
基于GPU并行运算的高效雷达成像谱估计算法
2014-05-25 00:34:37贾伟伟张启梅许小剑
制导与引信 2014年4期
贾伟伟, 张启梅, 许小剑
(北京航空航天大学,北京 100191)
基于GPU并行运算的高效雷达成像谱估计算法
贾伟伟, 张启梅, 许小剑
(北京航空航天大学,北京 100191)
Apes和Capon等谱估计算法在SAR成像方面有着广泛的应用。同基于快速傅里叶变换的成像算法相比,谱估计成像算法能够获得更窄的谱峰和更低的旁瓣,但是计算量庞大。本算法基于图形处理器(Graphic Processing Unit,简称GPU)并行计算原理,在Jacket平台上实现了以上两种算法在雷达超分辨成像上的加速。在NVIDIA Tesla C2050和Intel (R)Xeon(R)CPU X5680上的测试表明,与传统基于CPU的SAR成像算法相比,本算法能够使计算速度得到数倍的提升。
合成孔径雷达;谱估计;超分辨;图形处理器
0 引言
现代谱估计算法在合成孔径雷达(SAR)成像中的应用越来越广泛[1]。非参数谱估计Apes和Capon算法是两种经典的谱估计算法[2,3],Capon算法只能用来估计信号中具有复正弦信号的谱线,而Apes算法可以同时用于估计复正弦信号的谱线、幅度和相位[3]。Apes及Capon算法在抑制旁瓣的同时进一步提高了图像的分辨率,但其庞大的运算量消耗较长的时间。虽然已有学者提出快速Apes及快速Capon算法[4-6],大大缩短了计算时间,但仍存在很大的加速空间。
近年来,GPU并行计算以其高性能、低价格受到科研人员的广泛关注。GPU在处理能力和存储器带宽上相对于CPU有明显优势,在成本上无需太大代价。CPU负责串行计算,处理逻辑性强的事务;GPU则专注执行高度线程化的并行任务。因此,GPU在执行以浮点运算为主,高度并行化的计算任务时更具优势[7-9]。
本文在Jacket平台上,使用GPU并行运算实现了SAR超分辨成像的Apes及Capon算法的加速。
1 Jacket平台介绍
2007年NVIDIA公司发布的计算统一设备架构(Compute Unified Device Architecture,简称CUDA)是一种将GPU作为数据并行计算设备的软硬件体系。CUDA C/C++,CUDA Fortran代码效率高,但算法实现较复杂。基于CUDA的Jacket平台,是专门用于MATLAB实现GPU加速的计算引擎,方便灵活、易于掌握。作为一个完全对用户透明的系统,Jacket平台能够自动地进行内存转移和计算优化,使数据移植到GPU上进行运算。一旦GPU的数据结构建立,该数据的任何操作只能在GPU上进行,要返回CPU端进行操作,必须先转换回CPU类型。
所有给定的CPU线程在某一时刻只能与一块GPU通信,所以Jacket平台要使用多个GPU,必须开启多个CPU线程。每个CPU线程都可以调用GPU完成数据的并行计算,从而实现算法的多GPU加速。但通常内核间通信以及内存转移带来的延时,会导致加速效果变差[9]。
2 Apes及Capon算法加速
2.1 加速原理
本文基于GPU对Apes、Capon算法及快速Apes、快速Capon算法进行改进[4-6],以实现计算的加速。以Apes算法为例,假设二维正弦采样信号为

式中:a为两个维度上频率为(ω1,ω2)时的信号幅度;en1,n2为零均值高斯白噪声。令N1、N2分别为行向和列向的采样点数,n1=0,1,…,N1―1; n2=0,1,…,N2―1。H(ω1,ω2)是长度为M1× M2的二维滤波器冲击响应,h(ω1,ω2)为由H(ω1, ω2)构成的列矢量。



其中:

