
基于多约束聚类的企业生产计划与质量设计优化模型
2014-04-25 07:16朱晓宁马风才
统计与决策 2014年24期
朱晓宁,张 群,颜 瑞,马风才
(北京科技大学 东凌经济管理学院,北京 100083)
0 引言
现在钢铁产品的需求越来越呈现多品种、小批量的特点,而钢铁产品的生产批量又很大,为了在多品种、小批量的生产模式下节能降耗和减少成本,钢铁企业通常采用基于成组技术的同成分合同合炉冶炼、同规格订单合批轧制的批量计划方案组织生产[1]。在这种生产模式下,质量设计不仅需要基于标准对单个产品进行设计,还需要对不同钢级产品的批量质量进行标准+α[2]的设计,α是高于或严于标准规定的产品特性,是为了保证批量生产的不同产品既能达到质量要求,又尽可能减少因质量等级过高而产生的质量浪费现象。目前,对于炼钢合炉生产计划的研究大多集中在炼钢—连铸阶段最优炉次计划的确定上。轧钢批量生产计划的研究大多集中在板带钢、型钢和无缝钢管以及炼钢—连铸—连轧的集成生产批量计划与调度上。张文学和李铁克[3]在分析钢铁生产中的钢轧一体化批量计划编制问题基本特征的基础上给出了一体化编制策略,并建立了问题的约束满足优化模型。针对模型的NP难特性,提出了一种将改进离散粒子群算法、约束满足和邻域搜索相结合的混合算法。Kim等[4]建立了质量设计与生产计划集成概念模型,但是并没有提出定量模型。杨静萍等[5]分析了面向组批生产计划的钢铁产品质量设计的特点及生产计划的集成性,提出了基于带空间和容量约束的聚类分析的组批质量设计方法,但是其模型没有考虑成本因素,本文则在文献[4]、[5]的基础上进行改进,增加了生产成本约束和炉成本约束,研究如何在尽可能满足炉容量、生产成本、炉成本、规格范围和交货时间约束下,尽可能将质量差别小的订单安排在相同的炉次生产,从而优化钢铁企业批量生产计划与质量设计的集成模型。
1 面向订单的钢铁企业批量生产计划与质量设计集成原理
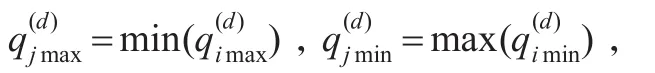
(1)根据客户需求对各单一合同进行质量特性设计。
(2)对于相似合同,根据质量特性差异大小,按照批量容量限制对这些合同进行聚类划分,将质量特性取值范围相同或相近的合同尽量分在同一组批中,以便减少由于低要求高标准生产而带来的质量损失。
(3)计算各组批聚类的中心,得到组批质量特性值及α值。
2 面向订单的钢铁企业生产计划与质量设计集成优化模型
2.1 模型建立

然后把所有合同按质量特性向量进行分类,归入不同的集合中,使得每个集合内的质量特性差异最小。
模型描述如下:
(1)有不同型号(容量不同)的炉,每个炉有不同的固定成本和变动成本;
(2)有多组质量特性不同的生产合同,将所有生产合同按质量特性分成不同的批次形成生产计划;
(3)根据产品质量要求安排对应炉完成生产计划,每个炉可以完成一个批次的生产合同,每个批次只能交给一个炉完成,炉与批次是一一对应的关系;
(4)每个炉安排的生产任务不能超过其容量限制,每个炉的总生产成本不能超过其总成本上限;
(5)目标函数是各个批次内生产合同的质量特性差异之和最小,质量特性差异由质量特性向量之间的欧氏距离表示。
给出各个符号的意义,如表1所示。

