
基于粗糙集正域的手写字母识别算法
2014-08-03 15:23唐朝辉陈玉明吴克寿
计算机工程与应用 2014年23期
唐朝辉,陈玉明,吴克寿
厦门理工学院 计算机科学与技术系,福建 厦门 361024
基于粗糙集正域的手写字母识别算法
唐朝辉,陈玉明,吴克寿
厦门理工学院 计算机科学与技术系,福建 厦门 361024
1 引言
后PC时代,大量手持设备、小型网络终端相继面世,键盘编码输入方式越来越不能满足客户的需求,为满足用户日益增长的使用体验和易用性需求,采用手写输入是未来的趋势;同时大屏幕设备的普及,也为手写输入带来了便利。手写识别技术是手写输入可行性的最重要的条件,已经成为模式识别和机器学习的一大热点,但由于手写习惯不同、形似字、连写、输入噪声等问题,给手写识别带来了很大的复杂性。近几年机器学习领域对手写体识别做了大量研究[1-3],部分成果取得了较好的应用,它们主要基于统计分析、神经网络和聚类分析,如支持向量机(SVM)、误差反向传播(Back Propagation,BP)算法、Bagging算法等。
1982年由波兰数学家Pawlak[4]首次提出的粗糙集(rough set)理论是一种处理模糊和不确定知识的数学工具[4-5],现已经被广泛应用于数据挖掘、人工智能、模式识别等诸多领域[6-11]。粗糙集可用于特征选择,其目的是得到最小的特征子集,但找到所有可行的特征子集已经被证明是NP-hard问题,所以目前大多数研究采用启发式搜索策略,获取特征选择的一个或多个可行解,但不一定是最优解或所有解。
苗夺谦等人[12]提出了一种基于主曲线的脱机手写数字识别方法,该方法将主曲线及知识约简算法运用于识别模型。本文针对手写识别的特点,结合粗糙集正域,定义了特征重要度概念,并应用于手写识别决策系统约简当中;同时提出了基于粗糙集正域的手写字母识别算法,通过实验分析验证了算法的可行性。
2 粗糙集相关概念
粗糙集理论研究方法基于数据分类与知识的联系,并利用集合等价关系来描述数据分类[13-15]。为构建基于粗糙集的手写字母样本学习和测试集分类算法,引入以下粗糙集的相关定义。

定义2给定决策系统T=(U,C∪D,V,f)以及属性子集B⊆C,B可以确定一个二元等价关系,记为IND(B),其中 IND(B)={(x,y)∈U×U|∀a∈B,f(x,a)=f(y,a)}。
定义3设T=(U,C∪D,V,f)为一个决策系统,∀B⊆C,∀X⊆U,记 U/IND(B)={B1,B2,…,Bi},则称 B*(X)=∪{Bi|Bi∈U/IND(B),Bi∈X}为 X 关于 B 的下近似集,称B*(X)=∪{Bi|Bi∈U/IND(B),Bi∩X≠∅}为 X 关于 B的上近似集。
定义4设决策系统 T=(U,C∪D,V,f),U/D={D1,D2,…,Di}表示在离散数据下决策特征集D对论域U的等价划分,U/IND(C)={C1,C2,…,Ci}表示条件特征集C对论域U的等价划分,称为C相对于D的正区域。
定义5设决策系统T=(U,C∪D,V,f),对b∈B⊆C,若POSB(D)=POSB-{b}(D),则相对于决策特征D来说特征b是不必要的;否则b是必要的。对∀B⊆C,如果B相对于决策特征D都是必要的,则称特征集B独立于决策特征D。
定义6设决策系统T=(U,C∪D,V,f),若 ∀B⊆C,POSB(D)=POSC(D)且特征集B独立于决策特征D,则称特征集B是条件特征集C相对于决策特征D的一个约简。
定义7设决策系统 T=(U,C∪D,V,f),∀a∈C,R⊆C,定义a相对于R的特征重要度为Sign(a,R,D)= |POSR∪{a}(D)-POSR(D)|。
3 手写样本采集及分布检验
为提取手写样本特征,首先截取手写字母的手写有效区域,然后定义一个SegNum×SegNum的等距划分,将每个样本的长度和宽度SegNum等分,每个样本的特征为[1,SegNum×SegNum]的向量。
手写字母采样策略如下所示:
(1)在可视化界面上用鼠标手写字母,同时给出样本正确的分类,便于样本监督学习。
(2)获取样本特征:首先找出手写字母的上、下、左、右边界,并截取出来,对其进行二值化,如图1所示;然后将截取的手写样本横向、纵向平均划分成SegNum×SegNum个小区域,计算每个小区域中黑像素所占的比例,如果该值大于所有小区域中黑点所占比例的平均值,将该值作为[1,SegNum×SegNum]样本特征向量中对应特征的特征值。

