
对等网络中高频访问区域的发现算法
2014-12-23 01:30郑晓健郑晓兰付铁威庞淑英
计算机工程与设计 2014年3期
郑晓健,郑晓兰,李 彤,付铁威,庞淑英
(1.昆明理工大学 津桥学院 计算机科学与电子信息技术系,云南 昆明650106;2.云南省计量测试技术研究院,云南 昆明650228;3.云南大学 软件学院,云南 昆明650091;4.昆明理工大学 计算中心,云南 昆明650093)
0 引 言
为了使非结构化对等网络的资源搜索算法具有更高的命中率,研究者们的思路转向构造良好的P2P覆盖网络拓扑来改善查询算法的性能[1,2,16]。人们发现传统的非结构化P2P网络完全随机的拓扑和洪泛查询算法在系统性能上的表现不能令人满意,在查找流行资源时可以获得高命中率,但检索稀有资源时的效果并不好,统计数据显示命中率还达不到82%,而且网络带宽 的 消 耗 很 大[1-5,9,16]。基于索引副本缓存的方法为此提供了较好的解决方案,即在网络中扩散稀有资源的索引,使查询包在路由过程中依靠索引尽快找到资源[1,2,9]。问题是扩散范围该如何控制呢?因为将所有稀有资源的索引副本都到扩散网络节点中去固然能提高搜索命中率,但也会消耗节点的大量存储和网络的带宽资源[1,2]。
本文的思想就是在扩散稀有资源索引副本时利用非结构化对等网络搜索具有的局部性[3]来控制范围。大量研究发现P2P搜索具有局部性,合理运用不同的局部性可以显著提高非结构化P2P网络的资源搜索命中率[3]。具有代表性的是文献 [1,2]利用搜索的空间局部性提出的在节点中设立分级索引副本表并将稀有资源的索引副本分类扩散到节点的方法。文献 [1]提出两站式索引副本算法(twohops index replication,THIR),第1站设在每个节点,存储所有直接邻居的稀缺资源索引副本。第2 站设超级节点,存储两步(two hops)之内的超级节点的索引副本。遍历所有超级节点就可以找到在线资源。文献 [2]针对THIR 算法存在超节点负荷过重和单点易失性问题提出了改进算法(new layered two-hops index replication,NLIR),第1 站仍设在每个节点,邻居节点的稀有资源索引副本存储在其索引副本表(index replication table,IRT)中,第2站按照节点的异构性将节点分为三级,各级别分配数量不等的索引副本即由网络带宽和存储费用构成多阶段决策模型,用动态规划法求出分配数量的最优解。该方法的搜索命中率略高于THIR,但算法较复杂且耗时。尽管文献[1,2]等两站式索引副本扩散方法存在以上问题,但说明可以通过改变网络局部的检索环境来改善系统整体性能。本文提出的高频访问区域索引副本扩散算法(the diffusion of high frequency access areas index replication,DHFA2IR)是利用高频度访问节点在网络中聚集的局部特性实现的。实验说明在TTL 受限时算法比THIR 有更高的搜索命中率。
1 高频访问区域发现算法
1.1 搜索的局部性
