
基于自适应噪声估计的语音增强技术
2014-08-03 15:23夏乐乐孙永荣
计算机工程与应用 2014年23期
夏乐乐,孙永荣,王 勇
1.南京航空航天大学 自动化学院,南京 210016
2.中航工业雷达与电子设备研究院,江苏 苏州 215000
基于自适应噪声估计的语音增强技术
夏乐乐1,孙永荣1,王 勇2
1.南京航空航天大学 自动化学院,南京 210016
2.中航工业雷达与电子设备研究院,江苏 苏州 215000
1 引言
在飞机座舱中,由于受飞机发动机转动、机身与空气的摩擦以及机载仪器噪声等原因的影响,机载语音通信不可避免地会受到噪声环境的干扰,带有很强的背景噪声的语音信号很难被机载语音系统识别,必须对机载语音进行增强处理,以消除背景噪声,提高语音通信质量与识别率。
目前语音信号的降噪方法大致有四类:噪声对消法、谐波增强法、基于参数估计的语音再合成法和基于语音短时谱估计的增强算法[1]。其中基于语音短时谱估计的谱减法[2]是目前最常用的语音增强技术。这种方法的优点是运算量小,易于实现,在平稳的声学环境及较高信噪比时能取得较好的效果,但不适用于非平稳以及低信噪比噪声,并且会产生具有一定节奏性起伏、听上去类似音乐的“音乐噪声”[3]。
针对传统谱减法的不足,研究人员提出了很多改进方法。例如:在传统谱减法的基础上增加了调节噪声功率谱大小的系数和增强语音功率谱的最小值限制[4]、根据语音信号的信噪比自适应调节语音增强的增益函数[5]、将人耳的掩蔽特性应用到非线性谱减法的增强算法[6-8]、在估计语音信号概率密度函数的基础上改进数谱估计[9]等方法。以上方法都不同程度地改善了传统谱减法,使得噪声明显减少,残留噪声也得到了进一步抑制。但是在非平稳以及低信噪比情况下去噪效果还是不太理想,并且有些算法的计算量较大。
本文针对基于自适应噪声估计的改进谱减法进行研究,以达到在非平稳以及低信噪比噪声环境下能有效地抑制音乐噪声,并且提高机载语音系统在强噪声环境下的识别正确率。
2 谱减法原理分析及算法改进
2.1 谱减法原理分析
谱减法的基本思路是:假设在加性噪声与短时平稳的语音信号相互独立的条件下,从带噪语音的功率谱中减去噪声功率谱,得到较为纯净的语音频谱,从而估计出原始语音[10-11]。谱减法的原理分析如下:
设s(t)为纯净的原始语音信号,n(t)为噪声信号,则带噪语音信号x(t)可表示为:

对式(1)两端进行傅里叶变换,可以得到:

对式(2)两端取模后再平方,可得:

由于假设噪声信号服从高斯零均值分布,s(t)和n(t)相互独立,cos(θS-θN)一项为0,可得:

由于相对平稳的噪声信号可认为变化甚小,所以可以通过发音前的“寂静段”信号的功率谱来估计发音期间噪声的功率谱,从而得到原始语音功率谱的估计值为:

根据人耳对语音信号相位不敏感的特点,可以用噪声信号的相位来代替估计之后语音信号的相位,进行傅里叶逆变换,即可得到增强后语音的时域信号。
2.2 谱减法改进研究
在2.1节中假设cos(θS-θN)一项为零,而在机载座舱噪声环境中,噪声信号不服从高斯零均值分布,如果忽略此项,对噪声功率谱的估计会出现较大误差,影响语音增强效果,所以cos(θS-θN)一项不能忽略[12]。设λ=cos(θS-θN),-1≤λ≤1,将其带入公式(3)中得:

在式(6)中将|S(ω)|作为未知数,解此一元二次方程得(舍去非正解):

所以最终改进的谱减法原理公式为:

其中i表示帧数,文中k的取值区间一般为[0.01,0.05]。
3 谱减法中噪声自适应估计
传统谱减法假设噪声是局部平稳的,也即指发音间的噪声具有和语音开始前那段噪声相同的统计特性,且在整个语音段中保持不变。所以对整个语音段噪声功率取相同的值。即公式(5)中的|N(ω)|2取定值。谱减法的关键之处在于对噪声的估计。对噪声的估计越准确,经过谱减之后得到的噪声就越接近于原来的纯净语音[13]。在实际机载座舱环境下的噪声是非平稳噪声,所以用相同的噪声功率值是不准确的,这样做会使得语音段要么噪声消除不够,要么减除过多产生失真。为此,必须对噪声估计开展研究。