表1 钢铁企业批量生产计划与组批质量设计的优化模型符号及解释

2.2 算法设计
遗传算法是一种有效的全局搜索算法,由美国Michigan大学的J.Holland[6]教授在1975年提出的。遗传算法各部分的策略为:
(1)编码规则。根据问题特点,采用混合编码方式,对决策变量xlt采用二进制编码方式,对决策变量Ot采用实数编码。例如,假设把3个合同分成2个批次,每个合同有2个维度的质量特性,则染色体表示的生产计划为合同1、2划入第一个批次,合同3划入第二个批次,其中批次1的质量特性中心点为(0.1,0.2),批次2的质量特性中心点为(0.15,0.15)。
(2)适应度函数。模型为求最小值问题,对于此类问题通常选择目标函数的倒数作为适应度函数,但是考虑到目标函数取值范围未知,为了提高算法的泛化能力,考虑用如下公式作为适应度函数:

(3)选择算子。选择操作提供了遗传算法的驱动力,驱动力太大则遗传搜索将过早终止,驱动力太小则进化过程将非常缓慢。本文采用轮盘赌选择策略,其基本原理是根据每个染色体适应度的比例来确定该个体的选择概率或生存概率。为了实现最优保存策略,当前种群中的最优染色体直接进入下一代。
(4)交叉算子。交叉操作是交换两个染色体部分基因的遗传操作。根据交叉概率Pc选择进入配对池的父代个体,把父代染色体中的部分基因加以替换重组,产生子代个体。由于本文染色体编码由两部分组成,所以需要采用混合交叉算子,具体方法为:第一部分采用均匀交叉;第二部分采用双点交叉。均匀交叉算子:首先随机地产生一个与染色体第一部分基因串等长的二进制串,0表示交换,1表示不交换,根据二进制串判断是否交换父代个体对应位置上的基因。双点交叉算子:首先随机产生两个个基因位置,然后直接将配对染色体对应位置上的基因互换。
(5)变异算子。变异操作是产生新个体的辅助方法,它决定了遗传算法的局部搜索能力,同时保持种群的多样性。变异操作依据变异概率Pm对每代种群中的染色体进行基因突变,常用的基因突变方式有均匀、交换、逆转和位移等,根据本文编码规则的特点,采用混合变异算子。对染色体第一部分基因串使用均匀变异算子,对应基因直接在0和1之间进行变异,对染色体第二部分基因串使用双点变异算子,对应基因分别以0.5的概率翻倍或减半。
(6)调整非可行解。对于交叉操作和变异操作中产生的非可行解进行调整。每个合同都必须且只能划入一个批次中,因此同一合同的所有基因只能有一个取值为1,其余基因取值为0,当同一合同的基因有两个或两个以上取值为1时,随机选择一个位置令该基因值为零,当所有基因均为零时,随机选择一个位置令该基因值为1。染色体第二部分采用实数编码,所有操作均不会导致非可行解情况出现。
根据遗传算法各部分的策略,得到算法步骤如下:
(1)参数初始化:设定最大迭代次数G,初始种群规模Popsize,交叉概率Pc,变异概率Pm;
(2)种群初始化:随机产生Popsize个可行解作为染色体,构成初始种群,令g=0;
(3)种群更新:更新当前种群,用第g代种群替代当前种群;
(4)计算适应度:计算当前种群中各染色体的适应度值,适应度值最高的染色体直接进入下一代;
(5)遗传操作:对当前种群进行选择、交叉和变异操作,产生新的种群;
(6)非可行解调整:对新的种群中非可行解进行调整;
(7)终止条件:若g=G,则算法终止,输出当前种群中的最优染色体;若g<G,则更新当前种群,转Step3,g=g+1。
3 实例分析
选取包钢2011年7~8月订单进行实例研究,包钢现在共有10个转炉,210t×2,150t×2,120t×2,80t×4,每种类型炉的固定成本(元/炉次)和单位成本(单位:元/t)如表2所示。
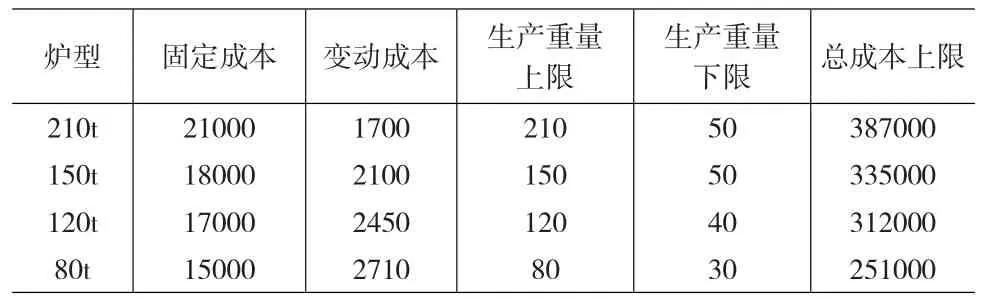
表2 不同炉类型基本情况表
选取了7~8月的61个订单(订单信息略)。

