
基于视觉显著性和提升框架的场景文字背景抑制方法
2014-05-29 09:47卢朝阳刘晓佩
电子与信息学报 2014年3期
姜 维 卢朝阳 李 静 刘晓佩 姚 超
基于视觉显著性和提升框架的场景文字背景抑制方法
姜 维*卢朝阳 李 静 刘晓佩 姚 超
(西安电子科技大学综合业务网国家重点实验室 西安 710071)
为解决复杂背景对场景文字自动定位算法干扰的问题,该文利用视觉显著性抑制背景且突出前景的特点,以方向梯度直方图特征、方向梯度直方图统计特征、梯度幅度特征和梯度曲线特征的弱分类器,结合提升框架提出一种背景抑制算法。该文算法的目标是抑制自然图像中复杂背景且突出前景文字,作为场景文字自动定位算法的预处理阶段增强算法效果。在ICDAR2011场景文字定位竞赛数据库和实验室场景中文数据库中实验结果表明,该文算法较好地抑制自然场景中复杂背景,并有效提升场景文字自动定位算法的性能。
图像处理;场景文字;背景抑制;视觉显著性;提升方法
1 引言
视觉显著性分析是人类特有的能力,可帮助人类快速准确检测识别目标。但是计算机在该方面仍无法与人类媲美,所以视觉显著性一直都是计算机视觉领域中的热点问题并在近年受到更广泛的关注[1]。
场景图像中的文字自动定位是计算机视觉领域中一个重要但未被较好解决的问题,主流算法性能远不及人类。文字的位置、大小与字体的不确定性,光照强度的变化性与背景的复杂性均是影响场景文字自动定位算法性能的重要因素,而背景的复杂性是造成算法效果不佳的首要原因。抑制场景图像背景,突出前景文字并提高文字定位算法性能是本文的研究目标。
场景文字自动定位算法通常分为两类:基于区域的方法和基于连通域的方法。基于区域的方法[2,3]认为文字区具有明显不同于背景区的纹理结构特性,首先将场景图像分割为块状区域,然后提取特征使用分类器去除背景区,最后按照某些原则聚合文字区;基于连通域的方法[4,5]假定因为某种特性文字区是独立与周围可分离的连通域,首先按照颜色,笔画宽度或边缘等特性作连通域分析获取文字候选区,再根据特征剔除背景区域,最后将文字区聚合成文本行。
基于区域的方法和基于连通域的方法各具优劣,但二者均会因为复杂背景的干扰影响定位算法性能。解决该问题的方法之一是在场景文字定位自动算法中增加预处理步骤,抑制自然图像的背景区域并突出前景文字。目前仅有文献[6]针对场景文字提出背景抑制算法,该算法使用图模型结合颜色、边缘和纹理信息达到场景文字背景抑制效果。
综上,场景图像的复杂背景是影响定位算法性能的重要因素,而视觉显著性的重要特点是抑制背景区域,突出显著目标。基于此,本文尝试模仿人类视觉的处理过程设计算法。人类视觉处理过程分为两步[7]:首先是快速简单的并行预注意过程,此过程快速忽略背景,获得显著目标;然后是一个较慢的复杂的串行注意过程,该步骤有目的地去除无效目标,突出感兴趣目标。人类认知场景文字的过程也符合以上步骤,本文据此设计的算法如图1所示。(1)根据谱残差理论获取输入图像的显著性图,将满足阈值条件的区域输入到下一阶段;(2)根据上一步骤的输入区域,利用方向梯度直方图特征、方向梯度直方图统计特征、梯度幅度特征和梯度曲线特征组成的级联分类器做6个尺度的文字区域检测,最终根据校正的提升分类器输出文字置信图;(3)显著性图与文字置信图进行几何平均,最终达到场景文字背景抑制效果。步骤(1)属于快速简单的并行的无意识的预注意过程,步骤(2)和步骤(3)属于较慢的复杂的串行注意过程。
本文创新点在于提出基于视觉显著性与提升框架的场景文字背景抑制方法,并设计梯度曲线特征与方向梯度直方图统计特征。
2 谱残差视觉显著性算法
2.1 谱残差视觉显著性分析
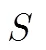

