
基于两级分块的文件同步方法
2014-12-23 01:29:50刘晓洁
计算机工程与设计 2014年3期
周 平,刘晓洁
(四川大学 计算机学院,四川 成都610065)
0 引 言
文件同步是指对客户端和服务器上同一文件的不同版本进行同步,使这两个不同主机上文件的版本一致。文件同步广泛用于文件的备份与恢复、web网站镜像等场景中。目前,较常用的文件同步算法有RDC(remote differential compression)[1]和Rsync[2,3]。文件同步主要包括文件分块、hash值比较以及网络传输3个步骤。其中,文件分块是其中最重要的一个步骤。文件分块算法是指按照一定的策略将文件分割成较小的数据块,以用于对比文件之间的细微差异。通常文件的版本之间的差异较小,通过分块能够更加准确地检测两个版本-中的差异数据块。
文件分块算法主要分为固定长度分块(fixed-sized partitioning,FSP)算 法[4]和 基 于 内 容 的 分 块(contented-defined chunking,CDC)算法[5]。FSP算法的特点是易于实现,且分块速度较快,但是对于插入和删除的位置较敏感,不能根据文件自身内容的变化进行调整与优化。而CDC 分块算法能将文件按内容分成大小不等的块,能够较好地检测到差异。目前最常用的CDC 分块 算法 有BSW[6,7](basic sliding window)分块算法和Winnowing[8]分块算法。BSW 分块算法采用的分块规则是预先设定两个正整数D 和r(r<D),若滑动窗口W 的Rabin[9]指纹值F( )W modD=r,则将窗口W 的右边界作为分块的边界点。由于分块受窗口宽度及两个设定值的影响较大,导致分块长度变化范围较大,因此分块效率不稳定。Winnowing算法在一个固定大小的窗口内,计算滑动块的Rabin指纹值,取极值点作为分块的边界点。此算法能够实现按文件内容进行分块,同时又能将分块大小限制在一定的范围内,克服了BSW 算法分块长度变化范围较大的问题,但Winnowing算法存在Rabin值的重复计算,因此分块算法比较耗时。
本文提出了基于两级分块的文件同步方法(DFRSYNC)。该方法首先使用循环队列对Winnowing分块算法进行改进,以提高分块效率;基于该改进的Winnowing分块算法,本文采用两级分块策略,首先设定较大的窗口值和滑块值,分别对客户端和服务器上的文件进行快速分块,初步定位差异块,然后设定较小的窗口值和滑块值进行第二次分块,从而准确定位差异块。
1 DF-RSYNC方法
DF-RSYNC 方法在传统Winnowing 分块算法的基础上,采用循环队列存储hash值以减少部分hash值的重复计算,同时为了更细粒度地检测到差异数据,采用了两级分块策略,因此需要两轮往返来传输两次分块的hash值及最终的差异数据。
1.1 Winnowing分块算法及其改进
