
一种可实现零内存存取的CAVLC解码算法
2014-06-02 06:43:08黄明政韩一石
计算机工程 2014年3期
黄明政,韩一石
一种可实现零内存存取的CAVLC解码算法
黄明政,韩一石
(广东工业大学信息工程学院,广州 510006)
在基于上下文的自适应可变长度编码(CAVLC)解码算法中,对非结构化自适应可变长度编码码表进行解码时需要反复查找码表进行码字匹配,从而导致解码速度慢和需要大量内存存取的问题。为此,提出一种可实现零内存存取的CAVLC解码算法。将CAVLC码字前缀0的个数作为一级索引,同时通过一级索引获得输入码流的可能长度。将码字后缀作为二级索引并获得码字的值,直接通过码字快速获得解码结果。对于确定的输入码字,只需通过无码表查找代码操作即可得到对应的解码输出。测试结果表明,该算法不仅可以实现零内存存取的CAVLC解码,而且其解码速度比标准算法提高了45%。
基于上下文的自适应可变长度编码;零内存存取;码字前缀;一级索引;码字后缀;二级索引
1 概述
H.264/AVC是最新的国际性的视频编解码标准,它通过ITU-T(电信联盟)和ISO/IEC(标准联盟)进行制定[1]。H.264/AVC标准包括基本档次、高级档次和主要档次3种。其中,H.264/AVC基本档次只包括基于上下文的自适应可变长度编码(ContextAdaptive Variable Length Coding, CAVLC)技术,这个技术被用来对视频图像的块残差数据进行编码。它适用于移动设备环境,这些环境都具有低复杂度、低功耗要求等特点。在H.264/AVC CAVLC编码中,在对视频图像的块残差数据量化并进行之字形扫描后,利用Coeff_token、(1)、、和这5个语法元素对视频图像的块残差数据进行编码压缩。其中,语法元素代表非零系数个数()和拖尾系数个数()(1);1代表拖尾系数符号;代表除了拖尾系数外的非零系数幅值;代表最后一个非零系数之前0的个数;代表每个非零系数前的0个数。