
基于用户兴趣度的垃圾邮件在线识别新方法*
2014-08-16 07:59王友卫刘元宁凤丽洲朱晓冬
华南理工大学学报(自然科学版) 2014年7期
王友卫 刘元宁 凤丽洲 朱晓冬
(吉林大学 计算机科学与技术学院,吉林 长春 130012)
随着网络技术的迅速发展,电子邮件已成为人们日常生活中重要的通信手段之一.日益增长的垃圾邮件常常附载大量虚假甚至危害社会稳定与安全的信息.垃圾邮件在线识别具有区别于传统文本分类的特点[1-2]:①识别过程需根据用户兴趣进行,同一封邮件在不同用户甚至处于不同阶段的相同用户眼中可能得到不同的分类结果;②邮件识别属于在线应用,因此对处理速度要求比较高;③在线邮件数量众多、种类复杂,难以通过传统人工标注形成通用的训练样本集.因此,如何有效解决以上问题成为垃圾邮件在线识别的首要任务.
增量学习方法已被广泛应用于垃圾邮件在线识别[3].与传统方法相比,增量学习可以充分利用历史学习结果,在不显著降低样本识别精度的前提下,减少训练时间及传统人工标注工作量.Syed 等[4]结合支持向量机(SVM)提出了Batch SVM 方法,该方法将增量样本集与训练集中支持向量集合并形成新的训练集,对训练集中的冗余样本处理过于简单,导致识别精度不高.王学军等[5]将SVM 和主动学习结合起来,通过在增量学习过程中选择正类样本构造新的最优超平面;该算法能准确识别正类样本,但针对负类样本的识别精度较低.刘伍颖等[2]根据用户反馈构建个性化的用户兴趣模型,通过组合邮件模型分类器与兴趣模型分类器结果实现对邮件的准确分类;该方法通过SVM 集成学习有效降低了特征向量空间维数,算法执行速度较快.陈荣等[6]结合基于最优标号和次优标号(BvSB)的主动学习去挖掘那些对当前分类器模型最有价值的样本进行人工标注,并借助带约束条件的自学习(CST)方法进一步选择待标注样本,使得当标注代价较小时仍能够获得良好的分类性能.
现有增量学习方法普遍存在下面问题:①待标注样本选择过程往往需要训练集中所有样本参与,故计算复杂度较高;②传统主动学习要求用户对待标注样本进行类别标注,忽略了用户对样本被正确分类的感兴趣程度.针对这些问题,文中对传统Batch SVM 方法做出改进,引入用户兴趣度的概念,实现了一种在线垃圾邮件识别新方法.
1 相关理论
1.1 Batch SVM 增量学习
Batch SVM 由Syed 等[4]提出,现已成为机器学习中一种典型的增量学习方法.如图1 所示,该方法实现的具体步骤如下.
输入:初始训练样本集合A0、增量样本集合S1,S2,…,Sn;
(1)使用SVM 对A0进行训练,获得支持向量集合V0;
(2)将S1加入V0生成训练集A1,对A1进行SVM 训练继而得到支持向量集合V1;
(3)重复类似步骤(2)的过程直到所有的增量样本集合都已参加训练.
输出:以An为训练集的分类器.
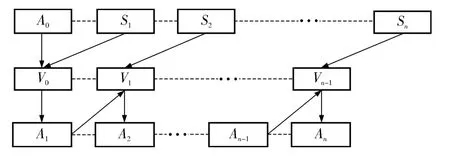
图1 Batch SVM 增量学习方法Fig.1 Incremental learning method of Batch SVM
1.2 主动学习模型
主动学习目的是在增量训练过程中有选择地扩大有标记样例集合和循环训练的方法,使分类器获得了更强的泛化能力.主动学习模型一般分为学习引擎和采样引擎两个部分[7],如图2 所示.
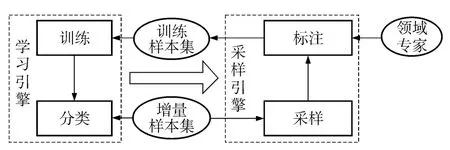
图2 主动学习模型Fig.2 Active learning model
其中,学习引擎先在初始样本集合上构造初始分类器,接着对增量样本进行分类;采样引擎则使用不同的采样算法从增量样本集合中选择样本推荐给领域专家进行标注,并使用标注后样本更新训练集以进行迭代训练.根据采样算法不同,可将主动学习算法分为基于流的主动学习和基于池的主动学习.理论研究表明,相对于监督学习而言,主动学习可以带来指数级的样本复杂度改善[8].
