
一种基于局部密度的k-means算法
2014-05-23 15:33和晓萍马晓敏黎吾鑫
云南民族大学学报(自然科学版) 2014年6期
关键词:means算法
黎 凡,王 新,和晓萍,马晓敏,黎吾鑫
(云南民族大学数学与计算机科学学院,云南昆明650500)
一种基于局部密度的k-means算法
黎 凡,王 新,和晓萍,马晓敏,黎吾鑫
(云南民族大学数学与计算机科学学院,云南昆明650500)
摘要:针对k-means算法必须事先指定初始聚类数k,并且对初始聚类中心点比较敏感,聚类准则函数对求解的最优聚类数评价不理想,提出一种基于局部密度的启发式生成初始聚类中心方法,在此基础上设计一种准则函数自动生成聚类数目,改进了传统k-means算法.实验表明改进的算法比传统k-means算法提高了聚类效率.
关键词:k-means算法;局部密度;初始中心点;聚类准则函数
聚类是一种无指导的机器学习方法,是数据挖掘中一个重要分支,主要用于发现相似类别的数据以及从数据中识别特定的分布或模式,被广泛地应用于人脸图像识别、股票分析预测、搜索引擎、生物信息学、医学及社会学等多种领域[1-4].它基于“物以类聚”的原理,把一组个体按照相似性归成若干类别(簇),使得同一类别的个体之间差异较小,不同类别的个体之间差别较大.目前已出现大量的聚类算法,总体来说可以分为5类:基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法和基于模型的方法.
k-means算法作为目前应用最广泛的一种基于划分的方法,只适用于数值型属性,对非球形簇处理效果不佳,具有简单、高效的特性,它的聚类思想比较简单,容易理解[2].但是算法本身具有局限性,不能预测簇的个数,聚类结果易受初始中心点影响,聚类质量依赖准则函数的选取等.本文针对k-means算法存在的不足,提出一种基于局部密度的启发式生成初始聚类中心方法,在此基础上设计一种准则函数自动生成聚类数目,改进了传统k-means算法,以提高聚类的质量和效果.
1 k-means算法
1.1 k-means算法基本思想
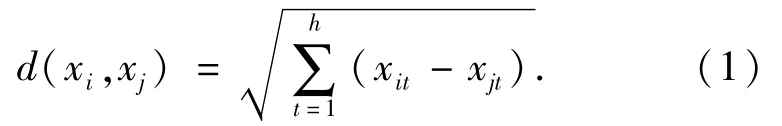
假设第Cj类中的样本为{xj1,xj2,...,xjnj},即包含nj个样本,则聚类中心cj=(,,...,,...,),其中为类中心cj的第p个属性分量,则聚类中心的第p个属性分量为:
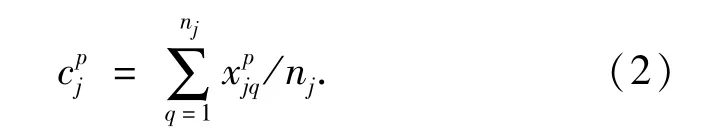

输入:聚类的数目k和包含n个对象的数据集;
输出:满足目标函数最小的k个簇;
Step 1从n个数据对象中任意选择k个作为初始聚类中心;
Step 2计算每个对象与这些中心的距离,并且根据最小距离对相应的对象进行划分;
Step 3计算每个类的均值作为新的中心,执行Step2;
Step 4循环执行Step 3和Step 2,直到准则函数E不再发生变化为止.
1.2 k-means算法的优缺点
k_means算法核心思想,主要通过计算点与点距离,找出使目标函数值最小的类,方法简便,易于实现.其次,算法时间复杂度为O(tkn),其中t为迭代次数,k为聚类数目,n为聚类对象数目,通常k≪t,t≫n,比较有效.