图1 算法流程图

自然场景的文字多为标语、广告和指示牌等,普遍显著而突出。文献[8]表明,人类对人脸与文字的快速准确定位能力,至少部分依赖于图像傅里叶幅度谱中的信息,而谱残差视觉显著性算法正是基于图像傅里叶幅度谱。因此,本文采用此显著性算法针对场景文字进行背景抑制,是可行且有依据的。
图2是利用谱残差视觉显著性分析得到的场景文字显著性图,其中场景图像分别来自ICDAR2011场景文字定位竞赛数据库和实验室场景中文数据库。图2(a)为原图,图2(b)是原图对应的谱残差显著性图,图像亮度代表显著性程度。图2中,谱残差视觉显著性算法成功抑制了背景区域,有效突出了包含文字在内的显著区域,但同时保留了其它显著元素,本文后续的文字区域检测阶段可有效抑制这部分干扰元素。
2.2 显著性区域筛选
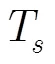

图2 谱残差视觉显著性分析样图
3 文字区域检测
文字区域检测算法使用提升框架将方向梯度直方图特征、方向梯度直方图统计特征、梯度幅度特征和梯度曲线特征的弱分类器组成级联分类器,以16×16的滑动窗口,4×4步长分6个尺度遍历之前筛选的显著性区域,最终通过分类器的校正获得文字置信图。
3.1 文字区域检测的特征
方向梯度直方图特征(Histogram of Oriented Gradients, HOG)最早被应用于行人检测[9],现已广泛应用于计算机视觉领域中各问题。本文同时采用文献[9]的R-HOG特征与文献[3]相似的T- HOG特征。
文字笔画通常是具有同一颜色或相同背景的双边区域,且笔画两侧梯度方向相反,幅度值近似相等;在具有完整文字的区域中,梯度幅值在各方向上差别不大。文献[3]验证了该假设,本文据此设计了方向梯度直方图的统计特征。
观察可发现,文字顶部与底部区域多聚集水平笔画,中间区域的竖直笔画更集中(水平笔画是方向梯度,竖直笔画为方向梯度)。图3很好地体现如上观察结果,图3(b),图3(c),中曲线是先按照图4(a)划分滑动窗口区域为8×1(等分为8行1列),然后对8块区域分别求方向梯度幅度和方向梯度幅度均值,最后分别描绘曲线得到的。正如观察所发现:方向梯度幅度值在滑动窗口顶部与底部较小,中部达到峰值;方向梯度幅度值在滑动窗口顶部和底部较大,中部最小;另外,文字一定程度的倾斜不影响该结论。根据以上分析,本文算法采用梯度幅度特征并设计梯度曲线特征。

图3 梯度曲线样例图

3.1.2方向梯度直方图统计特征 基于之前的观察结果,本文采用式(2)和式(3)表示方向梯度直方图统计特征。该特征针对的是整个滑动窗口,不再是窗口局部区域。

图4 滑动窗口区域的划分
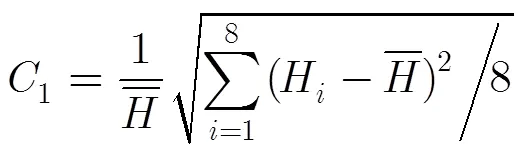

3.1.3梯度幅度特征 梯度幅度特征按照图4(a)将滑动窗口划分为8个区域,对每个区域求幅度均值,得到8个特征;同时按照1-2, 3-6, 7-8方式组合区域求幅度均值,得到3个特征。因为梯度幅度特征分为方向梯度幅度特征和方向梯度幅度特征,所以共有22((8+3)×2)个特征。
3.1.4梯度曲线特征 梯度幅度特征描述的是8×1区域中单个区域的方向梯度幅度或方向梯度幅度,梯度曲线特征将8个区域的梯度幅度作为整体考虑,即把8个区域梯度幅度作为8维向量。因为梯度幅度有两个方向,所以共计产生2(1×2)个8维特征。
3.2 弱分类器和联合特征