图1 截取后的手写学习样本
(3)为有效充分地学习手写字母样本并降低时间复杂性,样本数 N应该取样本特征数的5~10倍,本文为每类分类收集SegNum×SegNum×6个样本。
(4)将每个样本特征与预期的手写分类结果存储起来以构建手写字母识别决策系统,便于算法学习以提取手写字母分类规则。
根据机器学习理论,工程上很多的统计数据都在一定程度上满足正态分布。为保证手写样本具有一定的随机性、可靠性,对样本的分布做正态分布假设检测:根据单个样本模式的空间维度较大的特点,为提高分布检测的效率,本文采用主成分分析的方法获取特征空间的主成分,并利用 χ2检验法对主成分作正态分布检验。
首先假设手写字母特征符合正态分布 N(μ,σ2),μ,σ2未知。采用最大似然估计对μ,σ2进行点估计,得:
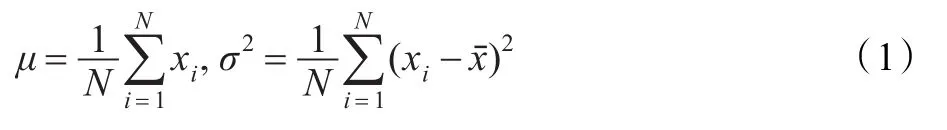
获得分布概率密度后,采用 χ2检验法检验样本是否满足正态分布。χ2检验法可以通过分组数据的取值范围并计算每个分组的频数来实现分布检验的,其统计量如公式(2)。

其中N为样本数,l为分组数,ri为实际频数,ti为理论频数。
4 基于粗糙集的手写字母样本学习与分类
4.1 样本学习算法
本文使用有监督的学习算法,首先建立手写字母识别决策系统,如表1所示。
其中u表示采集的单个样本;pi∈{0,1},表示样本的单块划分范围内是否具有一定数量的有效像素,ClassExpected∈{a,b,c,…,z}表示单个样本的预期分类,SN表示样本总数。

表1 手写识别决策系统结构
每一行代表一个输入样本的模式,D特征为决策特征,代表该样本对应的实际分类。
在手写识别分类算法中,首先要解决的是两类分类的问题。本文基于粗糙集理论,提出了基于粗糙集正域的手写字母学习算法。该算法首先利用粗糙集正域简化手写决策系统,然后从简化的决策系统中抽取所有两类分类规则,并对获取的所有分类规则作一致性检测,去除其中不一致的规则。
算法1基于粗糙集正域的手写字母学习算法
输入手写字母决策系统T=(U,C∪D,V,f)
输出基于T的手写分类规则表Rule
步骤1对T做一致性检测,去除不一致的规则。
步骤2Rule:={},计算T中 D对论域的分类数ClassNum。
步骤3计算条件特征集C相对于决策特征D的正域POSC(D)。
将C赋值给约简集R,R:=C。
如果POSR(D)=POSC(D)成立,重复以下操作:
(1)∀a∈R,计算出该特征的特征重要度Sign(a,R,D);
(2)选择R中特征重要度最小的特征a;
(3)更新约简集R:=R-{a}。
根据R简化T,得到简化的手写决策系统Tsimplified。

步骤5去除Rule不一致规则,输出Rule。
4.2 手写字母分类算法
对手写字母进行了合理的样本采集和决策规则提取后,便可以对测试样本进行分类。算法2描述了测试样本分类的过程。
算法2手写字母分类算法
输入手写分类规则表Rule、待测试样本特征向量sample
输出sample所属的分类result
步骤1result:={},temp:={}。
步骤2计算Rule中的分类总数ClassNum。

