
互信息在图像检索中的应用
2014-08-07 13:20盛仲飙
微型电脑应用 2014年1期
盛仲飙
互信息在图像检索中的应用
盛仲飙
介绍了一种用互信息来衡量相似性图像检索方法。该方法首先生成一种在统计上有代表性的视觉模式,使用这种模式的分布作为图像内容的描述符;基于该内容描述,设计了其互信息的计算方法以衡量图像的相似性。实验结果表明,在图像检索中,相对于其它如KL散度和L2规范等方法,互信息是一种更为有效的衡量相似性的方法。
图像检索; 互信息;高斯金字塔;颜色直方图
0 引言
基于内容的图像索引和检索是目前计算机视觉、图像数据库与知识挖掘领域最活跃的研究热点之一。 它直接对图像进行分析和抽取特征,利用这些描述图像内容的特征建立索引;其实质是一种近似匹配的技术,采用某种相似性度量对图像库中的图像进行匹配,以获得查询结果。
相似性测度是图像索引中的一个关键环节,测度的选择是否合理,直接影响到图像检索的准确性。互信息作为一种相似性测度方法有很多优点,首先,互信息测量了变量之间的普遍性统计关系。其次,对于变量的单调线性变换,其互信息是不变的;再次,互信息能够直观说明相似性大小。利用互信息作为相似性的衡量标准,检索结果是和样本图像具有最大的互信息的图像,或者说,这些被检索的图像应该能表达样本图像的最大信息量[1-5]。
1 互信息相似度量的图像表示
图像的内容描述往往采用颜色和纹理特征[1]。图像的表示方法对相似性测量效果有直接的影响。在没有标准的图像内容表示法时,本文采用了这样的一种方法:学习统计上有代表性的视觉模型,它同时描述了图像纹理和颜色分布特性。
首先把一个给定的图像分解成一个多层次的高斯金字塔,在每一级,该图像由对立的色彩空间来表示,令表示图像金字塔的第级图像,这些图像然后转换到一个对立空间。用空间,在每一级形成像素的图像补丁(块)。令为第l级图像补丁,对于每一个补丁块,我们建立的向量了形式如公式(1)
其中,al 是非彩色外观向量,cl 是Bl(i, j)块的彩色向量。对于各级金字塔,使用单一均匀尺寸(4×4像素)的块,它覆盖的了原图像的中面积为4×4,8×8,16×16,32×32,...的像素区域,覆盖面积取决于向量在金字塔的哪一级。然后,使用矢量量化来为非彩色向量(所有分辨率)和彩色向量(依然是所有分辨率)设计各自的码本。显然非彩色向量为16维,彩色向量为8维。
设计好的码本就可以代表图像的内容,一个图像通过如下四个步骤来检索:
(1)将图像分解成一个L级高斯金字塔;
(2)对于每个l级(l = 1, 2, …, L),将图像分成4×4块(相互可以交叠),对每一块,通过(1)来计算消色差和彩色向量,并且根据各自的码本,对这些向量进行编码。
(3)对于每个l级(l = 1, 2, …, L),构建一个非彩色视觉模式直方图和彩色视觉模式直方图, 这些直方图记录在对图像块进行编码时每个码字的出现频率。