令二维频率搜索矢量a(ω1,ω2)=a1(ω1)a2(ω2),其中为Kronecker乘积,且

最后可以得到Apes算法二维谱的估计值为
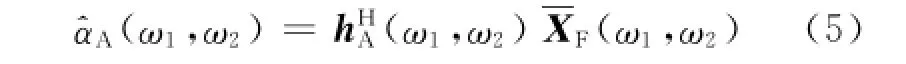
其中脉冲响应为


2.2 基于Jacket平台的算法流程
首先,运用gdouble函数将CPU数据类型转换成GPU数据类型。Jacket的内存管理系统将对GPU数据进行自动分配和管理,GPU数据调用的任何函数将自动执行,实现动态编译,无需额外编程。
其次,进行程序优化,调整数据的运算结构。GPU内核之间的数据通信以及内存与显存之间的数据传输将带来延时,致使GPU整体加速效果减弱,甚至可能导致比GPU更长的运算时间。
第三,多GPU运算时,Jacket需要使用开启多个CPU线程,从而使每个CPU线程都可以调用GPU完成并行操作,实现多GPU加速计算。
文中算法的耗时区间主要集中在自相关矩阵的计算及每一个频率点的谱值估计运算。图1为Apes算法的GPU并行运算程序流程图。
3 仿真结果及分析
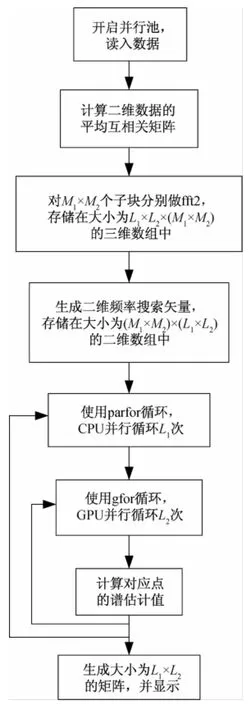
图1 Apes算法加速程序流程图
实验配置:Intel(R)Xeon(R)CPU X5680@ 3.33GHz处理器;64位Windows操作系统;64位MATLAB2013a;Jacket v2.3;4片NVIDIA Tesla C2050。所有计算结果均为5次计算时间平均值。Jacket程序执行时间中包含了数据在内存与显存之间的通信时间。
在实验中,选择B52H飞机缩比模型的实测数据进行加速效果验证。其中二维数据的频率采样点数N1=101,方位向采样点数N2=41。通过采用单CPU、4CPU、单GPU、4GPU四种方式进行对比,获得计算时间及加速比。首先设定二维滤波器的大小M1=31,M2=21,成像像素点数L1=150,L2=120。运行结果如表1所示。以单CPU的运行时间为参考基准,定义单GPU运行时间与其他三种方式运行时间的比值为加速比,对比验证其余三种运算方法的加速性能。

表1 各计算方法的运行时间及加速比
对比超分辨算法加速前后消耗的时间,可以发现GPU并行计算使程序运行时间大大减少。例如Apes算法使用单CPU计算的总时间为361.61 s,而经过4 GPU加速后时间缩短为61.30 s。
实验表明,将GPU并行计算应用于SAR超分辨成像中,获得了良好的加速效果。Apes算法使用4GPU获得5.89倍的加速;Capon算法使用单GPU获得3.74倍的加速;高效Apes算法使用单GPU获得14.60倍的加速;高效Capon算法使用单GPU获得6.82倍的加速。因为四种算法的运算量不同,内存与显存之间的通信在整个流程中的比重也不同,所以单GPU和4 GPU对四种算法的加速性能略有差异。而4 CPU没有达到加速效果,主要原因是CPU之间的数据分配及传输时间占较大比重,CPU多核加速的优势没有得到发挥。
表2给出了不同像素点数时Capon算法的耗时及加速比,其中二维滤波器的大小仍为M1= 31,M2=21。随着运算量的增大,运算加速比基本保持稳定。