在CAVLC解码算法中,只有和1这2个语法元素通过规则的算术运算进行解码,其中算术运算的解码过程不需要查找任何的码表,所以它不需要进行存储码表的内存存取,则这2个语法元素的解码码表内存存取次数为0。其余的3个语法元素,如、和,都是通过可变长度的编码码表(VLCTs)进行解码,在此过程中,需要不断地查找码表进行相应的解码码流的匹配;如果码字跟解码的码流不匹配,需要重新查找;因此,在一次解码的过程中,需要多次地查找匹配码表操作才能完成一个码字的解码;以此类推在这3个语法元素的解码过程中,一个视频图像码流需要反复查找匹配存储在内存中的不规则码表,因此,这需要消耗大量的内存存取直到所期望的码字被匹配。在嵌入式系统特别是在多媒体应用场合中,内存存取次数是系统性能和功耗的瓶颈[2]。
为了能够减少内存存取次数,许多优化的CAVLC解码算法已经被提出。在硬件设计方案中,文献[3]将所有的码表融合成一个码表,同时将码表构建成多个子表来减少40%的功耗。文献[4]提出流水线架构来大幅度降低系统操作频率,从而进一步减少功耗。在软件设计方案中,传统的码表查找算法,如顺序查找码表算法(TLSS)和二叉树查找码表算法(TLBS)被用来进行CAVLC解码。然而,由于TLSS要进行完整地码表查找匹配而得到所需要的解码码字,因此它需要在每一个解码码字上进行码表的内存存取。由于TLBS对于码表的内存存取的随机性,因此它在某些系统中表现得并不是很高效。在一些新的方案中,由于整数算术运算可以直接进行码字的解码而不需要码表查找操作的特性,因而,整数算术运算被引入CAVLC解码算法中来减少码表的内存存取次数。在Moon的方案中,用于和语法元素的新码表被提出来,它通过利用整数算数运算来减少约65%~88%的内存存取次数[5]。在Kim方案中,其他一些整数算数运算被提出来,它可以减少大约94%的内存存取次数[6]。然而,在Moon方案中,少量内存取次数是必须的,因为部分语法元素还使用TLBS来进行解码。
