
基于K 均值与决策树的P2P流量识别研究
2014-12-23 01:34张治斌
计算机工程与设计 2014年3期
张治斌,谭 静
(1.河南理工大学 现代教育技术中心,河南 焦作454003;2.河南理工大学 计算机科学与技术学院,河南 焦作454003)
0 引 言
在P2P网络管理中,P2P 流量识别已经成为网络领域需要研究的一个核心课题[1]。早期的流量识别技术通过端口号和应用层载荷特征进行识别。但是P2P在后来的发展中采用了随机动态端口,端口伪装以及应用层数据加密等技术,使得它们的识别准确度无法保证,因此基于机器学习的识别方法成为了目前研究的热点[2]。文献[3]使用KMeans算法识别不同网络流,Erman等人[4]用EM 算法来分类网络流量,并与贝叶斯方法进行比较。此类无监督学习方法可以直接聚类没有类别标记的训练样本,因此可以发现新的网络应用,但是具有稳定性差,计算资源耗费大的缺点。徐鹏等人[5]提出了基于决策树的流量识别方法,文献[6]使用支持向量机对P2P流量进行识别。该类有监督学习方法在分类精度和时间方面展现出很好的性能,但是用来建立分类器的大量高品质标签样本难以获取。文献[7]提出了基于K-Means的半监督流量分类方法,利用少量标记样本和大量无标记样本进行聚类,具有较好的分类效果,但其分类准确率一般低于有监督学习方法。
本文针对这些不足提出了一种基于K 均值与决策树的P2P流量分类模型,该模型首先利用基于K 均值的半监督分类算法对数据样本进行预处理,然后用处理过的样本训练决策树识别模型。在标记样本较少的情况下,对P2P 流量具有较高的识别精度。
1 决策树分类模型
1.1 模型原理
决策树是一种有监督学习的方法,它是利用归纳的方法通过对建立的属性叶子节点进行测试从而形成的一种树形结构的学习规则。本文采用的是决策树中最经典的C4.5算法,在属性的选择上,它采用信息增益率作为标准,选择信息增益率大的属性产生节点,进而再根据属性的不同取值建立不同的分支,在分支上通过重复该方法再建立分支,直到一个分支仅包含同一类别的数据。在流量识别问题上,设网络流训练样本数据集X={X1,X2,……,Xn},它的属性集Q={Q1,Q2,……,Qm},通过训练,将网络流划分为不同类别的信息熵为

式中:p(Xi)=|Xi|/|X|,|Xi|为第i类的网络流个数,|X|为网络流总数。对其中一个属性Qm进行测试,设Qm的值域为{q1,q2,……,qt},数据集对Qm的条件熵为M(X,Qm=qj)log2p(Xi|Qm=qj)),其中p(Xi|Qm=qj)=|Cij|/|Yj|为在测试属性Qm=qj时属于第i类的决策概率,|Cij|为当Qm=qj时属于第i类的网络流个数,|Yj|为Qm=qj情况下网络流总个数。选择属性Qm进行划分后的对分类的信息熵为

属性Qm的信息增益为

属性Qm的信息增益率为


1.2 决策树构建过程
构建决策树模型包括分类器的训练和分类器的测试两个阶段。在分类器的训练阶段,首先通过训练生成一棵初始决策树,然后通过剪枝处理对决策树进行简化,最后提取分类规则建立分类器。分类器建立后,为了评估分类模型的准确性,在第二阶段需要用测试数据集对其进行测试。
1.2.1 决策树模型的生成
在C4.5算法中,生成初始决策树的关键在于根据信息增益率选择每个节点的最佳测试属性。构建C4.5决策树的算法过程如下:
(1)对样本集的连续特征进行离散化处理。
(2)对决策树T 进行初始化,使得T 只包含一个根节点(X,Q),X 为样本集,Q 为属性集。
(3)if(叶节点(X’,Q’)中的X’属于同一类别或者Q’为空)

(4)任选一个不满足上述条件的节点(X’,Q’)

