析人员事先给定预设值γ,M和^α,当概率Pr(| Wt|>γ)<^α时,则认为客户行为在该窗口内存在异常行为,此时否定H0。
与时点检验相同,由于^α可作为窗口检验犯第一类错误概率的估计,即客户在窗口内行为实际正常,但经过检验后被判定为异常的可能性,因此分析人员可以依据这一点给出适当的预设值。
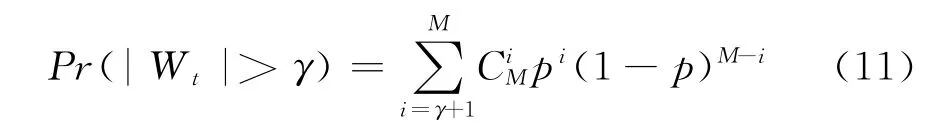
4 CPEST算例
为说明CPEST应用于实际数据的效果,本文选取低洗钱风险的某A公司和因涉嫌诈骗洗钱罪被查处的某B公司作为算例进行分析。利用二者符合《金融机构大额交易和可疑交易报告管理办法》规定的大额交易建立特征时序,并按照下式进行归一化处理[18]:

其中,zt为原始特征时序,kt为归一化后的时序,L为时序长度。根据伪邻近点法和互息法确定m和τ后,按照(1)式进行相空间重构,得到延迟向量集{Kt}。
分别应用CPEST的窗口检验和独立的时点检验对上述时序进行分析。关于窗口检验,分析人员给出的预设值^α为0.01,γ为2,M为5,与对应的窗口内时点检验的预设值为0.1056。关于独立的时点检验,分析人员给出的预设值α为0.005。这里和α的取值基于本文3.2和3.3中的讨论,γ和M的取值则主要是根据分析人员的工作经验。
4.1 算例1:低洗钱风险企业的数值分析
选取A公司2008年底至2011年初的大额交易记录,根据交易频繁程度,取日交易总金额作为客户行为特征属性,按照时间前后顺序采集得到包含594点数据的特征时序,初始训练样本集容量为300。根据伪邻近点和互息法得到的嵌入维数m为5,延迟时间τ为2。
表1列出了A公司的窗口内时点检验中,满足Pr(ξ>et)<的时点所对应的被检测样本序号t、预测误差et(简称受关注预测误差,下同)和事件ξ>et的概率。由于α<p,该结果包含了独立的时点检验满足Pr(ξ>et)<α的时点。从表1中可以看出,被检验的时序中没有被判断为存在异常的窗口,但时点249被独立的时点检验判断为异常,需进行人工分析。

表1 A公司受关注预测误差及相关概率密度
参照《金融机构大额交易和可疑交易报告管理办法》对可疑交易模式的定义,在A公司的实际交易数据中加入仿真的异常交易数据:将检测集中第41时点的日交易总金额增加样本数据最高日交易总金额的50%,将第69、70和71时点的日交易总金额分别增加样本数据最高日交易总金额的25%。表2列出了A公司加仿真数据后检验中受关注的预测误差及相关概率密度。从表2中可以看出,时点67至时点73的时段被窗口检验判断为存在异常,时点41被独立的时点检验判断为异常,需进行人工分析。