2 垃圾邮件在线识别新方法
结合传统Batch SVM 和主动学习理论实现了一种在线垃圾邮件识别新方法.给定训练样本集Ai及增量邮件集合Si(i=1,2,…,ns,ns为增量集数目),文中方法的执行过程如图3 所示.
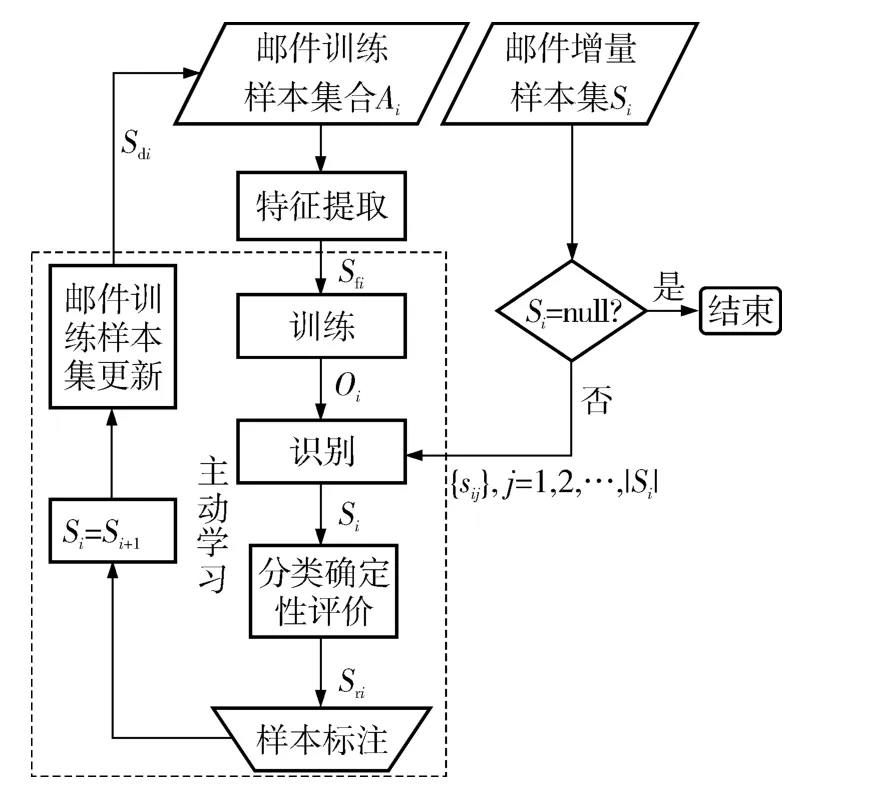
图3 文中方法的执行过程Fig.3 Executing process of the proposed method
2.1 特征提取、样本训练及识别
为了更好地兼顾算法执行速度及特征提取效果,使用类间-类内综合测量特征提取方法(CMFS)进行特征提取[9].将邮件训练集Ai中不同单词对应的CMFS 值按照从大到小的顺序排列,选取前nf个单词构成特征词集合Sfi.
序列最小优化算法(SMO)由Microsoft Research的Platt[10]在1998年提出,它能快速地解决SVM 分类过程面临的二次规划问题.基于SMO 在处理稀疏矩阵方面的优异表现,文中使用该算法对Ai进行训练,接着使用所得分类器Oi对Si中每封邮件进行识别.SMO 相关参数设置如下:惩罚因子ζ=1.0,容忍极限值=0.001,核函数为RBF Kernal,核函数参数γ=0.5.
2.2 分类确定性评价
Joshi 等[11]通过在主动学习过程中统计未标注样本属于各个类别的概率大小来寻找那些分类结果最不确定的样本,将其推荐给专家进行标注.该方法将Si中增量样本sij与Ai中每个样本进行比较,因此计算量较大.为此,文中考虑使用代表样本,即从包含个已标注样本的训练集Ai中随机选取/2个代表样本(记为Ari)与sij进行比较.若Ari中垃圾邮件、合法邮件集合分别为Arsi、Arhi,则邮件sij(j=1,2,…,)分类确定性u(sij)计算如下:
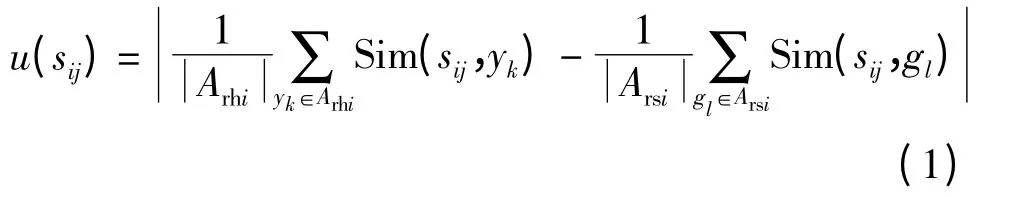
式中,Sim ( sij,yk)、Sim ( sij,gl)分别表示邮件sij与邮件yk、gl之间的相似度,使用欧式距离表示.将Si中所有邮件对应u(sij)按照从小到大的顺序排列,选择前Nt(文中取Nt=10)封邮件(记为Sri)推荐给用户.
