
基于DRPKP算法的文本去重研究与应用
2014-08-07 13:20俞枫王引娜
微型电脑应用 2014年1期
俞枫,王引娜
基于DRPKP算法的文本去重研究与应用
俞枫,王引娜
SimHash算法是目前主流的文本去重算法,但它对于特定行业的文本数据在主题方面的天然相似性特点并没有特殊的考虑。基于多年在金融证券行业信息管理和数据整合的经验,本文分析目前文本去重方法存在的问题,特别针对SimHash算法在特定行业文本去重中的不足,创新地提出一种基于段落主题的文本去重方法(简称DRPKP算法),通过对去重准确率、覆盖率和去重时间3个指标进行对比测试,DRPKP算法比SimHash算法准确率可提高24.5%、覆盖率可提高16.34%,且去重时间更短。
文本去重;段落主题;SimHash;相似度;MapReduce
0 引言
SimHash算法由Charikar.M.S在2002年提出[1],是目前主流的文本去重算法,它被包括Google在内的互联网公司广泛使用于开放领域的网页文本去重,它具有计算速度快,存储空间小等优点。然而,SimHash算法对于特定行业的文本数据在主题方面的天然相似性特点并没有特殊的考虑。以金融证券行业为例,其文本信息包含的关键字雷同、文本结构相似,这种主题天然相似性是特定行业文本有别于开放领域网页文本的特征,这会给通用型的去重算法带来干扰。
基于多年来在金融证券行业信息管理和数据整合的经验,本文针对SimHash算法在特定行业文本去重中的不足,提出了一种基于段落主题的文本去重方法(简称DRPKP算法),并基于MapReduce框架进行了算法实现,以国泰君安金融资讯和统一检索平台中的实际数据为基础,通过分组测试和交叉比较,验证了DRPKP算法相比SimHash算法在去重准确率、覆盖率和去重时间3个指标方面的性能,结果表明DRPKP算法比SimHash算法准确率可提高24.5%、覆盖率可提高16.34%,且去重时间更短。
1 文本去重相关技术比较
目前,文本去重的主要方法有:
1)基于URL的去重。主要是检测URL是否重复,文献[2]采用布隆过滤器检查一个URL是否已经被抓取过以判断重复信息。然而,由于同一个网页可以关联给不同的URL,因此,基于URL的去重效果准确性较低。
2)基于特征码的去重。它一般是从文章中提取出一些字符串(称为“指纹”),把指纹映射到hash表中,通过统计hash表中相同的指纹数目或者比率,来计算网页的相似性。代表算法有DSC和DSC-SS算法,DSC算法效率不高,而且文档数量大时比较的次数过多,导致效率下降,DSC-SS算法处理短小文档时效率较低。
3)基于文本复制检测技术的去重。代表方法有COPS (copy protection system) 系统及其相应算法、SEAM ( Stanford copy analysis method)原型、dSCAM模型、KOALA系统、YAP3和MDR以及北大天网查重算法,这些方法的基础是基于词频统计的方法来计算文件相似性,方法不够准确而且计算量大,不适合大规模的文本去重。
4)基于局部敏感哈希的去重。经典代表如SimHash算法,它是从文本中抽取一些带有权重的特征集,通过这些特征集的叠加计算得到该文本的指纹,通过计算两个指纹之间的海明距离来判断两个文本的相似度。文献[3]提出基于多SimHash指纹和k维超曲面的近似文本检测,文献[4]提出对SimHash存在的问题进行了改进。然而,SimHash算法及其改进的方法主要还是面向包含主题众多,特征集差异度比较大的开放文本领域,而在特定行业中的文本之间的相似度天然就很高,使得通用去重算法判断文档重复的准确率降低。根据我们在金融证券领域的文本去重经验,在券商的文本数据中重复数据约占50%,而SimHash算法只能去掉重复数据中的60%到70%,低于其用于开放领域网页文本去重的平均水平(SimHash算法在开放领域网页文本去重的平均水平在70%以上)。
