
布尔矩阵Apriori算法的MapReduce并行化实现
2014-06-15 06:06陈方健张明新
常熟理工学院学报 2014年2期
陈方健 ,张明新 ,杨 昆
(1.苏州大学,计算机科学与技术学院,江苏 苏州 215006;2.常熟理工学院,计算机科学与工程学院,江苏 常熟 215500;3.中国矿业大学,计算机科学与技术学院,江苏 徐州 221116)
人、机、物三元世界的高度融合引发了数据规模的爆炸式增长和数据模式的高度复杂化,世界已进入网络化的大数据时代[1].这些大数据中蕴含着潜在的、有价值的知识,但是基于传统的思维和模式却很难被发现并加以利用.为了摆脱这一局面,数据挖掘技术应运而生.Apriori算法是关联规则挖掘中最基本也是最重要的算法之一.但在大数据时代,传统的Apriori算法已经很难满足人们的需求.为此本文提出将Apriori算法移植到云平台下,解决大数据对传统Apriori算法带来的缺陷.
云计算是一种融合了多种技术的计算模型,具有超大规模性、高可靠性、高可扩展性等特点[2].Hadoop是一种类似于Google“云平台”的一种开源实现.Hadoop上提供了基于Java的MapReduce分布式处理框架,供用户简单实现分布式运算.
本文提出将事务库转化为布尔矩阵以适应MapReduce分布式处理框架分片处理大数据的特点,再结合Apriori算法的思想实现频繁项集挖掘,为在大数据中获取潜在的、有价值的知识提供快速、有效的方法.
1 MapReduce介绍
MapReduce是由Google实验室在2004年提出的一种分布式并行编程模式,主要用于处理基于集群的大规模数据集的分布式处理模型[3-4].MapReduce分布式处理框架将并行化计算抽象为Map和Reduce两个接口.用户通过实现Map和Reduce两个接口以实现并行化,MapReduce框架将输入的大数据文件按行分割为一系列独立的数据块.每个数据块交由一个节点内Map实例处理,用户通过实现Map接口,在单个数据块内处理若干键值对<key,value>,产生若干中间键值对<key,list(value)>.Map函数处理完成后所得到的中间键值对<key,list(value)>,作为Reduce函数的输入并加以处理.用户实现Reduce接口,对每一个中间键值对进行自定义操作得到新的<key,value>.最终将Reduce输出的结果写入到指定文件.MapReduce处理大数据的过程如图1所示:
2 MR_B_Apriori算法的并行化方法
2.1 传统的Apriori算法
Apriori算法主要目的是找出事务数据库中的频繁集.主要思想[5-6]:Apriori利用了频繁集的所有非空子集一定是频繁集的性质.首先扫描一次数据库D,统计各1-项集的支持度得到频繁1-项集的集合L1,自连接得到候选2-项集的集合C2,扫描事务数据库得到L2,如此迭代循环,通过第K次扫描得到Lk.若Lk=Ø,则算法结束.传统Apriori算法在生成Lk的过程中需要逐次扫描事务数据库K次,当数据库很大时会产生严重的I/O瓶颈使算法效率下降.