然而,聚类个数需要事先给定,在对于数据对象分布不了解且不能估计的情况下,聚类数目的给出就有了主观和盲目性,不适合的簇个数会造成不合理的硬性划分,影响聚类质量;其次,初始中心点的选取具有随机性,对噪声比较敏感且很容易陷入局部最优,而不同的初始点得到的聚类结果有很大差异性.好的初始点会适当减少迭代次数,加快聚类收敛速度,提高聚类质量;坏的初始点会增加迭代次数,使聚类效果变差;最后,当簇之间大小不均,密度不均又相邻较近时,处于稀疏的大簇边界上的点很容易被错分到与之相邻的高密度的小簇中,从而影响聚类的质量[2-3].
2 基于密度的初始中心点算法
现实世界中噪声是永远存在的,尤其是在大规模数据集中,将算法用在含有噪声的数据中,肯定对算法质量产生影响,对数据进行去噪处理,消弱噪声对算法的影响就很有必要.噪声本身就是孤立点,根据孤立点本身特性,采用基于局部密度的方法,对于密度很小的点直接删除掉,在剩余数据对象上进行聚类.下面介绍依据LOF算法[7-8]产生的基本概念.
2.1 基本定义
定义1 对象p的k距离(k-dist(p)).
对于一个正整数k,数据对象p的k距离记作k-dist(p).在数据集D中,存在一个数据对象o,该数据对象与数据对象p之间的距离记作d(p,o).满足条件:
1)至少存在k个点o∈{D/p},满足d(p,o)≤k-dist(p);
2)至多存在k-1个点o∈{D/p},满足d(p,o)<k-dist(p).
定义2 数据对象p的k距离邻域

定义3 点p的密度记作density(p)),

其中q(i)表示Nk(p)中元素的个数.
定义3密度公式不同于LOF算法中定义,不需要计算p的可达距离,或者p的第k距离邻域内所有数据对象到p的可达距离之和亦或平均距离之和,只需找出p的k距离,统计出p的k距离邻域内对象的个数,密度值即为后者比前者,思想更为简单,且计算量减少.
2.2 基于密度的初始化中心点算法
我们选取密度较高的点作为初始聚类中心,因为密度高的点不可能是孤立点且是聚类中心的可能性比较大,这样可以减少聚类迭代次数,增进聚类收敛速度.对于初始聚类中心的选取采取最远最优先策略[2],即先从整个数据集中随机选择1个数据点作为第1个聚类初始点,然后从剩下的数据集中选择离第1个中心最远的数据点作为第2个中心,然后再从剩下的数据集中选择离前2个中心所组成的集合最远的数据点作为第3个中心,以此类推,直到选择的中心数达到所要求的簇数为止.这一策略与聚类定义相呼应:不同类之间差别比较大,所以类中心点选取应尽可能远.算法描述如下:
Step 1根据定义3计算所有样本对象的密度density(xi),根据密度参数σ删除孤立点(个数为n0),此时样本对象的个数变为n=n-n0(去除属性噪声),初始化中心点集M={};
Step 2选择密度最大的样本对象记为m1,将m1从点集X剔除,存放到M中,利用公式(1)计算X剩下的点与m1距离最远的点,记为m2,将m2从点击X剔除,存放到M中;
Step 3重复Step 2直到M中有k个点,即M={m1,m2,...,mk};
Step 4输出初始中心点集M,算法结束.
该算法使用重新定义的密度公式,在Step 1直接去除属性噪声,算法时间上稍有缩减.但是在k-距离值给定和密度参数σ给定上和DBSCAN(基于密度算法)或LOF(孤立点检测算法)等一样,都需要凭经验给出.在实际应用中我们可以多取几组k-距离值,观察算法结果输出的密度值后,再确定密度参数值σ.
3 基于初始化中心点和加权准则函数的k-means算法
3.1 加权准则函数
一般准则函数的设计都注重两方面,每个簇的内部应该是紧凑的,即类内距离尽可能小,各个簇之间应该尽可能远,即类间距离尽可能大.所以就产生类内差异w(c)和类间差异b(c)2个概念[1].
