
论词汇分布作为词汇复杂度的一个测度
2014-05-23 15:33应晓东
云南民族大学学报(自然科学版) 2014年6期
应晓东
(浙江警官职业学院公共基础部,浙江杭州,310018)
论词汇分布作为词汇复杂度的一个测度
应晓东
(浙江警官职业学院公共基础部,浙江杭州,310018)
摘要:提出了一种评估非母语英语学习者的词汇应用能力的方法,用于提高英语为非母语者的自然语音响应自动评分系统的精度.方法根据词表中每个词在参照语料库的出现频率来估算词汇复杂度,并评定响应中词汇的平均难度等级.基于口语响应中的单词,得出3种特征:相关覆盖率、平均词排名及平均词频,研究了它们对人工语言能力得分的影响程度.最后,探讨了词汇分布特征对自动语音评分系统的影响,重点在于参照语料库的文类和词项类型2个因素的影响.
关键词:词汇;分布;复杂度;测量
口语评估通常用于测量语言能力的多个维度.目标语言的整体能力可以通过测试流利性、发音、语调、语法、词汇量、语篇结构等方面的能力进行评估.随着语言表达能力(口头和书面)自动评估技术的发展,急需建立评估的量化方法.
大多数自动语音评分研究都集中在流利性、发音和语调上,仅有一些研究探讨了与词汇应用相关的特征,并且仅限于形符类符比(TTR)等相关特征).词汇用法的语音结构包括2个部分:复杂度和精度,复杂度正是本文中试图量化的部分,词汇复杂度的测量措施试图量化使用者所使用的词汇多样性和丰富性.在已有研究结果的基础上,我们采用基于词汇分布的方法来评估词汇复杂度.
词汇分布,是指从一个涵盖各种目标语言的参照语料库中计算出每个词汇的出现频率.词汇复杂度通过词频来衡量,低频词由于词频较低,因此更复杂.本文设计了一些特征量来评估考生的响应文本中词汇的难度等级,对这些新的特征量和人工评分进行了相关性分析,同时评估了这些新特征量相对于自动评分系统中其他特征量的重要性.本研究的创新之处在于,在自动计分系统中应用词汇分布来评估词汇复杂度.
1 相关研究
词汇丰富性测度已经成为L1和L2语言能力评估研究的焦点,这些测度的类型可分为定量和定性测度[1].词频分布(lexical frequency profile,LFP)对给定的书面或口语表达使用词汇分布(VP)计算出不同频率单词的使用百分比,比如从1 000个最常用的词中计算出某一单词的词频,这些词来自一个预编译的词汇表,如学术词汇表(AWL)与Coxhead在1998年发表的相关词频分布.频率级指将一类单词(或选择适当的多词单位)根据其语料库中实际使用的频数分组.P-Lex是另一种使用单词的频率级评估词法丰富性的方法.这些措施均基于词条的不同频数,因此依赖于目标语言频率列表的有效性.
这2种类型的评估措施已用于英语作为第二语言学习者(ESL)的作文分析.Laufer和Nation 1995年的研究表明,LFP与词汇知识的独立评估措施相关性良好,可以根据学习者不同的能力水平对学习者进行分类.2004年,Morris和Cobb根据学生的文章研究了学生词汇量掌握程度与学生成绩的关系,结果表明学生拥有的词汇量与成级显著相关.另外,VP比口语面试更能评估高水平非母语者的语言能力.
Vermeer 2000年的研究指出,无论如何转换和修正,定量测度都没有获得预期的有效性与可靠性,没有达到预期的评估性能.本文试图基于一组参照词表的VP特征(词汇复杂度的测度)量化词汇运用能力.本研究的创新之处在于使用VP(词汇分布)作为口语评估中词汇复杂度的的测度,它源于自然语音能力水平的自动评分系统[2].
此外,我们还研究了参照语料库的文类对这些词汇测度性能的影响.为此,三种语料库将用来产生基准频率级.最后,我们将探讨词项类型如何影响这些测度的性能.
2 实验数据
本文采用AEST均衡数据集,它包括6个词项,考生要求对每个词项提供45至60秒的表述,所以每个考生需准备时长约5分钟的表述内容.6个词项中,2个词项根据考生的个人经验或背景知识,获取考生对同类主题的掌握信息和观点,这2个词项构成独立(IND)词项组.其余4个词项用于测试如听力和阅读等其他语言技能,构成集成(INT)词项组,再从这2组词项提取自然的、不受约束的自然语音.IND词项组和INT词项组的主要区别在于,IND仅提供一个提示词,而INT词项则提供了提示词、阅读文章和听力刺激.每个数据集的大小、用途以及考生的母语信息总结在表1中,所有词项用于提取自然的、不受约束的自然语音.