由文献[3]可知局部性是P2P 搜索具有的典型特征。P2P搜索中存在多种局部性,如时间局部性、空间局部性、兴趣局部性和语义局部性等[3]。实验表明还有一种因频繁访问节点而引发的高频度访问节点在网络局部聚集的特性。通常情况下,高度数节点具有高访问概率、较好的网络带宽、在线时间较长且稳定、处理速度快,而低度数节点的网络处理能力较差且不稳定[3]。高度数的节点易成为高频度访问节点,原因在于网络的幂律分布特性[2,3,9]。若以随机漫步或洪泛方式访问高度数节点后,其周围同样会出现更多高频度访问节点,且随着访问量的增加高频访问节点还会逐渐扩散到更大范围。这种高频度访问节点在局部聚集的现象称为高频访问节点的聚集局部性。利用该特性,在高度数节点产生的高频度访问节点中选择部分稳定性较高的节点作为索引副本扩散的目标,就能实现提高索引命中率和平衡负载的目的,另外还因非结构P2P搜索本身所具有的高鲁棒性而使节点在动态变化时对搜索几乎不产生影响[3]。
1.2 相关定义
用无向图G 表示P2P网络,G=(V,E)其中V 为G 的节点集合,对应网络中的Peer节点,E 为边的集合,表示Peer节点间的连接。任意节点vi∈V,vj∈V,若(vi,vj)∈E,则必有(vj,vi)∈E。任意节点vi∈V 的度(或邻居数)mvi为与此节点相连的边的个数[9]。
定义1 若节点vc通过某条路径(vo,v1,v2,……,vm,vo)访问vo,则称vc为源节点,vo为目标节点,并统称为核心节点。
定义2 vc的访问覆盖区域,简称vc的覆盖,记为Hc={vi|vi∈V,d(vc,vi)≤k,i=1,2,…,h},其中vc与vi间至少存在一条无重复节点的访问路径(vo,v1,v2,……,vm,vi),d(vc,vi)为vc到vi的最短路径长度,h 为Hc中的节点数,k为vc所发消息的TTL。
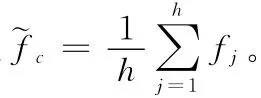
定义4 覆盖Hc的高频访问节点构成的集合Γc={vd|vd∈Hc,d=1,2,…m,fd>珟fc}称为覆盖Hc的高频访问区域HFAA(high frequency access areas)。
定义5 节点vi的邻居节点集定义为Ni={vj|vj,d(vi,vj)=1,j=1,2,…,m},m 为vi的度。
1.3 高频访问区域的存在性和产生的范围

证明:由假设知,Aij为基本事件,vi向网络发送和接收消息都要通过vij完成即AijAil=,Ai1+Ai2+…+Aim=Ω,所以Ai1,Ai2,…,Aim是一个完备事件组,由此

另外,由贝叶斯公式
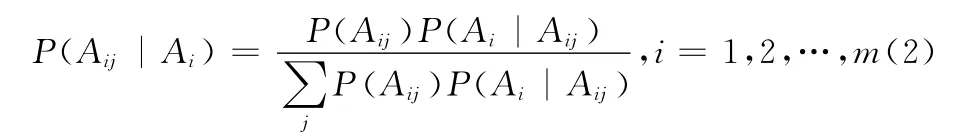
而消息洪泛时vij对于进出vi的消息都会转发即

因此由式(1)和式(3),可得式(2)为
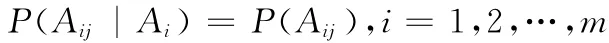
但vi既向任何邻居发送消息,也从任何邻居接收消息即P(Aij|Ai)≤P(Ai),因此P(Ai)≥P(Aij),于是引理成立,证毕。
说明两个核心节点的互访路径上的节点接收或发送消息的概率高于非路径节点,产生较高访问次数的概率也高于非路径节点。
定理1 若核心节点覆盖的交集非空,则在它们交集中产生高频访问区域的概率高于覆盖中其他区域。
证明:首先,设核心节点vc和vo的覆盖分别为Hc和Ho,且Hc∩Ho≠,即Hc∩Ho={v′i|v′i∈Hc∩v′i∈Ho}。由定义2知vc和vo都有路径与v′i链接,因此可设vc和vo的互访路径为(vc,v1,v2,…,vk,v′1,v′2,…,v′m,v1,v2,…,vs,vo),k≥0,m>0,s≥0,其中路径上的分段(v′1,v′2,…,v′m)为vc和vo互访时形成的重叠部分,该部分节点构成的集合为Γ={v′d|v′d,d=1,2,…m},显然ΓHc∩Ho。设vc和vo互访使节点v′d∈Γ产生的访问次数为f′d,使非重叠部分的节点vi∈(Hc∪Ho)-Γ 产生的访问次数为fi。由引理知,f′d≥fi的概率大于f′d<fi的概率,因此Hc∩Ho≠时定理成立。
