
三枝粗糙集和变粒度原理的手写体汉字识别
2014-08-04 02:38王建平王梦泽
计算机工程与应用 2014年22期
王建平,王梦泽
合肥工业大学电气工程及自动化学院,合肥 230009
三枝粗糙集和变粒度原理的手写体汉字识别
王建平,王梦泽
合肥工业大学电气工程及自动化学院,合肥 230009
手写体汉字识别是超多类模式识别问题,被公认为是模式识别领域中难题之一。粗糙集理论已经成功地运用到手写体汉字识别的研究中,但是仍然存在诸多的不完善,本文利用三枝粗糙集原理解决如何建立较完备稳定的特征表示和提取方法,以及处理不确定、不精确和不完全性特征信息的识别决策机制[1]。
粗糙集理论于1982年由波兰科学家Pawlak提出,它是一种研究不确定、不完整知识和数据的表达、学习、归纳的理论方法[2]。将粗糙集理论用于手写体汉字识别,建立特定空间上的等价关系分类机制,构成了对手写体汉字识别是超多类模式识别该空间的划分,并将真实属性知识理解为对手写体汉字识别超多类模式数据的划分,每一被划分的集合称为概念。
在变精度粗糙集模型中,阈值参数由专家给定,没有语义解释,而基于三枝粗糙集理论的决策粗糙集模型不仅给予了概率粗糙集模型一种基于贝叶斯最小风险下的语义解释[3-5],而且阈值参数可以直接计算得出,针对这一情况,本文研究基于三枝粗糙集原理,构建期望风险最小决策的语义下决策粗集理论基本模型的过程。
引入粒度原理,从属性重要度的角度出发,结合信息粒度的逻辑运算,形成凝聚式的自下而上的信息粒网的构建,形成决策信息系统特征约简集的粒度网结构,最终构成由特征属性和决策属性组成的决策系统。
1 脱机手写体汉字识别决策信息系统
1.1 手写体汉字识别信息系统
根据粗糙集理论对广义论域信息系统的定义[6-7],对脱机手写体汉字识别信息系统可作如下定义。

1.2 三枝粗糙集的汉字识别决策信息系统
模仿人类有导师的学习识字过程,将手写体汉字的真实值D=d作为先验知识加入到脱机手写体汉字识别系统S=(U,A,V,f)中来指导训练过程中的决策。
定义2设手写体汉字识别信息系统S=(U,A,V,f),若A中的属性可分为两个不相交的子集,即A=C∪D,C∩D=ϕ,其中C={C1,C2,…,Cn}为条件属性集,即所提取的手写体汉字样本特征集;D={d}为决策属性集,即样本汉字的真是属性。记其中RC表示特征属性集C中所有特征值相同的汉字样本组成的等价类,Rd表示真实值相同的汉字样本组成的等价类,这两种等价类分别对手写体汉字样本集U进行了划分。若RC⊆Rd,即特征属性对样本汉字的划分细于真实属性对样本汉字的划分,即所选特征足以将样本汉字正确分类,则S=(U,A,V,f)称为脱机手写体汉字识别决策信息系统。
定义3P(Rd|Rc)为手写体汉字特征属性集Rc关于汉字真实属性集Rd的相对正确分类率;设λ=(ai|Rd)为当手写体汉字样本的真实值为Rd时采取动作a的损失函数,则该动作所带来的预期可表示为:


该决策过程的实际意义是,当采取某种动作所带来的风险不超过其他两种动作所带来的风险时,就采取该动作,对于决策代价函数值的大小,根据上述条件,决策规则可重新定义为:

当β=0和α=1时,上述模型将转化为pawlak粗集模型。当β=α=0.5时,上述模型转换为0.5概率粗集模型。一般不要超过两行。
1.3 决策信息系统约简
定义概率粗糙集模型的属性约简[9-10],假设决定一个信息表,S=(U,A,V,f),一个属性集B⊆C是C关于D的一个约简;定义概率粗糙集模型的属性约简它满足如下两个条件:

(S)性质保留性:

2 粒度原理的手写汉字特征属性定义
2.1 几个性能指标熵的定义

其中,I(D|B(α,β))表示手写体汉字样本特征属性子集B(α,β)确定后脱机手写体汉字识别决策信息系统所残留的平均信息量,残留的不确定性,I(D|B(α,β))越小,说明D与B(α,β)相关性越大,识别错误率越小。
2.2 手写体汉字特征属性重要度的定义