表1 数据集规模及考生的母语信息
每个响应采用4分制,其中1分表示低表达能力,4分表示高表达能力,由训练有素的人力评价者做出评定.评分准则可参照AEST评估准则.
由于AEST平衡数据集不重复计分,我们通过一大型的双重评分数据集评估语料库的评者间一致比,该数据集与AEST平衡数据集采用同样的计分准则和评分过程.用从AEST数据集采集的41 KB大小的双重评分响应,计算出与人工评分的皮尔逊相关系数为0.63,这表明两者在误差范围内相符合.该数据集的评分分布见表2.

表2 数据集的能力评分分布
3 实验
首先开发词汇分布特征,预先编译好多组词表,比如,将参照语料库中100个最常见的词列成词表.接着对每个测试响应使用语音识别器生成转录,根据每个参照词表的响应,计算出词汇分布特征评分及基本特征形符类符比(TTR)评分.
3.1 生成词表
本文所使用的3个参照语料库列于表3,它包含了英文最常用词汇表(GSL),托福2000学术语言口语、书面语语料库(T2K-SWAL)和AEST数据集.

表3 本文中使用的3种参照语料库
T2K-SWAL是在学术中使用的涵盖多种语言的口语和书面文本集.本研究仅采用了其中的口语文本.口语语料库包含会议讨论、会话、讲座等的人工转录文本,这些来自授课、学习小组会议、办公和服务接触等[3].
T2K-SWAL和AEST的所有人工转录都是标准化的,将所有的形符小写化,并去除除破折号和引号以外的所有非字母、数字字符,词汇的形态变体作为不同的词处理.所有的词根据其在语料库中的出现频数进行排序,生成6组词表:排名前100的词组成TOP1词表,排名101至300的词组成TOP2词表,排名301至700(TOP3)的词组成TOP3词表,排名701至1500的词组成TOP4词表,排名1 501至3 000的词组成TOP5词表,排名3 000以上的词组成TOP6词表.由于GSL只有约2 200个单词,所以只能生成5组词表.
3.2 生成评估数据的录音文本
本文采用隐马尔可夫模型(HMM)语音识别器对AEST数据集进行训练,收集了7 872个考生约733 h的非母语语音内容,使用了三音子声学模型和二元文法、三元文法和四元文法的N元文法语言模型.测试集输出的词错误率(WER)为27%.语音识别器对评估数据的每个响应通过ASR(自动语音识别技术)将语音转录成文本[4].
首先,每个串联响应基于ASR假设前提生成词表.IND词项只提供1个句子提示,而INT词项提供更多的刺激词,包括提示词、一段文章和听力刺激.为了尽量减小词汇对考生的影响,我们从词表中排除了提示词或刺激词的语境词.其次,用3个参照词表得到5种特征.每个参照词表最多生成10种特征,特征类型见表4.