另外,假设H1∩H2∩…∩Hn-1≠时定理成立,如果
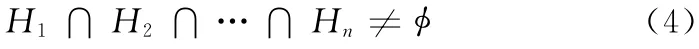
则Hn≠,由集合的结合律知式 (4)可表示为
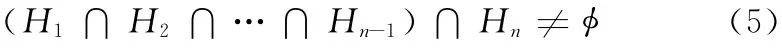
即集合H1∩H2∩…∩Hn-1和Hn的交集非空,由前面的证明知两个的交集中产生高频访问区域的概率高于覆盖的其他节点,因此定理结论成立,证毕。
利用定理1的结论,发现算法的目标就是到覆盖的非空交集中去寻找高频访问区域。
定理2 访问覆盖中的任意节点可以在该节点的邻居节点范围内产生高频访问节点。
证明:设-vc∈Hc,vc的度为m,且其邻居集为Nc即-vi∈Nc,i=1,2,…,m,节点vi的被访问次数记为|vi|。如果vi∈Nc,vj∈Nc,i≠j且|vi|=|vj|,由定义1,-vo∈Ho,当vo访问vc时,必然-vi∈Nc,使|vi|至少增加1,于是|vi|>|vj|,i≠j;否则,如果|vi|≠|vj|,i≠j,即有|vi|>|vj|或|vi|<|vj|;由定义3,vc的邻居节点中总能得到访问次数大于其他邻居节点的节点,且其访问次数高于邻居节点的平均值即在vc的邻居节点范围存在高频访问节点,因此定理结论成立,证毕。
由定理2 可以知,通过访问覆盖中预设的目标节点,就可以使其邻居节点中产生高频访问节点,从而使高频访问区域的位置产生在可以预测和控制的范围内。
1.4 索引副本扩散和资源检索
利用以上结论,索引副本设为两站式结构,第1 站设在每个节点上,存储所有直接邻居的稀缺资源的索引副本。搜索的局部性表明,节点更有可能从邻近的节点那里得到查询应答,设此站的目的是尽量建立和邻近节点的连接,让搜索算法优先查找邻近节点[3],第2站设在高频访问区域的节点上,让高频访问节点的索引副本相互扩散,以提高检索命中率[8-10]。可以在网络中选择一批高度数节点作为种子,然后由种子节点采用随机走或洪泛算法互发建立高频访问区域消息,这样在种子节点的邻居中将产生覆盖的交集,进而形成覆盖的高频访问区域,再经过高频访问节点间的信息互换就实现了索引副本的扩散。普通节点建立高频访问区域表HFAAT(high frequency access areas table),记录高频访问节点的ID、IP、覆盖ID;高频访问节点还要建立索引副本表IRT(index replication table),记录覆盖中所有节点的ID、IP、关键字、文件属性[2]。
首先,定义如下记号:节点vi发消息M 给节点vj记为vi|Mvj;节点vj收到节点vi发的消息M 记为vivj|M;节点vj向邻居转发消息M(检查M 的TTL 是否为0,不为0则转发M,否则停止转发)记为vj|M。
算法1:高频访问区域索引副本扩散算法DHFA2IR
输入:核心节点T={v1,v2,…,vm},vi∈T 建 立HFAAT;
输出:高 频 访 问 区 域Γ1,Γ2,…,Γm,ΓjHj,v∈Hj的HFAAT 记录覆盖的高频访问节点,v′j∈Γj,v′j建立HFAAT 和IRT;
(2)vivt|M,vt∈Hj,vt检查M,若不重复则η++;vj还要将vi的信息记录到HFAAT,并检查η≥m 否?是,vj|Mηvt,vt∈Hj;vt|M;