表2 Capon算法在不同数据大小下的耗时及加速比
内核之间的通信以及内存转移会带来延时,甚至会造成GPU计算比CPU计算耗时更长。同时,GPU计算的高度并行性,要求数据之间相互独立。此外,在使用多GPU时,内存分配也会消耗时间。只有数据的结构及运算的具体要求满足并行条件,方可采用GPU并行运算。
4 结论
本文在Jacket平台下针对SAR超分辨成像算法(Apes及Capon算法)的加速问题进行了深入研究,详细阐述了一种基于GPU并行运算的SAR成像算法实现方案。文中针对成像算法的结构特性以及Jacket平台的运算特点,合理设计内存分配、数据传输及并行化执行流程,实现了Apes和Capon算法在GPU上的高效运行。在NVIDIA Tesla C2050上的测试结果表明,与传统基于CPU的方法相比,基于GPU并行运算的SAR成像算法运算速度大大提升。
[1]Cumming I.G.,Wing F.H..Digital Processing of Synthetic Aperture Radar Data:Algorithms and Implementation[M].Artech House,2004:140-141.
[2]Li J.,Stoica P..An Adaptive Filtering Approach to Spectral Estimation and SAR Imaging[J]. IEEE Transactions on Signal Processing,1996,44 (6):1469-1484.
[3]赵晓晖.谱估计与自适应信号处理教程[M].北京:电子工业出版社,2013:107-113.
[4]Liu Zheng-she,Li Hong-bin,Jian Li.Efficient Implementation of Capon and APES for Spectral Estimation[J].IEEE Transactions on Aerospace and Electronic Systems,1998,34(4):1314-1319.
[5]Glentis G.O..Efficient Algorithms for Adaptive Capon and APES Spectral Estimation[J].IEEE Transactions on Signal Processing,2010,58(1): 84-96.
[6]Angelopoulos K.,Glentis G.O.,Jakobsson A.. Computationally Efficient Capon-and APES-Based Coherence Spectrum Estimation[J].IEEE Transactions on Signal Processing,2012,60(12):6674-6681.
[7]张舒,褚艳利.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009:15-20.
[8]孟大地,胡玉新,石涛,等.基于NVIDIA GPU的机载SAR实时成像处理算法CUDA设计与实现[J].雷达学报,2013,2(4):481-491.
[9]Cook S..CUDA Programming-A Developer's Guide to Parallel Computing with GPUs[M]. Morgan Kaufmann Publishers,2012.
[10]任璐.关于提高SAR图像质量的研究[D].西安:西安电子科技大学,2005.
Spectral Estimation Acceleration for SAR Imaging Based on the GPU Parallel Computing
JIA Wei-wei, ZH ANG Qi-mei, XU Xiao-jian
(Beihang University,Beijing 100091,China)
Spectral estimation algorithms such as Apes and Capon have been widely used in SAR imaging,which can obtain complex spectral estimation with more narrow spectral peaks and lower sidelobes compared with FFT methods.The major disadvantage is the huge amount of computing which takes too long time.Based on the principle of GPU parallel computing,this paper proposes a technique to achieve the acceleration of the above two algorithms of radar imaging on the platform of Jacket.Tests on NVIDIA Tesla C2050 and Intel (R)Xeon(R)CPU X5680 showed that the GPU-based program can reach several times speed than the traditional algorithms of SAR imaging.
synthetic aperture radar;spectral estimation;super resolution;graphic processing unit(GPU)
TN011
A
1671-0576(2014)04-0037-04
2014-08-25
贾伟伟(1989―),女,硕士在读;张启梅(1988―),女,博士,均从事信号与信息处理技术研究;许小剑(1963―),男,博士,教授,主要从事智能化信息处理、遥感特征分析与建模、雷达目标识别等研究。
猜你喜欢
当代陕西(2019年13期)2019-08-20 03:54:22
电子设计工程(2017年17期)2017-09-07 06:37:46
环球市场(2017年36期)2017-03-09 15:48:21
数字通信世界(2015年4期)2015-09-23 07:57:30
装备环境工程(2015年1期)2015-02-06 07:48:55
测绘科学与工程(2014年5期)2014-02-27 07:06:14
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
大连交通大学学报(2012年3期)2012-07-02 03:26:44
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08 07:28:38
电脑爱好者(2009年13期)2009-07-07 09:52:52