类内差异可以用多种距离函数来定义,最简单的就是计算类的每一点到它的所属类中心的距离平方和:

类间差异度量也有多种:min距离(2类中最为靠近的2个样品点间的距离)、max距离(2类中最远的2个样品点间的距离)、类平均距离(分别位于2个类中任意2个点的平均距离)、类中心距离(2个类的聚类中心之间的距离),这里我们采取类中心距离:

聚类质量与类内差异和类间差异都有关系,类内差异越小,类间差异越大,聚类效果越好.而类的数目越多,类内差异就越小,类间差异就越大,所以应尽可能使聚类数目更大,但这与最初聚类的目的相违背,我们希望把尽可能多的点集中到较少类中.
基于这一思想提出一个聚类准则函数:J(c,k)=w(c,k)*b(c,k),其中k为聚类数目,w(c,k)即w(c),b(c,k)即b(c).实验表明:w(c,k)会越变越小,趋于稳定的一个很小的值接近0,尤其从1个类至2个类,急剧减小,2个类至3个类次之;b(c,k)相比较b(c,k-1)一般呈现1~2倍增长.用w(c,k)来约束b(c,k),给b(c,k)一个减小的系数,来限制聚类数目的变大;用b(c,k)乘以w(c,k)来促使类的数目变多,类内差异缩小.由于b(c,k)的增长较显著,起主要作用,所以J(c,k)越大,聚类质量越高.
J(c,k)仍有可改善之处,前面我们提到当簇之间大小不均且密度不均而相邻较近时,处于稀疏的大簇边界上的点很容易被错分到与之相邻的高密度的小簇中[3],从而影响聚类的质量.簇一般情况是不同的,大小相同且密度相同的2个簇是很难出现的,所以,我们的准则函数在定义差异时,不应该只做简单的簇间累加平方和,而应考虑簇本身的不同之处.
从k-means算法执行过程中我们发现,只要开始执行Step 2就会对所有的点进行一个分类,会把相应的点分配到对应的类中,从整体来看,数据集中不同数目的点分配到不同的簇中,数目多的点的簇当然会对准则函数的值贡献比较大,数目少的点的簇对准则函数的值贡献比较小,即使在Step 4重复计算均值中心直到算法结束为止,每一次迭代截止或者下一轮重复计算均值中心即将开始这一静态点,都是不同数目的点分配到不同的簇中.鉴于此,我们采用概率中“期望—方差”思想,对于每一个簇做加权处理,加权系数为簇中点的数目除以数据集总数目;所以有:
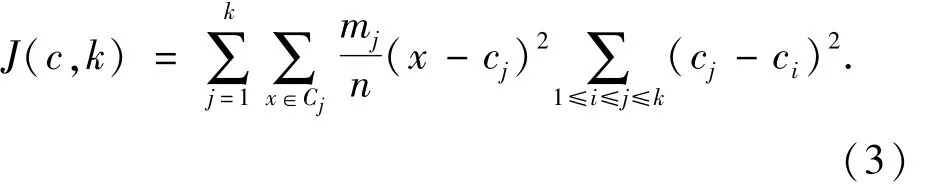
mj为Cj中元素个数,n为数据集元素总个数.如文献[3]经过加权重mj/n后,会使得簇中数目多的点对准则函数值贡献较大,这样在k_means算法的每一次迭代过程中,数据对象就会更倾向于被分配给数据对象数目较小的簇.于是当不同大小、不同密度的簇相邻较近时,处于稀疏大簇边界上的点被错分到与之相邻的高密度小簇中的可能性就会减少,从而改善聚类效果.
同上,J(c,k)最大时,聚类效果最好,用max(J(c,k))表示,此处k为最优聚类数目.
3.2 基于初始化中心点和加权准则函数的k_means算法
输入:具有n个对象的样本数据及k;
输出:使准则函数最小的最优的聚类数k;
Step 1.1 调用基于密度的初始值中心算法来确定i个对象作为初始中心;
Step 1.2 计算每个对象与这些中心的距离,并且根据最小距离对相应的对象进行划分,并记录每一簇中元素的数目mj;
Step 1.3 更新簇的平均值;
Step 1.4 根据式(3)来计算准则函数J(c,k),循环执行Step 1.2和Step 1.3,直到其收敛为止;
Step 2 根据max(J(c,k))来搜索准则函数J(c,k)值最大的,记下相应的k值;
Step 3 结束.