(4)连接各级消色差和色彩直方图来构建最终图像符。
3 互信息及其计算
假设X = (x1, x2, …, xn), Y = (y1, y2, …, yn)是二进制码的直方图,xi 和 yi 是相应直方图的第n个二进制数。X 和Y 的互信息[3,10,13]定义为公式(2):
其中,H(X) 是X直方图的香农熵,由二进制数的概率分布计算可得。此处的香农熵不同于图像熵,图像熵可以由二进制数直接计算可得。将X的二进制数设为a,0≤a≤1。二进制数的概率分布可以定义如公式(3):
其中,δ是狄拉克δ函数。在离散情况下,a是一个不连续的量,积分用“和”来代替。 H(X|Y) 是基于条件概率P(X = a | Y = b)的条件熵,在Y的值为b的情况下X为a的概率。
熵是一种不确定性度量。因此,方程式(2)的含义为当直方图X的不确定度减去直方图Y(Y的内容)已知时X的不确定度。因此,当Y已知时,X的不确定度减少的量为交互信息I(X; Y),或者说,Y包含了关于X的信息量。交互信息是对称的,也就是说I(X; Y) = I(Y; X),因此互信息也是x中包含的关于Y的信息量。
互信息也可以定义为直方图的联合概率分布为公式(4):
估计直方图X和Y的联合概率P(a, b)=P(X=a, Y=b),最简单的办法就是计算相应的二进制码值的共生矩阵。共生矩阵可以记为CM(a, b),它记录了二进制量X (其值为a)与相应的二进制量Y(其值为b)一致的次数。这与应用于纹理特性的共生矩阵类似公式(8)。基于图像配准的交互信息使用了一种类似的方法来估计两个图像的联合概率[6]。联合概率通过记录除以共生矩阵记录的总次数来获得联合概率。P(X=a) 和P(Y=b)的边缘分布可以通过共生矩阵的行和或者列和得到。
联合概率也可以使用Parzen窗口技术来估计得到[7]。假定vi = (xi, yi),uj = (xj, yj)为对应X,Y的二进制值,vi = (xi, yi)联合概率可以定义为:
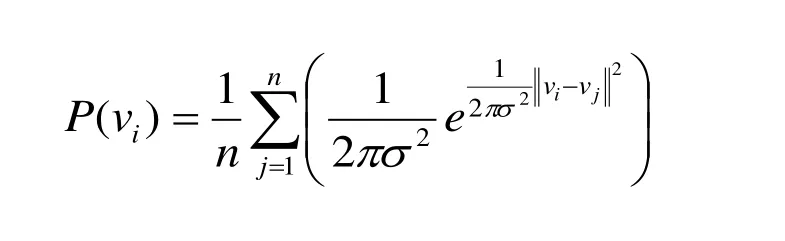
4 实验结果
大量实验来研究基于交互信息的图像检索的性能。我们所使用的数据库是Corel库存图像数据的集合。对于每张图像,我们都使用了3级高斯金字塔,彩色和消色差模式的密码长度都是64位。
在实验中,我们进一步定义了2种基于交互信息的相似性度量方式。归一化的互信息定义为公式(6):

信息距离测度(MID)定义为公式(7):
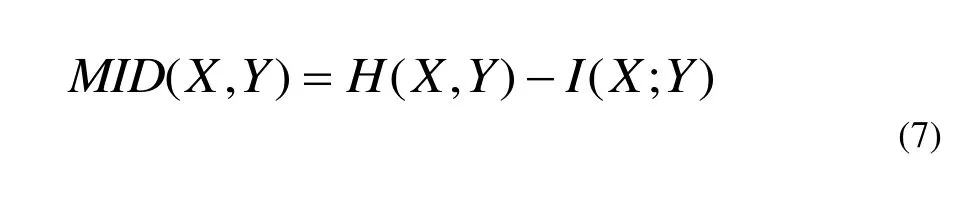
其中,H(X, Y)为相关平均信息量,MID满足距离公理:MID(X, Y) ≥ 0, MID(X, X) = 0, MID(X,Y)=MID(Y, X),MID(X,Y)+MID(Y, Z)≥MID(X, Z).