为消除CAVLC码表的内存访问次数,进一步提高解码速度,本文提出一种可实现零内存存取的CAVLC解码算法,设计能够表达非结构化可变长度编码码表的代码,同时利用该算法,不通过任何码表查找获得解码的码字。
2 CAVLC的解码原理
在H.264/AVC基本档次中,CAVLC和Exp-Golomb码字被用来作为熵编码的方法。指示信息通过Exp-Golomb码来进行编码,其中这些码字都具有规则性结构。那些残差块数据的量化变换系数通过CAVLC码来进行编码[7]。在CAVLC中,那些量化的系数被之字形扫描,然后被5个语法元素进行编码:,(1),,,。
在CAVLC解码器中,一个4×4块残差数据的之字扫描值通过压缩的比特流来进行重建。图1为CAVLC解码过程的一个例子,它可以在H.264/AVC标准中找到[8]。该图显示了在H.264/AVC基本档次中的CAVLC解码原理。其中,Zero_left指示了剩余的0系数的个数。1和语法元素一般都通过整数算术运算进行解码,因为它们都是通过规则的可变长度编码码字(VLC)进行编码的。语法元素、和通过可变长度编码码表进行解码,因为他们都是通过码表查找来执行的。在解码的过程中,需要大量的内存存取来找到所需码字。
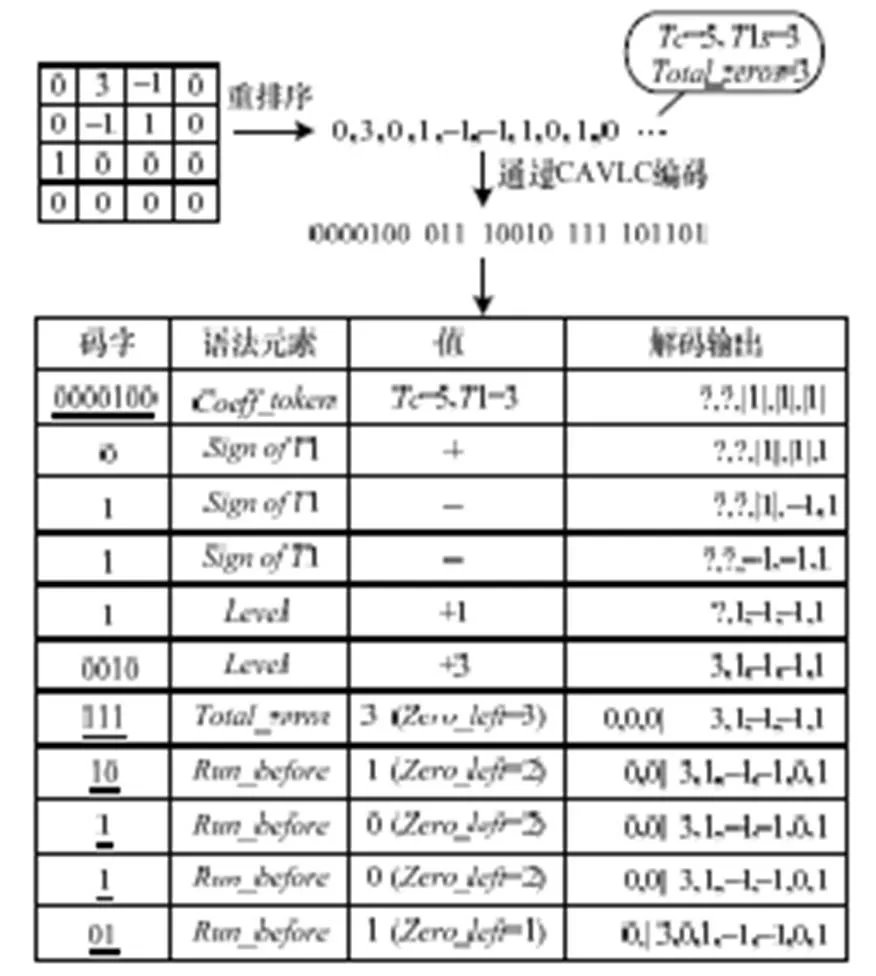
图1 CAVLC解码示例
3 本文算法
在H.264/AVC CAVLC解码中,那些利用可变长度编码码表进行解码的语法元素必须得到处理才能减少内存存取次数以进一步降低功耗。在这些语法元素中,语法元素是二维码表,然而和这2个语法元素的码表是一维码表。通过分析可变长度编码码表的码字相关性,本文提出了一种直接的CAVLC解码方案[9],具体步骤如下:
(1)将输入码流的最开始连续0的个数作为一级索引,同时通过一级索引获得输入码流的可能长度。
(2)确定所提出的码表中的二级索引并获得码字的值。
(3)通过码字快速地获得解码结果。
基于这种原则,二维码表和一维码表被分别设计如表1和表2所示。
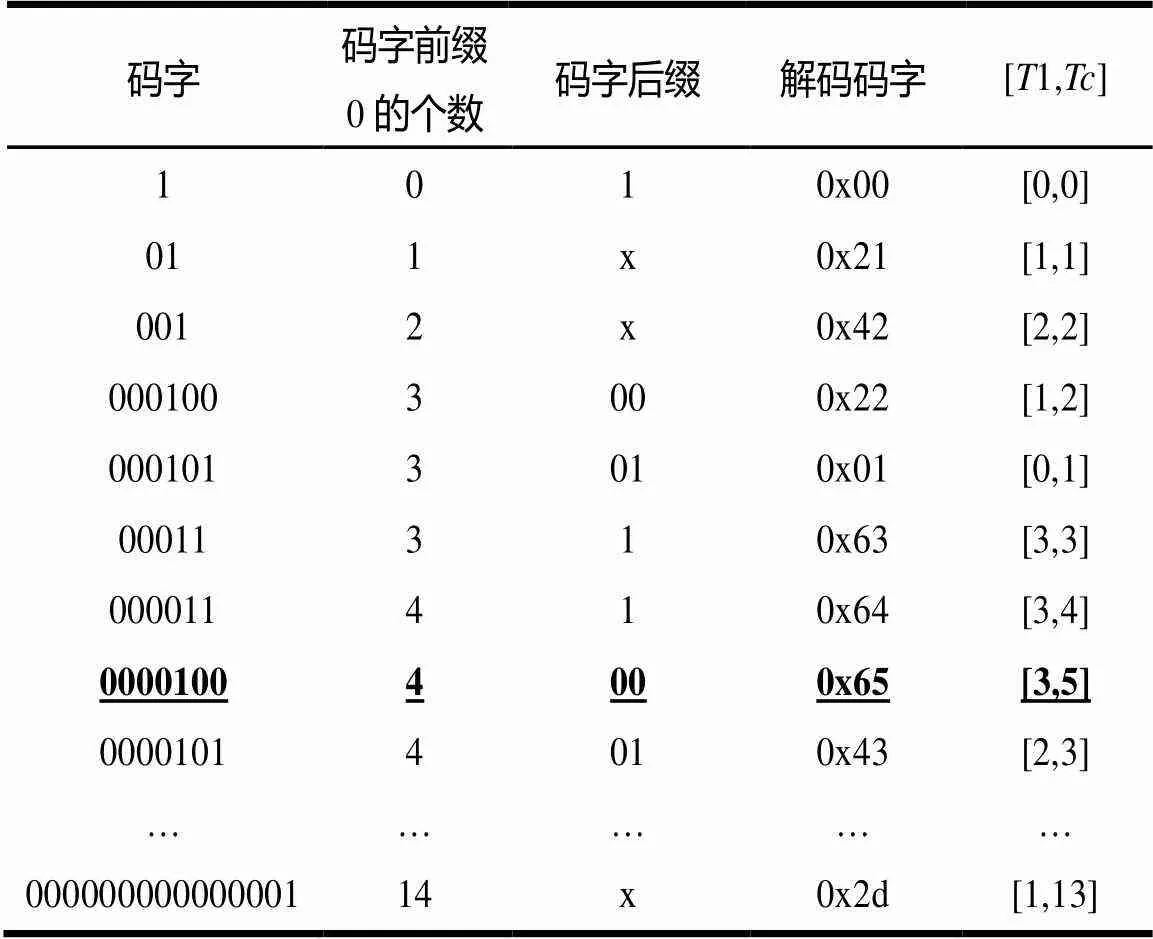
