
基于Logistic模型的供应链金融信用风险实证研究*
2014-08-08 06:20:00施丽娟
重庆工商大学学报(自然科学版) 2014年7期
陈 钦, 施丽娟
(福州外语外贸学院 经济学院,福州 350202)
1 Logistic模型的理论基础
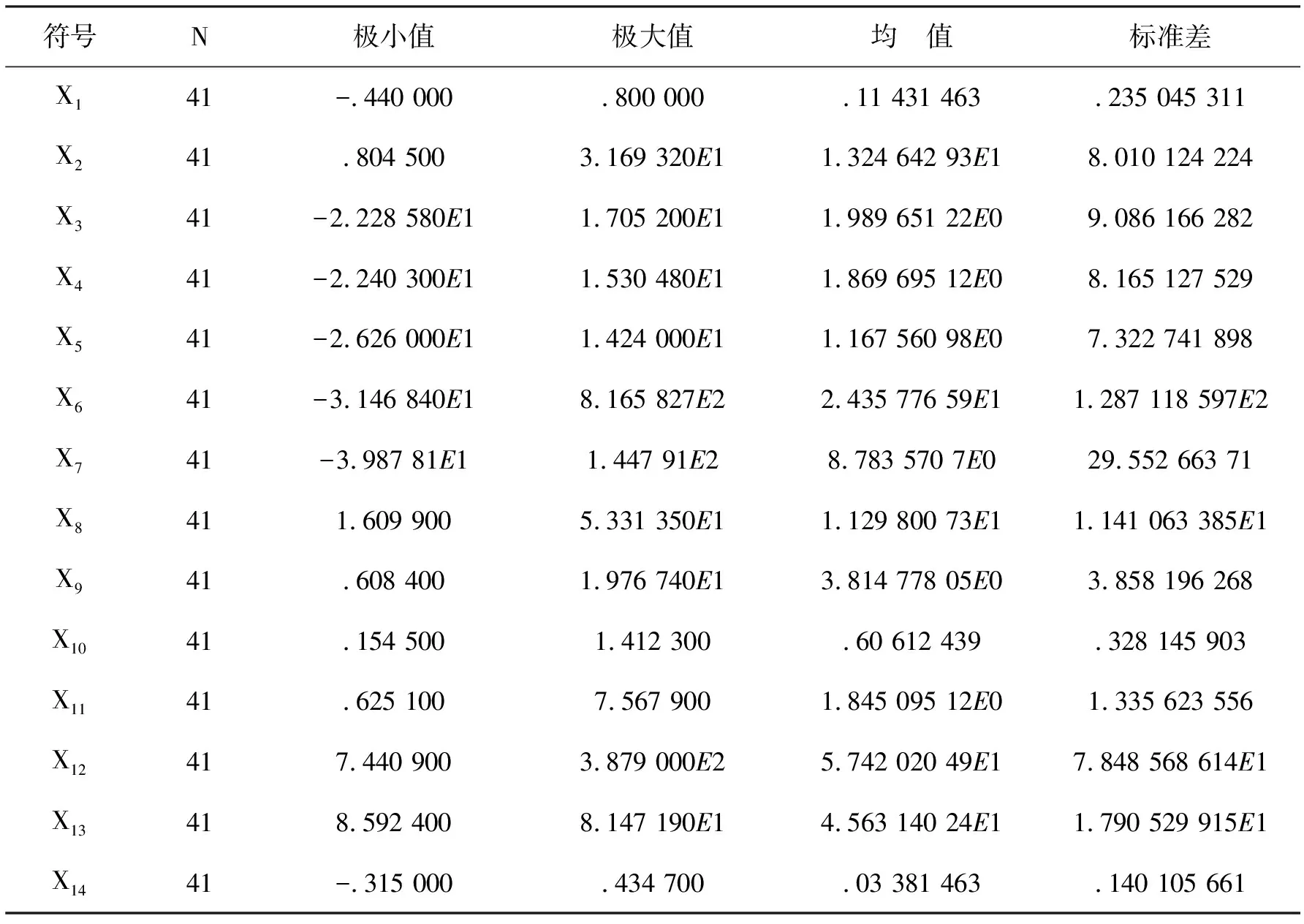
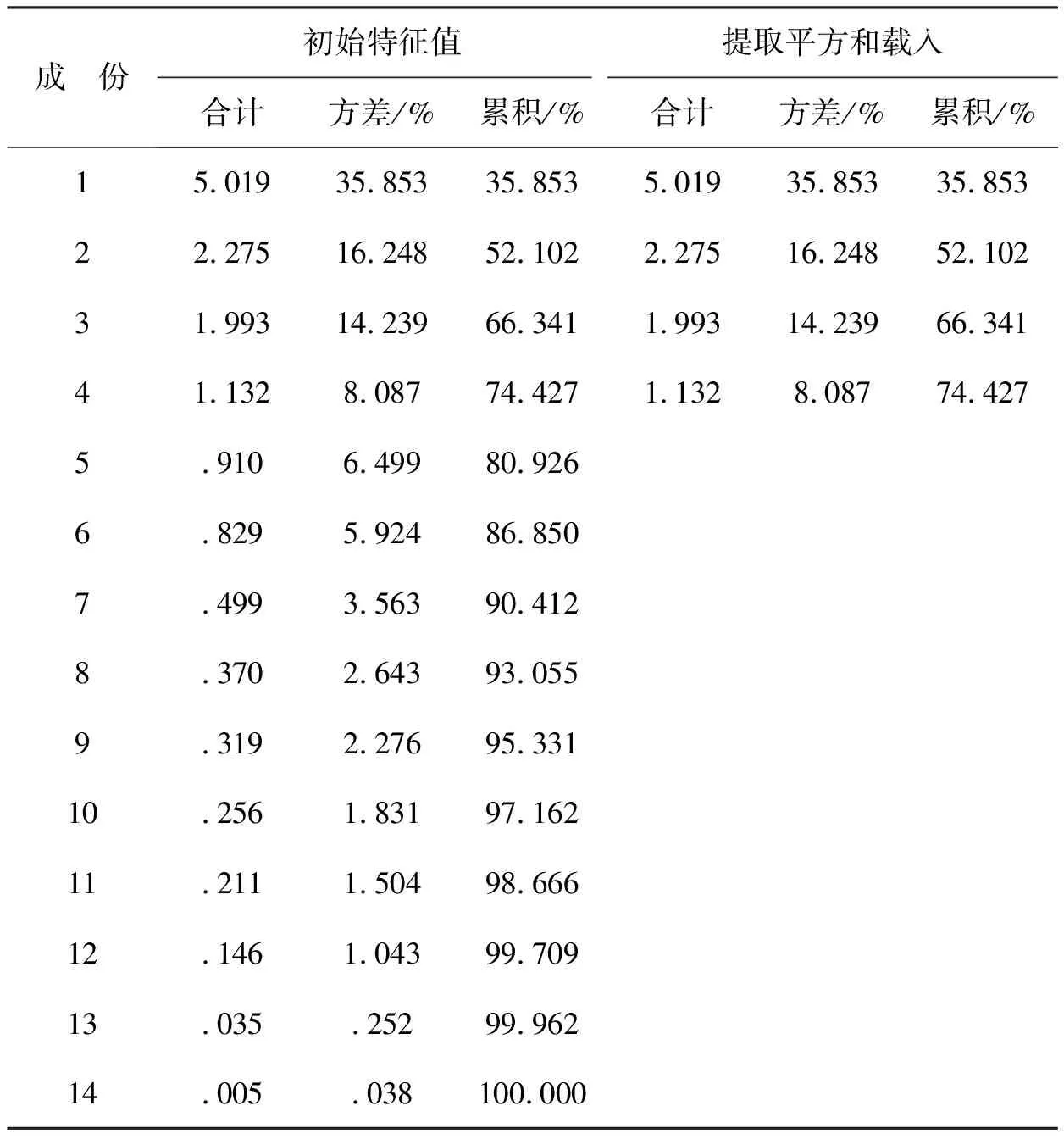
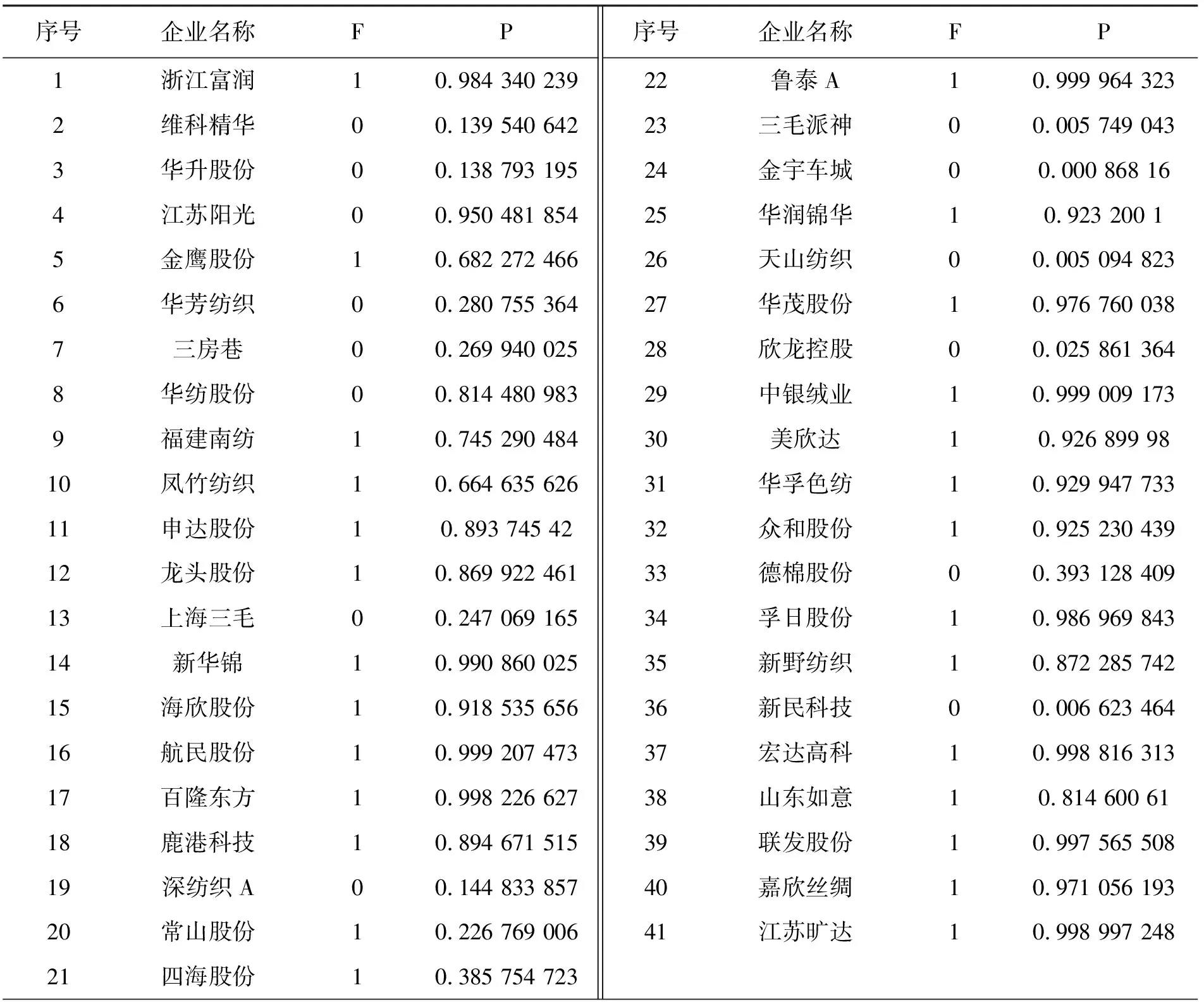
选择Logistic模型进行供应链金融的信用风险评价,对利用供应链金融进行融资的企业的违约率进行实证分析。采用主成分分析法选择具有代表性的自变量,以减少候选变量间的相关性,对模型进行修正简化。Logistic模型是目前计算违约概率方面研究比较成熟的一种模型。方法假设企业守约概率服从Logistic分布。采用一系列财务和业务指标(Xk,k=n)作为自变量建立Logistic模型,预测企业的守约概率P。然后根据银行和相关投资者的风险偏好程度设立分界点P*,通过P与P*的比较,以确定融资企业的违约率是否偏高,最后决定是否对该企业进行贷款。Logistic模型的因变量Y仅有0和1两个取值,1为守约,0为违约。