2.3 样本标注
文中主动学习方法中领域专家即为邮件接收者(用户).传统主动学习方法强制用户对待标注样本的类别进行标注,而实际上,用户未必对所有类型样本都关心,且他们针对不同类型样本的感兴趣程度也不尽相同.文中提出了一种新的邮件样本标注模型,特点有:①用户可根据邮件内容决定是否对其进行标注;②引入了用户兴趣度的概念来区分用户对不同类型样本的感兴趣程度.
定义 用户U 对邮件E 能被正确分类的感兴趣程度,定义为U 对E 的用户兴趣度.
文中样本标注模型将任意待标注邮件E 表示为具有以下4 个域的结构形式,如图4(a)所示.
(1)索引.邮件的唯一标识.
(2)内容.邮件的文本内容包括邮件主题,正文等信息.
(3)类别.E 为合法邮件还是垃圾邮件,记为C(E),该部分由用户进行手工标注.
(4)用户兴趣度.U 对E 的用户兴趣度记为I(E),该部分由用户进行手工标注.
给定Sri中邮件sij,则样本标注过程如下:
(1)用户查看sij内容决定其对此类型样本是否感兴趣,若不,则丢弃sij(如图4(b)所示),否则,转至步骤(2);
(2)用户标注sij的类别C(sij)及用户对sij被正确分类的兴趣度I(sij)(默认为1).I(sij)由用户根据经验给出,如:若用户对sij内容特别感兴趣,说明他对sij分类结果正确与否特别关注,故可标记I(sij)=1.0,如图4(c)所示.同理,若用户对sij内容感兴趣程度一般,则可标记I(sij)=0.5,如图4(d)所示;若用户对sij内容有一点感兴趣,则可标记I(sij)=0.3,依此类推.
(3)重复执行步骤(1)、(2)直至遍历完Sri中的所有邮件,至此便生成了标注邮件集合Sdi对应的标注模型实例集合S'di.

图4 文中方法的邮件标注模型及实例Fig.4 Email labeling model and examples of the proposed method
2.4 训练样本集更新
传统主动学习训练样本集更新时将用户标注后所有样本直接加入原始训练集,一方面使得训练集样本数量增长较快;另一方面无法有效区分不同类型样本分类正确与否对用户造成的影响(例如:相对于垃圾邮件而言,用户对合法邮件被正确分类的需求更高).文中提出了一种基于“轮盘赌”[12]的样本加入方法,针对已标注的邮件集合Sdi处理步骤如下.
1)为保证合法邮件优先于垃圾邮件被加入训练集,设置权值μ(0 <μ <1,文中取μ=0.9).
2)根据2.3 节样本标注结果,获得Sdi对应的标注模型实例集合S'di;
3)针对Sdi中每封邮件sij,先从S'di中获得与之对应的用户兴趣度I(sij),接着计算sij加入Ai的概率Pij:
(1)if C(sij)=ham,then Pij=I(sij)
(2)else Pij=I(sij)* μ(0 <μ <1)
(3)endif
3 实验结果与分析
3.1 数据集与评价方法
将常用于在线仿真的非加密英文邮件TREC2007(包含50 199 封垃圾邮件、25 220 封合法邮件)作为实验数据集[13].去除邮件附件、标签、邮件头、停用词等信息,并使用Porter Stemming 算法进行词形还原[14].设置特征提取的对应特征向量维数nf=600,测试集数目nt=5.为仿真在线学习过程,保证算法针对初始训练集A0的训练时间、针对增量样本集Si(0 <i≤ns)的学习时间、针对测试集Tj(0 <j≤nt)的测试时间满足图5 所示的先后关系.进一步地,在对Tj(0 <j≤nt)进行仿真测试之前,先由用户按照文中邮件标注模型对Tj中每封邮件进行标注,生成标注模型实例集合T'j.