表4 特征列表
具体步骤如下:
1)GSL用TOP1至TOP5词表组创建了5种特征,但并未建立TOP6词表组.T2K-SWAL和AEST数据集用TOP1至TOP6词表组分别创建了6种特征.
2)“rank”是词表中单词按词频降序排列的序号,不存在于参照语料库的词默认秩为Ref-MaxRank1.
3)平均词频指参照语料库所有单词数中不同单词频数的总和,参照语料库不存在的单词词频默认为1.
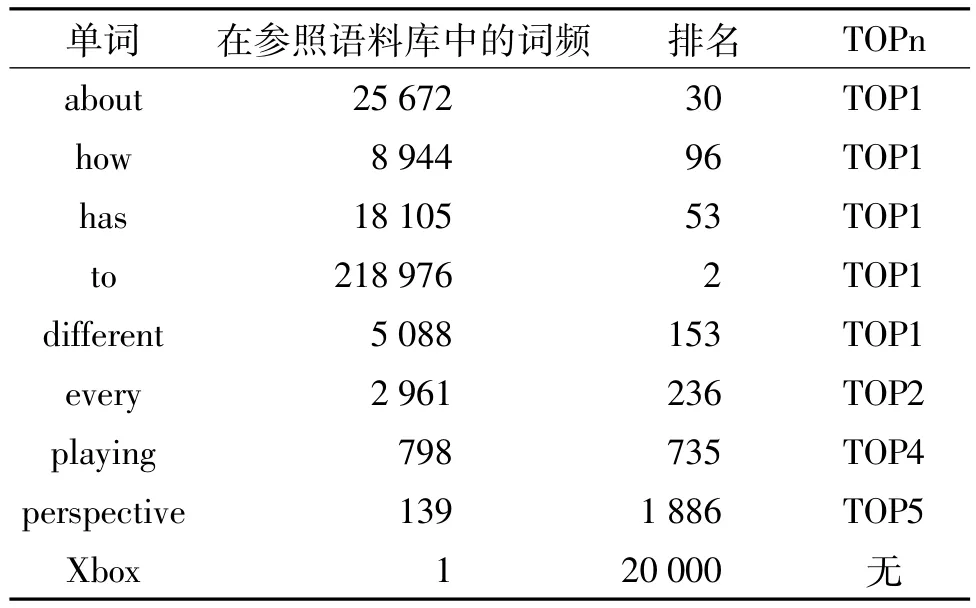
表5 特征计算示例
根据ASR假设生成第1步的语音文本,第2步生成对应的类符清单,第3步排除与提示词重叠的单词“student”和“relax”,得到最终含有9个类符的清单.
如果上述类符清单中的单词存在于参照语料库(按词频排序的词表)中,则可获得相应词的词频、排名和属于第几TOP词组.如果参照语料库没该单词,词频默认为1,默认单词秩为20 000,如表5中的“Xbox”.
4 实验结果
4.1 相关性分析
本文分析了所提出的特征和人工评分之间的相关性,以评估其对能力得分预测性能的影响.通过总结构成串联响应的2个响应的得分,估算了串联响应的参照能力得分.因此,新的评分范围为2~8分.表6列出了皮尔逊相关系数r[5].
aFreq特征评估性能最好,其次是TOP1.统计显示,这2个特征与人工评分有显著的负相关性.特征TOP6也表现出与人工评分的显著相关性,但比特征TOP1的相关性低10%~20%.这表明,当响应文本的词汇不仅仅局限于几个最频词时,人工评估更可能给予高分.然而,难词(低频词)的运用与人工评分也显示出微弱的相关性.

表6 各特征的评分与人工评分的相关系数
4.2 建立评分模型
为建立自动评分模型,我们采用了词汇分布与多元线性回归(MLR)框架下有效的其他特征:
wdpchk(流利性):平均词块长度,词块是指长时间沉默后的某一片段;
tpsecutt(流利性):每秒生成的单词类符数;
normAM(发音):语速归一化的平均声学模型得分;
phn_shift(发音):母语语音语料库中归一化元音持续时间与标准归一化元音持续时间的平均绝对距离;
stretimdev(韵律):每秒重读音节之间的平均距离偏差;
lmscore(文法):单词数归一化的平均语言模型得分.
首先计算这些特征的评分与人工评分的相关系数,并与评估性能最好的词汇分布特征进行了比较.表7列出了这些特征的评分与人工评分的皮尔逊相关系数r.

表7 各特征的评分与人工评分的相关系数
对于IND和INT这2个词项组,代表流利性的特征tpsecutt相关性最好.IND词项组中,tpsecutt与人工评分的相关系数约为0.66,INT词项组中相关系数甚至更高为0.73.
五倍模型的平均值列于表8,加权kappa值用以表明自动评分和人工评分的一致性,及其未经四舍五入(un-rnd)和经四舍五入(rnd)的皮尔逊相关系数r的一致性.新的加权kappa值显示出与人工评分更高的一致性,但对2个词项类型的改善都不大,仅约1%.皮尔逊相关系数和加权kappa值作为评估性能的测度,以保持与Zechner等在2009年的研究结果一致.此外,我们旨在研究预测分数和实际评分之间的关系,而非预测分数和实际分数之间的差异,相关性度量正合要求[6].