表1 Coeff_token(VLCT0, 0≤NC<2)语法元素的部分二维码表
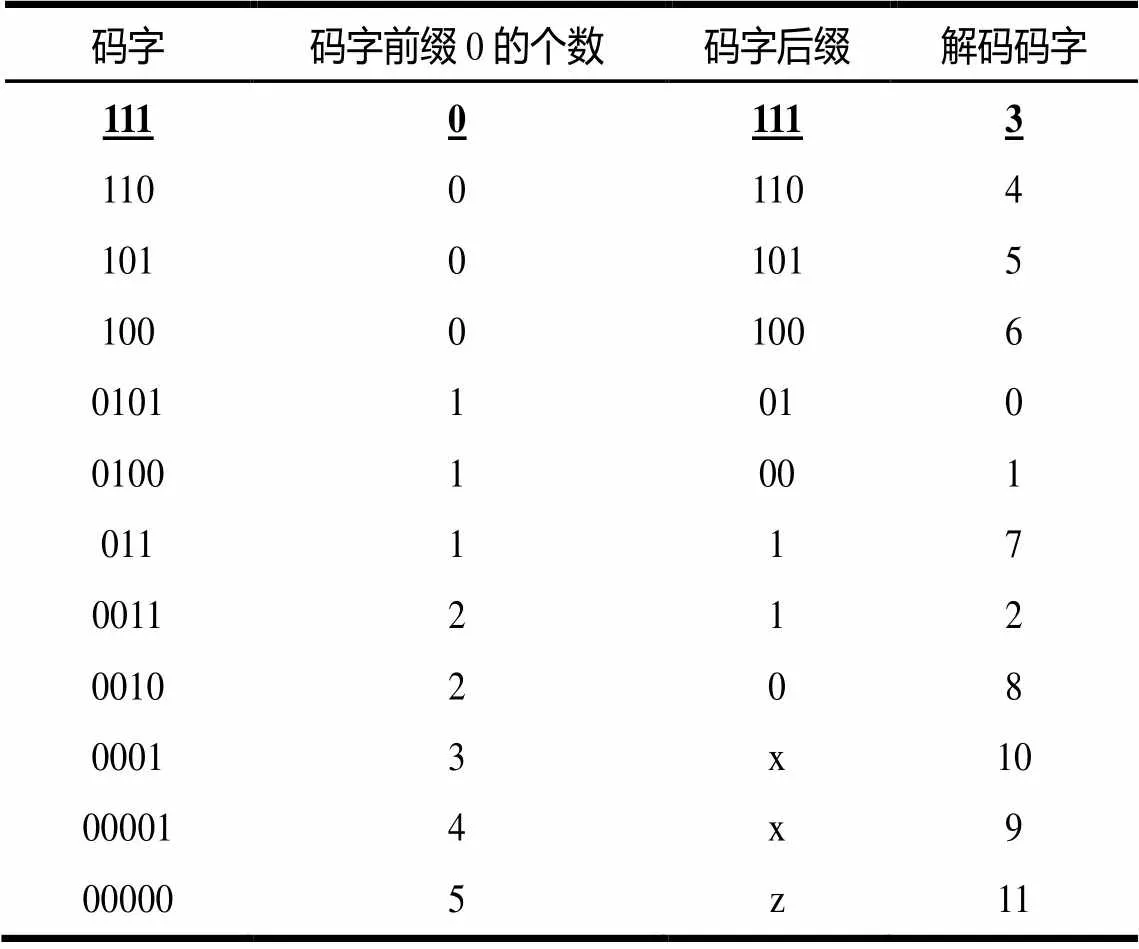
表2 Total_zeros(Tc=5)语法元素的部分一维码表
在表1中,码字(Code)表示对应语法元素的输入比特流;8位的解码码字(Codeword)表示解码输出结果;其中前3位表示拖尾系数(1)的个数,后5位表示非零系数的个数();码字前缀0的个数表示码字的第1个非零系数之前部分的连续0个数;码字后缀(Code Suffix)表示第1个非零系数之后的部分。在表2中,解码码字直接表示单一的解码输出结果;其他元素表示与表1相同的意思。表3和表4分别表示码字长度与表1、表2中所提到的码字前缀0的个数之间的关系。
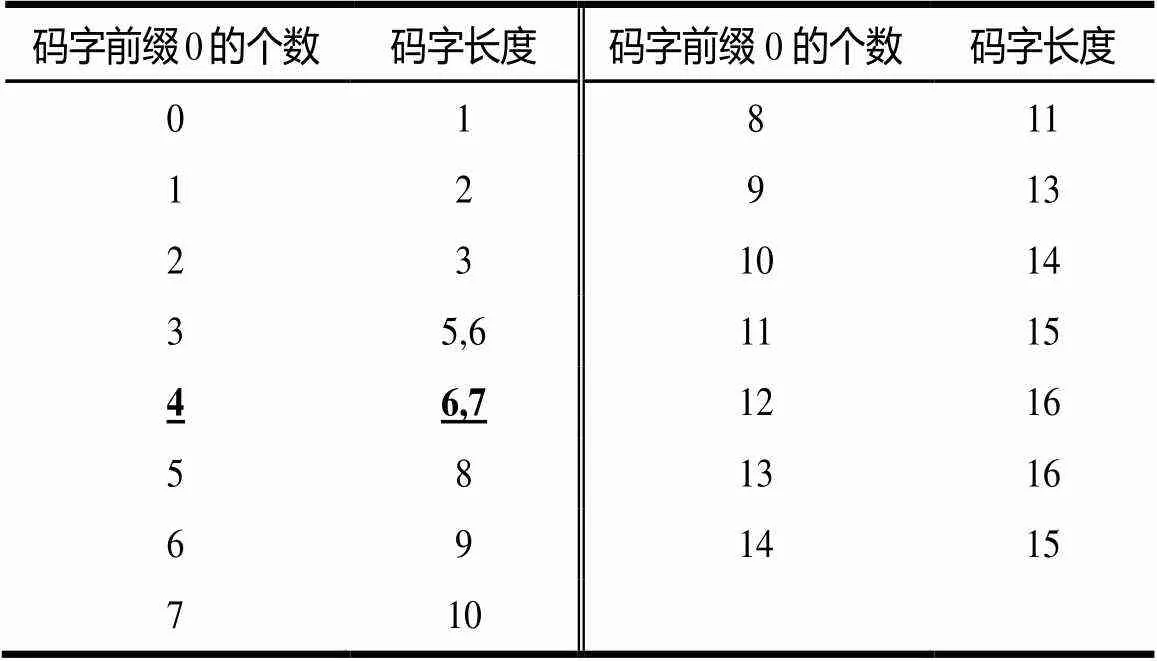
表3 表1中码字前缀0的个数和码字长度之间的关系

表4 表2中码字前缀0个数和码字长度之间的关系
本文所提出的解码算法由以下步骤组成:
Step1 选择语法元素的可变长编码码表的入口。语法元素有3个可变长度编码码表和1个固定长度编码的码表,分别为(VLCT0, 0≤<2)、(VLCT1, 2≤<4)、(VLCT2, 4≤<8)、(FCLT,=–1)[10]。
Step2 读取码字前缀0的个数值,并将其值作为一级索引。
Step3 通过一级索引获取码字的长度。其中,语法元素的码字长度和一级索引之间的关系如表3所示。设定一个参数RL作为二级索引,其中,=码字长度–码字前缀的长度。
Step4 读取在输入码流中的可能码字后缀,并将它假设为,其中,的长度是根据来确定的。将的值跟CAVLC算法中的标准码字后缀进行比较,可以获得如表1中的解码码字。
其他2种语法元素和也通过同样的步骤进行解码,只不过利用码表表2和表4来代替表1和表3。语法元素和1可以通过规则的整数算术运算进行直接解码。
图2展示了一个选择VLCT0入口开始而实现CAVLC的5个语法元素解码例子。对于语法元素,一级索引和二级索引可以逐步获得,则和1的结果可根据一级索引直接得到。