(5)选择满足条件max(ratio(X’,Q’m))的属性A 对节点(X’,Q’)进行测试。
(6)for each A=Ai

(7)返回(3)
初始决策树生成后,为了消除统计噪声或数据波动对决策树的影响,对决策树采用后剪枝算法进行修剪,不具有代表性的叶节点或分支将被从决策树中剪去,达到简化决策树的目的。剪枝完成后,提取算法生成的分类规则来建立分类器,分类规则是从决策树的根节点到其中任意一个叶节点的路径的集合,通常用if-then的形式来表示。分类模型构造过程如图1所示。
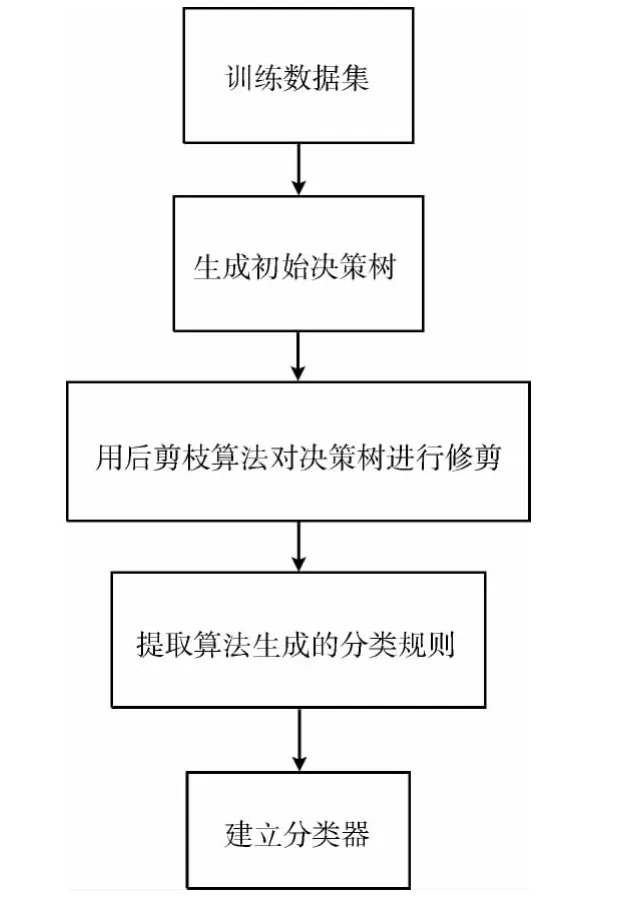
图1 分类模型构造过程
1.2.2 分类模型的评估
为了评估分类模型的准确性,需要用创建好的分类模型对与训练集相互独立的测试集进行预测,然后将结果与实际值进行比对,本文采用十折交叉验证法对分类模型进行验证,把数据集分为十份,其中一份作为测试集,其余九份轮流作为训练集,十次测试准确率的平均值即为分类模型的精度。
2 基于K-Means与决策树的P2P流量识别模型
在机器学习算法中,有监督学习比无监督学习具有更高的检测精度和分类速度,而在有监督学习中,经过各类研究的对比验证,决策树算法在流量分类精度和时间方面,比支持向量机、贝叶斯算法和神经网络等显示出了更好的性能,但是,由于使用决策树算法建立分类模型时,在离线学习阶段需要利用大量的高品质标签样本进行训练来提高算法的准确性,而现实中,标签样本的获得随着P2P 流量的加密变得越来越困难,基于这个问题,本文在使用决策树算法建立分类模型之前,采用K-Means半监督聚类算法对含有大量无标签样本和少量标签样本的训练数据集进行预处理,利用标签样本建立的映射关系得到不同簇的类别,进而获取无标签样本的类别标记,实现在只有少量标签样本的情况下,分类模型也能保持较高的识别精度。
2.1 K-Means半监督聚类
K-Means聚类一般利用无标签样本进行聚类,无法利用标签样本提供的有效信息,使得对样本的聚类精确度受到限制,为提高聚类的准确性,为决策树训练提供准确的标签样本,本文采用K-Means半监督聚类来实现对数据集的预处理,算法思想描述如下:
(1)将标签样本和无标签样本合并为一个样本集X={X1,X2,……,Xn},第i个样本的类别用Yi表示,标签样本的Yi已知,无标签样本的Yi未知,任一样本向量可以表示为(Xi1,Xi2,……,Xij),Xij为第i个样本的第j个特征。
(2)用K-Means算法[8]进行聚类,将样本集划分为K个不同的簇{C1,C2,……,Ck}。
(3)建立簇与标签间的映射关系,假设在一个簇内的所有样本的类别都是相同的,簇Ck内属于Yi的样本概率表示为P(Yi|Ck),计算公式为