本文算法的时间复杂度分析:首先在计算初始化中心点为O(n log(n))(用R-tree),当n很大时,计算量就会比较大;其次在自动生成聚类数目的时候,由于k≤,只需进行次循环,所以算法的总共时间复杂度为.算法一开始运用基于局部密度的方法消除初始值对聚类结果的影响,并对噪声起到抑制作用.然后采用加权准则函数,对簇大小不一、密度差异较大情形,能做出较好区分.
4 实验结果和分析
本文是在Matlab 7.0平台上选择UCI中Iris数据和Breast cancer数据,其中Iris为150行4个属性的数据,Breast cancer为699行9个属性的数据.图2改进算法中k距离值为3,输出结果后,得出密度参数σ=3.849 1,用以删除小于σ的10%孤立点14个后,在剩余136个点上的聚类.从图上就可以看出,图2的初始中心点(“cszxd”)比图1更分散,更科学,比起随机初始点的任意性,可以减少算法迭代次数.

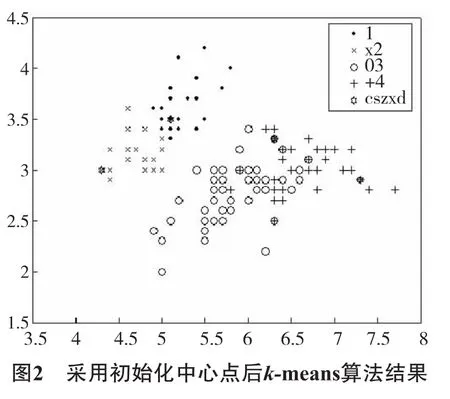

表1 传统k-means算法分成4类的40次试验
比较表1,优化初始中心点后的k-means算法试验恒分为4类,最大迭代次数恒为10次,比传统kmeans算法(分成2或3类情况11次)更稳定,且除极少数情况,比传统算法迭代次数更少,从而加快聚类收敛速度.
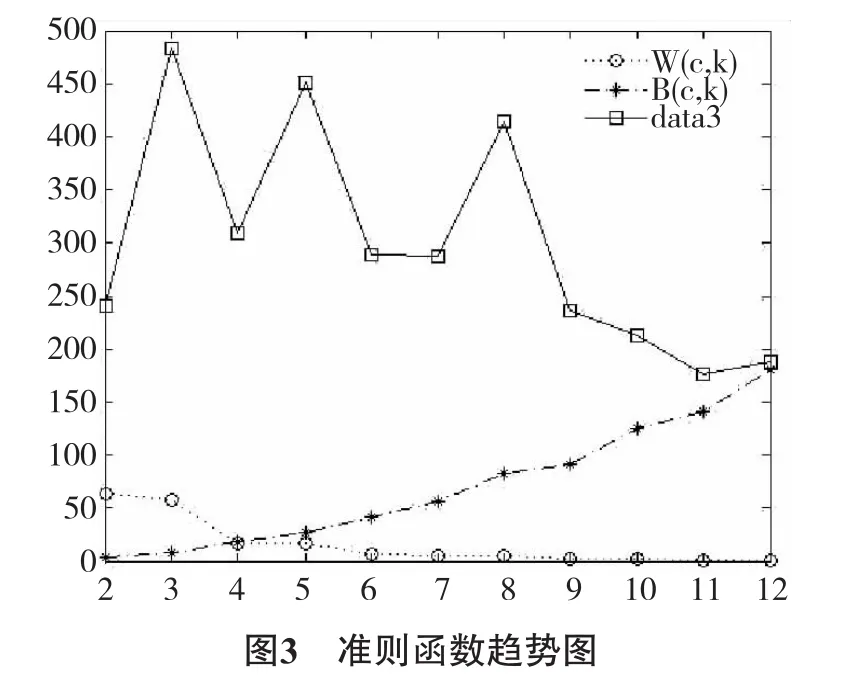
由图3可以看出b(c,k)、w(c,k)、J(c,k)变化情况,在k=3时,J(c,k)值最大,按照本文改进准则函数算法描述,经处理后Iris数据应该被划分为3类.