作为比较,我们同样完成了KL散度测量,标准相关度、欧几里得距离作为相似性度量。
假定Qi作为第i级查询图像,i=1,2…,k,并且令Qi(1), Qi(2),…,Qi(Ni)作为Ni 个查询图像Qi的 “正确” 答案。我们定义了如下的平均累计召回措施为公式(8):
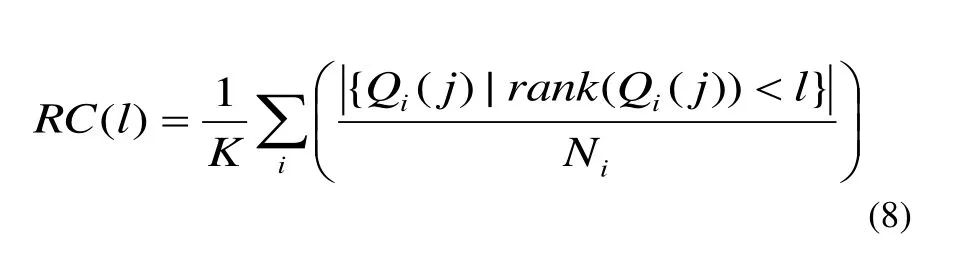
显然,较大的RC(1),性能就越好。 我们还定义了下面的精度测量为公式(9):
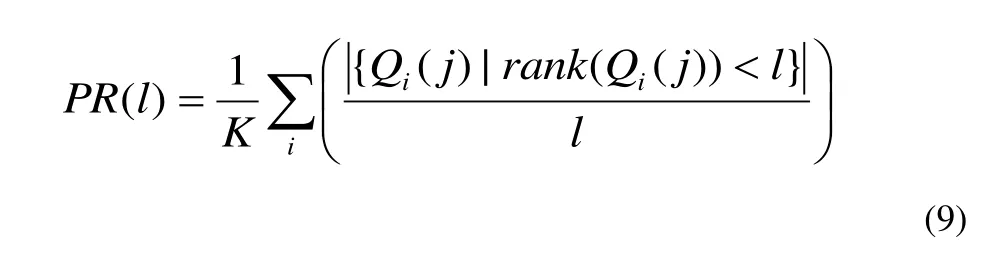
同样,较大的PR(1)所对应的性能越好。选择3个类动物图像作为查询实例和目标图像,它们是猎豹,老虎,狮子的动物形象。图像数据库的总大小是10,000。对于每一种相似性的衡量措施,交互信息(MI),归一化互信息(NMI),交互信息距离(MID),利用Kullback-Leibler散度(KLD),归一化相关(NC),和欧氏距离(ED),我们进行了300次查询,就是每个狮子,老虎,猎豹类别中的图像都被用来作为一个查询。这些查询的检索率和精确性如图1和2所示:
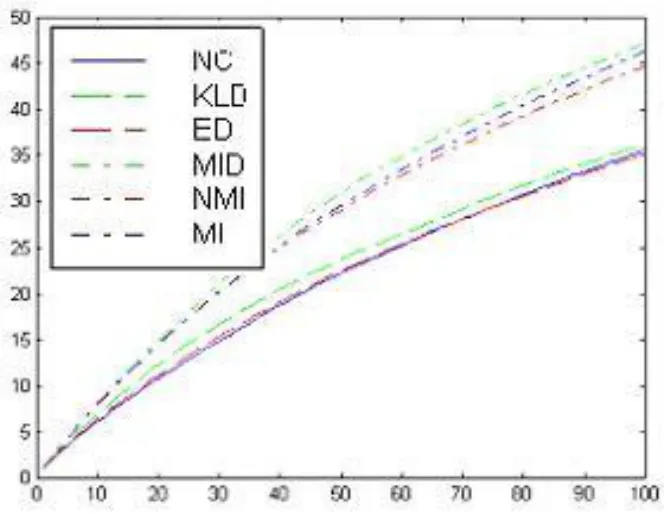
图1.不同相似性度量的召回率
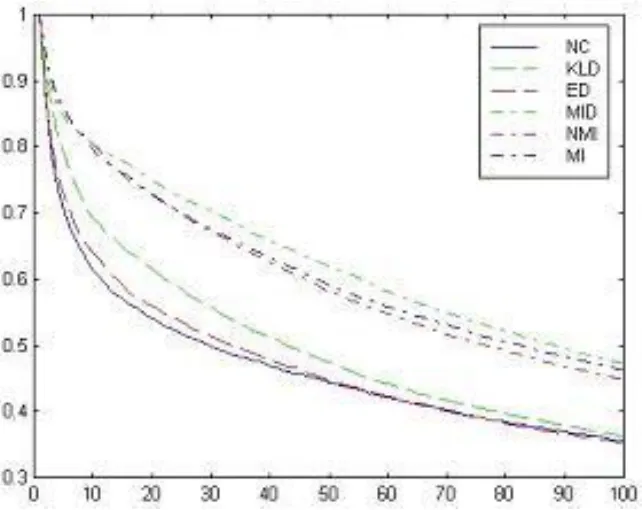
图2. 不同相似性度量的精确度
从图1和2可以看出,交互信息衡量相似性的表现优于其他措施。我们注意到交互信息定义量X和Y等于Kullback_Leibler 分散度而且和Kullback_Leibler发散角有密切的关系,事实上,交互信息I(X,Y)介于联合概率函数P(X,Y)和概率函数p(x)和P(Y)的积之间。然而,我们的结果清楚地表明,相比Kullback_Leibler散度,交互信息是一种更有效的相似性度量手段。
5 总结
在本文中,我们引入了基于交互信息的图像检索方法,验证了可以使用交互信息作为图像间相似性度量。两个图像具有更高的交互信息,意味着知道了一个图像能表达另一个图像更多的信息,因此互信息自然是一种衡量图像间相似性的手段。最后设计了一种计算图像的视觉直方图之间交互信息的方法,实验结果证明了相比于所广泛使用的方法,交互信息衡量手段具有很大的优越性。这种方法可以很容易地扩展到其他的图像内容描述符,如颜色相关图、MPEG-7颜色描述符和其他广泛使用的图像描述符。
[1] Minakshi Banerjee, MalayK. Kundu, Pradipta Maji.Content-based image retrieval using visually significant point features, [C]Fuzzy Sets and Systems 2009,160: 3323–3341
[2] Thomas Hurtut, Yann Gousseau, Francis Schmitt, Adaptive image retrieval based on the spatial organization of colors, [J]Computer Vision and Image Understanding, 2008, 112 : 101–11
[3] Maciej A. Mazurowski, Joseph Y. Lo, Brian P. Harrawood, Mutual information-based template matching scheme for detection of breast masses: From mammography to digital breast tomosynthesis, [J]Journal of Biomedical Informatics, 2011, 44: 815–823 815–823
[4] Feng Wanga, Cheng Yang, Zhiyi Lin, Yuanxiang Li, Yuan Yuan, Hybrid sampling on mutual information entropy-based clustering ensembles for optimizations, [C]Neurocomputing, 2010, 73: 1457–1464
