
基于Hadoop的K—Means聚类算法在高校图书馆工作中的应用研究
2014-09-18 11:05李萍
大学图书情报学刊 2014年5期
李 萍
(北京师范大学珠海分校,519087)
引言
数据挖掘是数据库和人工智能领域的热点问题。由于计算机、信息技术和网络技术的不断发展,信息量以及数据种类也不断增多,网络中存在着各种结构模式的数据以及丰富甚至冗余的信息。云计算的出现,为数据挖掘提出了新的计算方式。Hadoop是一个用于构建云计算平台的Apache开源项目,现在已经应用于很多领域。在Hadoop计算平台上,用户可以方便地使用该项目提供的并行编程模型和计算框架,还有可以提供高吞吐量数据访问的分布式文件系统,以及实现多种机器学习与数据挖掘的算法库。随着图书馆事业的发展,用户对图书馆资源的使用提出了越来越高的要求,为读者提供有针对性的服务,成为图书馆发展中所面临的具体任务之一。有效地使用数据挖掘技术,可以从庞杂无序的数据中提取出重要的、可供参考的信息,为图书馆的管理工作和个性化服务提供有效的技术支持。
1 关于Hadoop
Hadoop由2002年开始的项目Apache Nutch发展而来,现在已经成为Apache软件基金会名下的一个开源分布式计算平台。至2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上发表了重要的文章,其设计理念使Doug Cutting等人深受启发,并且尝试开发Map/Reduce编程模型。为了能够支持Nutch引擎的主要算法,他们还将Map/Reduce与Nutch Distributed File System(NDFS)相结合 。2006年初,开发人员将NDFS和Map/Reduce这两个子项目从Nutch移出,并且将二者充分结合,形成了一个独立而且全面的子项目,取名 Hadoop。同期,Doug Cutting加入了雅虎公司,该公司为其组织了专门的科研团队和资源,将Hadoop逐步开发成了一个可以灵活处理Web数据的系统。随着越来越多用户的加入以及云计算和大数据的发展,从2009年开,Hadoop作为海量数据分析的最佳解决方案,受到许多IT厂商的关注,从而出现了Hadoop的商业版和支持Hadoop的软件以及硬件产品。
1.1 Hadoop的特点
Hadoop是一个能够对大量数据进行分布式处理的计算平台,突出的优点有:(1)具有非常高的可靠性。对于计算元素以及存储失败这些特殊情况的处理,设计人员均已经在设计之初就考虑到了,Hadoop被设计为能够自动的、分时的保存多个数据副本,通过这一特点,能够充分地做到对失败节点的重新分布;(2)具有高效性。Hadoop可以在各个节点之间,以动态传递数据的方式,来保持每个节点工作时的动态平衡。它实现加快处理速度的方式,是靠并行处理方式来完成的;(3)具有非常强的可伸缩性。Hadoop利用计算机集群各个节点的分布优势,可以随时将节点规模扩展到需要的节点集群规模。根据数据存储的物理条件,它可以在集群各点上分配数据,完成处理工作,以至于可以达到处理PB级数据的工作要求;(4)使用成本较低,其普遍适用性的民众基础较广泛;(5)Hadoop能够很好地在Linux操作系统上运行,其自身带有用Java语言编写的运算框架,可以使它很稳定地运行。其应用程序当然也可以用C++等语言来编写、运行。