(3)vjvt|Mη,vt∈Hj,vt以节点的ID、IP、关键字、文件属性、节点的度mt和η 等信息产生Mrη,vt|Mrηvj;vt|Mη;
(4)vtvj|Mrη,vj将vt的信息记录到IRT;获得Hj的所有n 个节点的信息后,计算,找出η>avg 和mt超过设定值的节点v′t作为Hj的高频访问节点,建立高频访问区域联系表HFAAT 并将v′t记录其中 (建立Γj),以HFAAT 信息产生MΓ,vj|MΓvt,vt∈Hj;以IRT 信息产生MI,vj|MIv′t,v′t∈Hj;
(5)vjvt|MΓ,vt∈Hj,vt建立HFAAT 并记录vj发来的高频访问节点;vt|MΓ;
(6)vjv′t|MI,v′t∈Γj,v′t建立IRT 并记录vj发来的Hj的索引副本表点;v′t|MI;
(7)当系统中没有消息发送和接收时,算法结束。
算法2:普通节点退出算法
(1)vt∈Hj以ID 产 生Mq,vt|Mqv′j,v′j为HFAAT 中记录的高频访问节点;
(2)vtv′j|Mq,v′j从IRT 中删除vt记录;
算法3:高频访问节点退出算法
(1)v′t∈Hj以ID 产 生MΓq,v′t|MΓqv′j,v′j为HFAAT 中记录的高频访问节点,v′t|MΓqvs,vs为IRT中记录的普通节点;
(2)v′tv′j|MΓq,v′j从IRT和HFAAT 中删除vt记录;
(3)v′tvs|MΓq,vs从HFAAT 中删除v′t记录;
算法4:节点加入算法
(1)vt|Mnvi,vi∈Nt;
(2)vtvi|Mn,vi以HFAAT 产生Mrn,vi|Mrnvt;
(3)vivt|Mrn,vt建立HFAAT 并记录vi发来的高频访问节点;
(4)vt以ID、IP、关键字、文件属性、mt和η 等信息产生Min,vt|Minv′j,v′j为HFAAT 中记录的高频访问节点;
(5)vtv′j|Min,v′j将vt的信息记录到IRT;
算法5:高频访问区域刷新算法
(1)vt∈Hj以HFAAT 产生MR,v′t|MRv′s,v′s为HFAAT 记录的高频访问节点;
(2)v′tv′s|MR,v′t更新HFAAT 并记录;
高频访问区域刷新算法可以采用定时方式执行,以保持信息一致。
算法6:资源检索算法
输出:v的资源请求Q 的查询结果(资源不存在返回(3));
(1)以v的资源请求Q 产生,利用HFAAT,vt|Mqv′j;
(2)vtv′j|Mq,v′j查询IRT,存在拥有资 源节点v′t,v′j|Mqv′t;否则,v′j利用HFAAT,v′j|Mqv′k;
(3)v′jvt|Mq,vt返回要查询的信息;
(4)v′jv′k|Mq,v′k∈Γk,v′k查询IRT,存在拥有资源节点vs,v′k|Mqvs;否则,返回 (3);
(5)v′kvs|Mq,vs返回要查询的信息。
2 仿真和结果分析
实验所用的仿真模型参考了文献[7,9-15]提出的建立网络拓扑技术,仿真程序用VB6.0开发。实验包括高频访问区域的存在性验证和算法的有效性验证。
定义6 高频访问区域出现率为核心节点的覆盖内产生高频访问区域的次数与实验次数的百分比。
2.1 高频访问区域的存在性验证
通过仿真程序产生具有1000个节点的模型网络,在每个网络中随机产生20个高度数测试节点,即度数超过网络平均节点度数的节点,以洪泛和随机漫步方法实现节点互访(为了寻找规律性TTL不加限制),检查测试节点的邻近节点的访问次数,然后计算覆盖中高频访问区域的出现率,实验结果如图1所示。可以看出,节点的覆盖中均存在高频访问节点,并构成了高频访问区域,表明覆盖的交集中高频访问区域出现率近100%,与理论分析结果吻合。