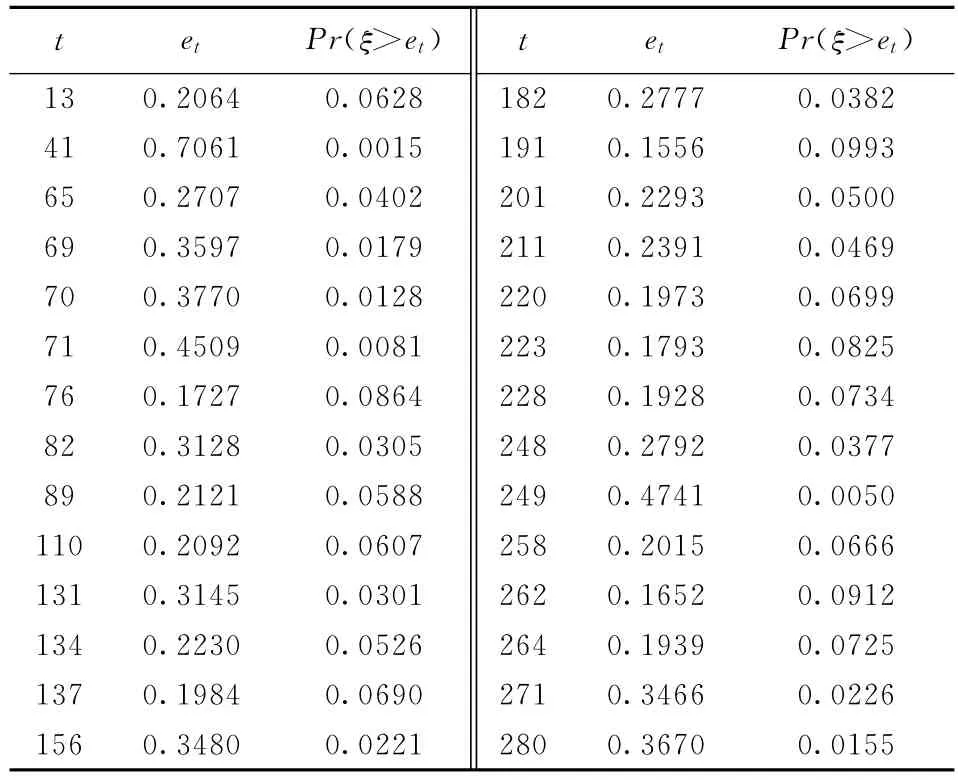
表2 A公司加仿真数据后受关注预测误差及相关概率密度
4.2 算例2:涉嫌疑犯罪企业的数值分析
选取B公司2008年前后的大额交易记录,根据交易频繁程度,取日交易金额总额作为客户行为特征属性,按照时间前后顺序采集得到包含347点数据的特征时序,初始训练样本集容量为100。根据伪邻近点和互息法得到的嵌入维数m为5,延迟时间τ为2。
表3列出了B公司检验中受关注的预测误差及相关概率密度。从表3中可以看出,客户行为在时点156至时点162和时点199至时点203的两个时段被窗口检验判断为存在异常,时点159,213被独立的时点检验判断为存在异常,需进行人工分析。
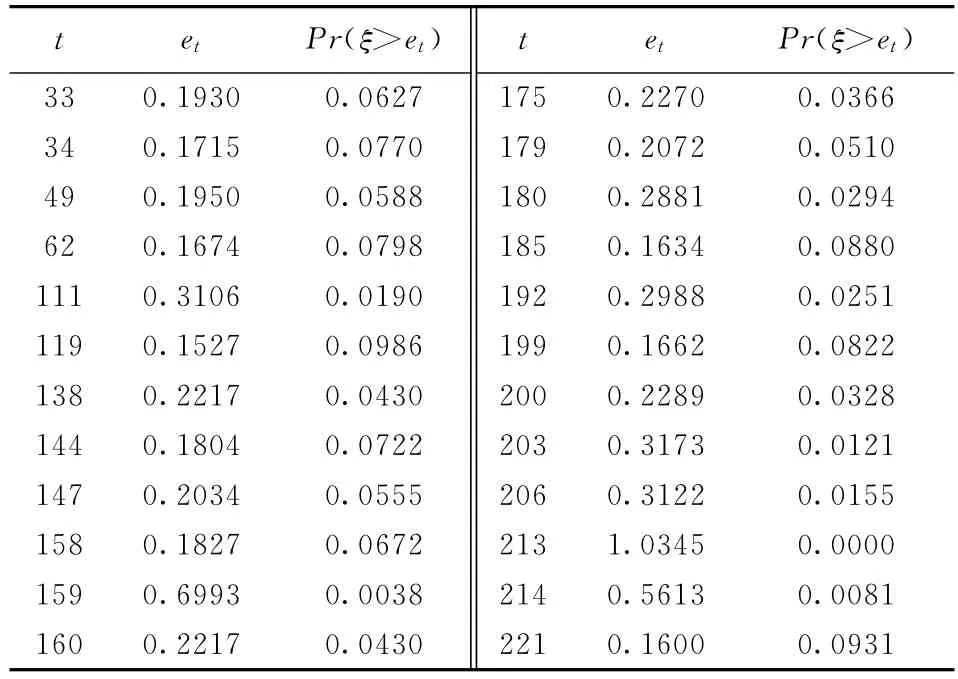
表3 B公司受关注预测误差及相关概率密度
4.3 与利用控制图识别异常方法的比较
为进一步考察CPEST的实际功效,本文通过实验,将其与原理相似的利用控制图识别异常[9,19]的典型方法(简称控制图法)进行了比较。统计过程控制中控制图法的通常流程是,先建立时序模型对数据进行预测,得到预测误差集合{et};然后将预测误差分为前后不重合的两部分,包含N个数据的第一部分用于计算上、下控制限:

两种方法对多个案例的实验结果表明,在合理设置参数的前提下,控制图法虽然对部分案例也能做出与实际情况基本相符的结论,但对A公司交易加仿真数据等案例的检验效果不如CPEST。控制图方法相较CPEST有以下两点突出的不足:
(1)控制图法的前提是预测误差符合正态分布,但B公司等算例的预测误差不满足正态分布,会表现出偏态,厚尾和缩尾的现象,因而不满足控制图方法的适用条件。
(2)如果用于计算上、下控制限的预测误差集中包含异常数据,则可能会致使上、下控制限发生改变,导致控制图法漏检部分异常数据。例如,在对A公司交易加仿真数据的实验中,将时点41的预测误差放入计算控制上限的预测误差集合中后,导致上控制限偏大,影响到了对时点69的检出。
4.4 实验结果分析