1.2 Hadoop子项目
Hadoop是一个分布式计算基础架构,它由多个子项目构成,分别提供不同的配套服务。其中,Map/Reduce并行编程模型以及HDFS分布式文件系统这两个子项目是最有特色的。Hadoop各组件如图1所示。
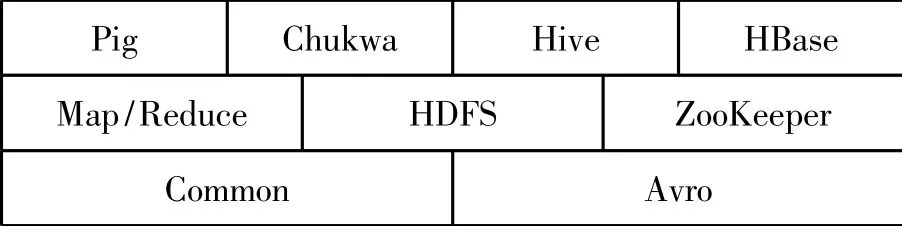
图1 Hadoop组件图
以下对Hadoop架构中的子项目进行简单介绍:
(1)Map/Reduce是分布式数据处理模式和执行环境。它的组件提供Map和Reduce处理,主要用于大规模数据集的并行运算;(2)HDFS是分布式文件系统,其前身是NDFS。它是适合在通用硬件上运行的分布式文件系统,具有高容错性;(3)Common是系列分布式文件系统和通用I/O的组件及接口。由 Hadoop 0.20版本诞生开始,Core/Common就统一更名为Common。它的主要作用就是给Hadoop其他的子项目提供必要的、能够支持的、最常用的工具。该子项目的内容有File System、RPC以及串行化库。就算是只有低硬件配置的计算机群组也能够搭建云计算环境,提供了基本的运算与传输数据服务,并且为运行在该平台上的软件开发提供了所需的API;(4)Avro是用于数据序列化的系统。它提供了多种数据结构类型,快速可压缩的二进制数据格式,存储持久性数据的文件集,远程调用RPC,动态语言集成功能;(5)Pig是一个对大规模数据进行分析和评估的平台。其突出优势是它的结构能够经受高度并行化的检验,适用于处理大型的数据集;(6)HBase数据库。它的存储方式是分布式的列存储模式,主要以HDFS为基础,能够充分应用于分布式数据处理;(7)Zookeeper是一个针对大型分布式系统,可用性高的协调系统。主要用于构建分布式应用,所提供的功能有:配置维护、名字服务、分布式同步、组服务等;(8)Hive是一个基于Hadoop的数据仓库工具。它主要管理HDFS中存储的数据,并且提供完整的SQL查询功能,可以实现将SQL语句转换为Map/Reduce任务进行运行,方便Map/Reduce编程人员进行Hadoop应用的开发;(9)Chukwa的作用主要是收集分布式数据,并且做出相应的分析系统。
1.3 Hadoop的Map/Reduce并行编程模型
Map/Reduce主要用在搜索引擎能够提供后台的网页索引处理上面,还有应用程序和数据处理方面,这种计算框架能够很好地应用于处理海量数据。Map/Reduce这种设计模式非常方便软件工作者编写分布式并行程序。
Map/Reduce并行编程模型的处理过程是:针对大规模的数据集操作,首先是分发到同一个主节点负责下的每个独立分节点上一起完成,然后收集各分节点上产生的中间结果,经过整合,最后得到结果。Map/Reduce的处理过程分为Map过程和Reduce过程,这两个过程被抽象为相应的Map函数和Reduce函数。其中,Map和Reduce这两个概念的主要思想取自于函数式编程语言和矢量编程语言。其中,Map过程负责将任务分解成为多个子任务,便于各节点独立工作;Reduce过程主要是将各节点分解后的多任务处理的结果汇总起来。Map/Reduce在非常大的程度上为编程人员在不会分布式并行编程的条件下,在分布式系统上运行自己设计的程序提供了便利。Map/Reduce处理大数据集的过程如图2所示:
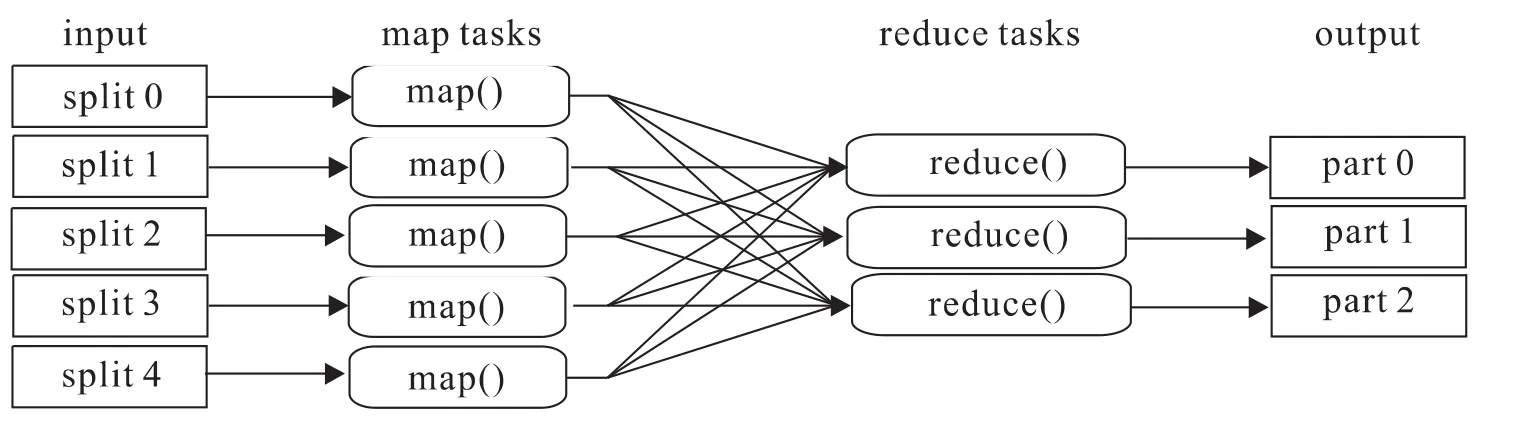
图2 Map/Reduce处理大数据集的过程
Map/Reduce的Map阶段中,任务的输入数据被分割成若干固定大小的片段(splits),继续将分解后的每一个split再分解成为若干〈键,值〉对,表示为〈K1,V1〉。Hadoop将会对每一个split创建一个Map任务,来执行用户根据具体需要自定义的map函数。函数的输入是函数对应的split中初始的〈K1,V1〉对,经过计算,得到中间结果,表示为〈K2,V2〉。然后对这些中间结果依据K2开始排序,再按照相同key值的条件下,对value值进行分组,结果统一在一起形成新的列表,表示为 <K2,list(V2)〉元组。最后还需要将这些元组按照key值的范围进行分组,分组结果将对应不同的 Reduce任务。
Map/Reduce的 Reduce阶段中,首先,不同的Mapper接收来的数据由Reduce进行整合后排序;然后,调用用户根据具体需求自己设计的reduce函数;其次,处理输入的〈K2,list(V2)〉对;最后,得到结果,表示为〈K3,V3〉对。将结果输出到HDFS上。
2 基于Hadoop的k-means算法
数据挖掘(Data Mining,DM),也可以认为是数据库中的知识发现(KnowledgeDiscoverin Database,KDD),主要是提取出隐含在庞大的、残缺的、充满噪声的、不明确的、随机的实际应用中的数据,以及人们事先不知道的,却又是潜在的、有用的信息和知识的过程。人们可以通过数据挖掘技术从数据库中存储的各类数据中提取出规律以及有用信息等;同时还可以帮助人们根据各种需求来分析这些规律、信息等。数据挖掘技术不但可以记录数据的形成以及使用的过程,而且能够进一步预测发展趋势。
2.1 聚类分析
聚类分析(cluster analysis)是一种探查数据结构的工具。聚类分析的核心是聚类,也就是将数据对象首先划分为簇,最后得到同一个簇内的所有的对象都相似,而不同簇的对象都是相异的。通过某些度量或与其他对象的关系都可以来描述所有对象。聚类不需要以先验标识符来标定数据类别的假定。
K-means聚类算法是一种非常经典的基于划分的聚类方法。这种聚类方法是一种局域原型的目标函数聚类方法,它的目标函数是数据点到原型的某种距离作为优化,使用目标函数求极值的方法找到迭代运算的调整规则。K-means算法采用欧式距离作为相似性的评价指标,也就是说相似度与两个对象的距离成正比,距离越近则似度就越大。K-means算法的聚类准则函数采用了误差平方和准则函数。该算法是求对应某一初始聚类中心向量V的分类,在不断地迭代过程中,不间断地将距离靠近的对象组成簇,使得评价指标J最小,从而得到最终的结果,也就是紧凑且独立的簇。此过程可以从算法公式清楚地看出来。所以说,K-means算法是一种硬聚类算法。算法公式如图3所示。
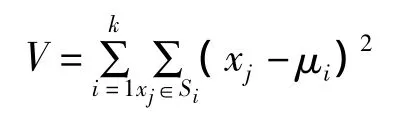
图3 K-means算法公式
K-means聚类算法的第一步需要选取任意k个对象作为初始聚类的中心,该选取过程是随机的,但中心点的选取在很大程度上影响聚类的结果。一次迭代运算是根据数据集中剩余的每个对象与各个簇中心的距离,将对象重新赋给最近的簇。如此反复,将所有的数据对象考察完后,该次迭代运算结束,继而计算出新的聚类重心。算法收敛的标志是一次迭代前后,J的值没有发生变化。K-means聚类算法过程如图4所示,其具体过程简述如下:
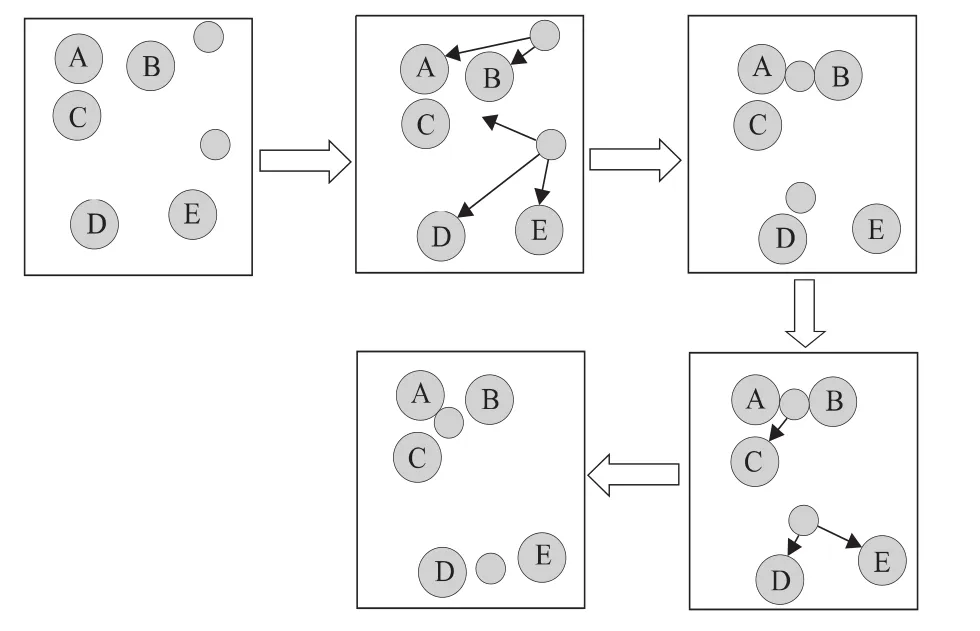
图4 K-means算法过程
2.2 K—means聚类算法并行分析
在Mahout的聚类分析计算过程中,数据需要转化成向量的方式来表示,在Mahout中的接口是org.apache.mahout.math.Vector,每一个域用一个浮点数(double)来表示,通过继承 Mahout里的基类AbstractVector,来实现有关向量的很多操作。一共有三种表示方式:
(1)DenseVector位于 mahout—math文件夹下的src/main/java中的package:org.apache.mahout.clustering.math中,是以一个浮点数数组(private double[]values)来实现,对向量里所有域都进行存储,适合用于存储密集向量。
(2)RandomAccessSparseVector位于 mahoutmath文件夹下的src/main/java中的package:org.apache.mahout.clustering.math中,是基于浮点数的HashMap实现,其中key是整形 (int)类型,value是浮点数(double)类型,它只存储向量中不为空的值,并提供随机访问。
(3)SequentialAccessSparseVector位于mahoutmath文件夹下的src/main/java中的package:org.apache.mahout.clustering.math中,key是整形类型,value是浮点数类型,用一个int数组存储indices,用double数组存储非零元素的并行数组来实现,只存储向量中不为空的值,并且只提供顺序访问。要想读/写某个元素,需要在indices中查找offset,由于indices是有序的,所以查找操作用的是二分法。
在K-means算法中,所有做聚类分析的数据对象会被描述成n纬空间中的一个点,用向量表示;算法开始会随机选择K个点,作为簇的中心,然后其余的点会根据它与每个簇心的距离,被分配到最近簇中去;接着以迭代的方式,先计算每个簇的中心,再对所有点属于哪个簇进行重新划分;如此迭代直到收敛;迭代次数是有限的。K-means算法简单且高效,但存在一些问题。K值是人为确定,给出较合理的K值有一定难度;随机选择初始簇心存在可能会选到较孤立的点,进而对聚类的结果产生很大影响。
Mahout的K-Means聚类算法有两个Map操作、一个Combine操作和一个Reduce操作,每次迭代都用1个Map、1个 Combine和1个Reduce操作得到并保存全局Cluster集合,迭代结束后,再用一个Map进行聚类操作。可以在Mahout-core下的src/main/java中的package:org.apache.mahout.clustering.kmeans中找到相关代码。如图5所示:

图5 代码图
从目录结构角度看,需要两个输入目录:其中一个用于保存数据点集input,另外一个用来保存点的初始划分clusters;在形成clusters集合的阶段,每次迭代会生成一个新的目录,上一次迭代的输出目录将会作为下一次迭代的输入目录,这种目录的命名为:Clusters+‘迭代次数’;聚类点的最终结果会放在clusteredPoints文件夹中,而Cluster信息放在Clusters+‘最后一次迭代次数’文件夹中。