3 利用属性及重要度构建多粒度结构
3.1 粒的内部结构、粒集的组织结构
粒的内部结构表示为:G(A,W,Gp,Gc);其中G为一个粒,A为粒的属性集,W为属性重要度集,Gp为该粒的父粒集,Gc为该粒的子粒集,A按照属性重要度递减的顺序排列。粒的相似性分为两种[12-13]。

3.2 粒的计算
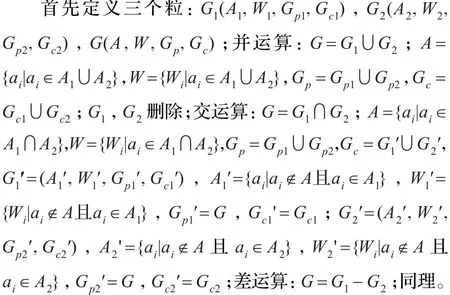
3.3 粒度网的构建
从特征属性重要度的角度出发,研究设计了一种基于特征属性重要度的自下而上的粒度网的构建策略[13],该算法按照特征属性重要度递减的顺序构建,并结合粒度之间的并、交、差运算,使系统可以更好获取信息,使得每层的粒度适用度逐层变大。分裂式粒度网构建流程图。
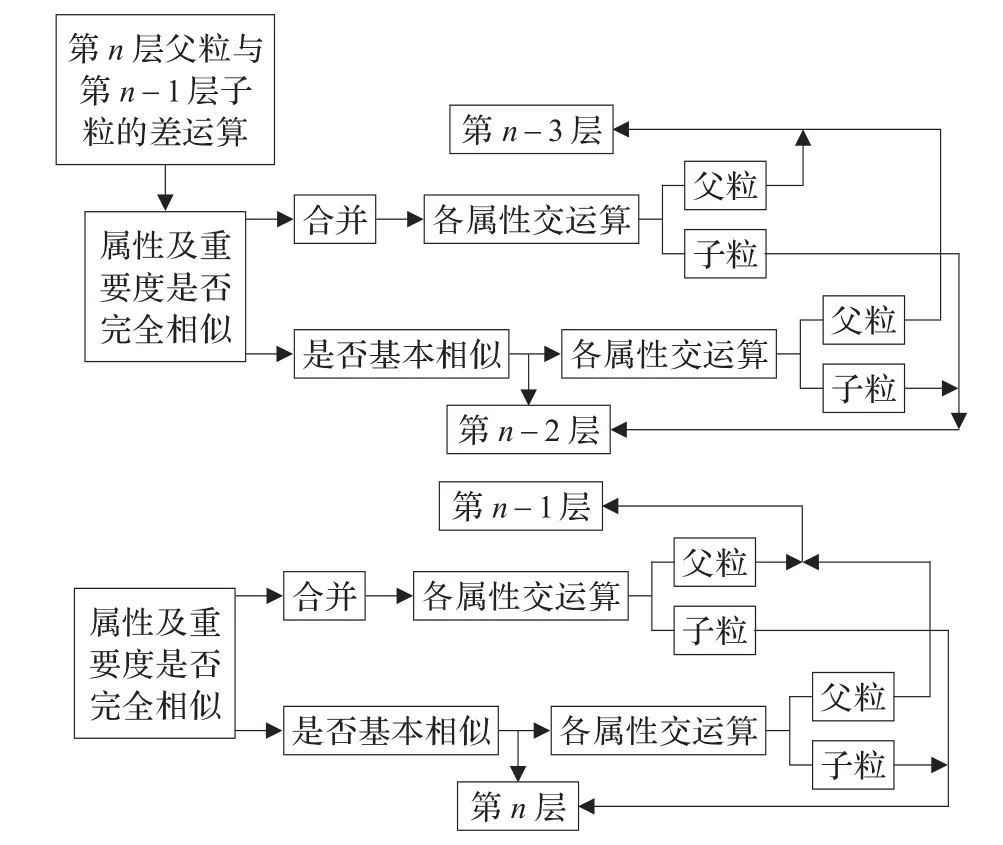
图1 N层特征递阶约简示意图
步骤1根据已有汉字特征属性及其权重进行分组,把属性及其权重完全相似的特殊应用合并,基本相似的特殊应用分为一组,构成不同分组,分组内进行交运算,父粒形成倒数第2层,剩余属性形成最底层粒。并将此层与决策属性的并集进行约简。如果约简后决策属性唯一则直接输出匹配规则,如果不唯一,则继续建立下一层决策系统。
步骤2对所有汉字特征属性与其有父子联系的倒数第2层粒进行差运算,把特殊应用的剩余属性根据属性及其权重分组,把属性及其权重完全相似的特殊应用合并,基本相似的特殊应用分为一组,构成不同分组,分组内进行交运算,父粒形成倒数第4层。重复上述骤。
步骤3…N:以此类推逐渐形成领域适用粒度逐渐变大的层次多粒度树。具体算法如下:
算法1基于特征属性相对重要度的分层递阶约简算法。
输入:手写体汉字识别决策信息系统S=(U,C∪D,V,f),其中U={x1,x2,…,xn}为待训练手写体汉字样本集;C={c1,c2,…,cn}为所提取的手写体汉字样本特征集,即条件属性;D={d}为汉字的真实值,即决策属性集。