1.1.1 传统Winnowing数据分块算法
传统的Winnowing算法原理如图1所示,其中W 代表固定窗口。B1,B2,…,BN-1,BN代表窗口W 内从左边界到右边界滑动块。设Lw为固定窗口大小,LB为滑动块大小,且Lw>LB。
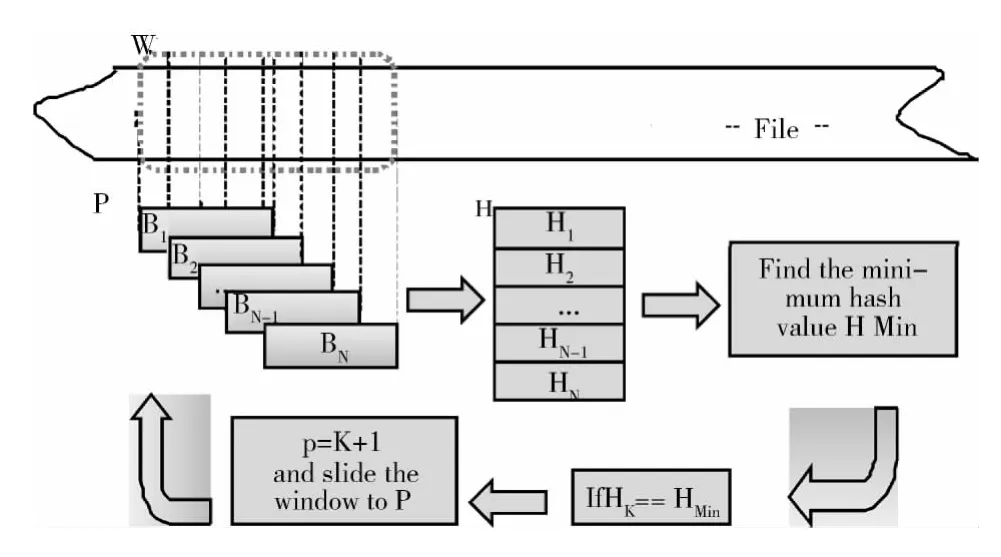
图1 Winnowing数据分块算法
(1)设P为窗口当前的左边界点,滑动块以窗口的左边界为起始点。
(2)若滑块的右边界没有到达窗口的右边界点,则每次向前移动一个字节,得到滑动块B1,B2,…,BN-1,BN,且块数N=Lw-LB。
(3)计算各块B1,B2,…,BN-1,BN的Rabin 指纹值,并保存到hash表H 中。若有Bk(k∈ [1,N]) 满足H(Bk)=min (H (B1),H (B2),…,H (BN)),则划分长度L=k的块,令P=P+k+1为窗口的下一个左边界点,返回(1)。
由上述算法描述可知,Winnowing虽能够实现对文件按内容分块,并将分块长度L限制在LW-LB,但在窗口的移动过程中,部分块的Rabin值存在重复计算的问题。如(3),窗体在分块的前后只滑动了块长L=k个字节的距离,当K 值比较靠近窗口的起始点P 时,就有一部分滑块的Rabin值要重复计算,重复计算的滑动块数是LB-L,这极大地增加了分块的时间。
1.1.2 改进的Winnowing分块算法
为提高分块效率,避免Rabin值的重复计算,本文对上述算法做了改进。本文使用了一个容量为N=Lw-LB+1的循环队列Q,初始时,队列Q 的头指针front与尾指针rear都为0,使滑块的起始位置P初值也为0。
(1)滑块以P为起点,依次向前滑动一个字节,并计算每个块的Rabin 指纹值,依次插入到队列Q 的队尾,rear=rear+1,直到队列Q 满,即(re ar+1 )modN=front。
(2)比较队列Q 中的各滑块的Rabin指纹值,若有Qk(k∈[front,rear])满足Qk=min(Qfront,Qfront+1,…,Qrear),则划分长度为 L= (k-front+1+N )modN新块,且P=P+L。
(3)删除队列中从front 到K 的元素,即front=(k-front+1 )modN。转到(1)。
算法原理如图2所示。
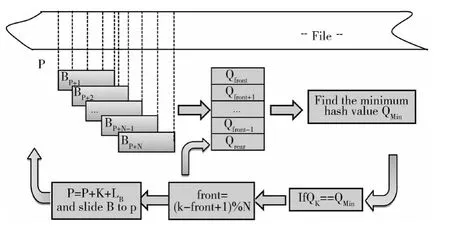
图2 改进的Winnowing数据分块算法
改进的Winnowing分块算法实现如下:

1.2 两级分块方法
为了实现高效准确的差异检测,本文采用了文献[10]提出的两级分块的文件同步思想,其采用的分块方法是首先使用CDC算法粗粒度地定位差异块,再对不匹配的块使用Rsync定长滑动块技术在细粒度上查找差异块。本文中分块算法采用的是改进的Winnowing分块方法。算法流程如图3所示。
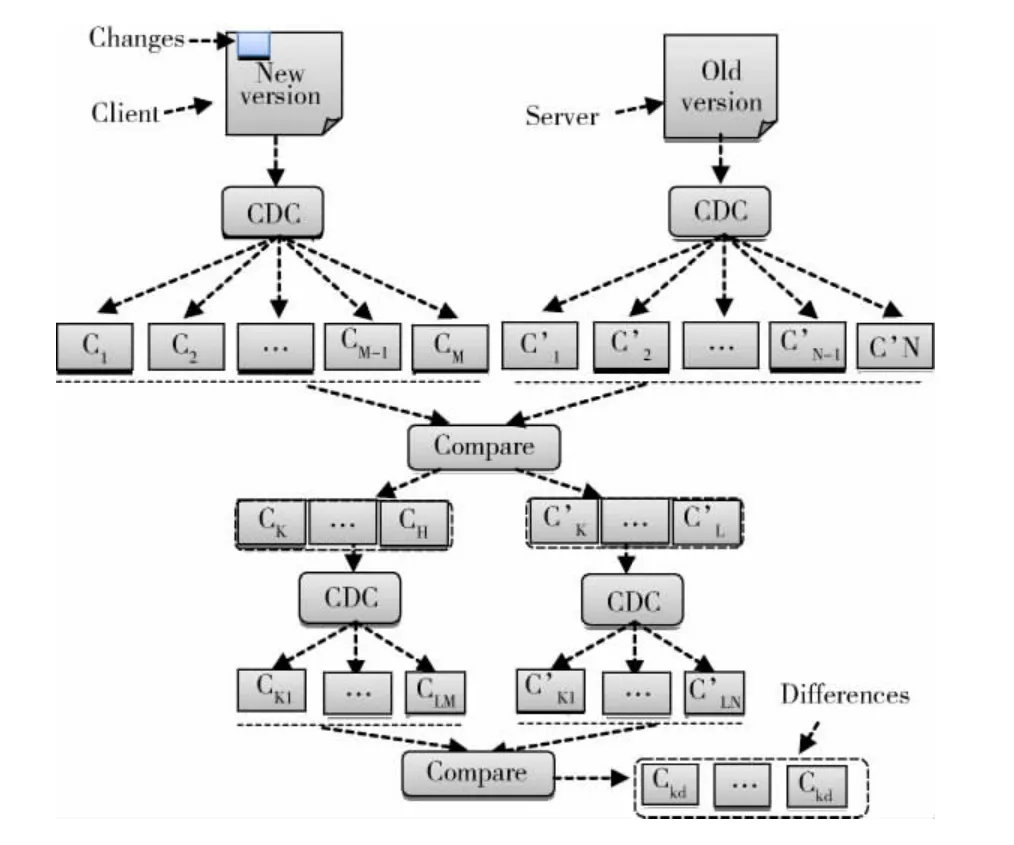