将样本逐一匹配决策规则Rule(i,j)中的每条规则;
如果匹配成功,保存匹配规则的分类结果result,跳到步骤4。
步骤4返回分类结果result。
5 实验结果与分析
首先对于 ∀SegNum∈{2,4,6,8,10},根据第3章的采样策略进行手写字母的采样,每个样本的特征数为SegNum×SegNum,每一类学习样本采集数N取n×6,每类待测样本采集数为100。然后对每一类样本作正态分布假设检验,并利用Matlab主成分提取命令pcacov提取“a”分类的学习样本第一主成分,利用jbtest命令对第一主成分进行正态分布检验,结果如图2所示,符合正态分布假设。
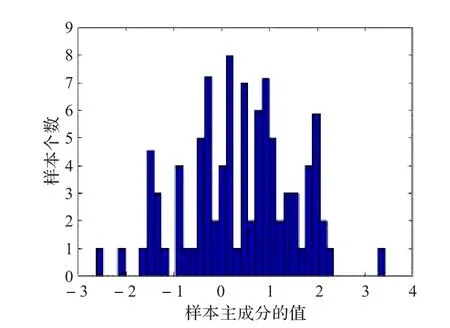
图2“a”分类学习样本正态分布检测结果图
通过类似实验检验其他所有分类的样本正态分布情况,结果表明都符合正态分布假设。
为检验基于粗糙集手写识别算法的有效性,对算法做了纵向对比:当改变手写字母样本的物理分割数SegNum,即改变样本的特征数n=SegNum×SegNum,观察算法在时间消耗、分类准确率、误识率、拒识率上的性能变化。在相同实验条件下实验结果如表2所示。其中SegNum代表手写字母样本的横向、纵向平均划分块数。

表2 样本等分数变化时实验结果比较
由表2可知,当SegNum取6时,手写识别算法的分类准确率较高;SegNum过小或过大算法的分类效果会比较差。当SegNum取过大时,学习算法会出现过拟合的现象,导致算法抗干扰性下降,同时算法的分类正确率也较低。SegNum=6是一个较为合理的样本分割数。
取 SegNum=6,对比 Roughset、BP 神经网络、ID3、Fisher在手写字母识别上时间消耗、分类准确率、误识率、拒识率上的平均性能差异,其中时间包含学习时间以及识别时间,都采用本文设计的样本数据结构。在相同实验条件下实验结果如表3所示。