输出:属性约简集B和识别规则。
(1)属性分层
①由公式分别计算手写体汉字决策信息系统的相对粒度熵I(D/{ci}),i=1,2,…,n。
②令Bβ为使I(D/{ci})最大的特征属性,对ci∈{C-Bβ}分别按照定义8计算SGF(ci,Bβ,D)并按递减顺序排列。
③按照属性重要度排序的顺序,依次将每2个相邻权重的属性记作一个粒G1,如{G1,G2,…,Gn},再根据相似性定义计算每2个粒的特征属性重要度及属性的相似程度,分别进行并,交,差运算,记作:AGi,i={1,2,…,n}形成一个自下而上的,粒度逐渐变细的粒度网结构。
(2)第一层决策系统
图1由逻辑运算得到的第n层与决策属性d构成的第一层决策系统,记作:(AG1,d);对首层决策系统进行约简,得到其简约,如果输出结果唯一就停止运算。如果输出不唯一,继续进行下一步。
(3)次层决策系统
图1所示,逻辑运算得到的第n-1层与决策属性d的构成次层决策系统,记作:(AG2,d);步骤如上所示。
(4)当属性重要度已分配到最底层,无法向下进时,算法停止。
4 识别规则的融合算法
脱机手写体汉字识别决策信息系统经过手写体汉字特征属性约简以及适当的属性值约简之后,从而得到“if…then…”形式的脱机手写体汉字识别决策规则集。只要找到匹配的条件就可以得到与之相对应的结论,即汉字真实属性,从而完成粗糙集理论下的脱机手写体汉字识别过程。
然而,约简后的手写体汉字特征属性集中的元素取值会出现没有或者有多条识别规则的条件匹配的情况,这时就要解决规则匹配的问题。选用适当的规则融合理论,以解决决策规则不能唯一匹配的问题。
5 实验结果与仿真