图3 两级分块
首先将固定窗口和滑动块大小设置为较大值,使用改进的Winnowing分块算法,分别对存在于客户端和服务器端的相同文件的不同版本进行分块,其中,客户端为新版本,服务器端为旧版本,分别将新旧版本文件分成C1,C2…,CM块和C′1,C′2,…,C′N块。计算每块的hash值,再将两个版本文件分块的hash值进行比较,分别找出两组分块hash值中不相同的块,如新版本进行比较后的差异块是Ck…CH,旧版本中差异块是C′k,…,C′L。将固定窗口和滑动块的大小设置为较小值,分别对这两组差异块再使用改进的Winnowing分块算法进行再分块,分成Ck1,…,CLM块和C′k1…C′LN块。再将这两组再分块的hash值进行比较,找出有差异的小块Ckd…即为最终的差异数据。
1.3 两轮往返方法
由于本文采用了两级分块策略,因此需要两轮往返来传输两次分块的hash值及最终的差异数据。两轮往返协议如图4所示。首先服务器发送分块请求到客户端,客户端将第一次分块后的Hash值返回给服务器,服务器将对应文件的旧版本进行分块,并将这两个版本的分块Hash值进行对比,并将对比结果以Bitmap存储后发送到客户端,客户端根据收到的Bitmap,对差异块重新进行分块,并将二次分块的Hash值传送到服务器。服务器将其二次分块Hash值与收到的Hash值进行对比后,将二次分块的Bitmap发送到客户端,客户端根据该Bitmap计算出差异数据后,将差异数据发送到服务器。服务器根据两轮收到的bitmap值和差异数据对文件进行重构。
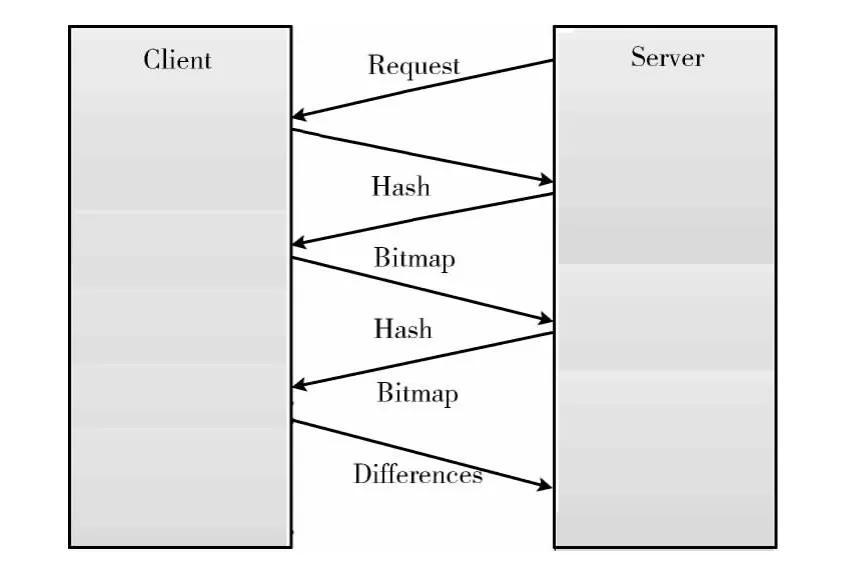
图4 服务器与客户端的两轮往返
在两轮往返过程中,文件块信息存放在各自的主机上。每个信息块是一个数据结构,第一次分块的块信息Block-Info1的格式为<BlockNumber1,BlcokBegin1,BlockLength1>,其中,BlockNumber1为第一次分块块号,BlockBegin1为分块起始位置,BlockLength1 为第一次分块的块长,第二次分块的块信息BlockInfo2 的格式为<BlockNumber1,BlockNumber2,BlockBegin2,BlockLength2 >, 其 中,BlockNumber1为第一次分块的块号,BlockNumber2 为对BlcokNumber1块的第二次分块的块号,BlockBegin2 为第二次分块相对于第一次分块的起始位置,BlockLength2 为第二次分块的块长。
2 实验分析
本实验首先对传统Winnowing分块算法和本文提出改进的Winnowing分块算法在分块的时间上进行了对比。然后基于改进的Winnowing 分块算法,对比了一级分块与DF-RSYNC方法的两级分块方法在差异数据检测的粒度以及同步过程中所产生网络传输量。实验使用SHA1计算分块的hash值,采用socket进行网络数据传输,并用gzip压缩算法对待传输的数据进行压缩。