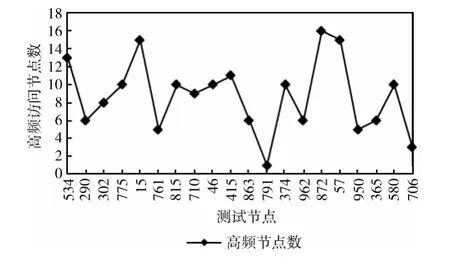
图1 高频访问区域存在性实验
2.2 算法的有效性验证
DHFA2IR 为两站式索引副本算法的改进型,实验针对两站式索引副本扩散的经典算法THIR,在相同仿真网络中对它们的平均命中率和平均查找长度进行比较。在不同规模的仿真网络中,随机选择100个节点,每个节点放置一个稀缺资源。实验分两种情况进行:①比较DHFA2IR算法使用前后平均命中率和平均查找跳数;②比较DHFA2IR 和THIR 算法的平均命中率和平均查找跳数。考虑到比较的公平性只将DHFA2IR 的索引副本扩散到网络中两跳以内。
首先,用DHFA2IR 算法将节点索引副本扩散到网络中,然后用随机漫步方法搜索稀缺资源,比较应用DHFA2IR 算法前后的命中率。由实验结果图2看出应用算法前后的效果差别明显,如网络规模为500和TTL 为50时,采用DHFA2IR 算法前后搜索成功率分别为1%和20%,平均查找跳数分别为31.2和8.4。两种算法的查找跳数与网络规模成正比,但DHFA2IR 算法平均查找跳数的增加比较平缓,说明算法性能比较稳定。
DHFA2IR 和THIR 算法的比较在规模为1000 个节点的仿真网络上进行,分别用DHFA2IR 和THIR 算法将索引副本扩散到网络中,然后用随机漫步方法搜索稀缺资源,比较DHFA2IR 算法和THIR 算法的搜索命中率和平均查找跳数。由图3可以看出在TTL 相同时,DHFA2IR 在搜索命中率优于THIR 算法,如TTL 为5时,DHFA2IR 和THIR 搜索命中率分别为0.6 和0.2。这是因为DHFA2IR充分利用了高频访问节点在数量和访问概率方面的优势,而THIR 只利用少量超级节点来扩散索引副本。随着TTL的增大,搜索深度的加大,漫游到超级节点的机率会逐步增大,THIR 搜索的成功率逐步提高。
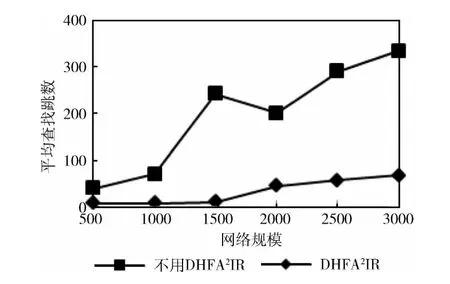
图2 搜索成功时平均查找跳数随网络规模变化情况
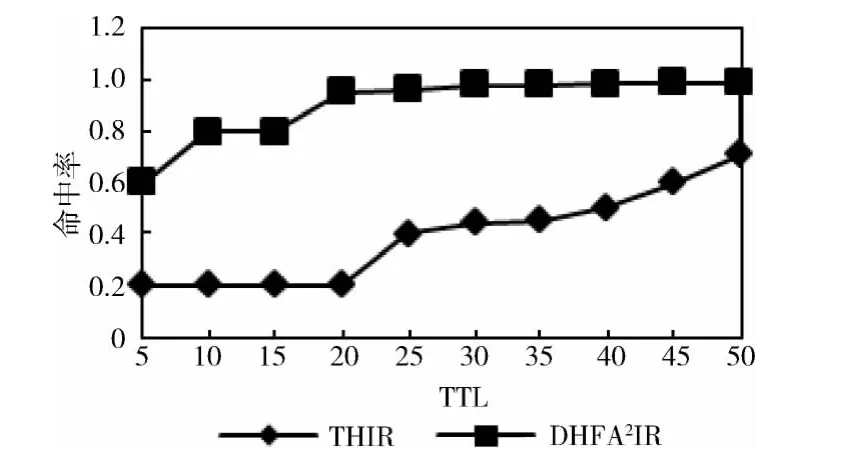
图3 搜索命中率随TTL的变化情况
3 结束语
为了提高非结构化P2P网络中稀缺资源的搜索命中率,通过对非结构化P2P网络中高频度访问节点在网络中的聚集局部性的研究,发现高频访问节点在节点覆盖区域的交集中以高概率出现,并形成高频访问区域。本文从理论和实验上证实了高频访问区域的存在,并利用高频访问在局部聚集的特性提出了控制节点索引副本在高频访问区域扩散的方法。实验表明,相比传统两站式索引副本扩散方法THIR,DHFA2IR 方法明显提高了检索命中率。算法使节点存储和网络带宽开销有一定增加,对网络性能影响不大。该方法也为网络负载的分担提供了一条思路。
今后,研究重点将放在对高频访问区域的动态迁移规律上,进一步探索提高算法稳定性的方法。
[1]Krishna P,Puttaswamy N,Alessandra Sala,et al.Searching for rare objects using index replication [C]//Phoenix,AZ:IEEE INFOCOM,2008:1723-1731.