图5 初始训练集A0、增量样本集Si 及测试集Tj 的时间关系Fig.5 Time relationship among initial training corpus A0,incremental corpus Si and testing corpus Tj
基于传统垃圾邮件识别算法性能评价标准[15],文中提出了一种结合用户兴趣度的垃圾邮件识别召回率(r)、准确率(p)评价新方法.针对标注模型实例集合T'j(0 <j≤nt),若T'j中属垃圾邮件的模型实例集合记为T'js,属合法邮件的模型实例集合记为T'jh,则r、p 定义如下:

式中,α 为用户对某邮件的兴趣度,Φs为T'js中所有邮件对应的用户兴趣度集合,Φss为T'js中被正确分类的邮件对应的用户兴趣度集合,hs为T'jh中被错分的邮件对应的用户兴趣度集合,ns(α)为T'js中对应兴趣度为α 的邮件数目,nss(α)为T'js中对应兴趣度为α 且被正确分类的邮件数目,nhs(α)为T'jh中对应兴趣度为α 且被错分的邮件数目.由式(2)知,r 越大,系统发现垃圾邮件的能力就越强;p 越大,合法邮件被漏读的可能性就越小.
3.2 耗时分析
假设当前邮件训练集Ai样本数为,增量集Si样本数为,对Ai进行SVM 训练的耗时为tT(Ai)、从Si中选择待标注样本的耗时为tS(Si).表1 评估了不同主动学习方法对应的tT(Ai)、tS(Si)值.其中,Sdi为用户标注后样本集,Spdi为文中实际加入训练集的样本集,tV(A)表示对样本集A 进行SVM 训练所需时间,tC()表示计算样本集合Ai-1中所有样本的分类确定性所需时间,tO()表示对个元素排序所需时间,δ表示CST 样本选择过程所需时间.可见,由于存在SpdiSdi,文中方法的tT(Ai)值不大于Joshi 方法、Chen 方法;进一步知,由于tC()过程耗时依赖于大小,故文中方法所得tS(Ai)值将小于另外两种方法.

表1 不同主动学习方法对应的tT(Ai)、tS(Si)值Table 1 tT(Ai)and tS(Si)values corresponding to different active learning methods