两类企业的数值分析结果与其是否涉嫌洗钱的实际情况基本吻合,表明了CPEST的可用性。通过算例可以看出,该方法可以辅助分析人员提高工作效率,一方面该方法可以减轻人工分析工作量,对于低洗钱风险的客户交易进行分析时,该方法合理缩小人工分析的关注范围,例如上述算例1中分析人员只需要对客户294天交易情况中的1天进行人工分析;另一方面,该方法能够识别涉嫌犯罪或高洗钱风险客户历史交易中的相对异常部分,给分析人员提供进一步分析的切入点。此外,该方法还克服了控制图法的某些缺陷,有更广的适用性。
需指出的是,关于CPEST误报率和漏报率的分析,目前受限于缺少足够样本而不宜草率做出结论,这方面需要今后在条件允许情况下进行深入的研究。
5 总结
本文根据反洗钱监测分析工作需要提出一种新的异常交易识别方法——CPEST,该方法能够帮助分析人员摆脱耗时费力到近乎不可能完成的“对客户历史交易逐笔分析”的困境,有效提高监测分析工作的效率。该方法的理论意义包括:一是为非线性时序分析和统计推断在反洗钱异常交易行为识别研究中的有机结合提供了一个框架,后续研究工作可以在这个框架下进行深化,例如考虑使用SVR之外的其它非线性模型;二是运用核密度估计方法,在没有样本母体正态分布的假设下,构造了异常交易的统计假设检验(时点检验和窗口检验),为异常交易的量化分析提供了新的研究思路。该方法仍需结合
实际工作进一步完善的方面包括误报率和漏报率,以及如何确定模型中的参数等。最后仍需强调的是,客户身份识别和人工分析在当前可疑交易甄别中的重要性是不可替代的,在使用数据挖掘技术时也必须注意与分析人员的交互,这不仅是时序预测等方法成功应用于实际情况的需要[20],也是反洗钱工作的内在要求。
[1]欧阳卫民.正确理解新的大额和可疑资金交易识别标准[J].中国金融,2007,(16):64-65.
[2]中国人民银行反洗钱局.中国反洗钱报告(2010)[M].北京:中国金融出版社,2011.
[3]汤俊,熊前兴.基于时序相似度的离群模式检测模型[J].武汉大学学报(工学版),2006,39(3):111-114.
[4]Liu Xuan,Zhang Pengzhu,Zeng Dajun.Sequence matching for suspicious activity detection in anti-money laundering[M]//Mehrotras,zeng DD,chen H C.Intelligence and Security Informatics.Berlin:Springer Verlag, 2008:50-61.
[5]喻炜,王建东.基于交易网络特征向量中心度量的可疑洗钱识别系统[J].计算机应用,2009,29(9):2581-2585.