用Breast cancer数据实验,分成2类,传统kmeans算法最大迭代次数为7次(最多出现),算法运行时间为0.062 s;改进的优化中心点算法依然删除10%孤立点,在603个数据上为测试,最大迭代次数5次,算法运行时间为0.421 s.J(c,k)在k=13时,取最大值,根据新的准则函数应划分为13类.
5 结语
本文提出的算法能较好地选取初始中心点,加快算法收敛速度,且给出新的准则函数自生成聚类数目,不用事先给定聚类数目,取得与文献[1]相当的效果;但在准则函数的构造方面也还有不足,应适当加系数,或限制b(c,k)过快增长.
参考文献:
[1]汪中,刘桂全,陈恩红.一种优化初始中心点的k-means算法[J].模式识别与人工智能,2009,22(2):299-304.
[2]苗润华.基于聚类和孤立点检测的数据预处理方法的研究[D].北京:北京交通大学,2012.
[3]张雪凤,张桂珍,刘鹏.基于聚类准则函数的改进kmeans算法[J].计算机工程与应用,2011,47(11):123-127.
[4]安爱芬.一种改进的k-means初始聚类中心选择算法[J].山西师范大学学报:自然科学版,2013,27(1):30-34.
[5]李志.基于Web服务器日志挖掘的数据与处理研究[D].成都:成都电子科技大学,2012.
[6]张琳,陈燕,汲业,等.一种基于密度的k-means算法研究[J].计算机应用研究,2011,28(11):4071-4074.
[7]任义丽,刘洪甫,吴俊杰,等.基于组合局部鼓励点的噪声处理算法[J].中国科技论文,2013,8(7):672-678.
[8]胡彩平,秦小麟.一种基于密度的局部离群点检测算法DLOF[J].计算机研究与发展.2010,47(12):2110-2116.
[9]ZHANG Xuan-yi,SHEN Qiang,GAO Hai-yang,et al.A Density-Based Method for Initializing the k-means Clustering[C]//Proceedings of 2012 International conference on Network and Computational Intelligence,IPCSIT.2012,46:46-53.
[10]FAHIM A M,SALEM A M,TORKEY F A,et al.An efficient enhanced k-means clustering algorithm[J].Journal of Zhejiang University SCIENCE A,2006,7(10):1626-1633.
(责任编辑 梁志茂)
中图分类号:TP181
文献标志码:A
文章编号:1672-8513(2014)06-0439-04
收稿日期:2014-03-04.
基金项目:国家自然科学基金(61363022);教育部人文社科基金(12YJA870019).
作者简介:黎凡(1990-),男,硕士研究生.主要研究方向:数据挖掘.
通信作者:王新(1963-),男,教授,硕士生导师.主要研究方向:数据挖掘.
An effective k-means algorithm based on local density
LI Fan,WANG Xin,HE Xiao-ping,MA Xiao-min,LI Wu-xin
(School of Mathematics and Computer Science,Yunnan Minzu University,Kunming 650500,China)
Abstract:In terms of the k-means algorithm,it must choose the initial clustering number,more sensitive to the initial cluster center but the evaluation is not ideal forclusteringcriterion function to solve the optimal number of clusters.This paper proposes a heuristic way based on the concept of local density to generate the initial cluster centers,and then designs a criterion function,which automatically generates the number of clusters.The traditional k-means algorithm is improved.The experiments show that this algorithm improves the efficiency of the traditional k-means algorithm.
Keywords:k-means algorithm;local density;initial cluster center;clustering criterion function
猜你喜欢
哈尔滨理工大学学报(2017年1期)2017-04-08
商业经济(2017年3期)2017-03-20
哈尔滨理工大学学报(2016年4期)2016-11-10
电脑知识与技术(2016年16期)2016-07-22
计算机时代(2016年7期)2016-07-15
计算机时代(2016年6期)2016-06-17
电脑知识与技术(2016年6期)2016-06-06
电脑知识与技术(2016年7期)2016-05-19
软件(2016年1期)2016-03-08
现代电子技术(2014年8期)2014-09-27