表8 词项类型的多元线性回归模型基于评分模型的性能表
4.3 讨论
一般情况下,考生在口头测试时会使用相对少的词汇量.测试时使用到的IND词项数平均为87.21,INT词项数平均为98.52,高频词的比例也很高.词频排名前100的单词比例近50%,排名前1 500的单词(TOP1~TOP4词组的总和)的比例平均超过89%,意味着这1 500个单词占了考生自然语音中近90%的主动词汇.图1给出了TOP1~TOP6词组常用词的平均比例.
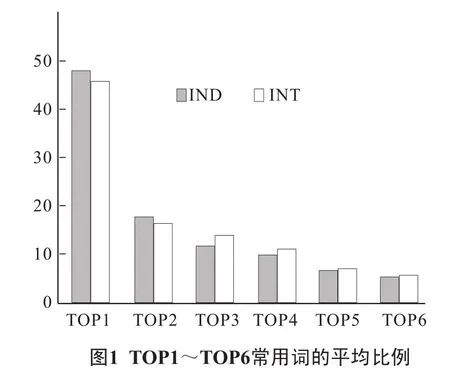
INT词项出现的比例与IND词项出现的比例差不多,但在TOP3至TOP6词组中,INT词项的比例均略高于IND词项,INT词项似乎包括更多低频词.
该研究中,基于AEST数据的特征的评分性能优于以T2K-SWAL为基础的特征的性能.虽然评估数据中没有词项与AEST数据重叠,考生能力水平和任务类型的相似度使AEST中的词汇及其分布与AEST平衡数据集更好地匹配,最终基于AEST数据集的特征性能最佳[7].
尽管个别特征(如aFreq)表现出了高相关性,但所有表现最好的特征并没有相应增加评分模型的评分性能.最可能的原因是训练数据集的规模比较小,每组只有约380条IND响应和约760条INT响应用于评分模型的训练[8].另一种可能性是训练数据集与现有特征重叠,词汇分布特征用于评分模型的建模可能已经被现有特征集一定程度上所涵盖.今后的研究中,我们将进一步详细探讨词汇分布特征.
5 结语
本文提出了衡量英语作为第二语言(ESL)学习者的词汇使用情况的特征.探讨了词汇分布特征是否适用于测量词汇的复杂度.计算了3种参照语料库的词频,用于评估考生的词汇复杂度.3种参照语料库中,AEST数据库的特征表现出较好的评估性能.本评估系统共生成29种特征,其中平均词频(aFreq)与人工评分的相关性最好.词汇分布特征的评分性能显示出与人工评分很强的相关性,但与现有评估语言能力的特征集一起用于自动评分模型时,扩充的特征集并未有多大的改善.
参考文献:
[1]才让加.面向自然语言处理的大规模双语语料库构建技术研究[J].中文信息学报,2011,8(2):10-13.
[2]俞敬松,王华树.计算机辅助翻译硕士专业教学探讨[J].中国翻译,2010,6(4):45-49.
[3]姚敏锋.基于短语译文组合的汉英翻译系统[J].广东外语外贸大学学报,2010,12(8):98-103.
[4]冀铁亮,穗志方.语言学与统计方法结合建立汉语动词SCF类型集[J].中文信息学报,2007,7(5):45-51.
[5]计算语言学与语言科技原文丛书[J].中文信息学报,2010,9(06):44-46.
[6]王厚峰.计算语言学歧义消解研究——兼介绍北京大学计算语言学教育部重点实验室[J].术语标准化与信息技术,2010,18(12):112-113.
[7]祝清松.我国自然语言处理研究的文献计量分析[J].情报杂志,2009(S2):44-50.
[8]徐金安.理性主义与经验主义相结合的机器翻译研究策略[J].计算机科学,2011(6):122-125.
(责任编辑 庄红林)
中图分类号:H003
文献标志码:A
文章编号:1672-8513(2014)06-0460-05
收稿日期:2014-06-05.
作者简介:应晓东(1973-),男,硕士,讲师.主要研究方向:英语语言学与计算语言学.
Vocabulary distribution:a measure to words′complexity
YING Xiao-dong
(Department of Basic,Zhejiang Police Vocational Academy,Hangzhou 310018,China)
Abstract:We presents a method that assesses ESL learners′vocabulary usage to improve an automated scoring system of spontaneous speech responses by non-native English speakers.Focusing on vocabulary sophistication,we estimate the difficulty of each word in the vocabulary based on its frequency in a reference corpus and assess the mean difficulty level of the vocabulary usage across the responses(vocabulary profile).Three different classes of features were generated based on the words in a spoken response:coverage-related,average word rank and the average word frequency and the extent to which they influence human-assigned language proficiency scores was studied.Finally,we discussed the influence on the vocabulary features of the automated speech scoring system.
Keywords:vocabulary;distribution;complexity;measurement
猜你喜欢
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
中华胰腺病杂志(2019年4期)2019-08-29
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
中国医药导报(2016年28期)2017-01-06
中国当代医药(2016年29期)2017-01-03
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
中华胰腺病杂志(2012年3期)2012-11-07