式中:njk——Ck中标记为Yi的样本数,nk——Ck中的总样本数。
(4)最后通过簇标签决策函数来确定Ck中的样本类别,计算公式为

2.2 识别模型
根据上述思想描述建立流量识别模型,该模型包含4个模块,如图2所示。
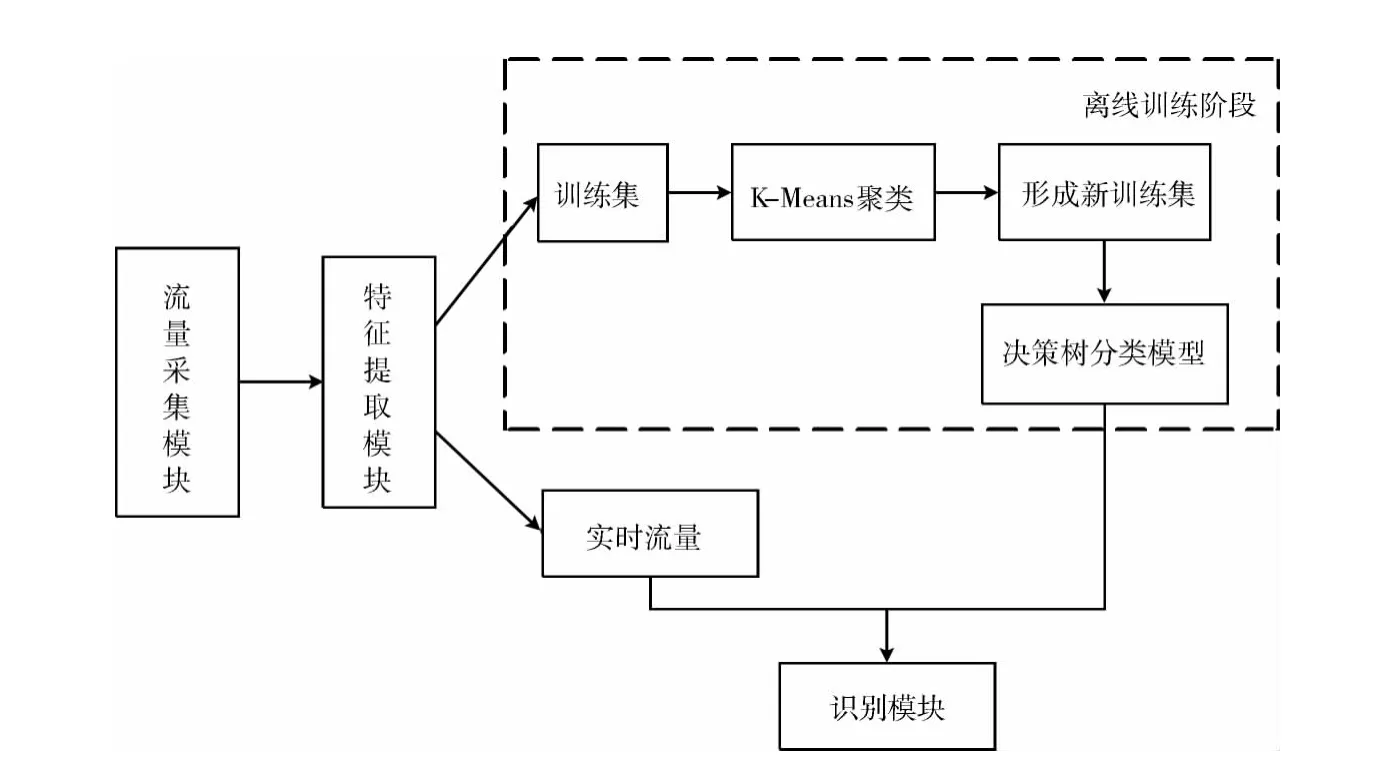
图2 流量识别模型
流量采集模块:此模块的功能是采集用作离线训练和实时识别的网络流量。
特征提取模块:对采集的流量的统计特征进行选择,筛选出对分类有价值的特征,以实现降维,提高分类效率。
离线训练模块:该模块的功能是通过训练得到分类模型。用K-Means半监督算法对训练样本集进行聚类,通过计算最大后验概率来确定簇类别,形成新的训练样本集,最后进行决策树分类模型的训练。
识别模块:用训练好的分类模型对实时网络流量进行在线识别。
2.3 算法描述
基于K 均值与决策树的P2P流量识别算法描述如下:
步骤1 将准备的标签样本集M={(xi,yi)|i=1,2,……,m}和无标签样本集N={xj|j=1,2,……,n}合并为一个样本集D,对D 进行特征提取。
步骤2 从混合样本集D 中任意选取K 个对象作为初始聚类中心。
步骤4 分配完毕后,重新计算每个簇中样本的平均值,作为新的聚类中心。
步骤5 将新的聚类中心与上一次的聚类中心进行比较,如果不同,转步骤2,如果相同,转步骤6。
步骤6 通过聚类得到K 个不同的簇C={ci|i=1,2,……,k},根据最大后验概率确定簇类别,对簇中无标签样本进行标记,与之前的标签样本混合形成新的样本集D1。
步骤7 用新样本集D1训练决策树分类模型,并采用十折交叉验证法对分类模型进行测试。
3 实验与结果分析
3.1 实验准备
实验采用Moor数据集[9],Moor数据集将网络应用类型分成了10类,共包含249种不同的特征属性,通过随机抽样从数据集中抽取代表非P2P应用的数据流与P2P应用的数据流。实验使用一台普通PC(双核CPU,2G 内存,Windows 7操作系统),采用Matlab7.1作为仿真工具。
在机器学习流量识别方法中,对流统计特征的选择往往对识别结果的准确性有非常大的影响,所以在选择特征时,要尽量剔除无关的特征,留下对分类有价值的特征。本文对Moore提出的249个流特征采用FCBF 算法[10],从中选择出8个特征组合成特征子集,如表1所示,特征名_ab表示客户端到服务器端,特征名_ba表示服务器端到客户端。