通过以上分析,目前的各类去重方法均存在一定的不足。主流的通用型去重算法,如SimHash算法,由于特定行业文本具有关键词集合小、关键词重复率高、文本结构特征相似等特点,使判断文本信息是否相似的难度加大,从而导致通用型去重方法在特定行业文本去重的表现反而比开放领域有所下降。
2 基于DRPKP的文本去重算法
2.1 DRPKP算法
针对SimHash算法在特定行业领域应用的不足,本文提出基于DRPKP算法的文本去重方法,相比于SimHash算法,DRPKP算法充分考虑了文本的结构以及特性的分布情况:SimHash算法是一个文本产生一个指纹,而DRPKP算法是文本中的每个段落产生一个指纹,因而一个文本可以表达为其包含段落的指纹集合。对于同一个文本而言,基于段落主题的指纹集合比单一指纹包含更多的信息,从而提高对文本相似度判断的准确率。
DRPKP算法的流程如图1所示:
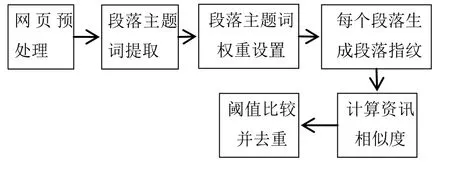
图1 基于DRPKP算法的去重流程图
以下为基于DRPKP算法的去重步骤:
Step1:利用中科院的ICTCLAS系统对文本进行分词和词性标注,为了减少计算的复杂度,去掉除名词和动词以外的词。
Step2:对文本按照段落提取主题词,并为每一个提取的主题词设定权重,这些带有权重的特征构成一个多维向量。
其中主题词提取的实现方式是:统计出段落文本中的实词的出现概率,其中代表实词wi在段落中出现的次数,n(si)代表段落si中出现的实词个数,然后选取概率最高的10个主题词作为段落主题。
每个主题词的权重计算为词频权重、上下文权重和位置权重之和,其中上下文权重是指在一个词汇窗口(20个字)出现的多个主题词的上下文权重,若一个词汇窗口同时出现n个主题词,则每个主题词的权重为0.1n,位置权重考虑的位置包括标题、首段、尾段、第x段,计算公式如公式(1):
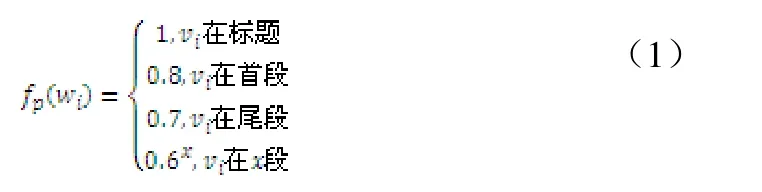
Step3:初始化一个64维的向量,且各维初始化为0。采用Rabin的随机多项式生成指纹算法将每个段落主题计算出一个
64-bit的指纹,Rabin的指纹算法是基于系数属于二进制整数空间的不可约多项式的模运算。
Step4:对于每个段落的64-bit指纹,如果第i位为0,则64维向量的第i维的值被减去该段落主题的权重;反之,如果第i位为1,则加上该段落主题的权重。
Step5:当所有的段落主题特征都这样处理完之后,64维向量的各维的值则有正有负,如果该维的值的符号为正则取1,为负取0,从而得到了该段落的指纹。如果该文本有m个段落,则文本d的指纹集合为。
Step6:计算两个文本的海明距离得出两个文本的相似度。
2.2 DRPKP算法实现
为了进一步提高去重过程的效率,本文采用MapReduce框架对DRPKP算法进行实现。MapReduce是一种并行运算的编程模型,它通过定义Map函数(映射)和Reduce函数(规约)实现并行计算。DRPKP算法基于MapReduce的去重流程如图2所示:
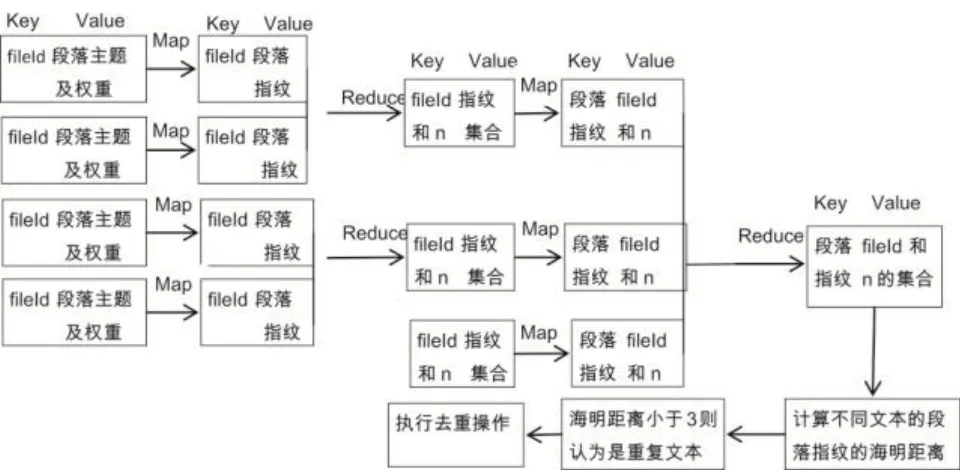
图2 基于MapReduce的去重流程
其中fileId代表文本的ID,n代表文本的段落数。
DRPKP算法实现包含两个MapReduce过程。
第一个MapReduce过程,以提取段落指纹为Map函数,输入为段落主题及权重,输出为根据3.1中的Step4得出的段落指纹;以生成文本指纹集合为Reduce函数。第二个MapReduce过程为计算海明距离做准备,把第一个MapRduce过程的结果做倒排,产生段落指纹与包含该段落文本的对应关系,结果用于计算海明距离,根据海明距离来判断两个文本是否重复。
在实际实验中,判定两个文本是否重复的海明距离阈值设定为3,这个数字是与文本所包含的平均段落数有关的经验数字,文本包含的段落数越多,相应的阈值也会越大。