K-Means聚类算法的Map/Reduce实现,用了2个Map操作、1个Combine操作和1个Reduce操作,通过两个不同的JobTracker触发,用Dirver来组织的,Map/Reduce执行顺序图如图6所示:

图6 K-Means算法的Map/Reduce执行顺序
3 K-means聚类算法在图书馆中的应用
本实验基于Hadoop平台使用K-means聚类算法,对图书馆的图书借阅数据进行挖掘。对图书的使用率进行三类划分,分别为高使用率的图书、中使用率的图书和低使用率的图书。通过实验结果提出一些指导日常工作的建议和措施。
本实验中所使用的数据取自北京师范大学珠海分校图书馆所使用的图书管理系统。数据统计时间为2012年3—6月,10-12月(剔除寒、暑假期以及非整月数据),共计10万条左右的图书外借和阅览数据。其中,图书阅览数据是图书馆内各阅览室日常的上书统计数据。挖掘、分析图书借阅数据,可以有效及时地判断读者的阅读需求,进而推出个性化读者服务,为更加合理安排图书馆的日常工作提供数据依据。
该实验算法中距离定义的方式采用了欧式距离作为分组依据,使用快速聚类方法完成整个聚类过程。其中类的数目指定为3。将这些参与借阅的图书分为高使用率图书、中使用率图书和低使用率图书三种。实验中所用算法的部分核心代码如下所示:


由实验结果汇总得出:特定时间内,三类被借阅图书的百分比。如图7所示:

图7 聚类结果示意图
对于不同使用率级别的图书数据分析,图书馆可以及时做出相应的工作调整,来满足读者的需要,进一步提升图书馆的服务质量。以下针对实验结果,提出一些切实、可行的工作建议:
(1)对于高使用率的图书,馆员在工作中及时调整此类图书的复本数量;缩短购书周期;增加阅览室相关架位的安置;增加日常图书维护工作;增加不同载体图书的购入比例等;(2)对于使用率一般的图书,馆员需要及时调整图书宣传策略和宣传力度;及时调整购买不同载体类型图书的经费比例;控制此类图书馆藏增长率的同时,提高图书学术质量等;(3)对于低使用率的图书,馆员需要及时审核图书的学术质量;降低图书复本量;调整纸质版图书和电子版图书的购买比例;阅览室内可以适当减少对此类图书的日常读架、整架工作;适当调整图书的架位预留量等。
3 结语
随着社会的发展,信息技术的不断提高,图书馆的信息服务能力也得到了进一步的提升。同时,图书馆的采编部、流通部、参考咨询部等各部门的业务对信息的发现、使用、提供等方面的需求也不断增多。为了满足工作的需要,图书馆必须提高处理信息的能力以及组织信息资源的能力。为了不断满足读者的个性化需求,图书馆必须具备对大量数据深层次开发的能力,并进行及时、准确、有效地预测,才能够推出合理的特色服务。数据挖掘技术可以对图书馆现有的各种数据进行充分地挖掘,了解读者信息需求的同时,不断满足其个性化信息需求。图书馆是组织、传递知识和信息的服务机构,其信息服务能力的程度直接依赖于各种信息技术的发展水平。云计算技术的发展为图书馆服务以及图书馆信息数据的处理开启了新的篇章,在扩大图书馆发展空间的同时,不断完善图书馆信息服务功能。
[1]朱 明.数据挖掘导论[M].合肥:中国科学技术大学出版社,2012.2.