表3 横向对比实验结果
从表3可以看出,本文提出的基于粗糙集手写字母识别算法具有最优的分类准确率;虽然其时间性能相对较差,但算法的时间代价主要在离线的样本学习过程中,对手写字母的在线识别速度没有影响。实验结果验证了粗糙集算法在性能上的总体优势,具有一定的实用价值。
6 结语
本文基于粗糙集相关理论,提出了一种新的手写字母识别方法。首先对学习样本进行正态分布假设进行验证,然后利用粗糙集原理对手写字母决策系统进行特征选择以适当地简化决策系统,并对简化后的手写决策系统进行分类规则的提取,实验证明算法是有效可行的。由于在样本采样过程中样本离散化会导致样本部分有效信息的丢失,同时算法也没有考虑粗糙集边界元素对粗糙集分类的影响,接下来的工作将应用邻域关系改进本文的算法,并综合考虑粗糙集正域和边界对分类结果的影响,以提高分类算法的分类精度。
[1]刘勇,赵斌,夏绍玮.模糊超椭球分类算法及其在无约束手写体数字识别中的应用[J].清华大学学报:自然科学版,2000,40(9):120-124.
[2]Demirekler M,Altincy H.Plurality voting based multiple classifier systems:statistically independent with respect to depend classifier sets[J].Pattern Recognition,2002,35:2365-2379.
[3]Altineay H,Demirelder M.Undesirable effects of output normalization in multiple classifier systems[J].Pattern Recognition Letters,2003,24:1163-1170.
[4]Pawlak Z.Rough sets[J].International Journal of Information and Computer Sciences,1982,11(1):341-356.
[5]Kryszkiewicz M.Comparative study of alternative type of knowledge reduction in inconsistent systems[J].International Journal of Intelligent Systems,2001,16(1):105-120.
[6]张文修,吴伟志,梁吉业,等.粗糙集理论与方法[M].北京:科学出版社,2003.
[7]刘清.Rough集及Rough推理[M].北京:科学出版社,2001.
[8]Wang G Y,Wang Y.3DM:domain-oriented data-driven data mining[J].Fundamenta Informaticae,2009,90(4):395-426.
[9]Chen Y M,Miao D Q,Wang R Z.A rough set approach to feature selection based on ant colony optimization[J]. Pattern Recognition Letters,2010,31(3):226-233.
[10]Hu Q H,Yu D R,Xie Z X.Neighborhood classifiers[J]. Expert Systems with Applications,2008,34(2):866-876.
[11]Jiang F,Sui Y F,Cao C G.Some issues about outlier detection in rough set theory[J].Expert Systemswith Applications,2009,36(3):4680-4687.
[12]苗夺谦,张红云,李道国,等.基于主曲线的脱机手写数字识别[J].电子学报,2005,33(9):1639-1643.
[13]丁卫平,王建东,段卫华,等.一种求解属性约简优化的协同粒子群算法[J].山东大学学报:理学版,2011,46(5):97-102.
[14]Yao Y Y,Zhao Y.Discernibility matrix simplification for constructing attribute reducts[J].Information Sciences,2009,179(7):867-882.
[15]吴克寿,陈玉明,曾志强.基于邻域关系的决策表约简[J].山东大学学报:工学版,2012,42(2):7-10.
TANG Chaohui,CHEN Yuming,WU Keshou
Department of Computer Science and Technology,Xiamen University of Technology,Xiamen,Fujian 361024,China
According to the characteristics of handwritten letter recognition,a new handwritten letter recognition algorithm is proposed based on the rough set theory.The hypothesis of normal distribution has been tested to ensure the reliability of the collected samples.By using upper approximation,lower approximation,as well as positive region of rough set,feature selection is made in order to simplify the decision-making system.Classification rules are then extracted from the simplified decision-making system.Experimental results show that the new algorithm has higher recognition accuracy, and is feasible and effective.
rough set;positive region;handwriting recognition;feature selection;supervised learning
针对手写字母识别的特点,结合粗糙集相关理论,提出了一种新的手写字母识别算法。通过对采集的样本进行正态分布假设验证,保证样本的可靠性;利用粗糙集上近似、下近似以及正域概念,对手写样本决策系统进行特征选择以简化决策系统,并进一步提炼手写分类规则。实验结果表明,新算法具有较高的识别准确率,是有效可行的。
粗糙集;正域;手写识别;特性选择;监督学习
A
TP181
10.3778/j.issn.1002-8331.1212-0221
TANG Chaohui,CHEN Yuming,WU Keshou.Handwritten letter recognition algorithm based on rough set positive region.Computer Engineering and Applications,2014,50(23):118-121.
国家自然科学基金(No.61103246,No.60903203);厦门理工学院人才科研启动项目(No.YKJ10036R);厦门理工学院教改项目(No.JGY201315);福建省教育厅B类项目(No.JB12252S,No.JB14082);福建省大学生创新创业训练计划项目(No.201411062043)。
唐朝辉(1983—),男,讲师,主要研究方向:粗糙集、机器学习;陈玉明(1977—),男,博士,讲师,主要研究方向:粗糙集、粒计算、数据挖掘;吴克寿(1975—),男,博士,副教授,主要研究方向为粗糙集与数据挖掘。E-mail:chhtang@xmut.edu.cn
2012-12-18
2013-01-25
1002-8331(2014)23-0118-04
CNKI网络优先出版:2013-03-29,http://www.cnki.net/kcms/doi/10.3778/j.issn.1002-8331.1212-0221.html
猜你喜欢
故事作文·低年级(2021年12期)2021-12-21
科教导刊·电子版(2021年6期)2021-05-06
作文成功之路·小学版(2020年7期)2020-08-24
电子制作(2018年18期)2018-11-14
重庆交通大学学报(自然科学版)(2017年3期)2017-05-17
环球市场信息导报(2016年41期)2017-01-19
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
自动化学报(2016年8期)2016-04-16
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