[2]Xu Haimei,Lu Xianliang,Ge Lijia,et al,Rare resource’s sharing mechanism in unstructured P2Pnetworks[J].Journal of Electronics & Information Technology,2009,31 (8):2029-2032.
[3]LI Zhijun,JIANG Shouxu,LI Xiaoyi.Exploiting multi-level locality to implement the scalable search in unstructured P2P network [J].Journal of Software,2011,22 (9):2104-2120.
[4]Sharifkhani F,Pakravan MR.A new metric for comparison of P2Psearch algorithms[C]//Seventh International Conference on P2P,Parallel,Grid,Cloud and Internet Computing,2012:191-195.
[5]Cheng Lan,Gou Jin,Zhou Feng.Peer to peer network search algorithm based on apperceiving location and preferential attachment[J].Journal of Chinese Computer Systems,2012,33(6):1256-1261.
[6]Zhang Yuxiang,Zhang Hongke.A load balancing method in superlayer of hierarchical DHT-based P2Pnetwork [J].Chinese Journal of Computers,2010,33 (9)1580-1590.
[7]Li Zhen,Duan Hancong,Nie Xiaowen,et al.Routing optimization on the layered peer-to-peer management network [J].Journal of Chinese Computer Systems,2012,31 (1):54-57.
[8]Li Pua,Chen Shiping,Li Jianfen.Cloud resources locating algorithm based on peer-to-peer network [J].Application Research of Computers,2013,30 (2):570-573.
[9]Tang Daquan,He Mingke,Meng Qingsong.Research on searching in unstructured P2Pnetwork based on power-law distribution and small world character [J].Journal of Computer Research and Development,2007,44 (9):1566-1571.
[10]Yao Quanzhu,Li Wei,Kong Wei.Research on communication protocol of unstructured P2Poverlay network [J].Computer Engineering and Applications,2011,47 (7):99-102.
[11]Sarshar N,Roychowdhury V P.Multiple power-law structures in heterogeneous complex networks[J].Physics Review E,2005,72 (2):1-11.
[12]Ma Wenming,Meng Xiangwu,Zhang Yujie,et al.Bidirectional random walk search mechanism for unstructured P2P network [J].Journal of Software,2012,23 (4):894-911.
[13]REN Liyong,LEI Ming,ZHANG Lei.Data traffic optimization in P2Papplication layer [J].Journal of University of Electronic Science and Technology of China,2011,40 (1):111-115.
[14]Hoong P K,Matsuo H.Push-pull two-layer super-peer based P2Plive media streaming [J].Journal of Applied Sciences,2008,8 (4):585-593.
[15]Qian Ning,Wu Guoxin,Zhao Shenghui.A Bayesian network-based search method in unstructured peer-to-peer networks[J].Journal of Computer Research and Development,2009,46 (6):889-897.
[16]Zhou Xiaobo,Zhou Jian,Lu Haneheng.A layered interest based topology organizing model for unstructured P2P [J].Journal of Software,2007,18 (12):3131-3138.
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
体育科技文献通报(2022年5期)2022-06-05
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
中国生殖健康(2019年11期)2019-01-07
长江丛刊(2018年31期)2018-12-05
NBA特刊(2017年8期)2017-06-05
中国卫生(2015年12期)2015-11-10
