
基于自然语言生成的关联规则可视化方法
2014-08-03 15:23赵娇娇赵书良郭晓波刘军丹
计算机工程与应用 2014年23期
赵娇娇,赵书良,郭晓波,刘军丹
1.河北师范大学 数学与信息科学学院,石家庄 050024
2.河北省计算数学与应用重点实验室,石家庄 050024
3.河北师范大学 移动物联网研究院,石家庄 050024
基于自然语言生成的关联规则可视化方法
赵娇娇,赵书良,郭晓波,刘军丹
1.河北师范大学 数学与信息科学学院,石家庄 050024
2.河北省计算数学与应用重点实验室,石家庄 050024
3.河北师范大学 移动物联网研究院,石家庄 050024
1 引言
关联规则挖掘是数据挖掘[1]的一个重要方向,其目的是从数据集中发现属性间存在的有趣关联或相关模式,从而发现对用户有价值的知识和信息,帮助用户制定科学的决策,因此,如何有效地展示关联规则挖掘结果是至关重要的。目前,关联规则可视化研究受到国内外计算机科学工作者的广泛关注[2-7]。文献[8]提出将平行坐标技术应用到关联规则可视化中,较好地利用了图形的表达能力,然而,展示结果容易出现交错现象,规则的可理解性较差,不利于普通用户深入分析和研究;文献[9]使用2D矩阵技术(全局展示)和鱼眼视图技术(细节呈现)相结合的方法较好地展示了大数据量的关联规则,但该方法的展示形式不利于非专家用户理解;文献[10]利用Java3D可视化技术的特点,将关联规则通过三维坐标的颜色、图形及三维属性表示出来,较好地利用了人对于色彩和形状敏锐的感知能力,有利于专家用户观察和分析关联规则,但尚未考虑到非专家用户对色彩和形状的理解能力和水平。现阶段多数关联规则可视化研究工作大都存在以下不足:展示结果一般面向数据挖掘领域的专家用户,不利于普通用户分析和使用;单纯的关联规则蕴含式表示方式可理解性较差等。对于上述问题而言,不具备数据挖掘知识背景的普通用户无法很好地理解并使用这些关联规则。
可视化技术已经成为一种有效的知识表示手段,关联规则挖掘结果的可视化展示也应更加面向大众化,更加贴近普通用户的需求,因为并非所有用户都能理解“金银花津液∧荆芥 =>薄荷冰,(support=3%,confidence= 71%)”[11]所表达的知识和信息。
本文提出了一种新的基于自然语言生成的关联规则可视化方法NLG-AR(Natural Language Generation-Association Rules),将自然语言生成技术引入关联规则可视化中,首先通过领域知识库中解释模式将关联规则中每一项生成简单的自然语言句子,然后通过合并规则生成概括的自然语言句子,最后通过解释模板生成流畅的具体自然语言句子,使得不具备数据挖掘知识的普通用户也能理解和运用挖掘出来的有价值的关联规则信息。
2 基于自然语言生成的关联规则可视化方法NLG-AR
本文提出了一种基于自然语言生成的关联规则可视化方法NLG-AR,将关联规则、支持度和置信度作为方法的输入,相关领域的自然语言句子作为方法的输出。
2.1 NLG-AR方法结构
NLG-AR方法采用自然语言生成的经典管道技术[12-13],如图1所示,主要包括三步:内容规划、句子规划和表层实现,具体内容如下:
内容规划:输入参数(包括支持度和置信度)和关联规则的前件、后件项集。首先,分别对关联规则的前件项集、后件项集、支持度和置信度进行形式化定义;然后,从知识库中调用预定义的解释模式,对关联规则中前件项集和后件项集的每一项进行句子解释,生成的句子称为单项句子解释。
句子规划:内容规划中生成的单项句子解释作为输入,从知识库中调用合并规则,分别对关联规则前件项集和后件项集生成的单项句子解释进行合并,生成的句子称为多项句子解释;然后将这两个多项句子解释进行合并,生成概括的自然语言句子。

图1 NLG-AR方法结构图
表层实现:本方法采用基于模板的表层实现。概括句子解释、多项句子解释、支持度和置信度作为输入,生成最终具体的自然语言句子。
2.2 NLG-AR领域知识库
领域知识库是NLG-AR方法的重要组成部分,在关联规则生成自然语言句子过程中起着关键作用,主要由解释模式、合并规则和解释模板构成。
2.2.1 单维关联规则的解释模式