图2 本文算法的解码原理
图2中语法元素的输入码流(0000100),其一级索引为4。如表3所示,可以直接获取码字长度为6或7,这样就可以得到二级索引为1或2。如表1所示,在VLCT0中的码字后缀可能为(1),(00)或(01)。对于输入码流(0000100),值与它的码字后缀相等。笔者转换值,并与标准的码字相比较,可以得到解码码字为(0X65)。这个解码的码字可被解码为1=2,=5。根据、、1、和元素即可得到解码输出。在表1~表4中,加下划线的数字表示这个例子中所用到的相应参数。
4 仿真结果
本文计算4种算法的CAVLC解码码表内存存取次数节省数据,包括二叉树查找码表算法(TLBS)、Moon算法,Kim算法和本文算法。针对不同QP值的测试序列,与标准按顺序查找码表算法(TLSS)相比,上述4种算法内存存取次数的减少比例如图3所示。其中,TLSS算法数值利用JM16.2[11]得到,仿真环境为Windows XP操作系统,CPU为Intel 2.00 GHz,内存大小为1 GB。

图3 不同序列的码表内存存取次数节省比例
由图3可以看出,本文提出的算法完全消除解码过程中的码表内存存取次数,并且本文算法节省比例比其他各种算法都高。由于本文算法可以在代码中完全表达解码过程中非结构化的可变长度编码码表,从而完全省略对码表的查找,继而完全省略码表的内存存取。此外还可以看出,Kim算法比TLBS算法和Moon算法的内存存取次数节省比例更高一点。可以看出,TLBS算法在图像高QP值处的内存存取次数会少一点,而Moon算法在图像低QP值处的内存存取次数会少一点。相似结论也可在文献[6]中找到。
解码时间通过Window系统的API接口函数Query PerformanceCounter()进行计算,算法的时间节省比例根据下式计算:(1–本文算法/标准算法)×100%。图4显示了用不同QP值的各种序列进行测试时,各种算法的解码时间节省比例。