3.3 性能测试
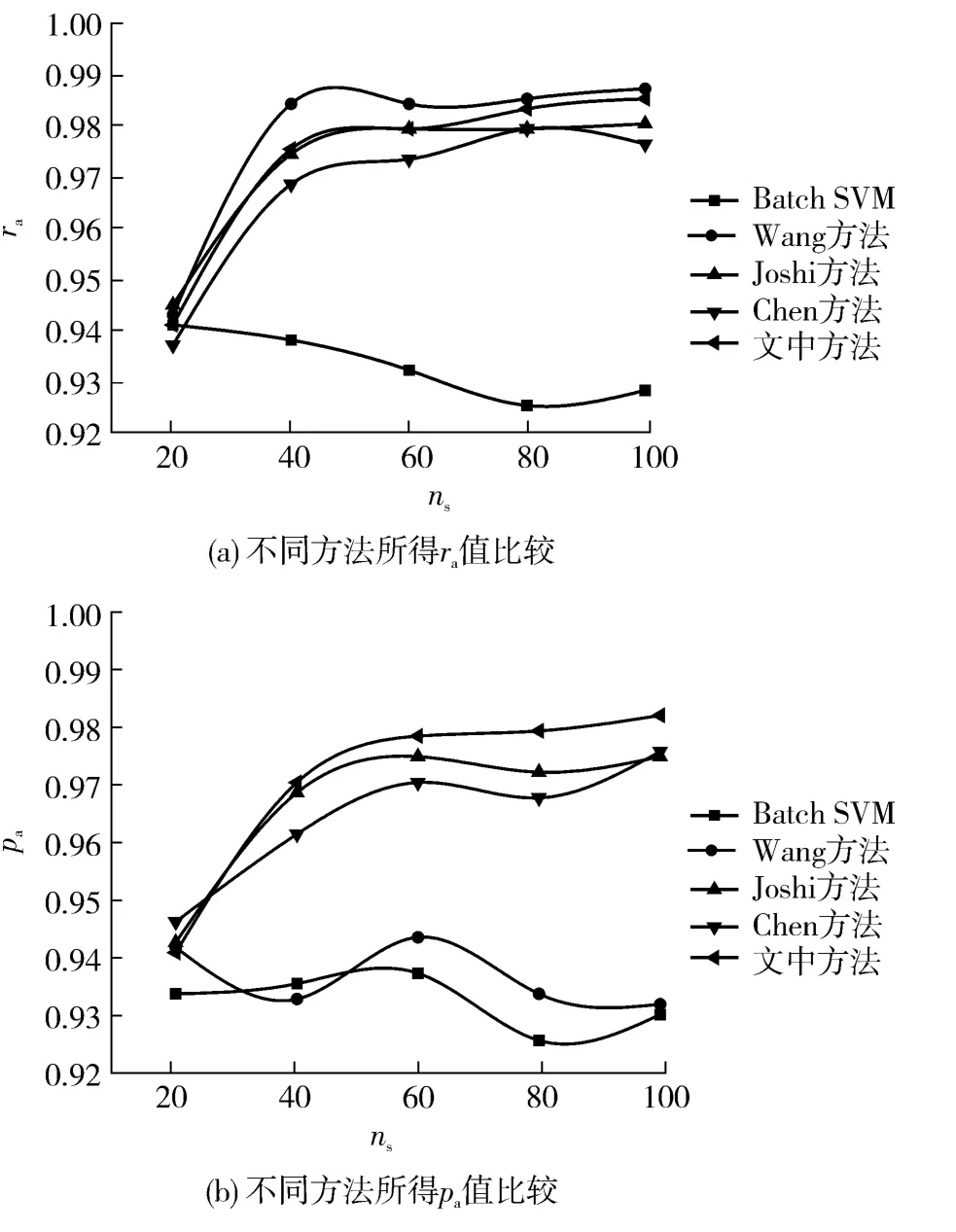
图6 10 个用户在不同ns 值下对应的ra、pa 值Fig.6 ra and pa values of 10 users with different ns values
3.3.1 多用户情况下的性能测试
表2 不同方法所得及值Table 2 andvalues obtained by different methods
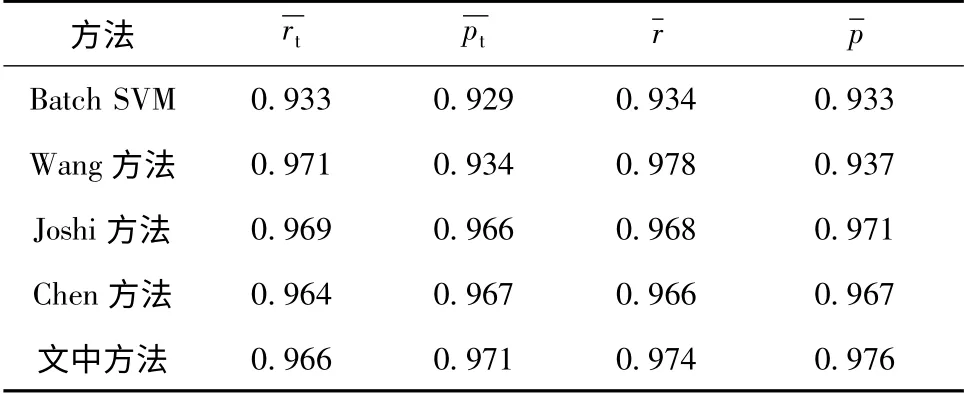
表2 不同方法所得及值Table 2 andvalues obtained by different methods
方法 r t p t r p Batch SVM 0.933 0.929 0.934 0.933 Wang 方法 0.971 0.934 0.978 0.937 Joshi 方法 0.969 0.966 0.968 0.971 Chen 方法 0.964 0.967 0.966 0.967文中方法0.966 0.971 0.974 0.976
3.3.2 单用户情况下的性能测试
单用户仿真实验时应考虑用户兴趣迁移对学习效果的影响[16].先从S1-S100中挑选5 个典型邮件内容主题,接着给出某一用户在不同增量学习阶段针对这些主题的兴趣度变化过程,如表3 所示.在增量学习不同阶段由用户自行对Tj(1 <j≤nt)进行标注,先使用传统评价方法计算垃圾邮件识别召回率均值、准确率均值,再使用文中新评价方法计算召回率均值、准确率均值,结果如表4 所示.可见,相对于传统评价方法,新评价方法下文中方法的召回率均值、准确率均值提升明显;文中方法所得值虽低于Wang 方法,但明显高于其他方法;文中方法所得值为0.979,比全局次高值大0.010.综上说明:新评价方法反映了用户兴趣度对分类结果的影响;文中方法在增量学习不同阶段区分了用户兴趣度,有效降低了用户兴趣迁移对算法识别效果的影响.