本文提出的方法主要面向单维关联规则的自然语言解释,即关联规则中的项或属性涉及一个维,例如:关联规则buys(A)=>buys(C),它只涉及一个维buys。
一般中文自然语言句子由“主谓宾”三个部分构成,因此,本文引用RDF语义关系三元组[14]<subject,predicate,object>的形式,设计了通用的单维关联规则的自然语言解释模式:
定义1解释模式 pattern(s,p,o),s表示句子解释的主语,p表示句子解释的谓语,o表示句子解释的宾语。设 I={I1,I2,…,Im}是项的集合,关联规则 A⇒B定义在 I上,其中 A⊂I,B⊂I,并且A∩B=ϕ。X={X1,X2,…,Xk,…},Xi是相关领域词汇。那么 s、p、o 中有且只有一项属于A∪B,其余两项必属于X。
针对特定领域,解释单维关联规则时,用户需定义符合自己领域的具体模式。以治疗感冒的中药专利数据集上挖掘出的关联规则“金银花津液∧荆芥 =>薄荷冰”为例,解释模式为 pattern(s,p,o),s、p 属于相关领域词汇,s为“治疗感冒的中药方剂”,p为“含有”,o属于关联规则中的项,o∈{金银花津液,荆芥,薄荷冰}。选取关联规则中任一项(例如:薄荷冰)代入解释模式后,变为pattern(治疗感冒的中药方剂,含有,薄荷冰)。
定义2对解释模式的实例化,称之为事实,事实是与自然语言句子解释直接对应的。
例1pattern(治疗感冒的中药方剂,含有,薄荷冰)即为一个事实,表示的自然语言句子为“治疗感冒的中药方剂含有薄荷冰”。
2.2.2 合并规则
为了保证生成的句子自然顺畅,若两个事实之间存在相同的组成内容,需进行适当地合并。针对已定义的解释模式,定义了三种通用的合并规则:
规则1模式主语不同(谓语和宾语相同),则合并规则为pattern(s1,p,o)+pattern(s2,p,o)=pattern(s1s2,p,o)。
例2两个事实分别为pattern(治疗感冒的中药方剂,含有,薄荷冰)和pattern(清凉油,含有,薄荷冰),经过规则1合并后成为pattern(治疗感冒的中药方剂、清凉油,含有,薄荷冰),表示的自然语言句子为“治疗感冒的中药方剂和清凉油都含有薄荷冰”。
规则2模式谓语不同(主语和宾语相同),则合并规则为pattern(s,p1,o)+pattern(s,p2,o)=pattern(s,p1p2,o)。
例3两个事实分别为pattern(某中药方剂,预防,感冒)和pattern(某中药方剂,治疗,感冒),经过规则2合并后成为pattern(某中药方剂,预防、治疗,感冒),表示的自然语言句子为“某中药方剂预防和治疗感冒”。
规则3模式宾语不同(主语和谓语相同),则合并规则为pattern(s,p,o1)+pattern(s,p,o2)=pattern(s,p,o1o2)。
例4两个事实分别为pattern(治疗感冒的中药方剂,含有,薄荷冰)和pattern(治疗感冒的中药方剂,含有,金银花津液),经过规则3合并后成为pattern(治疗感冒的中药方剂,含有,薄荷冰、金银花津液),表示的自然语言句子为“治疗感冒的中药方剂含有薄荷冰和金银花津液”。
2.2.3 解释模板
支持度和置信度是关联规则的自然语言句子解释中不可或缺的组成部分。为了保证对关联规则解释的完整性,将支持度和置信度两个重要参数加入到自然语言句子解释中。于是,设计了两种解释模板[15]:
模板 1template1(patterns,sup),与支持度有关,其中patterns为一个事实,代表概括句子解释,sup为关联规则的支持度。
例5存在事实patterns=pattern(治疗感冒的中药方剂,含有,薄荷冰)和支持度sup=1%,代入模板1后,表示的自然语言句子为“1%的治疗感冒的中药方剂含有薄荷冰”。
模板 2template2(pattern1,pattern2,conf),与置信度有关,其中pattern1和pattern2分别为一个事实,pattern1代表关联规则前件项集的多项句子解释,pattern2代表关联规则后件项集的多项句子解释,conf为关联规则的置信度。其中该模板涉及多组连词,可随机生成。