图4 120帧图像序列的时间节省比例结果
表5是图4的解码时间数据。其中,Forman、Crew和Paris序列是CIF格式的,而Harbour、Soccer和Mobile序列是QCIF格式的。可以看出,本文算法比其他各种算法具有优越性。与TLSS标准算法相比,本文算法表现出45%的时间节省比例,这是因为该算法不需要进行码表查找从而可以快速定位解码码字。由于Moon算法和Kim算法利用了部分整数算术运算操作,这2种算法相对于TLSS算法也表现出了一定的高效性。而由于TLBS算法的二叉树随机内存存取性质,因此,该算法表现得并不高效。

表5 系统的CAVLC解码次数
5 结束语
H.264标准的CAVLC查表解码算法在匹配解码码字时,需要反复查找码表,会导致解码速度慢和需要消耗大量内存存取的问题,为此,本文提出一种可实现零内存存取的直接CAVLC解码算法。该算法根据CAVLC算法的语法元素、、中前缀0的个数与码字长度之间的对应关系,利用二级索引思想来提出能够表达CAVLC中的非结构化码表,同时利用二级索引技术设计能够表达非结构化码表解码的代码,实现CAVLC的无码表查找的直接解码。仿真结果表明,相比于标准的TLSS算法,本文算法可以实现零内存存取的CAVLC解码。同时,本文算法比标准TLSS算法快45%,优于目前常见CAVLC解码算法。这些内存存取次数的节省不仅适用于高比特率的场合,也适用于低比特率的场合。本文算法尤其适用于对功耗要求严格的嵌入式平台编解码环境[12]。下一步工作是设计无码表查找同数字算术运算相结合的解码算法,或纯数字算术运算的解码算法,以实现CAVLC解码速度、内存存取次数的消除和内存存储空间的最佳平衡。
[1] ITU. Advanced Video Coding for Generic Audio Visual Services[EB/OL]. (2011-11-01). http://citeseerx.ist.psu.edu/ showciting?cid=323674.