3.2.2联合特征 本文算法共使用 45(19+2+22+2)个简单特征。45个简单特征两两组合生成990个联合特征,得到包含1035(45+990)个特征的特征池,最终通过提升方法选择特征组成提升级联分类器。
3.3 校正级联提升分类器与文字置信图
校正级联分类器由5级组成,第1级为简单特征分类器,后4级为联合特征分类器。每一级弱分类器数目分别为26, 49, 64, 75与75。
提升方法具有良好的泛化能力,但无法进行类别准确概率估计。算法根据文献[11]进行校正,得到准确的后验概率。通过校正级联分类器可得到图像6个尺度的文字置信图,将其归一化到原始尺度做均值得到最终的文字置信图如图5(c)所示。图5(b), 5(c), 5(d)分别是本文算法3个阶段的效果图。
4 实验与分析
4.1 级联分类器的训练
级联分类器的训练数据来自ICDAR2011场景文字定位竞赛数据库中的229幅训练图像和实验室场景中文数据库随机抽取的250幅图像。训练时以16×16的滑动窗口遍历训练图像的文字区域提取25929个正样本数据,相同方法遍历训练图像的背景区域提取300000个负样本数据。
4.2 显著性阈值的确定
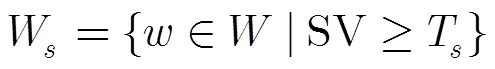
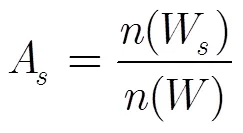
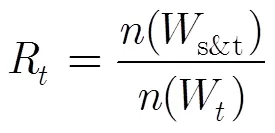

图5 算法各阶段效果图
4.3 评价标准




4.4 实验结果与分析
本文实验图像来自ICDAR2011场景文字定位竞赛数据库和实验室场景中文数据库。ICDAR2011场景文字定位竞赛数据库是目前英语文字定位算法的主要测试数据库,包含255幅自然场景下英文环境测试图像;实验室场景中文数据库是本实验室建立的自然场景下中文环境图像数据库,拥有5000幅场景汉字图像。



表1 ICDAR2011场景文字定位竞赛数据库中算法性能比较(%)
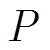
图6中是4种场景文字背景抑制算法效果的比较,图6(a)是原图,图6(b), 6(c), 6(d)分别是文献[12],文献[13],文献[6]的算法效果图,图6(e)是本文算法效果图。因为前3种算法是基于边缘的,所以本文也将背景抑制结果二值化后与边缘图结合后再进行比较。如前文分析本文算法结果中含有更少的背景像素(像素级别准确率高),文字区域更完整(区域级别召回率高),会出现微小的背景区域(区域级别准确率略低),但较容易在后续步骤去除。