例6存在两个事实pattern1=pattern(治疗感冒的中药方剂,含有,薄荷冰)、pattern2=pattern(治疗感冒的中药方剂,含有,荆芥)和置信度conf=70%,代入模板2后,表示的自然语言句子为“如果治疗感冒的中药方剂含有薄荷冰,则治疗感冒的中药方剂会含有荆芥,其可能性为70%”或者为“若治疗感冒的中药方剂含有薄荷冰,那么治疗感冒的中药方剂会含有荆芥,其可能性为70%”。
2.2.4 关联规则的形式定义
关联规则输入格式为:A=>C(support,confidence),依次为前件项集A、后件项集C、支持度support和置信度confidence。首先,将前件项集A中每一项定义为ai,其中i=1,2,…,n;后件项集C中每一项定义为ci,其中i=1,2,…,n,便于生成单项句子解释。然后,分别定义支持度和置信度两个重要参数为sup和conf。
2.3NLG-AR算法
基于自然语言生成的单维关联规则可视化方法结构图,如图1所示。
算法具体步骤如下:
输入:关联规则A=>C(support,confidence)
输出:概括句子解释和具体句子解释
(1)构建领域知识库中的合并规则和解释模板,定义具体领域的解释模式pattern(s,p,o)。
(2)根据预定义格式,对输入的关联规则进行形式化定义:前件项集中每一项定义为ai,其中i=1,2,…,n;后件项集中每一项定义为ci,其中i=1,2,…,n;支持度和置信度分别定义为sup和conf。
(3)调用(1)中的解释模式pattern(s,p,o),将(2)中定义的前件项集中每一项代入pattern中,迭代生成多个单项句子解释,分别为事实pattern_ai,其中i=1,2,…,n;类似地,将(2)中定义的后件项集中每一项代入pattern中,迭代生成多个单项句子解释,分别为事实pattern_ci,其中i=1,2,…,n。
(4)调用(1)中的合并规则,迭代合并(3)中生成的单项句子解释pattern_ai,得到合并后的多项句子解释pattern1;类似地,迭代合并(3)中生成的pattern_ci,得到合并后的多项句子解释pattern2。
(5)继续调用(1)中的合并规则,将(4)中生成的多项句子解释pattern1和pattern2合并生成patterns,得到概括句子解释。
(6)最后将(2)中定义的sup和conf,以及(5)中生成的patterns和(4)中生成的pattern1、pattern2分别代入(1)中预定义的模板template1和template2,生成最终的具体句子解释。
3 NLG-AR的实现
本文以治疗感冒的中药专利数据集为例,将其挖掘出的关联规则:金银花津液∧荆芥 =>薄荷冰,(support= 3%,confidence=71%),运用NLG-AR方法生成自然语言句子,便于非数据挖掘领域的中药专家了解中医药数据库中中药方剂的配伍规律,为中医新药的研制提供指导信息。
3.1 领域知识库的构建
定义中药领域的具体解释模式为:pattern(治疗感冒的中药方剂,含有,o),o为关联规则中的项,构建领域知识库,包括定义的pattern、预设计的合并规则和解释模板。
3.2 形式定义关联规则
根据预定义的格式,前件项集中每一项分别定义为“a1=金银花津液,a2=荆芥”,后件项集中每一项定义为“c1=薄荷冰”,支持度定义为“sup=3%”,置信度定义为“conf=71%”。
3.3 生成单项句子解释
从知识库中调用解释模式pattern,分别将a1、a2和c1代入pattern中,生成pattern_a1=pattern(治疗感冒的中药方剂,含有,a1)、pattern_a2=pattern(治疗感冒的中药方剂,含有,a2)和pattern_c1=pattern(治疗感冒的中药方剂,含有,c1)。
3.4 生成多项句子解释
因为预定义的解释模式是宾语不同,所以调用合并规则的规则3。首先,根据规则3对前件项集生成的单项句子解释,即pattern_a1和pattern_a2合并生成pattern1=pattern(治疗感冒的中药方剂,含有,a1、a2);因后件项集只生成了一个单项句子解释,所以不再需要合并,即pattern2=pattern_c1=pattern(治疗感冒的中药方剂,含有,c1)。
