
基于特征加权的自动图像分类方法
2014-08-07 13:20王科平张志刚
微型电脑应用 2014年1期
王科平,张志刚
基于特征加权的自动图像分类方法
王科平,张志刚
低层特征的选择与提取是自动图像分类的基础,一方面,所选择的图像特征应能代表各种不同的图像属性,利于不同类别图像之间的区分;另一方面,为了提高后续模型的计算效率,需要减少噪声特征、冗余特征。提出了一种基于特征加权的自动图像分类方法。该方法根据图像低层特征分布的离散程度来衡量特征相对于类别的重要性,增加相关度高的特征的权重,降低相关度低的特征权重,从而避免后续模型被弱相关或不相关的特征所支配。所提的特征加权算法主要考察的是特征相对某个具体类别的重要程度,可以为每个类别选择出适合自身的特征权重。然后,将加权特征嵌入到支持向量机算法中用于自动图像分类,在Corel图像数据集上的实验结果表明,基于特征加权的自动图像分类算法可以有效地提高图像分类的准确性。
自动图像分类;特征加权;支持向量机
0 引言
随着网络图像数据海量增长,图像分类技术变得越来越重要。为了能够得到更好的分类效果,人们一直在努力寻找和设计更能表达图像语义内容的低层视觉特征,这些特征主要有颜色特征,如颜色直方图、颜色矩、颜色聚合向量和颜色协方差矩阵[1,2];纹理特征,如小波变换、Gabor滤波以及关于纹理的一些统计特征等;形状特征,主要是包括可以描述图像区域形状的圆度、傅里叶描述子、长宽比和矩不变量等等[3,4]。上述特征综合起来在某种程度上可以很好的描述图像的视觉特性,相应地,描述图像的特征数据的维数也就变得很高。在图像表示问题中,并不是所有的这些特征数据都具有有效的预测功能,可能存在着低效特征、无关特征,这些特征不但增加了研究系统的复杂程度,而且还可能严重影响图像分类的准确性,如何从中选出区分能力强的特征,合理地构造特征空间是图像分类技术必须重视的问题,并已成为该领域研究的新热点。
在自动图像分类中,所提取的颜色、纹理、形状等这些特征所起的作用不是完全相同,有些特征与分类相关性较高,有些特征与分类的相关性低,所以,不能采取“一视同仁”的方法给它们赋予相同的权重。特征加权旨在根据某种准则为数据集中的各个特征赋予一定的权重,是找出最有效的特征、提高数据分类能力的一种有效方法。在特征加权中,每个特征被赋予一个0~1之间的权重,如果某个特征的相关度比较高,则赋予一个较大的权重,相关度低,则赋予一个较小的权重,不相关则权重为0。目前,已有很多研究成果是关于应用特征加权提高机器学习算法性能的[5-8]。
1 图像的学习方法
文献[9]指出将图像集正确的划分到相应的语义类别将会大大提高基于内容的图像检索系统的性能。目前,很多机器学习算法已被成功用于图像分类,其中,监督学习算法是应用较广的一种图像分类方法,是一种有效的降低语义鸿沟的方法。在监督学习算法中,支持向量机由于其结构简单、具有全局最优性和较好的泛化能力,被广泛地应用于目标识别、文本分类。我们知道,在SVM中,核函数是一个核心问题,核函数的计算常常与样本的特征密切相关,如果样本中存在较多的与分类弱相关或不相关特征,那么,这些特征可能会严重影响核函数的计算,从而最终影响分类器的分类性能。从这个方面入手,研究者提出了很多有效的方法。文献[10]和[11]提出了基于模糊数学的支持向量机模型(Fuzzy SVM, FSVM),该模型为了减少噪声和野值的影响,根据样本对分类贡献的不同,为其赋予相应的隶属度,从而提高分类器的性能。由于样本规模大小不同也可能会造成分类性能的降低,文献[12]对不同规模样本赋予不同的权重,该方法根据类别的差异进行了相应的补偿,大大提高了小类别样本的分类精度,该文献对于需要重点关注小样本类别精度的应用研究有重要的现实意义。文献[13]提出了一种特征加权支持向量机的算法,该算法通过计算特征相对于整个分类系统的信息增益来衡量特征的重要性,然后将加权特征应用到支持向量机的分类过程,取得了较高的分类效果。
在上述文献所提的特征加权算法中,特征权重的计算都是相对整个分类系统的,即它们主要考察特征对整个系统的贡献,而不具体到某个类别,这就使得这些算法比较适合用来做所谓“全局”特征选择(指所有的类都使用相同的特征权重)。本文算法主要是针对“本地”的特征选择,即,每个类别有自己的特征权重。因为在图像分类中,特征与类别的相关度是不一致的,有的特征,对某个类别有较高的区分度,而对另一个类别则无足轻重,例如,颜色特征对图像类别为“太阳”的影响程度较高,而位置特征对“太阳”的影响程度相对较低。因此,建立和类别相关的特征权重是本文研究的主要内容。通过对图像特征分布情况的分析发现,特征相对类别的重要程度可以根据特征的统计分布来衡量,所以,本文提出了一种新的特征加权算法,该算法根据图像特征统计分布的离散程度来计算特征与类别的相关程度,增加相关度高的特征的权重,降低相关度低的特征权重,从而避免后续的学习算法被弱相关或不相关的特征所支配。然后,在加权特征的基础上结合支持向量机算法实现自动图像分类。由于,得到的特征权重是和图像类别相关的,所以在采用训练好的SVM算法进行分类时,我们先为图像进行多种加权处理,然后采用投票制度,根据投票结果进行分类。最后在Corel图像集1000幅图像上进行实验,结果表明本文的特征加权算法可以有效提高图像分类性能。
2 特征权重计算方法
图像特征分布具有这样的特性:在同一个图像类别中,如果某个特征的统计分布比较密集,离散程度比较小,那么这个特征相对与这个类别是起支配作用的,是一个重要的特征。相反,如果某个特征统计分布比较分散,离散程度比较高,则这个特征对于这个类别重要度就低如图1所示:

图1 某类图像前两维特征分布
图1(a)为某个图像类别,30幅图像的第一维特征分布,图1(b)为该类图像的第二维特征分布。从图示可以看出,该类图像的第一维特征分布比较离散,而第二维特征分布则比较集中,所以可知,第一维特征的重要性要低于第二维特征的重要性。那么,如何根据特征的分布特性来计算这个特征的这个重要程度,是我们实现特征权重计算的关键。
由于数据的标准差可以很好的反映数据集的离散程度,所以,本文采用标准差来衡量图像的特征权重。标准差是各数据偏离平均数的距离(离均差)的平均数,能反映一个数据集的离散程度,可以很好的描述数据的波动性。数据分布越密集,则波动越小,相应的标准差也就越小。相反,数据分布越分散,则波动越大,相应的标准差也就越大。所以,标准差可以很好的刻画我们图像特征的分布情况。
下面我们来看具体的特征权重计算方法。
由于每类特征的取值范围都不一致,且相差比较大,所以需要先对特征进行归一化处理。本文采用式(1)对特征进行归一化为公式(1):

下面计算特征的标准差,设样本集中类别为j 的第l 维的标准差为,为公式(2):
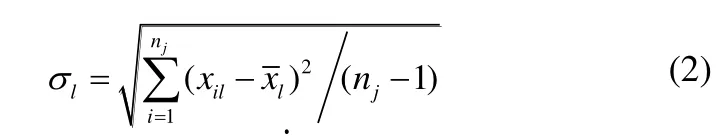
因为特征的重要程度和特征分布的离散程度是成反比的,离散程度高,特征重要程度低,相反离散程度低,即,标准差小,则该特征的重要性越高。本文用来表示特征的重要性,其计算公式为公式(3):

当某维特征分布相当密集时,其标准差会非常小,若特征取值为同一值,则标准差为零,这时为1;越大,相对应的越小,表明该特征的重要性越小。具体每个样本每维特征的计算方法如公式(4):

在后续文中,采用公式(4)得到的权重为每维特征加权。
3. 基于特征加权支持向量机的图像分类算法
3.1支持向量机
支持向量机(Support vector Machines,SVM)是由Vapnik等人于20世纪90年代中期提出,它是建立在统计学习理论基础上的一种机器学习方法[14]。支持向量机应用VC维理论和结构风险最小化原理进行训练,在很大程度上克服了传统机器学习方面所面临的维度高、局部极小值以及过学习等困难,并具有良好的推广能力。由于支持向量机出色的学习性能,使得其在模式识别和模式分类等问题中得到广泛的研究与应用。
支持向量机的最初研究是从两类线性可分情况下发展而来的。给定一个线性可分的样本集,)}是输入向量,是类别标签,SVM方法就是为了寻找一个两类之间的最优分类面或最优超平面。若超平面0能将样本正确分为两类,则最佳超平面b=应使两类样本到超平面最小距离之和最大,这种最优超平面是由离它最近的样本点,也称支持向量决定,与其他样本点无关。根据实际问题的需要,后来SVM扩展到可以处理线性不可分的情况。主要是通过非线性映射将要处理的数据映射到高维特征空间,在该空间,数据可以实现线性分类。