[6]汤俊.基于客户行为模式识别的反洗钱数据监测与分析系统[J].中南财经政法大学学报,2005,(4):62-67.
[7]欧阳卫民.我国反洗钱若干重大问题(下)[J].财经理论与实践,2006,27(142):2-9.
[8]苏宁.反洗钱法规实用手册[M].北京:中国金融出版社,2007.
[9]Alwan L C,Roberts H V.Time-series modeling for sta-tistical process control[J].Journal of Business and Economic Statistics,1988,6(1):87-95.
[10]Tay F E,Cao L.Application of support vector machines in financial time series forecasting[J].International Journal of Management Science,2001,29(4):309-317.
[11]Krollner B,Vanstone B,Finnie G.Financial time series forecasting with machine learning techniques:A survey[C].Proceedings of 18th European Symposium on Artificial Neural Networks Computational Intelligence and Machine Learning,Bruges(Belgium),April 28-30,2010.
[12]Packard N H,Crutchfield J P,Farmers J D,et al.Geometry from a time series[J].Physical review letters, 1980,45(9):712-716.
[13]Small M.Applied nonlinear time series analysis[M]. Singapore:World Scientific,2005.
[14]Ma Junshui,Perkins S.Online novelty detection on
temporal sequences[C].Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington D C,OSA, August,24-27,2003.
[15]Bishop C M.Pattern recognition and machine learning [M].New York:Springer,2006.
[16]Smola A J,Scholkopf B.A tutorial on support vector regression[J].Statistics and Computing,2004,14(3):199-222.
[17]Wand M P,Jones M C.Kernel smoothing[M].London:Chapman and Hall,1995.
[18]孟庆芳.非线性动力系统时间序列分析方法及其应用研究[D].济南:山东大学,2008.
[19]Stone R,Taylor M.Time series models in statistical process control:Considerations of applicability[J].The Statistician,1995,44(2):227-234.
[20]Ma Junshui,Perkins S.Time-series novelty detection using one-class support vector machines[C].Proceedings of the International Joint Conference on Neural Networks,IEEE,Portland,Oregon,USA,July 20-24,2003.
An Approach for Unusual Transaction Detection Based on Customer Behavior Time Series Analysis
LIU Zhuo-jun1,LI Xiao-ming1,2
(1.Academy of Mathematics and Systems Science,Chinese Academy of Sciences,Beijing 100190,China;2.University of Chinese Academy of Sciences,Beijing 100049,China)
The suspicious transaction reporting system is the principle mechanism to fight against money laundering,and it is a technical problem to detect suspicious transaction for financial institutions and the financial intelligence unit.To help anti-money laundering analysts screen customers′unusual transactions and behaviors in massive financial transaction information,a new method,composition of predictive error and statistic treatment(CPEST)is presented,which can be used to detect unusual behaviors from the inconsistency of customer behaviors.CPEST models a customer′s behavior,tests a customer′s behavior at a particular time using estimated errors,and uses a window test to improve the ability to identify suspected of money laundering.Applying the method based on support vector regression and kernel density estimation to real data examples and simulations,the experiment results suggest that the method,which is feasible and effective,has high value in popularization and application.
anti-money laundering;anomaly detection;time series;support vector regression;kernel density estimation
C931
A
1003-207(2014)12-0102-07
2012-05-30;
2013-07-01
国家科技支撑计划项目(2013BAK04B02-02)
刘卓军(1958-),男(汉族),黑龙江人,中国科学院数学与系统科学研究院,研究员,研究方向:系统安全.
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
中国农业信息(2021年3期)2021-11-22 06:44:48
中国集体经济(2020年31期)2020-11-28 07:34:34
北方文学(2018年18期)2018-09-14 10:55:22
职工法律天地·下半月(2016年4期)2017-05-31 17:41:04
山西广播电视大学学报(2017年1期)2017-02-21 09:46:39
电子制作(2016年15期)2017-01-15 13:39:08
上海国资(2015年8期)2015-12-23 01:47:28
股市动态分析(2015年13期)2015-09-10 07:22:44
小猕猴智力画刊(2015年1期)2015-05-30 09:43:18