类似,根据规则3,合并pattern1和pattern2生成概括句子解释patterns=pattern(治疗感冒的中药方剂,含有,a1、a2、c1),输出的概括自然语言句子解释为“治疗感冒的中药方剂含有金银花津液、荆芥和薄荷冰”。
3.5 套用模板生成具体解释
首先,调用与支持度有关的解释模板1,将patterns代入模板template1中,此时模板成为template1(pattern(治疗感冒的中药方剂,含有,a1、a2、c1),sup),输出的具体自然语言句子解释为“3%的治疗感冒的中药方剂含有金银花津液、荆芥和薄荷冰”。
其次,调用与置信度有关的解释模板2,将pattern1和pattern2代入template2中,此时模板成为template2(pattern(治疗感冒的中药方剂,含有,a1、a2),pattern(治疗感冒的中药方剂,含有,c1),conf),输出的自然语言句子解释为“如果治疗感冒的中药方剂含有金银花津液和荆芥,则治疗感冒的中药方剂含有薄荷冰,其可能性为71%”。
最后,输出关联规则的最终自然语言句子解释为:具体地讲,3%的治疗感冒的中药方剂含有金银花津液、荆芥和薄荷冰;如果治疗感冒的中药方剂含有金银花津液和荆芥,则治疗感冒的中药方剂含有薄荷冰,其可能性为71%;概括地讲,中药的配伍规律为:治疗感冒的中药方剂含有金银花津液、荆芥和薄荷冰。
4 实验对比与分析
目前存在多种关联规则展示技术,主要可以概括为两类:基于表的可视化技术和基于图形的可视化技术。下面介绍这两种可视化技术,并分析各自的优缺点。
基于表的可视化技术:类似于关联规则的原始蕴含式描述形式,用表结构文字化描述关联规则(如表1),表中的每一行描述一条关联规则,每一列分别描述关联规则中的参数,包括规则的前件、后件、支持度和置信度。此方法的优点是能够利用表的基本操作,对感兴趣的列(如支持度)进行排序,存在的不足是对普通用户而言可理解性差,不具有数据挖掘背景的非专家用户难以理解挖掘出的关联规则,降低了用户体验,导致无法充分利用挖掘出的价值信息。

表1 基于表的关联规则可视化
基于图形的可视化技术[16]:包括基于平行坐标的可视化技术(如图2)、基于矩阵的可视化技术(如图3)等。此类方法将关联规则映射成不同的图形原语,例如位置、形状、颜色和大小。此类方法的优势是充分利用图形和图像的表达能力以及人对于色彩和形状敏锐的感知能力,利于数据挖掘领域的专家用户方便深入地对结果进行观察和分析,但是特别要求用户对色彩和形状有敏锐的感知能力,普通用户很难达到这个要求,所以此类方法对普通用户来说,易理解性较差。

图2 基于平行坐标的可视化技术
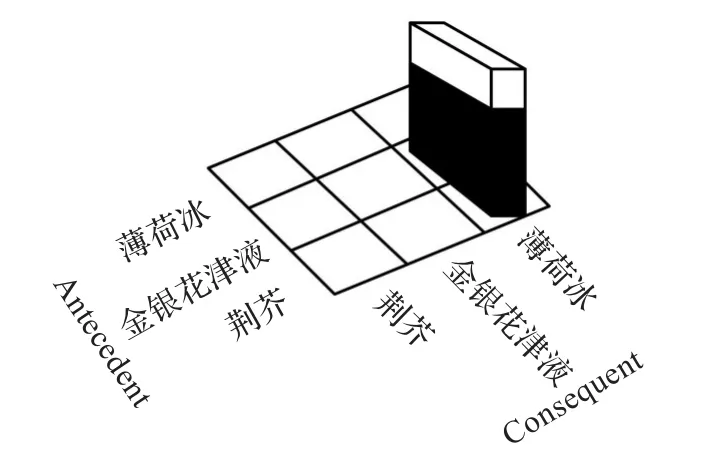
图3 基于矩阵的可视化技术
本文以中药专利数据库中挖掘出的关联规则为数据源,开发了基于NLG-AR的关联规则可视化原型系统,该系统不仅提供了友好的人机交互接口,而且用户可以按照支持度(或者置信度)对关联规则进行重新排序,选择自己感兴趣的规则,生成自然语言句子。例如,用户按照支持度递增的顺序显示关联规则,并选择关联规则“金银花津液∧荆芥 =>薄荷冰”进行自然语言句子的生成,如图4所示。与表1、图2和图3相比,显然关联规则的自然语言表示方法更简单易懂。

图4 基于NLG-AR的关联规则可视化原型系统
另外,邀请23名来自不同单位的中医中药领域的研究人员和管理者对本方法和图形可视化方法进行了评价。下面为反馈结果:
(1)对于图形可视化的展示:相对抽象,不易理解挖掘项之间的联系,一些用户反映自身对颜色不够敏感,更增加了理解关联规则的难度。
(2)对于自然语言可视化的展示:简单易懂,准确地了解了挖掘项之间的关系,对于不具有数据挖掘背景知识的用户直观地掌握了中药方剂的配伍规律。
通过原型系统展示和用户验证,可见本文提出的基于自然语言生成的关联规则可视化方法,通过自然语言生成技术将半形式化的关联规则解释成大众化的自然语言,提升了非专家用户的体验,增强了挖掘结果的易理解性,促进了今后数据挖掘研究面向更多的终端用户,利于数据挖掘技术应用于更广泛的领域。
5 结束语