如果P 借鉴前人的研究成果,并结合供应链金融的特点和传统信贷模式的信用风险评价方式,构成初步的供应链金融信用风险评价指标体系,其中包括14个指标。这14个信用风险评价指标分别是:X1(每股收益)、X2(主营业务利润率)、X3(营业利润率)、X4(净利润率)、X5(净资产收益率)、X6(主营业务收入增长率)、X7(净资产增长率)、X8(应收账款周转率)、X9(存货周转率)、X10(总资产周转率)、X11(流动比率)、X12(现金比率)、X13(资产负债率)、X14(现金流动负债比)。 样本数据来自沪深股市的纺织行业,共选取其中41家企业数据进行分析。指标数据来源于新浪财经的数据源(http:∥vip.stock.finance.sina.com.cn/mkt/#new_fzhy),主要截取2013年第3季度的报告数据作为基本数据来源。表1为SPSS运行的原始数据描述性统计量。 表1 原始数据描述性统计 样本数据中有14个指标,由于数量过多,应将各指标进行主成分分析。为了使数据具有标准性和可加性,便于后续分析,削除不同量级指标的影响,应将样本的原始数据标准化。运用SPSS统计软件进行主成分分析,表2为运行得到的主成分解释的总方差,表3为运行得到的主成分系数矩阵。 