表1 流特征及描述
3.2 结果分析
实验从两个方面对识别模型的性能进行了分析:标签样本数与K 值对识别模型精度的影响以及不同标签样本数对两种识别模型的准确率影响。
(1)标签样本数与K 值对识别模型精度的影响
由于模型采用k-means半监督聚类对训练样本集进行预处理,聚类效果与K 值的选择有很大关系,而标签样本为聚类提供了有效的样本分布信息,所以K 值的大小以及标签样本的多少对识别模型的精度都有一定的影响。为了对比标签样本数、K 值与识别精度的关系,实验设置3组不同K 值(K=10,20,30),在标签样本数变化的情况下,对识别准确率的影响如图3所示。

图3 标签样本数、K 值大小与识别精度的关系
从图3中可以看出,当标签样本数较少时,K 值设置过高反而会影响识别精确率,这是因为聚类过程中标签样本过少造成分布信息的反映不全面。随着标签样本数的增多,模型识别准确率随之增高,当标签样本数大于500时,K 值越大识别精确度越高。在实际情况中,可以根据训练集中标签样本的数量来设置K 值大小。
(2)不同标签样本数对两种识别模型的准确率影响
为了进一步测试识别模型的准确率,分别在训练集中标签样本数为50、100、200、500、1000、2000的情况下,使用本文识别模型与决策树识别模型进行分类实验,结果如图4所示。