本文提出了一种基于自然语言生成的单维关联规则可视化新方法。结合自然语言生成技术,提出了通用的解释模式、合并规则和解释模板,将关联规则解释成易于理解的自然语言,便于普通用户使用。通过实际数据对本文方法进行具体验证和分析,表明本文方法能够有效地满足非专家用户对挖掘出的关联规则的理解和运用,提升了关联规则的应用价值。在下一步的研究中,将针对如何有效地对多维关联规则进行自然语言生成的问题进行深入分析和研究。
[1]Han J W,Kamber M,Pei J.Data mining concepts and techniques[M].Burlington:Morgan Kaufmann Publishers,2012.
[2]Li Yang.Pruning and visualizing generalized association rules in parallelcoordinates[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(1):60-70.
[3]罗建,晏华.基于java技术的关联规则可视化新方法及实现[J].计算机工程与科学,2008,30(11):31-33.
[4]Blanchard J,Pinaud B,Kuntz P,et al.A 2D-3D visualization support for human-centered rule mining[J].Computers and Graphics,2007,31(3):350-360.
[5]Coutuier O,Hamrouni T,Yahia B S,et al.A scalable association rule visualization towards displaying large amounts of knowledge[C]//the 11th International Conference Information Visualization.Washington DC:IEEE Computer Society,2007:657-663.
[6]Liu G,Suchitra A,Zhang H J,et al.AssocExplorer:an association rule visualization system forexploratory data analysis[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Publisher,2012:1536-1539.
[7]Noraziah A,Abdullah Z,Herawan T,et al.WLAR-Viz:weighted least association rules visualization[C]//3rd International Conference on Information Computing and Applications.Berlin:Springer,2012,7473:592-599.
[8]Li Y.Visualizing frequent itemsets,association rules,and sequential patterns in parallel coordinates[C]//International Conference on Computational Science and Its Application.Berlin,Heidelberg:Springer-Verlag,2003,2667:21-30.
[9]Couturier O,Rouillard J,Chevrin V.An interactive approach to display large sets ofassociation rules[C]//Symposium on Human Interface.Berlin,Heidelberg:Springer-Verlag,2007,4557:258-267.
[10]易先卉,彭黎.基于三维坐标的关联规则可视化新技术[J].计算机工程,2008,34(22):57-59.