其中 α>1,0<β<1。
由式(9)可以看出:要实现此自适应噪声估计需要对带噪信号进行语音端点检测来区分语音段以及非语音段。文献[14]中使用已经得到广泛应用的基于能量和过零率的语音端点检测方法——两级判决法来实现语音的端点检测。由于需要端点检测的语音信号带有强噪声,文中在检测前先用传统谱减法对带噪语音信号进行去噪处理,然后再对其进行端点检测。
参照文献[15],文中端点检测的算法流程为:
(1)先将经过简单去噪的语音信号进行分帧处理,每一帧记为xi(n),n=1,2,…,N,N表示帧长,i表示帧数。

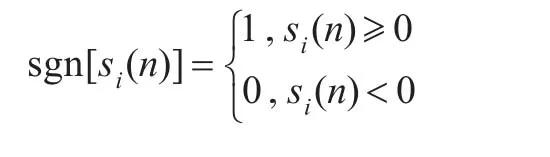
(4)根据语音的平均能量设置一个较高的门限T1,用以确定语音开始,然后再根据背景噪声的平均能量确定一个稍低的门限T2,用以确定第一级中的语音结束点。T2=ηEN,EN为噪声段能量的平均值。完成第一级判决。
(5)第二级判决根据背景噪声的平均过零率ZN,设置一个门限T3=μZN,用以判断语音前端的清音和后端的尾音。
步骤(4)、(5)中的η、μ为经过大量实验获得的经验值。本文中η=7,μ=5。
4 仿真结果及分析
为了验证本文所提的改进谱减法的有效性,分别求增强前后的语音信噪比(SNR),并通过已有的机载语音系统对增强前后的语音进行识别测试。

s(n)表示纯净语音,x(n)表示带噪语音,n表示采样点数。信噪比越高表示语音信号质量越好。
实验中采用的语音数据为若干段在安静的实验室环境下录制的纯净语音,其内容为“查询天气”。噪声选自NOISEX-92数据库,噪声类型为F16战斗机噪声。语音信号和噪声信号均单声道16 kHz采样,16 bit量化,对带噪语音采用汉明窗进行分帧,每帧256个采样点.帧间叠加128个采样点。图1为输入信噪比为0 dB时的仿真结果。表1为5 dB、0 dB、-5 dB三种输入信噪比下语音增强的效果比较。表2为在三种输入信噪比情况下,在机载语音系统中各进行20次语音识别实验后获得的成功率比较。

表1 语音增强效果比较 dB
图1(a)为在安静的实验室环境下录制的纯净语音波形;图1(b)为原始语音信号与战斗机噪声线性叠加获得的加噪语音波形;图1(c)为使用传统谱减法[16]对加噪语音信号去噪后的波形;图1(d)为对图1(c)信号进行端点检测后的结果,在此图中将语音段中的语音帧按帧赋“1”,非语音帧赋“0”,便于后续噪声自适应计算;图1(e)为使用本文算法去噪后的波形,将图1(c)、图1(e)分别与图1(a)比较,本文方法对幅度谱的恢复结果明显优于传统谱减法。

图1 输入信噪比为0 dB时仿真结果
将语音和噪声按比例线性叠加生成不同信噪比(5 dB,0 dB,-5 dB)。对这三种不同信噪比的含噪语音分别用传统谱减算法和本文所提的改进谱减法进行去噪实验,文中 β取0.4,α取2,λ取0.1,实验结果如表1所示。
从表1可以看出:用本文改进谱减算法增强后,其信噪比得到了进一步提高,增强效果明显优于传统谱减算法。
由表2可以看出,随着输入信噪比的减小,机载语音识别系统的识别成功率越来越低,特别是在低信噪比的情况下甚至根本不能识别。经过传统谱减法去噪后的识别率略有提升,但是依然没有达到要求,而经过本文提出的改进谱减法去噪后的识别成功率大大提升,效果良好,在低输入信噪比的时候也能保证很高的识别成功率,但是在-5 dB时还没能达到100%的识别率,这是由于信噪比过低时端点检测精度会降低,从而会影响去噪效果。