图4 两种模型识别精度与标注样本数的关系
图4结果表明,在训练集中标签样本数较少时,本文识别模型表现出了较高的识别精度,随着标签样本数的增加,两种识别模型的精度逐渐增高,标签样本数大于1000时,两者的识别精度几乎相同。实验表明,在现实大量标签样本难获得的情况下,基于K 均值与决策树的识别模型能保持较高的识别准确率。
4 结束语
现阶段针对有监督学习的流量识别方法的研究很多,但是随着越来越多的P2P流量使用加密技术,训练分类器需要的标注样本变得更加难以获得,从而大大限制了识别的准确度。本文引入一种基于K 均值与决策树的P2P流量识别模型,该模型首先利用基于K 均值的半监督聚类算法对包含少量标记样本和大量未标记样本的数据集进行预处理,利用已标记样本建立映射关系,从而获得未标记样本的类别信息,最后利用标记过的样本集训练决策树分类模型,实验结果表明,在标签样本较少的情况下,这种方法能保持较高的识别精度。下一步将利用更多的流量特征对识别模型进行改进以提高识别性能。
[1]LU Gang,ZHANG Hongli,YE Lin.P2Ptraffic identification[J].Journal of Software,2011,22 (6):1281-1298 (in Chinese).[鲁刚,张宏莉,叶麟.P2P流量识别 [J].软件学报,2011,22 (6):1281-1298.]
[2]LIU Qiong,LIU Zhen,HUANG Min.Study on internet traffic classification using machine learning [J].Computer Science,2010,37 (12):35-66 (in Chinese).[刘琼,刘珍,黄敏.基于机器学习的IP 流量分类研究 [J].计算机科学,2010,37 (12):35-66.]
[3]ZHANG Longcan,LIU Bin,LI Zhitang.Characteristics selection of network traffic under machine learning classification[J].Journal of Guangxi University,2011,36 (z1):6-10 (in Chinese).[张龙璨,柳斌,李芝棠.机器学习分类下网络流量的特征选取 [J].广西大学学报,2011,36 (z1):6-10.]
[4]Erman J,Mahanti A,Arlitt M.Internet traffic identification using machine learning techniques[C]//San Francisco,USA:Proc of 49th IEEE Global Telecommunications Conference,2006.
[5]XU Peng,LIN Sen.Internet traffic classification using C4.5 decision tree[J].Journal of Software,2009,20 (10):2692-2704 (in Chinese).[徐鹏,林森.基于C4.5决策树的流量分类方法 [J].软件学报,2009,20 (10):2692-2704.]
[6]PAN Shanrong,FU Ming,SHI Changqiong.Application of the supporting vector machine in P2Ptraffic identification [J].Computer Engineering and Science,2010,32 (2):38-113 (in Chinese).[盘善荣,傅明,史长琼.支持向量机在P2P 流量识别中的应用 [J].计算机工程与科学,2010,32 (2):38-113.]
[7]Kritchman S,Nadler B.Non-parametric detection of the number of signals:Hypothesis testing and random matrix theory[J].IEEE Transactions on Signal Processing,2009,57(10):3930-3941.
[8]LIU Sanmin,SUN Zhixin,LIU Yuxia.Research on P2Ptraffic identification based on K-means ensemble and SVM [J].Computer Science,2012,39 (4):46-74 (in Chinese).[刘三民,孙知信,刘余霞.基于K 均值集成和SVM 的P2P流量识别研究 [J].计算机科学,2012,39 (4):46-74.]
[9]Li Wei,Canini M,Moore W.Efficient application identification and the temporal and spatial stability of classification schema[J].Computer Networks,2009,53 (1):790-809.
[10]ZHU Xin,ZHAO Lei,YANG Jiwen.Network traffic classification method based on concept-adapting very fast decision tree[J].Computer Engineering,2011,37 (12):101-103(in Chinese).[朱欣,赵雷,杨季文.基于CVFDT 的网络流量分类方法 [J].计算机工程,2011,37 (12):101-103.]
猜你喜欢
甘蔗糖业(2022年2期)2022-05-22
湖南林业科技(2021年3期)2021-12-02
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
郑州大学学报(医学版)(2015年1期)2015-02-27