实验环境如下:服务器与客户端为两台配置相同的主机。具体配置为CPU:双核Intel(R)Pentium (R)Dual CPU 2.20GHz,内存:2GB,硬盘:ST3250310AS 250GB,操作系统:Windows32,网络环境是百兆局域网。文中算法均在Visual Studio 2010下使用C++编程实现。
2.1 分块时间对比
本实验就1.1.1与1.1.2 分别提到的两种分块算法对不同大小文件的分块时间进行对比,如图5所示,分块时间以毫秒为单位。可以看出,由于避免了部分Rabin指纹值的重复计算,改进的分块算法可显著地减少了分块时间。并且随着文件的增大,改进的分块算法的分块时间增长幅度较小。
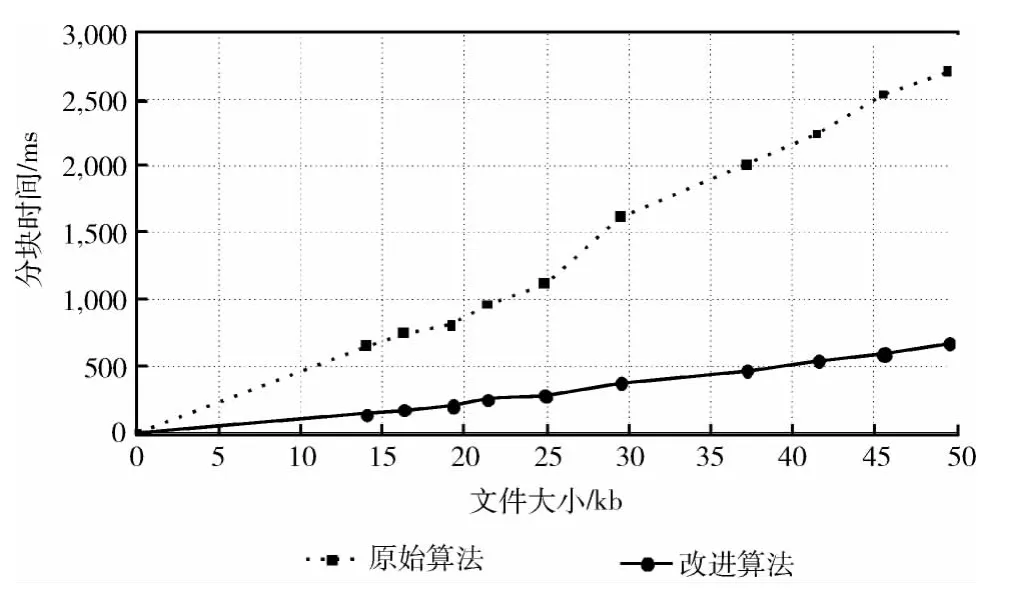
图5 分块时间对比
2.2 差异数据粒度对比
本实验对不同大小的文件采用改进的Winnowing分块算法进行一级分块和二级分块后,分别统计分块后获得的差异数据的大小,并与实际的差异数据大小进行对比,结果如图6所示。实验2.2和2.3采用的一级分块的窗口大小为2048B,滑动块大小为2048B,二级分块的窗口大小是512B,滑动块大小为512B。可以看出,二级分块较一级分块能够更细粒度地检测到差异数据。
2.3 网络流量对比
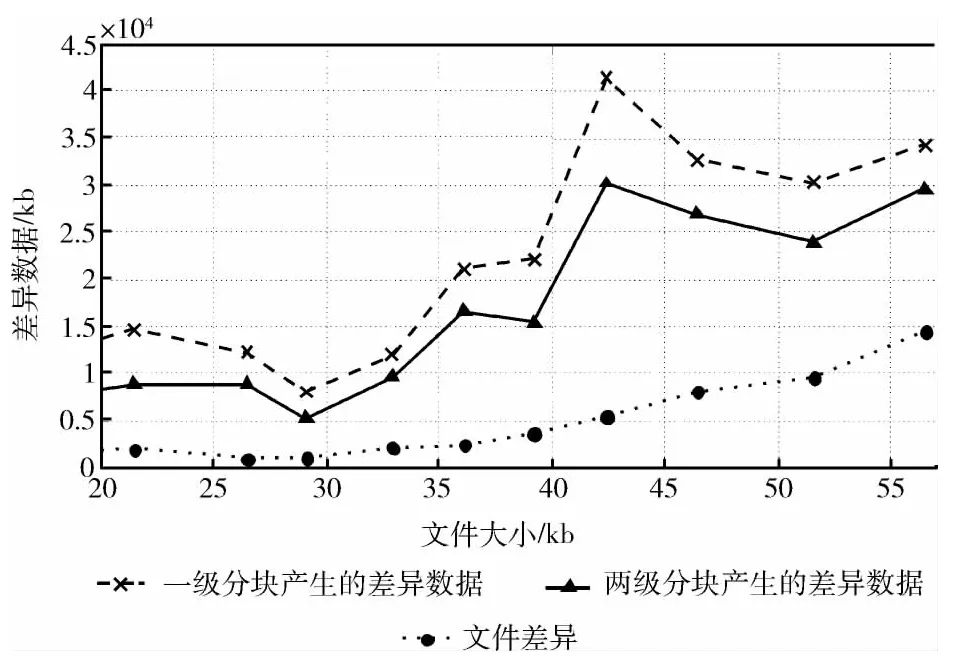
图6 分块粒度对比
该组实验针对使用改进分块算法的文件单轮往返同步方法与DF-RSYNC方法在网络上的数据传输量进行对比。表1记录了一轮往返和两轮往返同步中需要传输的差异数据量、额外数据量和总的数据量,表中除文件大小以KB为单位外,其余数据都以Byte为单位。图7每两个柱形代表在相同的文件大小下,两种同步方法的流量消耗。左边的柱形代表单轮往返的网络流量消耗,右边的柱形代表DF-RSYNC方法的网络流量消耗。每个柱的下部分代表传输中的差异数据量,而上部分代表额外数据的传输量。该组实验结果表明两轮往返同步较一轮往返同步传输的差异数据量要小,但增加了第二次分块的hash值、第二次分块的bitmap值等额外数据的传输。总体上来说,两轮往返同步方法DF-RSYNC 能在一定程度上地减少网络流量的消耗。

表1 一轮往返和两轮往返网络流量对比
实验结果表明,采用了循环队列的Winnowing分块算法可显著减少分块的时间,大大地提高了分块效率。两级分块相对于一级分块能够更精确地定位差异数据,减少差异数据的传输。虽然两级分块的两轮往返相比于一级分块的一轮往返来说,增加了额外的数据量,但由于两级分块检测到的差异数据量较一级分块小,因此两轮往返中差异数据的传输量较一轮往返小。总体上来说,两级分块,两轮往返的网络流量较一级分块一轮往返在一定程度上减少。
3 结束语

图7 网络流量对比