[5] 陈伟卿.基于互信息的医学图像刚性配准研究[D].大连理工大学,2010:26-30.
[6] 谭立球.基于本体的图像检索相关技术研究[D].中南大学,2009(5):65-74.
[7] 陈庆芳.基于分块互信息的图像匹配[J].计算机工程与应用,2011,47(9):160-162.
Application of Mutual Information in Image Retrieval
Sheng Zhongbiao
(School of Mathematics and Information Science, Weinan Normal University, Weinan 714000,China)
An approach for image retrieval using mutual information as a similarity measure is presented in this paper. It is based on the premise that two similar images should have high mutual information, or equivalently, the querying image should convey high information about those similar to it. The method first generates a set of statistically representative visual patterns and uses the distributions of these patterns as images content descriptors. To measure the similarity of two images, we develop a method to compute the mutual information between their content descriptors. Two images with larger descriptor mutual information is regarded as more similarity. The experimental results demonstrate that mutual information is a more effective image similarity measurement than others such as Kullback-Leibler divergence and L2 norms.
Image Retrieval; Gaussian Pyramid; Color Histogram.
TP393
A
1007-757X(2014)01-0055-03
2013.12.08)
陕西省教育厅科学研究计划(自然科学专项)项目(2013JK1165),渭南市自然科学基础研究计划项目(2012KYJ-8)
盛仲飙(1974-),女,陕西渭南人,渭南师范学院数学与信息科学学院讲师,硕士,研究方向:网络计算机应用技术研究,渭南,714000
猜你喜欢
数学物理学报(2022年5期)2022-10-09
中等数学(2021年8期)2021-11-22
河北画报(2020年8期)2020-10-27
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
计算机应用(2016年10期)2017-05-12
浙江大学学报(工学版)(2016年2期)2016-06-05
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
火控雷达技术(2016年2期)2016-02-06
西北工业大学学报(2015年4期)2016-01-19