[2]孙健波.数据挖掘技术在高校图书馆中的应用[D].南京:南京理工大学,2009.
[3]亢丽芸.基于Heritrix与Hadoop的海量网络学术文献获取及并行处理研究[D].山东:山东理工大学,2012.
[4]李贤虹.基于数据挖掘的读者个性化信息服务系统的研究与设计[D].南昌:南昌大学,2009.
[5]刘 力.长期演进系统下入侵检测关键技术的研究[D].南京:南京航空航天大学,2009.
[6]聂 云.数据挖掘在电信客户挽留中的应用[D].北京:北京邮电大学,2011.
[7]百度文库.聚类算法[EB/OL].http://wenku.baidu.com/view/bac5c4c5d5bbfd0a7956730c.html.
[8]王燕霞.基于相关主题模型的文本分类方法研究[D].苏州:苏州大学,2010.
[9]李 琳.基于粗糙集和遗传算法的聚类方法研究[D].桂林:广西师范大学,2009.
[10]百度文库.聚类算法介绍[EB/OL].http://wenku.baidu.com/view/9807b20f4a7302768e9939f7.html.
[11]关 庆.增强的软子空间聚类技术的研究[D].无锡:江南大学,2011.
[12]纪晓东.物流基地选址辅助决策的研究与实现[D].武汉:武汉大学,2005.
[13]王晓明.基于分类预测技术的软件成本估算方法的研究与应用[D].北京:国防科学技术大学,2010.
[14]孙德全.数据库的负载自动识别及自管理技术研究[D].北京:中国石油大学,2007.
[15]百度文库.决策主要分类方法介绍[EB/OL].http://wenku.baidu.com/view/eb54238acc22bcd126ff0cc6.html.
[16]罗志磊.决策树方法在高考志愿分析中的应用研究[D].郑州:决策树方法在高考志愿分析中的应用研究,2007.
[17]陈小辉.基于数据挖掘的入侵检测技术研究[D].南京:南京理工大学,2008.
[18]张明辉.基于Hadoop的数据挖掘算法的分析与研究[D].昆明:昆明理工大学,2012.
[19]李 倩.基于MapReduce模型的eMTM三维人体模型生成引擎[D].上海:东华大学,2012.
[20]谭 斌.基于服务的数据挖掘关联规则技术的研究[D].武汉:湖北工业大学,2012.
[21]博客频道-CSDN.NET.Hadoop简介-Hello World![EB/OL].http://blog.csdn.net/shanliangliuxing/article/details/7940664.
[22]于 翔.虚拟技术降低分布式存储系统部署成本[J].中国教育网络,2012,(4).
[23]百度文库.Hadoop中HDFS的实现代码分析[EB/OL].http://wenku.baidu.com/view/59425aeb 19e8 b8 f67 c1cb9c0.html.
[24]姜 文.基于Hadoop平台的数据分析和应用[D].北京:北京邮电大学,2011.
[25]陆颖隽,郑怡萍,邓仲华.美国图书馆的云服务[J].图书与情报,2012,(6).
[26](印度)西蒙.数据挖掘基础教程[M].北京:机械工业出版社,2009.1.
[27]刘 刚.Hadoop开源云计算平台[M].北京:北京邮电大学出版社,2011.8.6.
[28]孙 坦,黄国彬.基于云服务的图书馆建设与服务策略[J].图书馆建设,2009,(9):1 -6.
[29]陆嘉恒.Hadoop实战[M].北京:机械工业出版社,2011.9.
[30]刘 鹏.实战Hadoop:开启通向云计算的捷径[M].北京:电子工业出版社,2011.9.
[31]邓纳姆.数据挖掘教程[M].北京:清华大学出版社,2005.5
猜你喜欢
大众投资指南(2021年35期)2021-02-16
铁道通信信号(2019年6期)2019-10-08
综艺报(2019年5期)2019-03-18
电力与能源(2017年6期)2017-05-14
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
信息通信技术(2015年6期)2015-12-26
汽车文摘(2015年11期)2015-12-14
电子设计工程(2015年6期)2015-02-27
中国社区医师(2015年10期)2015-01-27