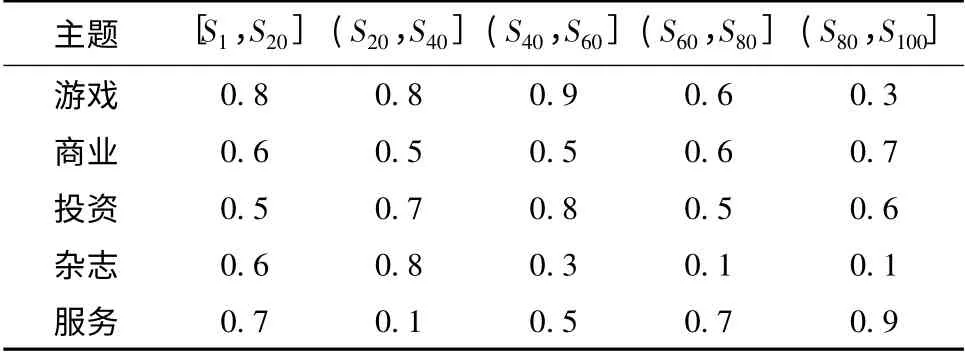
表3 不同增量学习阶段用户兴趣度变化Table 3 Changes of user interest degree at different incremental learning stages
表4 不同方法所得 及值Table 4 andvalues obtained by different methods
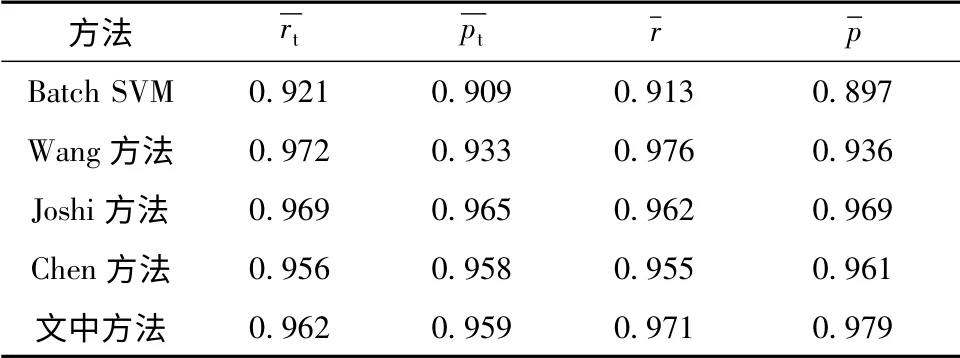
表4 不同方法所得 及值Table 4 andvalues obtained by different methods
方法 r t p t r p Batch SVM 0.921 0.909 0.913 0.897 Wang 方法 0.972 0.933 0.976 0.936 Joshi 方法 0.969 0.965 0.962 0.969 Chen 方法 0.956 0.958 0.955 0.961文中方法0.962 0.959 0.971 0.979
3.3.3 不同算法耗时对比实验
定义样本训练平均耗时w 及待标注样本选择平均耗时z 如下:
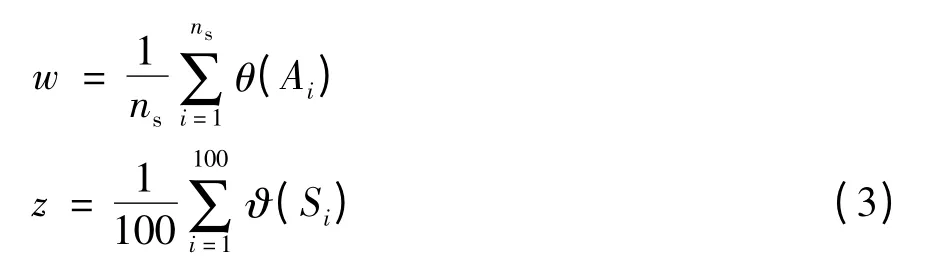
式中,θ(Ai)为对Ai进行SVM 训练的耗时,ϑ(Si)为主动学习过程中从Si中选择待标注样本的耗时.使用不同方法分别计算相应z 的值及当ns=20,40,60,80,100 时对应的w 值,结果如图7(a)-7(d)所示.可见,Batch SVM 方法所得w 值受取值影响较大,与关系不大;而其他方法w 取值与关系密切,=200 时所得w 值较=50 时普遍偏高.由于使用了“轮盘赌”方法抑制训练集规模的快速增长,故相对于Wang 方法、Joshi 方法、Chen 方法而言,文中方法的样本训练时间较短,且当增量集样本数目较大时,在一定程度内(ns≤40)优于Batch SVM.对比结合主动学习的Joshi 方法、Chen方法及文中方法对应的z 值发现,文中方法的结果明显偏小,进一步验证了该方法在降低待标注样本选择耗时方面的有效性.