本文针对Winnowing算法的分块效率不高,单级分块的粒度较粗,以及网络中差异数据传输量较大等问题,提出了基于改进的Winnowing分块算法对文件两级分块,两轮往返同步的方法DF-RSYNC。实验结果表明,采用的改进的Winnowing分块算法极大地减少了分块时间,其两级分块策略能更细粒度地定位差异数据,减少了网络上差异数据的传输量。但由于本文的方法DF-RSYNC 增加了第二次分块的hash值等额外信息的传输,因此怎样在细粒度的检测到差异的同时,尽可能地减少额外信息的传输量是今后我们要研究的工作。
[1]Teodosiu D,Bjorner N,Gurevich Y,et al.Optimizing file replication over limited bandwidth networks using remote differential compression [R].Microsoft Research,2006.
[2]Tangwongsan K,Pucha H,Andersen D G,et al.Efficient similarity estimation for systems exploiting data redundancy[C]//INFOCOM,Proceedings IEEE,2010:1-9.
[3]TANG Xiaodi,MA Xiaoxu.Design and implementation of remote file synchronization system based on difference[J].Computer Engineering and Design,2010,31 (20):4389-4392(in Chinese). [汤晓迪,马晓旭.远程文件差异同步系统的设计与实现 [J].计算机工程与设计,2010,31 (20):4389-4392.]
[4]Gharaibeh A,Constantinescu C,Lu M,et al.CloudDT:Efficient tape resource management using deduplication in cloud backup and archival services [C]//8th International Conference on Network and Service Management.IEEE,2012:169-173.
[5]Bjrner N,Blass A,Gurevich Y.Content-dependent chunking for differential compression,the local maximum approach [J].Journal of Computer and System Sciences,2010,76 (3):154-203.