表2是利用SPSS将所有的数据做了一个主成分分析,发现将14个指标转化为了4个有代表性的综合指标。根据主成分分析原理,主成分特征根大于等于1就认为是满意的主成分变量。表2中,主成分的特征根大于1的分别为5.019、2.275、1.993、1.132,分别解释了原指标变量的35.853%、52.102%、66.341%、74.427%的信息,累积贡献率达到了74.427%,所以这4个主成分能够较好地表示原来所有的指标信息。 由表3的主成分得分系数矩阵,得出主成分表达式: Y1代表企业获利能力的Z1(每股收益)、Z2(主营业务利润率)、Z3(营业利润率)、Z4(净利润率)和Z5(净资产收益率)在公因子Y1上游较高的载荷。反映的是企业的盈利能力,可称Y1为盈利能力因子。 Y2代表企业偿债能力的Z11(流动比率)、Z12(现金比率)和Z13(资产负债率)在公因子Y2上游较高的载荷。反映的是企业的偿债能力和现金流量,可称Y2为现金流因子。 Y3代表企业偿债能力的Z6(主营业务收入增长率)、Z9(存货周转率)和Z10(总资产周转率)和在公因子Y3上游较高的载荷。反映的是企业的营运能力,可称Y2为营运因子。 表2 主成分解释的总方差 表3 主成分系数矩阵 Y4代表企业发展前景和成长能力的Z8(应收账款周转率)在公因子Y4上游较高的载荷。