图1 MapReduce处理大数据的过程
2.2 事务数据库的布尔矩阵表示
对于任一给定的事务数据库D[7],令

其中 :R=f(D)=(rij)n×m,n为事务的个数 ,m为项目的个数,事务集 Ti(i∈n),项目集 Ij(j∈m),
i=1,2,…,n;j=1,2,…,m,于是,事务数据库D经一次扫描后,就可在f的作用下映射成布尔矩阵R,如图2所示.
由以上分析可知,对任何一个事务数据库扫描一次,即可得到与该事务数据库相对应的布尔矩阵.由于布尔矩阵中包含挖掘频繁项集所需要的全部信息,故对事务数据库的关联规则挖掘问题可顺利转化为对其布尔矩阵的分析操作.
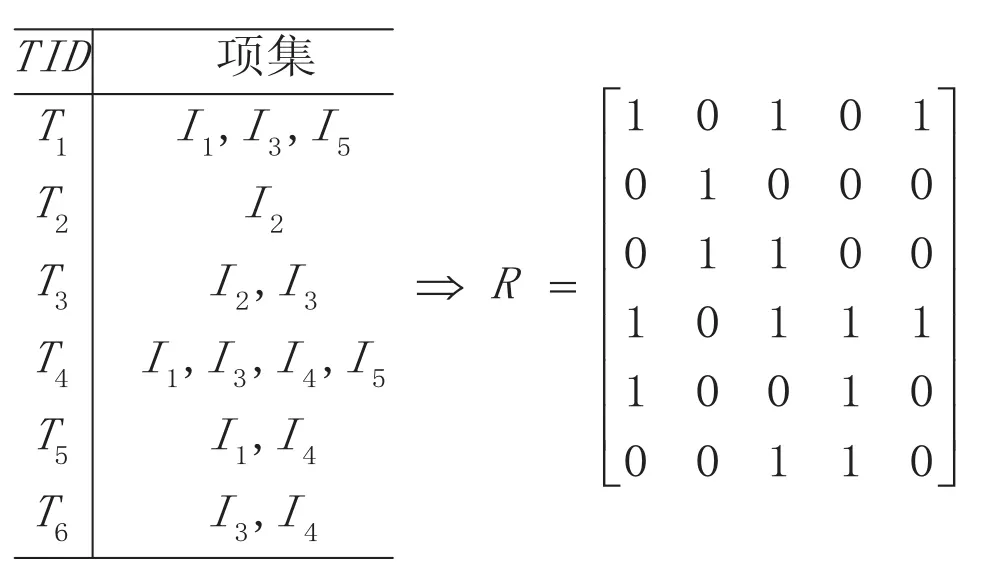
图2 事务数据库D映射一个布尔矩阵R
2.3 MR_B_Apriori的并行化方法
基本思路:根据MapReduce分布式处理大型数据的特点,可将扫描事务数据库一次所得到的布尔矩阵按行(保证事务的完整性)分块,将此大矩阵分解为若干小矩阵.每个小矩阵做转置后交由集群中的节点存储,供每次迭代时Map任务使用.Map任务在单个矩阵中计算候选K-项集的局部频度,然后在Reduce阶段合并融合得出候选K-项集的支持度.并根据给出的最小支持度得出频繁K-项集.MapReduce分布式处理框架能够完成大文件的按行分块.我们只要完成Map函数和Reduce函数的设计就可完成我们的并行化要求.
Map函数的设计:
Map函数的任务是为了统计每个分块矩阵内候选K-项集的局部频度.其输入为<key,value>对,key为代表候选K-项集集合的字符串数组,每个候选K-项集由字符串x-x-…-x表示(x为1,2…与I1,I2…对应),value为分割后的小矩阵.根据候选K-项集的字符串,在矩阵内对应的k个行向量之间做逻辑与运算.将运算结果各位上的数相加得到关于候选相集的局部支持度,若为0则直接丢弃.形成新的<key,value>对,新的key表示候选K-项的字符串,新的value则为该候选K-项集的局部频度.
Map函数伪代码如下:


Reduce函数的设计:
Reduce函数的任务是合并融合Map任务所得到候选K-项集的局部频度,得到候选K-项集的支持度.其输入为<key,value>对,将key相同的<key,value>对的value值相加得到新的<key,value>对. 这里的key值保持不变,value值为候选相的支持度.选择出满足最小支持度的<key,value>对,输出至指定文件得到频繁项集.
Reduce函数伪代码如下:

3 实例分析
为了清楚直观地说明算法运行的过程,这里以图2所示的事物数据库D为例.其转化的布尔矩阵为R.给出的最小支持度Minsup=2.
第一步,由Hadoop框架将关于事务数据库的布尔矩阵R按行分块,得到split0、split1、split2三个分块矩阵.