表3 不同钢铁产品标准聚类情况表
首先对订单进行预处理,预处理的步骤如下:
(1)剔除可以整炉生产的订单;
(2)将同标准的订单归到一起,计算同标准的订单需求总量;
(3)同标准订单需求量减去整炉生产量,得到该类标准产品合炉量;
(4)对质量设计参数进行预处理。
通过预处理后,共有16种标准,各标准的订单情况。对各合同质量设计参数均值结果进行主成分分析,根据主成分分析结果,可得到主成分表达式:

将各订单的质量设计参数上下限值范围代入主成分表达式,按照以上模型及算法进行求解,可得到聚类结果(表3),最终炼钢批量生产计划方案结果如表4所示,表明较好的解决了钢铁企业需求、批量生产计划与质量设计集成问题。

表4 炼钢批量生产计划方案结果
4 结束语
面向订单的批量生产计划与质量设计集成模型基于质量特性聚类为钢铁产品批量生产计划的决策提供依据,能够满足多品种、小批量的钢铁产品生产过程中不同产品批量生产的质量要求。该模型在满足炉容量、生产成本、炉成本、规格范围和交货时间约束下,对不同钢级产品的质量进行标准+α的设计,不仅满足了多约束条件,同时降低成本。采用主成分分析法进行数据预处理,在保证数据单位和量纲一致的前提下,缩小了问题域的规模,考虑到遗传算法较为成熟,并且对于各种特殊问题可以提供极大的灵活性来混合构造领域独立的启发式,从而保证算法的有效性的优点,采用遗传算法进行求解,并针对模型特点进行算法设计。最后通过实例研究证实了该模型的科学性和有效性,能够减少由于质量不合格或过高带来的质量浪费,同时减少由于未满足设备容量约束而造成的能源、人力等资源的浪费,为生产组织人员提供了定量决策依据,降低生产成本。
[1]唐立新.CIMS下生产批量计划理论及其应用[M].北京:科学出版社,1999.
[2]那宝魁.解读质量管理[M].北京:冶金工业出版社,2006.
[3]张文学,李铁克.基于粒子群和约束满足的钢轧一体化批量计划优化[J].计算机集成制造系统,2010,16(4).
[4]Kim J,Seong D,Jung S,et al.Integrated CBR Framework for Quality Designing and Scheduling in Steel Industry[J].Lecture Notes in Com puter Science,2004,3155.
[5]杨静萍,刘晓冰,王宇春等.基于多约束聚类的钢铁合同组批质量设计方法[J].计算机集成制造系统,2009,15(11).
[6]Holland J.Adaptation in Natural and Artificial Systems[M].Cambridge,MA:MIT Press,1975.
猜你喜欢
今日农业(2022年15期)2022-09-20
茶道(2022年3期)2022-04-27
流行色(2020年9期)2020-07-16
科学之谜(2019年3期)2019-03-28
科学之谜(2018年8期)2018-09-29
生物学教学(2018年3期)2018-08-08
中学生物学(2018年8期)2018-03-01
CHIP新电脑(2017年6期)2017-06-19
中学生理科应试(2016年4期)2016-11-19
恋爱婚姻家庭·养生版(2016年9期)2016-09-07