反映的是企业的成长能力,可称Y4为成长因子。 用经过主成分分析之后得到的表达式计算各公司的Y1、Y2、Y3和Y4数值与各个企业的评判指标F数值组合在一起,组合后的数值见表4。各个企业的评判指标F数值是参考了和讯网(http:∥www.hexun.com/)中对各家企业的最新财务评估,综合考虑企业的综合能力、盈利能力、偿债能力和成长能力。一般把综合能力在两颗星及以上的评判指标F数值设为1,特别要说明的是如果综合能为两颗星以上,但是盈利能力、偿债能力和成长能力中只要其中一个能力为一颗白星的,认定评判指标F数值设为0。 表4 各企业的Y1、Y2、Y3和Y4数值与评判指标F数值的对照 续表4 运用SPSS软件对组合后的数值进行回归分析,选择的方法是向后去除,逐步向后选择,移去检验基于Wald统计量的概率。SPSS统计分析软件运行的结果,见表5。 表5 主成分变量参数估计表 表5得到的结果是Logistic实证模型的拟合结果。根据第三步回归的结果,Y1、Y2被保留在方程中,概率均小于0.05。估计的Logistic回归模型如下: (1) 式(1)P值的大小表示了企业的守约概率,可以用来预测融资企业的信用风险的大小。