[2] Lee J, Park C, Ha S. Memory Access Pattern Analysis and Stream Cache Design for Multimedia Applications[C]//Proc. of DAC’03. Anaheim, USA: [s. n.], 2003: 21-24.
[3] Lin Hengyao, Lu Yinghong, Liu Binda, et al. A Highly Efficient
VLSI Architecture for H.264/AVC CAVLC Decoder[J]. IEEE Transactions on Multimedia, 2008, 10(1): 31-42.
[4] Lee B, Ryoo K. A Design of High-performance Pipelined Architecture for H.264/AVC CAVLC Decoder and Low-power Implementation[J]. IEEE Transactions on Consumer Electronics, 2010, 56(4): 2781-2789.
[5] Moon Y H, Kim G Y, Kim J H. An Efficient Decoding of CAVLC in H.264/AVC Video Coding Standard[J]. IEEE Transactions on Consumer Electronics, 2005, 51(3): 933-938.
[6] Kim Y, Yoo Y, Shin J, et al. Memory-efficient H.264/AVC CAVLC for Fast Decoding[J]. IEEE Transactions on Consumer Electronics, 2006, 52(3): 943-952.
[7] 薛 全, 张 颖, 刘济林, 等. 基于变步长分组的H.264系数码表优化[J]. 电路与系统学报, 2006, 11(3): 115-117.
[8] Sullivan G, Bjontegaard G. Recommended Simulation Common Conditions for H.26L Coding Efficiency Experiments on Low-resolution Progressive-scan Source Material[EB/OL]. (2001-09-28). http://65.54.113.26/Publica tion/4142353/.
[9] 张秀丽, 万 忠, 鲍程红. 基于码头分组的CAVLC解码算法优化[J]. 电路与系统学报, 2007, 14(3): 26-30.
[10] 毕厚杰. 新一代视频压缩编码标准——H.264/AVC[M]. 北京: 人民邮电出版社, 2005.
[11] Suhring K. JM16.2 Software[EB/OL]. (2011-11-10). http:// iphome.hhi.de/suehring/tml/.
[12] 龚建锋, 金文光, 季爱明. 基于H.264解码中CAVLC的优化[J]. 微电子学与计算机, 2007, 24(1): 85-87.
编辑 金胡考
A CAVLC Decoding Algorithm with Zero Memory Access
HUANG Ming-zheng, HAN Yi-shi
(School of Information Engineering, Guangdong University of Technology, Guangzhou 510006, China)
This paper proposes a zero memory access algorithm for direct Context-based Adaptive Variable Length Coding(CAVLC) decoding, aiming to solve the problems of slow decoding speed and a large of memory accesses caused by the repeated table look-up for the match codeword during the unstructured variable length coding table decoding. This algorithm takes the numbers of zero in CAVLC code prefix as the primary index, and gets the probably length of the input code stream. It takes the code suffix as the secondary index and gets the codeword value. It can get the decoded result by the codeword quickly. For the specific input code, the decoded output can be directly gotten without any table look-up. Test results show that not only the algorithm can achieve zero memory access for CAVLC decoding, but also the decoding speed of this algorithm can achieve 45% speed-up, compared with the standard algorithm.
ContextAdaptive Variable Length Coding(CAVLC); zero memory access; code prefix; primary index; code suffix; secondary index
1000-3428(2014)03-0278-05
A
TP919.81
广东省科技计划基金资助项目(2011B090400344, 2011B010200029)
黄明政(1989-),男,硕士研究生,主研方向:视频通信,视频编/解码;韩一石,副教授
2013-03-22
2013-04-23 E-mail:634099571@qq.com
10.3969/j.issn.1000-3428.2014.03.059
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
扬子江诗刊(2018年1期)2018-11-13 12:23:04
中国自行车(2018年9期)2018-10-13 06:17:04
舰船电子对抗(2018年3期)2018-08-28 02:02:56
扬子江(2018年1期)2018-01-26 02:04:06
优雅(2017年8期)2017-08-08 06:01:53
中国自行车(2017年1期)2017-04-16 02:54:07