为了验证文中方法的有效性,选取SCUT-IRAC手写体汉字图像样本数据库,采用文献[14]特征提取方法,其中选取“中”和“燮”这两个字仿真实验如下。
(1)“中”计算决策风险最小时的阈值β1,实验过程中计算得到9维属性约简集Bβ1的向量为{1,0,0,0,1,0,1,1,1},以及特征属性重要度的顺序{C1,C2,…,Cn},根据本文定义的粒之间逻辑关系得出决策系统为:AG={(AG1,d),(AG2,d),…,(AGn,d)},约简得到对应决策规则为:{a0(1),a1(0),a2(0),a3(0),a4(1),a5(0),a6(1),a7(1),a8(1)}=>D(1),输出D(1,β1),识别正确。
(2)“程”计算决策风险最小时的阈值β2,实验过程中得到9维属性约简集Bβ2的向量为{1,0,0,1,1,1,1,0,2},以及特征属性重要度的顺序{C1,C2,…,Cn},根据本文定义的粒之间逻辑关系的决策系统为:AG={(AG1,d),(AG2,d),…,(AGn,d)},约简得到对应决策规则为:{a0(1),a1(0),a2(0),a3(1),a4(1),a5(1),a6(1),a7(0),a8(2)}=>D(2),输出D(2,β2),识别正确。
再次选取SCUT-IRAC手写体汉字图像样本数据库中“大、目、自、跟、根、鹜、骛”这样的简单字、中等复杂字、复杂字、一对简单相似字和一对复杂相似字进行了实验。实验软件采用Rosetta和Matlab平台下开发的相关算法。其中每个汉字50个样本,分为训练集(90%)和测试集(10%),获得128维特征向量,利用Rosetta和Matlab环境开发相关算法,实现对训练集315个汉字样本的训练以及对测试集35个汉字样本的识别。实验结果如表1、表2所示。
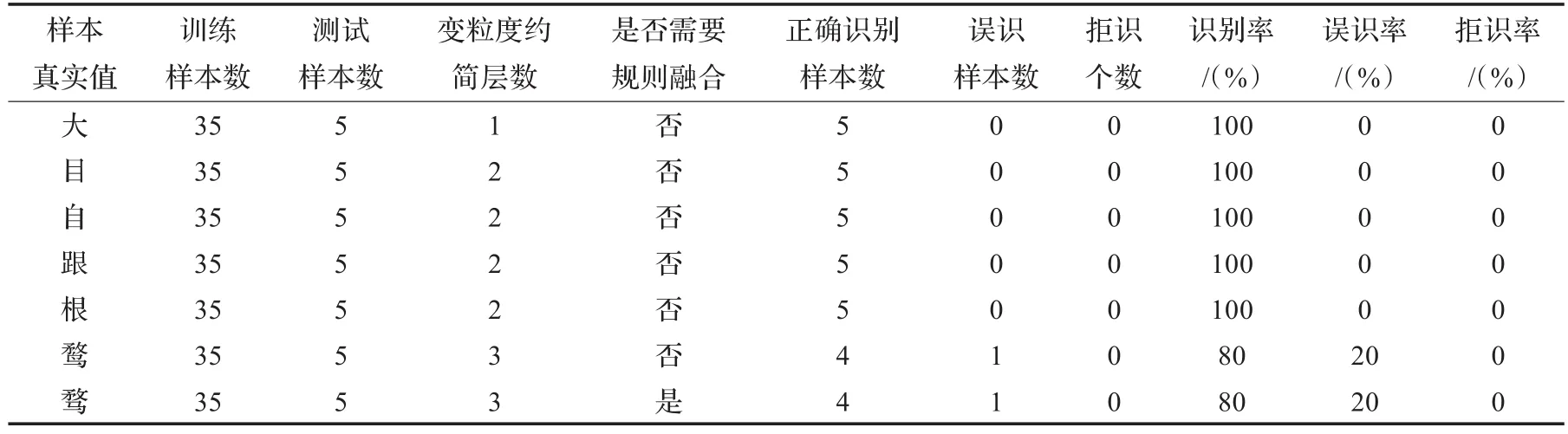
表1 所选样本汉字实验结果