若P值越接近1,则表示守约概率较大,属于低风险类,银行可以考虑给予信贷;若P值越接近0,表示守约概率较小,属于高风险类,银行应慎重考虑是否给予信贷。 以浙江富润为例: 即浙江富润的守约概率为98.43%,说明浙江富润的守约概率很高,银行可以考虑为其提供融资。 同理可得样本中41家的P值,见表6。 表6 企业评判指标Y和守约概率P对照表 从表6知,样本中共有41家企业,只有4家企业它们的F值与P值有误差,模型整体预测正确率为90.70%,其中判断信用良好的企业违约率较低的准确率为92.59%,判断信用较差的企业违约率较高的准确率为85.71%。由此可见,根据Logistic回归分析得出的供应链金融模式下的融资企业守约概率模型可以帮助测算企业在供应链金融模式下的信用水平,使评估方法从对企业静态的财务数据评估变成对动态的交易过程评估,并且准确度较高。 (1) 由于国内开拓供应链金融这种全新的融资业务还处于发展阶段,要逐步建立企业的信用档案,注重完善信贷数据库。加快企业和个人征信系统建设,在全国范围内实现企业和个人征信系统信息资源共享。对于信用较差的企业采用惩戒机制,对于信用较好的企业实行奖励机制,有助于改善整个社会的信用环境。同时在建设信贷数据库应侧重企业的非财务指标数据的收集工作。 (2) 样本主要是来自纺织行业的上市公司,只能反映这一行业的供应链金融信用风险识别模型。由于不同行业有各自不同的属性,因此本文得出的这个信用风险识别模型未必能完全适用于其它行业,需要根据各行业的不同属性对模型进行相应的调整,所以要加强对供应链金融信用风险的控制,就要考虑信用风险评价体系中的评价指标,考虑模型对不同行业的适用性问题。 (3) 由于我国正处于经济转型期,企业的外部环境变化较快,宏观经济因素对商业银行的稳健经营有着深刻影响,不足之处是没有把宏观经济因素考虑在内。所以加强对供应链金融信用风险的控制,就要加强对风险识别模型的检验。要定期对信用识别模型进行检验,考察该模型是否能较好地反映企业的信用变化情况。 参考文献: [1] 弯红地.供应链金融的风险模型分析研究[J].经济问题,2008(11):109-112 [2] 闫俊宏,许祥秦.基于供应链金融的中小企业融资模式分析[J].上海金融,2007(2):14-16 [3] 鲍旭红.基于供应链金融的中小企业融资渠道创新研究[J].科技和产业,2009(1):74-77 [4] 熊熊,马佳,赵文杰,等.供应链金融模式下的信用风险评价[J].南开管理评论,2009(4):92-98 [5] 胡海青,张琅,张道宏,等.基于支持向量机的供应链金融信用风险评估研究[J].软科学,2011(5):26-362 供应链金融信用风险评价指标体系的构成