3 DRPKP算法对金融证券类文本去重结果验证
为了验证DRPKP算法在特定行业文本去重中的效果,我们在国泰君安的金融资讯和统一检索平台上进行了实验。该平台是一个基于主题域的资讯整合平台,包含文本数据的总量超过300GB。基于随机采样,我们得到大小分别为10G、20G、50G、100G、200G的5组文本数据,通过分组测试,对比SimHash和DRPKP算法在去重准确率、覆盖率和去重时间3个方面的去重效果。
通过对5个文本集合进行去重操作,得出两种算法各自的准确率和覆盖率的如表1所示:
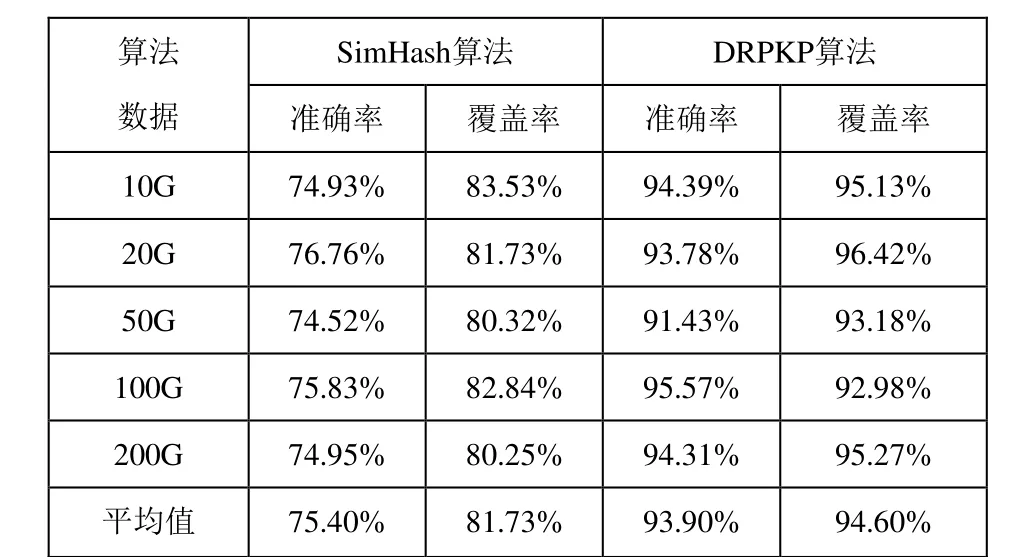
表1 两种算法的准确率和覆盖率比较
DRPKP算法的平均准确率和平均覆盖率比SimHash算法分别提升24.5%和16.34%。这意味着在实际去重中,可以准确发现并消除90%以上的重复数据。
为了比较DRPKP算法与SimHash算法的处理速度,将SimHash算法也采用MapReduce方式进行了实现。实验中,我们构建了10节点规模的MapReduce环境,8个Map节点,2个Reduce节点。两种算法的去重时间的对比如图3所示:
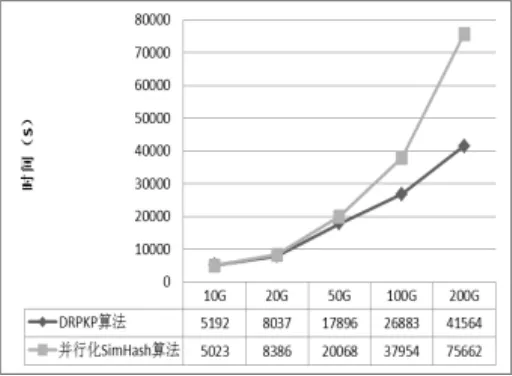
图3 算法的去重时间对比
可见DRPKP算法所需时间短于并行化的SimHash算法。
图3的结果的意义在于,虽然DRPKP算法基于指纹集合进行比较,理论上比SimHash要复杂一些,然而在分布式并行运算的框架下,文本数量和中间结果均被并行化处理,使SimHash在理论上的速度优势被削弱。由于特定行业文本数据的天然相似性,使得文本数量增大时,主题关键词、文本结构特征均出现收敛特性,即文本数量越多,段落指纹集合的归约效果越明显。因此,在特定行业文本去重中,随着文本数量的增多,DRPKP算法的速度优势就越发明显。
通过以上的对比测试验证了DRPKP算法在去重准确率、覆盖率和去重时间3方面均优于SimHash算法,其中DRPKP算法比SimHash算法平均准确率可提高24.5%、平均覆盖率可提高16.34%,而且在特定行业文本去重方面,DRPKP算法在处理速度上也具备明显优势,这种优势随文本数量的增加而愈发明显。文本去重作为平台的重要组成部分,提高了国泰君安客户与员工的资讯使用效率和使用体验。
4 总结
本文针对文本去重算法SimHash算法在特定行业文本去重方面的不足,提出一种基于DRPKP算法的文本去重方法,并将其在国泰君安的金融资讯和统一检索平台的生产环境中做了对比测试,通过对比DRPKP算法与SimHash算法在去重准确率、覆盖率和去重时间3方面的指标,发现DRPKP算法在准确率和覆盖率方面平均提升24.5%和16.34%,而且去重处理速度更快,结果表明DRPKP算法更加适用于特定行业的文本去重。未来,我们将把基于DRPKP算法的文本去重方法应用于医疗信息检索、网络安全监控等领域,从而进一步验证本文方法的适用性和测试结论。
[1] Charikar M S.Similarity Estimation Techniques from Rounding Algorithms[A].In: Proceedings of the Thirty-fourth Annual ACM Symposium on Theory of Computing[C].New York:ACM,2002:380-388.
[2] 黄涛.布隆过滤器在网页去重中的研究与应用[D].大连:大连海事大学,2013.
[3] 董博,郑庆华,宋凯磊,田锋,马瑞.基于多SimHash指纹的近似文本检测[J] .小型微型计算机系统,2011,11(11):2152-2157.
[4] 马成前,毛许光.网页查重算法Shingling和Simhash研究[J].计算机与数字工程,2009,1:15-17.