表2 实验结果统计
由上表可以看出,本文所研究的识别方法对35个手写体汉字测试样本的总体识别率为91.43%,误识率为8.57%,拒识率0。通过分析可发现,本系统对复杂相似字的识别准确率低于对简单相似字的识别准确率,这是由于采集的样本间的书写差异较大和所提取的汉字样本特征属性不够精细等多方面原因造成的,此外,采用分层变粒度的识别决策方法,有助于降低汉字识别的拒识率,提高正确识别率。
6 结束语
三枝决策是基于粗糙集的正域、边界域和负域以及假设验证提出的,它可以用来解释生活中的很多决策现象。领域多粒度网的构建策略,使问题的某些关键的性质必须在不同粒度上体现出来,通过粒运算证实满足粒化准则。为提高脱机手写体汉字识别的识别率和识别速度,本文利用三枝粗糙集理论和变粒度原理对脱机手写体汉字识别系统进行了研究。主要工作如下:
(1)从贝叶斯理论出发,基于三枝决策粗集理论,构建期望风险最小决策的语义下决策粗集理论。
(2)定义了脱机手写体汉字识别决策信息系统特征属性约简的几个性能指标熵,以及特征属性相对重要度指标,从属性重要度角度出发,对粒与粒之间进行逻辑运算,形成凝聚式的自上而下的信息粒网的构建策略,形成此领域适用粒度逐渐变小的层次多粒度网结构,建立相应的特征属性集达到最优的决策表。提高了信息利用率,更好地获取信息,提高了约简精度。
[1]封筠,王先梅.脱机手写体汉字识别技术研究的回顾与展望[J].微型电脑应用,2003(4).
[2]Pawlak Z.Rough sets[J].International Journal of information and Computer Science,1982,11(5):341-356.
[3]Yao Y Y.Three-way decisions with probabilistic rough sets[J].Information Sciences,2010,180:341-353.
[4]Yao Y Y.Two semantic issues in a probabilistic rough set model[J].Fundament a Informaticae,Manuscript,2009.
[5]Yao Y Y.Three-way decision:an interpretation of rules in rough set theory[J].LNAI,2009(5589):642-649.
[6]张文修,仇国芳.基于粗糙集的不确定决策[M].北京:清华大学出版社,2005.
[7]菅利荣.面向不确定性决策的杂合粗糙集方法及其应用[M].北京:科学出版社,2008.
[8]胡卉颖,罗锦坤,刘阿宁.三枝决策粗糙集模型属性约简研究[J].软件导刊,2012(2).
[9]耿志强,朱群雄,李芳.知识粗糙性的粒度原理及其约简[J].系统工程与电子技术,2004,26(8):1112-1116.
[10]贾修一,李伟湋,商琳,等.一种自适应求三枝决策中决策阈值的算法[J].电子学报,2011(11).
[11]Wang J P,Chen K Q.A study of off-line handwritten Chinese character recognition with optimized decision and iteration based on rough set and the granular theorem[J].Advanced Materials Research,2012:1715-1722.
[12]费雅洁.基于粗集理论的本体属性动态加权法研究[J].微计算机信息,2009,27:209-210.
[13]费雅洁,赵琦,许泓宁.一种领域多粒度网的动态构建策略[J].微计算机信息,2011(12).
[14]吴佑寿,丁晓青.汉字识别-原理方法与实现[M].北京:高等教育出版社,1992:154-171.
WANG Jianping,WANG Mengze
School of Electric Engineering and Automation,Hefei University of Technology,Hefei 230009,China
The model of the theory of three-way decision-theoretic rough sets is used for the recognition of handwritten Chinese characters.A model of the theory of three-way decision-theoretic rough sets is set up which the regional classification is based on positive,negative and boundary.It can better reflect the recognition of handwritten Chinese characters classification on approximation.And define characteristic attribute of reduction of relative granularity entropy and the significance of attribute in offline handwritten Chinese characters recognition decision information system.If consider the recognition of handwritten Chinese characters from the point of view of the importance of attribute,it can design a kind of bottom up particle network structure based on logical operation between grain and grain,you can obtain more effective information.Simulation results show that,the method is feasible and effective.
rough set;three-way decision making;risk of loss;attribute reduction;vary granularity
将三枝决策粗糙集模型用于手写体汉字识别,建立三枝决策粗糙集模型,其区域分类以正、负和边界为基础,更好地体现手写体汉字识别分类近似性。定义了脱机手写体汉字识别决策信息系统特征属性约简相对粒度熵和属性重要度,将手写体汉字识别从属性重要度的角度出发,设计一种基于粒与粒之间逻辑运算的自下而上的粒度网结构,使手写体汉字识别属性集的适用粒度逐渐变大,可以获取更多的有效信息。仿真实验表明,该方法是可行有效的。
粗糙集;三枝决策;风险损失;决策约简;粒度分层
A
TP391.12
10.3778/j.issn.1002-8331.1301-0176
WANG Jianping,WANG Mengze.Study of handwritten Chinese characters recognition based on three branches rough sets and variable granularity principle.Computer Engineering and Applications,2014,50(22):223-227.
王建平(1955—),男,博士,教授,主研领域:数字化监控、图像识别、检测技术;王梦泽(1987—),女,硕士研究生,主研领域:自动检测技术。E-mail:wangww@mail.hf.ah.cn
2013-01-16
2013-03-14
1002-8331(2014)22-0223-05
CNKI网络优先出版:2013-03-26,http://www.cnki.net/kcms/detail/11.2127.TP.20130326.1040.009.html
◎工程与应用◎
猜你喜欢
星星·散文诗(2023年1期)2023-04-15
实用临床医药杂志(2021年7期)2021-05-18
科技风(2020年3期)2020-02-24
中国篆刻(2019年6期)2019-12-08
成都信息工程大学学报(2019年2期)2019-08-28
中国现代医药杂志(2019年6期)2019-07-31
中国民间疗法(2019年24期)2019-02-12
自动化学报(2018年2期)2018-04-12
成都信息工程大学学报(2017年1期)2017-07-21
电脑知识与技术(2017年3期)2017-03-27