4 结语
提出了一种基于SVM 增量学习的垃圾邮件识别新方法,主要内容如下:①为降低寻找待标注邮件耗时,通过从已标注训练集中随机选择代表样本计算邮件的分类确定性;②提出了用户兴趣度的概念和新样本标注模型,将用户针对邮件被正确分类的感兴趣程度融入模型中;③结合用户兴趣度,使用“轮盘赌”方法更新邮件训练集;④提出了结合用户兴趣度的分类器性能评价新标准.实验结果证明:新样本标注模型有效融合了用户对邮件被正确分类的感兴趣程度,“轮盘赌”训练集更新方式在降低训练集规模增长速度的同时保证了用户感兴趣邮件被优先加入;新方法针对垃圾邮件识别效果好,样本训练及待标注样本选择速度快,具有较高的实用价值.
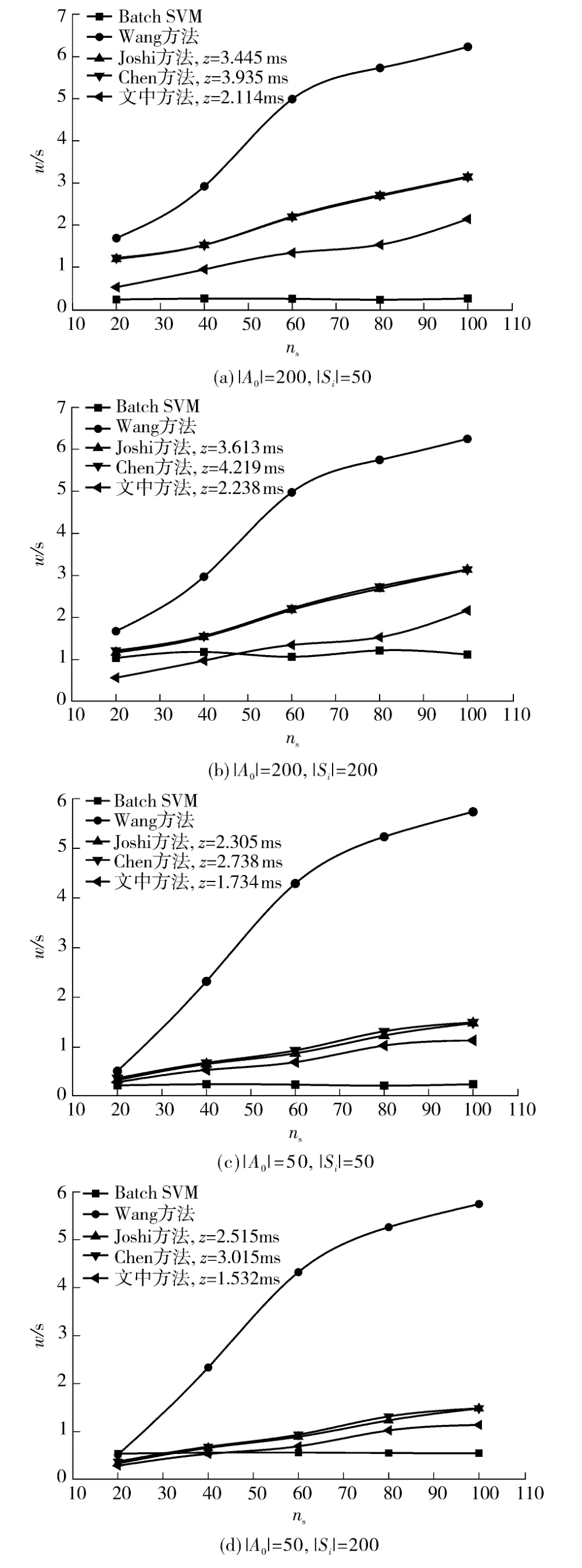
图7 ns 取不同值时不同方法所得w、z 值Fig.7 w and z values obtained by different methods with different ns values
[1]Liu W Y,Wang T.Active learning for online spam filtering[J].Information Retrieval Technology,2008,4993:555-560.