3 样本选取及原始数据描述性统计量
4 主成分分析

5 模型回归分析
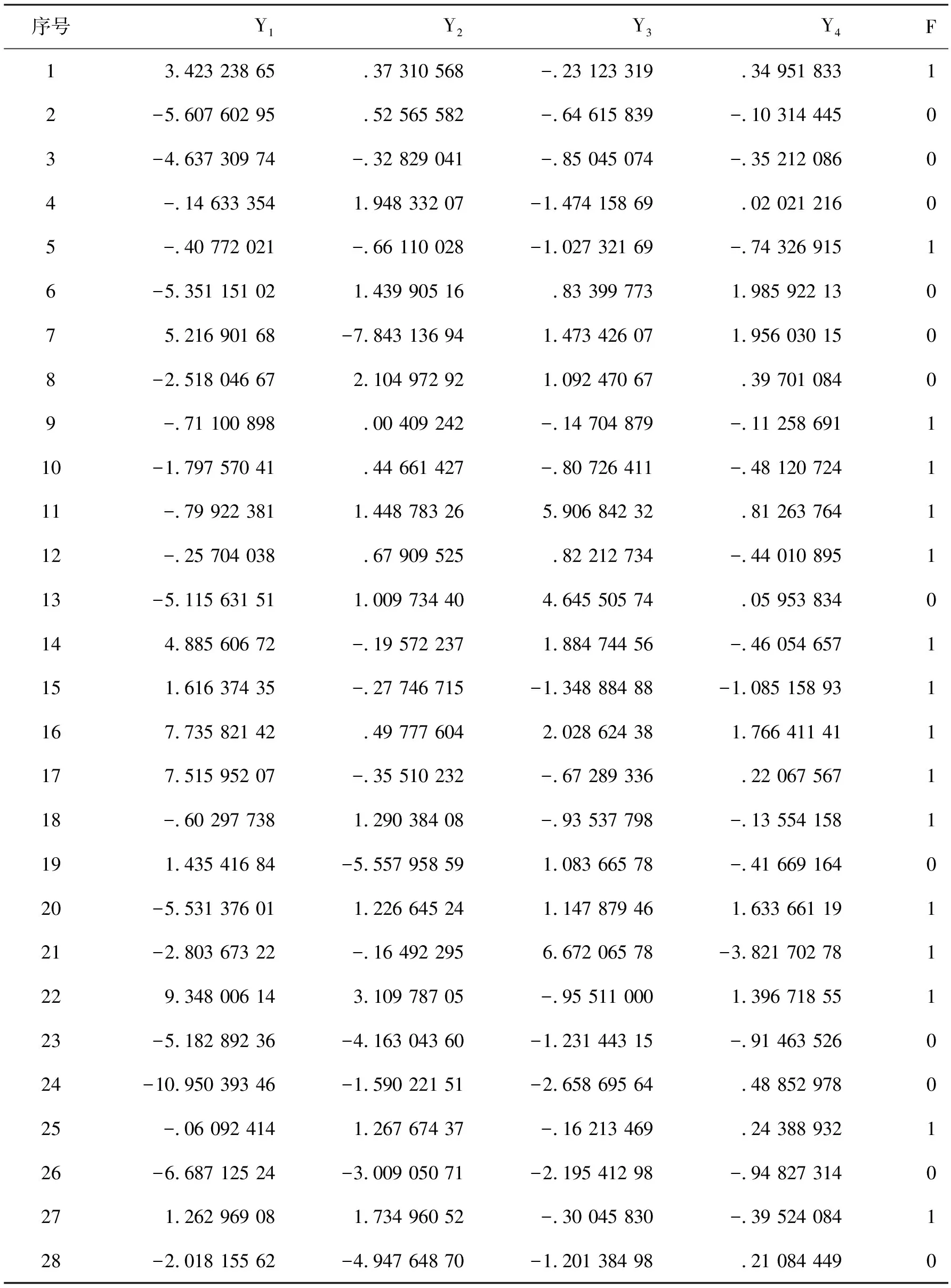
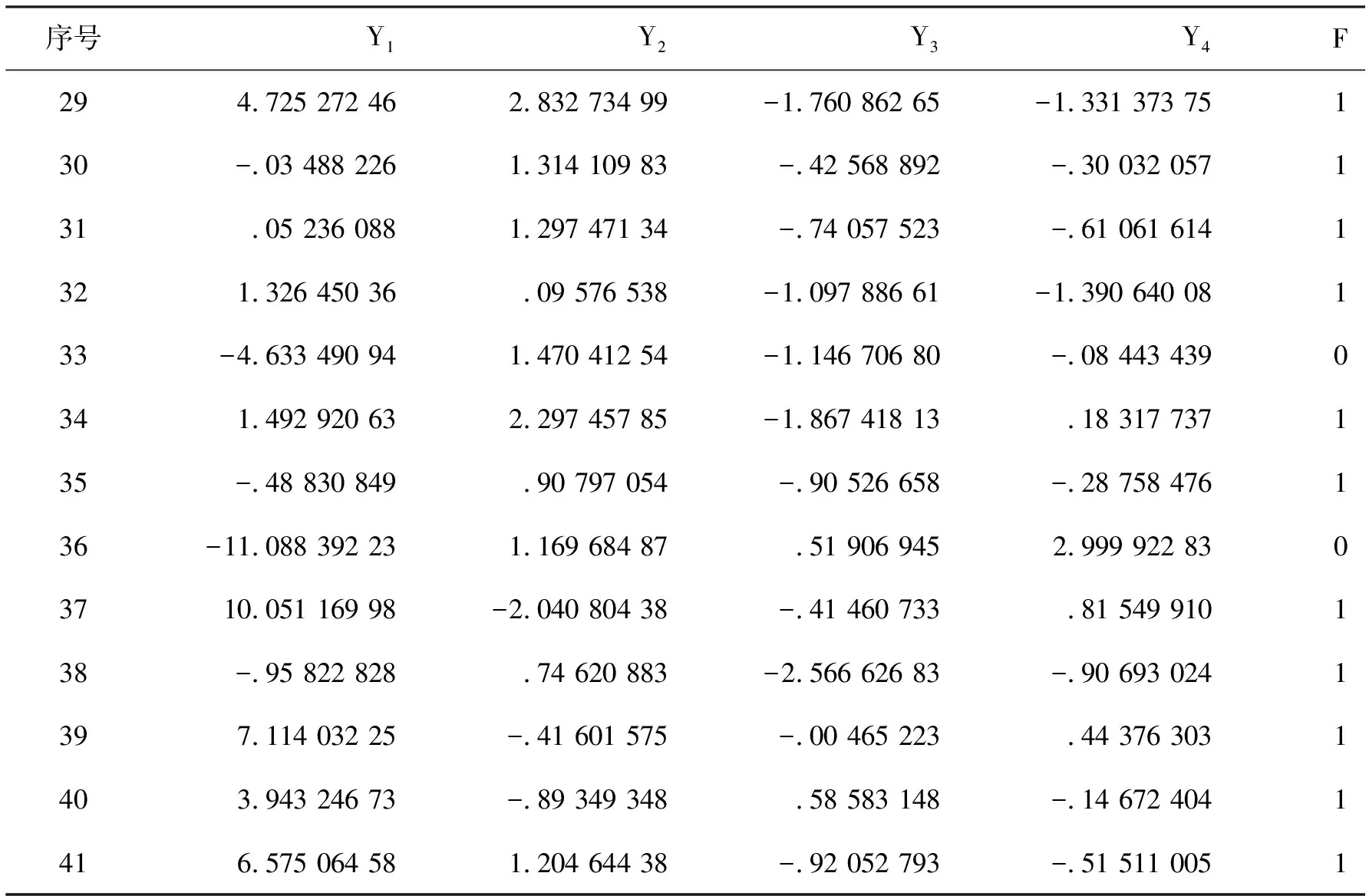

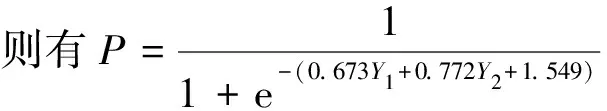
6 检验与结论
6.1 检 验
6.2 结 论
猜你喜欢
小学生学习指导(低年级)(2023年4期)2023-05-09 11:52:52
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
中学生数理化·高一版(2021年11期)2021-09-05 14:27:13
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
辽宁经济(2017年6期)2017-07-12 09:27:35
当代经济(2016年26期)2016-06-15 20:27:18
焊接(2016年2期)2016-02-27 13:01:02
新疆财经大学学报(2015年3期)2015-12-10 03:49:13