图6 场景文字背景抑制算法比较效果图
5 结束语
本文利用谱残差视觉显著性方法,结合提升框架基于方向梯度直方图特征,方向梯度直方图统计特征、梯度幅度特征和梯度曲线特征提出一种针对场景文字的背景抑制算法。实验证明,本文算法适用于自然场景下英文环境和中文环境的背景抑制,可有效提高场景文字自动定位算法的准确率,改善综合性能。
本文算法针对场景文字进行背景抑制取得较为显著效果,在未来工作中将继续完善该算法,将其扩展为完整的基于视觉显著性的场景文字自动定位系统。
[1] Qi Zhao and Koch C. Learning saliency-based visual attention: a review[J].,2013, 93(6): 1401-1407.
[2] Lee J J, Lee P H, Lee S W,.. AdaBoost for text detection innatural scene[C]. International Conference on Document Analysis and Recognition, Beijing, 2011: 229-434.
[3] Minetto R, Thomeb N, Cord M,.. T-HOG: an effective gradient-based descriptor for single line text regions[J]., 2013, 46(3): 1078-1090.
[4] 刘晓佩, 卢朝阳, 李静. 结合WTLBP特征和SVM的复杂场景文本定位方法[J]. 西安电子科技大学学报, 2012, 39(4): 103-108.
Liu X P, Lu Z Y, and Li J. Complex scene text location method based on WTLBP and SVM[J]., 2012, 39(4): 103-108.
[5] 姜维, 卢朝阳, 李静, 等. 基于角点类别特征和边缘幅值方向梯度直方图统计特征的复杂场景文字定位算法[J]. 吉林大学学报(工学版), 2013, 43(1): 250-255.
Jiang W, Lu Z Y, Li Jing,.. Text localization algorithm in complex scene based on corner-type feature and histogram of oriented gradients of edge magnitude statistical feature[J].(), 2013, 43(1): 250-255.
[6] Shi C Z, Xiao B H, Wang C H,.. Graph-based background suppression for scene text detection[C]. International IAPR Workshop on Document Analysis Systems, Queensland, 2012: 210-214.
[7] Hou X D and Zhang L Q. Saliency detection: a spectral residual approach[C]. IEEE Conference on Computer Vision and Pattern Recognition,Minneapolis, 2007: 1-8.
[8] Honey C, Kirchner H, and Van Rullen R. Faces in the cloud: Fourier power spectrum biases ultrarapid face detection[J]., 2008, 8(12): 1-13.
[9] Dalal N and Triggs B. Histograms of oriented gradients forhuman detection[C]. IEEE Computer SocietyConference onComputer Vision and Pattern Recognition, San Diego, 2005: 886-893.
[10] Hanif S M and Prevost L. Text detection and localization in complex scene images using constrained adaBoost algorithm[C]. International Conference on Document Analysis and Recognition, Barcelona, 2009: 1-5.
[11] Niculescu-Mizil A and Caruana R. Predicting good probabilities with supervised learning[C]. Proceedings of International Conference on Machine Learning, Bonn, 2005: 625-632.
[12] Lyu M R, Song J Q, and Cai M. A comprehensive method for multilingual video text detection, localization, and extraction[J]., 2005, 15(2): 243-255.
[13] Liu C M, Wang C H, and Dai R W. Text detection in images based on unsupervised classification of edge-based features[C]. International Conference on Document Analysis and Recognition,Seoul, 2005: 610-614.
[14] Shahab A, Shafait F, and Dengel A. ICDAR 2011 robust reading competition challenge 2: reading text in scene images[C]. International Conference on Document Analysis and Recognition, Beijing, 2011: 1491-1496.
姜 维: 男,1981年生,博士生,研究方向为自然环境文字分析与识别.
卢朝阳: 男,1963年生,教授,博士生导师,研究方向为图像分析与图像理解、图像与视频编码,基于指纹、虹膜及人脸的生物特征识别,基于图像分析的智能交通系统应用和自然环境文字分析与识别.
李 静: 女,1979年生,副教授,硕士生导师,研究方向为图像处理与模式识别、图像配准、文字识别、增强现实.
Visual Saliency and Boosting Based Background Suppression for Scene Text
Jiang Wei Lu Zhao-yang Li Jing Liu Xiao-pei Yao Chao
(,,710071,)
To solve the issue of background interferences on the scene text automatic localization algorithm, a scheme of background suppression for scene text is proposed, which utilizes characteristic of visual saliency to combine histogram of oriented gradient features, its statistical features, gradient magnitude features and gradient curve features with the boosting frame. The scheme aims to suppressing the complex background and highlighting the foreground text in natural scene. It can consider be as the preprocessing stage of the scene text automatic localization algorithm, and it improves the performances of the scene text automatic localization algorithm. The experimental results in both the ICDAR2011 scene text localization competition test dataset and the laboratory Chinese dataset show that the proposed scheme can suppress effectively the complex background and improve the scene text localization algorithm.
Image processing; Scene text; Background suppression; Visual saliency; Boosting method
TP391
A
1009-5896(2014)03-0617-07
10.3724/SP.J.1146.2013.00974
2013-07-08收到,2013-12-16改回
国家自然科学基金(60872141),中央高校基本科研业务费专项资金(K50510010007)和华为高校创新研究计划(IRP-2012-03-06)资助课题
姜维 jwmianzu@gmail.com
猜你喜欢
数学物理学报(2022年1期)2022-03-16
汽车工程师(2021年12期)2022-01-17
数学物理学报(2021年6期)2021-12-21
当代陕西(2020年14期)2021-01-08
应用数学(2020年2期)2020-06-24
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
计算机应用(2017年4期)2017-06-27
贵州师范学院学报(2016年4期)2016-12-01
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