Research and Application on Text Duplication Removal Based on DRPKP Algorithm
Yu Feng1,Wang Yinna2
(1.Guotai Junan Securities Co., Ltd., Shanghai200120,China; 2.China Information Technology Co., Ltd. Stored Data,Shanghai200120,China))
SimHash algorithm is one of the best algorithm for text duplication detection and removal. However,it has less consideration on the naturalsimilarity of text in specific fields. Based on our experience in information management and data integration in financing and securities industry, we analyzemost text duplication removal algorithms today, especially focus onSimHash algorithm,and propose an newalgorithm for text duplication detection and removal which is based on paragraph key phrase(DRPKP). We appliedour algorithm to detect and remove text duplication in real data set onGuo Tai Jun An’s Financial Information and Unified Information Retrieval Platform. In comparison withSimHash algorithm,our DRPKPalgorithm performs better with the precision ofduplication removal increased by 24.5%, andthe recallincreased by 16.34%; meanwhile, our DRPKPalgorithm also shows an advantage in operating time.
Image Retrieval; Gaussian Pyramid; Color Histogram.
TP311
A
1007-757X(2014)01-0058-03
2013.12.20)
项目资助:国家科技支撑计划课题“证券与金融产品交易综合服务示范”资助(编号:2012BAH13F03)
俞 枫(1969-),男,博士,国泰君安证券股份有限公司,高级工程师,主研方向:系统构架设计、IT规划,上海,200120王引娜(1986-),女,华存数据信息技术有限公司,硕士,研究方向:大数据、云计算、数据挖掘、机器学习,上海,200120
猜你喜欢
今日农业(2022年15期)2022-09-20
小学阅读指南·低年级版(2022年5期)2022-05-09
今日农业(2021年21期)2021-11-26
小学阅读指南·低年级版(2020年9期)2020-10-12
阅读(快乐英语高年级)(2020年9期)2020-01-08
散文诗(2017年17期)2018-01-31
老年医学与保健(2017年6期)2017-02-06
西南交通大学学报(2016年6期)2016-05-04
林业与生态(2016年2期)2016-02-27
西北工业大学学报(2015年1期)2015-02-22