第二步,将分块矩阵转置后存于群集内的节点.
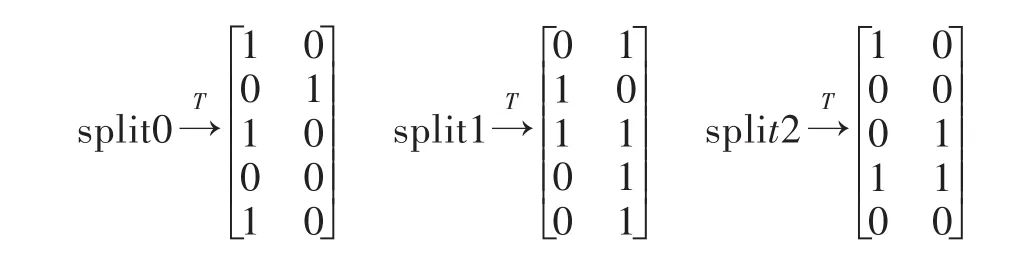
第三步,进行Map任务,以计算频繁2-相集为例.所得的结果为:
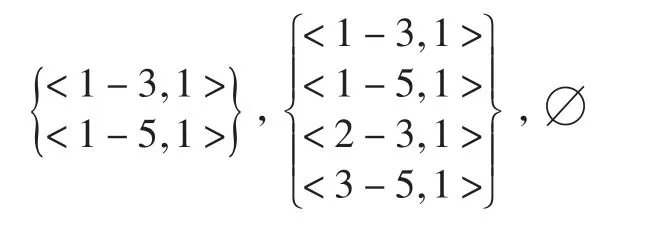
第四步,Reduce任务将 Map任务得到<key,value>对作为输入,将具有相同key值的value值相加得到相集的全局支持度,如图3所示.
第五步,将所得结果相集送至Map进行迭代运算直至候选(K+1)-相集为空集时迭代结束.
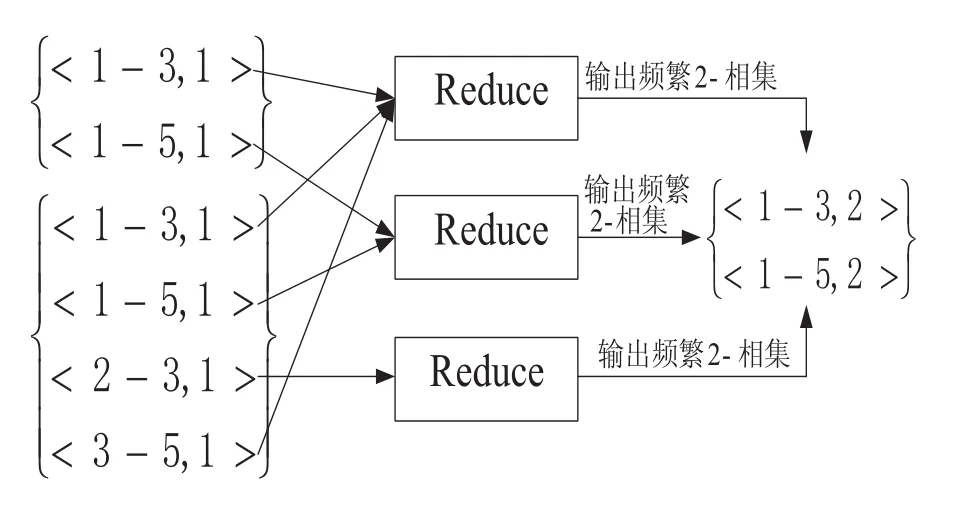
图3 Reduce过程计算全局支持度
4 算法的有效性分析
设|D|为事务库D的事务数,T为最大交易长度.分析Apriori算法可知[8],第一遍扫描事务库D需要O(T|D|),以后每次扫描,连接步骤需要O( ||Lk-1× ||Lk-1),修剪步骤需要O( ||Ck),遍历事务库D对候选集进行统计需要O( ||D× ||Ck),因此最坏情况下Apriori算法的时间复杂度为
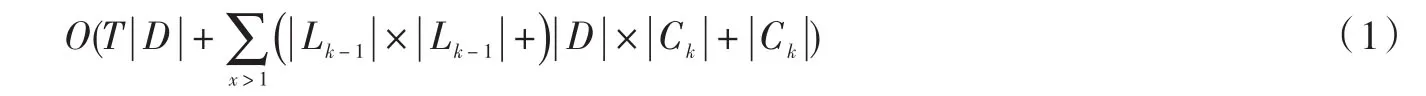
分析MR_B_Apriori算法的并行化实现过程可知,第一遍扫描事务库D得到布尔矩阵R需要O(T | D | ) ,连接步骤需要O(| Lk-1|× | Lk-1|),修剪步骤需要(O | Ck|),设将R分割为m个小矩阵,每个小矩阵有一个Map任务处理则对候选集进行统计需要的时间为O(| D |/m× | Ck|).
因此最坏情况下,MR_B_Apriori的时间复杂度为

比较(1)式和(2)式可见,式(2)中将候选集统计时间除以因子m说明MR_B_Apriori算法每次迭代都会节省O((m-1) ||D/m ||Ck)的时间,可见事务库越大、集群数越多节省的时间就越明显.
5 结束语
本文结合MapReduce分布式处理框架的这种“分而治之”思想和Apriori算法的思想,利用多台机器协同并行处理大数据集,降低了Apriori算法得到频繁相集的时间复杂度.可见将Apriori算法移植至MapReduce分布式处理框架下,对基于云平台的大数据挖掘具有指导意义.
[1]李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J].中国科学院院刊,2012,27(6):647-657.
[2]张石磊,武装.一种基于Hadoop云计算平台的聚类算法优化的研究[J].计算机科学,2012,39(10):115-118.
[3]杨代庆,张智雄.基于Hadoop的海量共现矩阵生成方法[J].现代图书情报术,2009,30(4):23-26.
[4]李玉林,董晶.基于Hadoop的MapReduce模型的研究与改进[J].计算机工程与设计,2012,33(8):3110-3116.
[5]刘敏娴,马强,宁以风.基于频繁矩阵的Apriori算法改进[J].计算机工程与设计,2012,33(11):4235-4239.
[6]饶正婵,范年柏.关联规则挖掘Apriori算法研究综述[J].计算机时代,2012,30(9):11-13.
[7]刘以安,羊斌.关联规则挖掘中对Apriori算法的一种改进研究[J].计算机应用,2007,27(2):418-420.
[8]王锋,李勇华,毋国庆.基于矩阵的改进的Apriori算法[J].计算机工程与设计,2009,30(10):2435-24.
猜你喜欢
房地产导刊(2022年4期)2022-04-19
山东农业工程学院学报(2020年12期)2020-03-19
幽默大师(2019年4期)2019-04-17
幽默大师(2019年3期)2019-03-15
幽默大师(2018年11期)2018-10-27
幽默大师(2018年3期)2018-10-27
天津科技大学学报(2018年4期)2018-08-22
湖州师范学院学报(2016年2期)2016-08-21
计算机工程与设计(2014年3期)2014-12-23
网络安全与数据管理(2010年1期)2010-05-18