[6]AO Li,SHU Jiwu.Data reduplication techniques [J].Journal of Software,2010,21 (5):916-929 (in Chinese). [敖莉,舒继武.重复数据删除技术 [J].软件学报,2010,21(5):916-929.]
[7]Chang Bingchun.A running time improvement for two thresholds two divisors algorithms[D].San Jose:San Jose State University,2009.
[8]Murugesan M,Jiang W,Clifton C,et al.Efficient privacypreserving similar document detection [J].The VLDB Journal—The International Journal on Very Large Data Bases,2010,19 (4):457-475.
[9]Jarrous A,Pinkas B.Secure computation of functionalities based on hamming distance and its application to computing document similarity [J].International Journal of Applied Cryptography,2013,3 (1):21-46.
[10]XU Dan,SHENG Yonghong.High effective two-round remote file fast synchronization algorithm [J].Journal of Frontiers of Computer Science and Technology,2011,5 (1):38-49 (in Chinese).[徐旦,生拥宏.高效的两轮远程文件快速同步算法 [J].计算机科学与探索,2011,5 (1):38-49.]
猜你喜欢
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
制造技术与机床(2018年11期)2018-11-23 01:08:02
传媒评论(2018年4期)2018-06-27 08:20:24
传媒评论(2018年4期)2018-06-27 08:20:16
电子测试(2018年10期)2018-06-26 05:53:34
意林(绘英语)(2018年1期)2018-04-28 01:21:42
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
地理与地理信息科学(2015年4期)2015-10-13 08:29:16
城市轨道交通研究(2015年11期)2015-02-27 11:02:50