利用拉格朗日乘子算法,可以把式(5)优化问题转化为下面的对偶问题为公式(6):
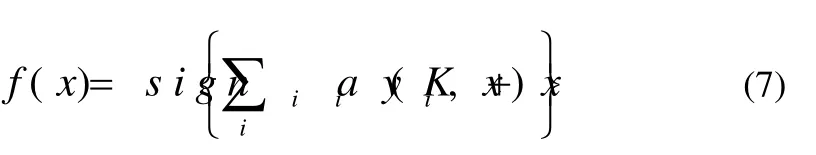
3.2基于特征加权支持向量机图像分类
SVM算法属于有监督机器学习算法,在学习过程中,首先需要利用已标注的数据集对SVM进行训练学习,然后将训练好的SVM应用于测试数据分类。本文注重的是得到本地特征权重,即,特征的权重和类别是相关的,图像类别不同,特征的权重是不一样的。我们用训练集中的样本计算出每个类别的特征权重,赋予相应的特征,用加权特征学习SVM分类模型。对于待分类图像,分别采用训练样本得到的权重进行加权,然后选用概率最大的作为图像的类别。


E和P为两个类别的特征加权矩阵,这些特征为对角阵,具体表达形式如公式(9):是由公式(4)计算得到,不同的图像类别得到不同的加权矩阵。本文处理的是多类问题,我们采用下式来确定图像的最后类别如公式(10):
其中E和P

标准的SVM是一种典型的两类分类器,而现实中要解决的问题,往往是多个类别的分类问题,比如文本分类、数字识别、图像分类等。如何由两类分类器得到多类分类器,就是一个值得研究的问题。现在常用的方法是将多类问题分解成若干个两类问题来处理。其中“一对一(one-versus-one,OVO)”和“一对其他(one-versus-rest,OVR)”是两种主要的方法。OVR方法将其中一类视为正类,其余类别视为负类,该方法会加剧样本不平衡带来的负面影响,恶化分类效果。OVO方法会为每两类建立一个分类器,然后采用投票的方式,将样本分配给的票最多的类别。在分类类别相对较少的情况下,OVO具有明显的分类优势,所以本文采用OVO的方法进行图像分类。
基于特征加权支持向量机图像分类的具体算法描述如下:
Step2:根据第2节中的描述,用公式(2)、 (3) 、(4)计算训练集每类中每个特征权重。

图2 10类图像样本

Step3:将Step2得到的权重赋予训练集每个样本,即公式(11):为某类图像第个特征的权重,为样本集中该类图像第图像样本的第个特征取值,为更新后的特征权重。
Step4:用加权后的特征训练SVM分类模型。
Step5:在为未标注图像分类时,分别用每类特征权重为未标注图像加权,然后用训练好的SVM分类模型分类,最后根据式(10)投票结果来判别图像类别。
4 实验与分析
为了验证本文所提出的基于特征加权的自动图像分类算法的有效性,我们采用了在图像分类、标注中普遍使用的Corel数据集。本实验从Corel数据集中选择1000幅图像,分别属于10个CD-ROMs,每个Corel CD-ROM目录下包括100幅图像,表达同一个主题概念。所有图像为JPEG格式,大小为384x256 or 256x384。由于本实验着重发掘图像特征相对于分类的重要性,所以选择的每类图像在视觉上都具有比较明显的共同特点如图2所示:
从每类中出1幅图像作为样例。这些类别分别是sun(太阳),beach(海滩),building(建筑),bus(公共汽车),desert(沙漠),elephant(大象),flower(花),horse(马),snow mountain(雪山)和food(食物)。
本实验每幅图像提取8个纹理特征,9个颜色特征。将1000幅图像分为训练集和测试集两部分,训练集包括300幅图像,每类30幅,剩下的700幅用来测试。通过对比特征加权支持向量机和普通支持向量机在图像集上的分类结果来验证本文所提算法的性能,如表1,表2所示:

表1 标准SVM算法在10类图像中的分类结果

表 2 本文算法在10类图像中的分类结果
表1与表2分别为标准SVM在Corel图像集上的分类结果与本文算法的分类结果,通过两表的数据对比,可以看出特征加权支持向量机在图像集上的预测结果要优于标准支持向量机的预测结果。从表1可以看出在第二类beach类,标准SVM的正确标注结果是67.1%,由于本文采用了特征加权,增强了特征的区分能力,将该类的标注精度提高到了77.2%。加权特征的应用使得与类别相关度高的特征得到加强,有利于类内图像的聚集,增加类间图像的区分度。由实验结果可以看出,基于特征加权的分类算法在多数类别比标准SVM的分类效果好,平均标注精确度由70.4%,增加到72.5%。
5 总结
图像自动分类问题是计算机视觉领域中备受关注的问题,由于图像底层特征与高层语义概念之间“语义鸿沟”的存在,目前已有的自动图像分类方法还不能令人满意。本文提出了一种基于特征加权的自动图像分类方法,该方法考虑到图像特征对分类系统的贡献不同,分别为特征赋予不同的权重。论文首先根据特征分布的离散程度来衡量特征的权重,增强高度相关特征在分类中的作用,避免后续标注算法被弱相关或不相关的特征所支配。加权特征的应用使得与类别相关度高的特征得到加强,有利于类内图像的聚集,增加类间图像的区分度,所以使图像整体分类效果得到提高。在Corel图像数据集上的实验结果表明本文所提算法具有良好的图像分类性能。本文特征权重的计算只考虑了低层视觉特征的统计分布情况,没有考虑特征的其他属性,比如特征之间的相关特性,结合特征的其他特性设计特征权重计算方法是一个很有意义的研究内容。
[1] X. Wang, J. Wu, H. Yang.Robust image retrieval based on color histogram of local feature regions[J]. Multimedia Tools and Applications, 2010. 323-345.
[2] T. Lu, C. Chang. Color image retrieval technique based on color features and image bitmap[J]. Information Processing and Management, 2007. 461-472.
[3] Ju Han, Kai-Kuang Ma. Rotation-invariant and scale-invariant Gabor features for texture image retrieval[J]. Image and Vision Computing, 2007. 25(9): 1474-1481.
[4] C.S. Sastry, M. Ravindranath, A.K. Pujari. A modified Gabor function for content based image retrieval[J]. Pattern Recognition Letters, 2007. 28(2): 293-300.
[5] Ran Li, Jianjiang Lu, Yafei Zhang, et al. Dynamic Adaboost learning with feature selection based on parallel genetic algorithm for image annotation[J]. Knowledge-Based Systems, 2010.23(3): 195-201.
[6] L. Setia, H. Burkhardt. Feature selection for automatic image annotation[J]. Lecture notes in Computer Science, 2006. l.4174: 294-303.
[7] L. Wang, L. Khan. Automatic image annotation and retrieval using weighted feature selection[J]. Springer Science + Business Media, LLC 2006, Multimedia Tools Applications,2006. 29(1): 55-71.
[8] 李洁, 高新波, 焦李成. 基于特征加权的模糊聚类新算法[J]. 电子学报, 2006.
[9] Li J, Wang JZ. Automatic Linguistic Indexing of Pictures by a Statistical Modeling Approach[J]. IEEE Trans. On Pattern Analysis and Machine Intelligence,2003.25(19): 1075-1088.
[10] C. Lin, S. Wang. Fuzzy support vector machines[J]. IEEE Trans.Neural Netw. 2002.13(2): 464–471.
[11] 张翔, 肖小玲, 徐光祐. 基于样本之间紧密度的模糊支持向量机方法[J]. 软件学报, 2006. 17(5): 951-968.
[12] 范昕炜, 杜树新, 吴铁军. 可补偿类别差异的加权支持向量机算法[J]. 中国图像图形学报, 2003. 8(9): 1037-1042.
[13] 汪廷华, 田盛丰, 黄厚宽.特征加权支持向量机[J], 电子与信息学报, 2009. 31(3): 514-518.. Cortes and V. Vapnik. Support-Vector Networks[J], Machine Learning, 1995. 20(3): 273-297.
Based on Feature Weighted Automatic Image Classification Method
Wang Keping1, Zhang Zhigang2
(1.School of Electrical Engineering and Automation, Henan Polytechnic University,Jiaozuo454003,China; 2. School of Information Engineering, Jiaozuo University, Jiaozuo454003,China)
The low-level feature selection and extraction are the basic problems for automatic image annotation. On the one hand, the selected features must represent the various characters of the images and be beneficial to classify the images. On the other hand, we should limit the dimension of the feature vector and reduce the redundancy of the features to save the posterior computing energy. In this paper, an automatic image classification based on the weighted feature is proposed. This method determines relevant features based on their statistical distribution and assigns greater weight to relevant features as compared to less relevant features, which will avoid the classification model being dominated by weak relevant or irrelevant features. Then we combine the weighted feature algorithm with the support vector machine (SVM) algorithm to realize the image annotation. Experimental results on the Corel image set show that the weighted feature image classification method can effectively improve the performance of classification.
Automatic Image Classification; Weighted Feature; Support Vector Machine (SVM)
TP317.4
A
1007-757X(2014)01-0013-05
2013.11.18)
王科平(1976-),女,河北张家口人,河南理工大学,副教授,博士,研究方向:图像理解,模式识别,焦作,454003张志刚(1976-),男,河北张家口人,河南理工大学,讲师,硕士,研究方向:图像处理、识别,焦作,454003
猜你喜欢
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
民族古籍研究(2018年1期)2018-05-21
新校长(2016年8期)2016-01-10
应用科技(2015年5期)2015-12-09
浙江大学学报(工学版)(2015年1期)2015-03-01
医学理论与实践(2014年5期)2014-03-06
医学理论与实践(2014年23期)2014-03-06
中国中医药现代远程教育(2014年16期)2014-03-01
医学理论与实践(2012年4期)2012-12-09