[11]钱增瑾,辛燕,鞠时光.基于中药专利数据集的关联规则发现算法[J].计算机应用研究,2007,24(7):61-63.
[12]Reiter E,Dale R.Building natural language generation systems[M].Cambridge:Cambridge University Press,2000:41-77.
[13]McCoy K F.Natural language generation and assistive technologies[C]//Proceedings of the 7th International NaturalLanguage Generation Conference.Stroudsburg:Association for Computational Linguistics,2012.
[14]闫秋艳,夏士雄.一种基于自然语言生成的XML关键字查询技术[J].计算机工程与应用,2008,44(26):150-153.
[15]Cullen C,O’Neill I,Hanna P.Human language technology[M]//Flexible natural language generation in multiple contexts.Berlin,Heidelberg:Springer-Verlag,2009:142-153.
[16]Bruzzese D,Davino C.Visual mining of association rules[C]//Visual Data Mining.Berlin:Springer-Verlag,2008,4404:103-122.
ZHAO Jiaojiao,ZHAO Shuliang,GUO Xiaobo,LIU Jundan
1.College of Mathematics and Information Science,Hebei Normal University,Shijiazhuang 050024,China
2.Hebei Key Laboratory of Computational Mathematics and Applications,Shijiazhuang 050024,China
3.Institute of Mobile Internet of Things,Hebei Normal University,Shijiazhuang 050024,China
For non-expert users,the general text association rules are hardly understood,moreover graphical visualization in the traditional sense is just popular for experts in the data mining field.To address these problems,a novel visualization methodology of association rules is proposed based on the Natural Language Generation(NLG),which introduces NLG technology to the association rules visualization.The proposed approach can interpret the items of rules as ordinary natural language by using the interpretation schema in the domain knowledge base,and ultimately generates the smooth and easy natural language sentences through sentence planning and surface realization.The experiments show that the results obtained by this approach are more easily understood to the non-expert users,and help them make accurate decisions by taking full advantage of value of information gained in the mining process.
natural language generation;association rules;visualization;domain knowledge base
针对传统的关联规则蕴含式表示方式和图形可视化方法对非专家用户来说不易理解的问题,提出了一种新的基于自然语言生成的关联规则可视化方法。该方法将自然语言生成技术引入到关联规则可视化中,通过领域知识库中的解释模式将关联规则中每一项生成简单的自然语言句子,并经过句子规划、表层实现,最终生成流畅的自然语言句子。实验最终得出的结果,便于普通用户理解和应用,从而帮助用户获取更有价值的信息。
自然语言生成;关联规则;可视化;领域知识库
A
TP391
10.3778/j.issn.1002-8331.1301-0009
ZHAO Jiaojiao,ZHAO Shuliang,GUO Xiaobo,et al.Visualization method of association rules based on natural language generation.Computer Engineering and Applications,2014,50(23):122-126.
河北省科学技术研究与发展计划项目(No.072435158D,No.09213515D,No.09213575D);河北师范大学硕士基金资助项目(No.201102002)。
赵娇娇(1986—),女,硕士研究生,CCF学生会员,研究领域为自然语言处理、智能信息处理;赵书良(1967—),通讯作者,男,博士,教授,研究领域为智能信息处理;郭晓波(1986—),男,硕士研究生,研究领域为数据挖掘、智能信息处理;刘军丹(1987—),女,硕士研究生,研究领域为应用数学、智能信息处理。E-mail:zhaojiaojiao2013@163.com
2013-01-05
2013-02-18
1002-8331(2014)23-0122-05
CNKI网络优先出版:2013-04-08,http://www.cnki.net/kcms/detail/11.2127.TP.20130408.1648.020.html
猜你喜欢
核科学与工程(2021年4期)2022-01-12
中国民间疗法(2021年1期)2021-04-20
中国民间疗法(2020年22期)2021-01-07
读友·少年文学(清雅版)(2020年6期)2020-10-20
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年2期)2020-06-15
读友·少年文学(清雅版)(2020年1期)2020-05-20
计算机应用(2018年5期)2018-07-25
中成药(2018年6期)2018-07-11
长春中医药大学学报(2017年1期)2017-04-16