表2 机载语音识别系统识别成功率比较
5 结论
由实验结果可以看出本文提出的基于自适应噪声估计的改进谱减法能够很好地解决强噪声环境下输入语音不能被机载语音系统识别的问题。它能够较好地消除背景噪声,并对“音乐噪声”也有很大程度的抑制,对带噪语音质量的增强效果显著,提高了机载语音识别系统对强噪声语音的识别率。语音在个别语音帧上有一点失真,这是由于端点检测不够精确的原因造成的,但是这并不影响语音整体的可懂度和清晰度。
[1]刘兴涛,王忠,张维.抑制坦克强背景噪声的改进谱减法研究[J].计算机工程与应用,2010,46(4):134-135.
[2]Boll S.Suppression of acoustic noise in speech using spectral subtraction[J].IEEE Transon AcousticSpeech and Signal Processing,1979,27(2):113-120.
[3]Miyazaki R,Saruwatari H,Inoue T,et al.Musical-noise-free speech enhancement based on optimized iterative spectral subtraction[J].IEEE Transactions on Audio,Speech,and Language Processing,2012,20(7):2080-2094.
[4]Berouti M,Schwartz R,Makhoul J.Enhancement of speech corrupted by acoustic noise[J].IEEE Transactions on Acoustics Speech,and Signal Processing,1979,27(4):208-211.
[5]Sim B L,Tong Y C,Changand J S,et al.A parametric formulation of the generalized spectral subtraction method[J]. IEEE Trans on Speech and Audio Processing,1998,6(7):328-337.
[6]Virag N.Single channel speech enhancement based on masking propertiesofhuman auditory system[J].IEEE Transactions on Speech and Audio Processing,1999,7(2):126-137.
[7]卜凡亮,王为民,戴启军,等.基于噪声被掩蔽概率的优化语音增强方法[J].电子与信息学报,2005,27(5):753-756.
[8]Jia Hairong,Zhang Xueying,Jin Chengsheng.A speech enhancement method based on wavelet packet and hearing masking effect[C]//ICSPS,2010,3:272-275.
[9]Cohen I.Relaxed statistical model for speech enhancement and a priori SNR estimation[J].IEEE Transactions on Speech and Audio Processing,2005,13(5):870-881.
[10]高留洋,朱文,桑振夏,等.一种基于改进的谱减法的语音增强算法[J].现代电子技术,2012,35(17):60-62.
[11]赵力.语音信号处理[M].北京:机械工业出版社,2009:294-298.
[12]钱国青,赵鹤鸣.基于改进谱减算法的语音增强新方法[J].计算机工程与应用,2005,41(35):42-43.
[13]Gao Liuyang,Guo Yunfei,Li Shaomei,et al.Speech enhancementalgorithm based on improved spectral subtraction[C]//ICIS,2009:140-143.
[14]程塨,郭雷,贺胜,等.一种基于实时噪声估计的改进谱减法[J].计算机科学,2010,38(11):212-213.
[15]张雪英.数字语音处理及MATLAB仿真[M].北京:电子工业出版社,2010:43-45.
[16]金学骥.语音增强算法的研究与实现[D].杭州:浙江大学,2005:18-19.
XIA Lele1,SUN Yongrong1,WANG Yong2
1.College of Automation,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China
2.The Rader&Avionics Institute of AVIC,Suzhou,Jiangsu 215000,China
The recognition and communication accuracy of speech system is considered to be decreased under strong noise environment.To solve the problem,a speech enhancement method is presented which is based on adaptive noise estimation.In the new algorithm,the speech signal is divided into speech segments and non-speech segments by endpoint detection,and the noise amplitude spectrums of the two kings segments are estimated adaptively and respectively.This algorithm also improves the spectral subtraction principle formulas according to the research of hypothesis in spectral subtraction which is not common.The experimental result shows that the algorithm in this paper performs better in reducing musical noise,maintaining high clarity and intelligibility,and improving the speech recognition and communication accuracy under strong noise environment than traditional spectral subtraction.
speech enhancement;spectral subtraction;noise estimation;music noise
针对语音系统受外界强噪声干扰而导致识别精度降低以及通信质量受损的问题,提出一种基于自适应噪声估计的语音增强方法。通过端点检测将语音信号分为语音段与非语音段,对这两种情况的噪声幅度谱分别进行自适应估计,并对谱减法中不具有通用性的假设进行研究从而改进原理公式。实验结果表明,相对于传统谱减法,该方法能更好地抑制音乐噪声,并保持较高清晰度和可懂度,提高了强噪声环境下的语音识别精度和通信质量。
语音增强;谱减法;噪声估计;音乐噪声
A
TN912.35
10.3778/j.issn.1002-8331.1305-0138
XIA Lele,SUN Yongrong,WANG Yong.Speech enhancement technology based on adaptive noise estimation.Computer Engineering and Applications,2014,50(23):225-228.
夏乐乐(1989—),男,硕士研究生,研究领域为语音信号处理与检测;孙永荣(1969—),男,博士,教授,研究领域为信号处理、智能控制;王勇(1965—),男,副总工程师,研究领域为航空机载显示技术。E-mail:lelxia2005@hotmail.com
2013-05-14
2013-07-02
1002-8331(2014)23-0225-04
CNKI网络优先出版:2013-08-22,http://www.cnki.net/kcms/detail/11.2127.TP.20130822.1410.012.html
◎工程与应用◎
猜你喜欢
噪声与振动控制(2022年3期)2022-07-04
数学物理学报(2022年2期)2022-04-26
现代仪器与医疗(2022年1期)2022-04-19
北京航空航天大学学报(2019年9期)2019-10-26
中学生数理化·教与学(2019年8期)2019-09-18
雷达学报(2017年3期)2018-01-19
地震研究(2017年3期)2017-11-06
数学物理学报(2017年1期)2017-06-05
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
应用海洋学学报(2015年1期)2015-11-22