[2]刘伍颖,王挺.集成学习和主动学习相结合的个性化垃圾邮件过滤[J].计算机工程与科学,2011,33(9):34-41.Liu Wu-ying,Wang Ting.Ensemble learning and active learning based personal spam email filtering[J].Computer Engineering & Science,2011,33(9):34-41.
[3]Bouchachia A,Gabrys B,Sahel Z.Overview of some incremental learning algorithms[C]∥Proceedings of IEEE International Conference on Fuzzy Systems.London:IEEE,2007:1-6.
[4]Syed N,Liu H,Sung K.Handling concept drifts in incremental learning with support vector machines[C]∥Proceedings of the Workshop on Support Vector Machines at the International Joint Conference on Articial Intelligence(IJCAI-99).Stockholm:IJCAII and the Scandinavian AI Societies,1999:317-321.
[5]王学军,赵琳琳,王爽.基于主动学习的视频对象提取方法[J].吉林大学学报:工学版,2013,43(3):51-54.Wang Xue-jun,Zhao Lin-lin,Wang Shuang.Video object extraction method based on active learning SVM [J].Journal of Jilin University:Engineering and Technology Edition,2013,43(3):51-54.
[6]陈荣,曹永锋,孙洪.基于主动学习和半监督学习的多类图像分类[J].自动化学报,2011,37(8):954-962.Chen Rong,Cao Yong-feng,Sun Hong.Multi-class image classification with active learning and semi-supervised learning[J].Acta Automatica Sinica,2011,37(8):954-962.
[7]Wu Y,Kozintsev I,Bouguet J Y,et al.Sampling strategies for active learning in personal photo retrieval[C]∥Proceedings of ICME 2006.Piscataway:IEEE,2006:529-532.
[8]吴伟宁,刘扬,郭茂祖,等.基于采样策略的主动学习算法研究进展[J].计算机研究与发展,2012,49(6):1162-1173.Wu Wei-ning,Liu Yang,Guo Mao-zu,et al.Advances inactive learning algorithms based on sampling strategy[J].Journal of Computer Research and Development,2012,49(6):1162-1173.
[9]Yang J M,Liu Y N,Zhu X D,et al.A new feature selection based on comprehensive measurement both in inter-category and intra-category for text categorization[J].Information Processing & Management,2012,48(4):741-754.
[10]Platt John.Sequential minimal optimization:a fast algorithm for training support vector machines[R].[S.l.]:Microsoft Research,1998.
[11]Joshi A J,Porikli F,Papanikolopoulos N.Multi-class active learning for image classification[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Miami:IEEE,2009:2372-2379.
[12]夏桂梅,曾建潮.一种基于轮盘赌选择遗传算法的随机微粒群算法[J].计算机工程与科学,2007,29(6):51-54.Xia Gui-mei,Zeng Jian-chao.A stochastic partical swarm optimization algorithm based on the genetic algorithm of roulette wheel selection [J].Computer Engineering &Science,2007,29(6):51-54.
[13]Cormack G V.TREC 2007 spam track overview[C]∥Proceedings of the 16th Text Retrieval Conference.Gaithersburg:National Institute of Standards and Technology,2007:500-274.
[14]Porter M F.An algorithm for suffix stripping[J].Program:Electronic Library and Information Systems,1980,14(3):130-137.
[15]Yang J M,Liu Y N,Liu Z,et al.A new feature selection algorithm based on binomial hypothesis testing for spam filtering[J].Knowledge-Based Systems,2011,24(6):904-914.
[16]Bouneffouf D,Bouzeghoub A,Gançarski A L.Following the user's interests in mobile context-aware recommender systems:the hybrid-ε-greedy algorithm[C]∥Proceedings of 26th International Conference on Advanced Information Networking and Applications Workshops.Fukuoka:IEEE,2012:657-662.
猜你喜欢
承德医学院学报(2022年2期)2022-05-23
当代陕西(2022年6期)2022-04-19
英语文摘(2021年10期)2021-11-22
潍坊学院学报(2020年2期)2021-01-18
疯狂英语·新阅版(2020年11期)2020-12-21
计算机与网络(2020年4期)2020-04-20
中学生数理化·中考版(2019年9期)2019-11-25
网络安全和信息化(2018年4期)2018-11-09
车迷(2018年12期)2018-07-26
电信科学(2016年9期)2016-06-15
