
基于语义依存关系匹配的汉语句子相似度计算
2014-04-21 05:55:54汪卫明梁东莺
深圳信息职业技术学院学报 2014年1期
汪卫明,梁东莺
(深圳信息职业技术学院教学督导室,广东 深圳 518172)
基于语义依存关系匹配的汉语句子相似度计算
汪卫明,梁东莺
(深圳信息职业技术学院教学督导室,广东 深圳 518172)
在中文信息处理中,句子相似度计算是一项基础而核心的研究课题,长期以来一直是人们研究的一个热点和难点。句子相似度计算在实际中有着广泛的应用,它的研究状况直接决定着其他一些相关领域的研究进展,如信息检索的相似句子匹配、自动问答的问题匹配与答案抽取等,句子相似度计算都是非常重要的环节。本文提出了一种基于依存关系匹配的句子相似度计算方法,利用词语内在概念和词语相互依存关系计算句子之间的相似度。结果表明,该算法能显著提高返回结果的准确率。
依存关系;关系匹配;词义相似度;依存关系相似度;自然语言处理
1 句子相似度的计算方法
目前,关于句子相似度的计算方法种类很多,从总体上看主要有以下几类:基于词语共现统计的方法、基于语义词典的方法、基于语法结构关系的方法以及基于词语排序的计算方法。国内学者从不同方面(如向量空间模型、语义距离、语义依存、公共短语等)来计算句子的相似度,下面分别介绍相关研究人员采用的不同方法。
1.1 基于词语共现的方法
基于词语共现统计的方法是一种最基本的方法,将文档看成词语的集合,不需要对文本内容进行深层理解,只是通过词语共同的出现次数来计算句子相似度[1,2]。计算句子的相似度,等价于计算句子之间关键词的相似度,比较两个词之间的相似度。有些研究人员在此基础上作了改进,考虑不同词性的词语的重要性,设置了不同的权重[3]。但归根结底,这是一种词频统计的方法,只考虑词语的统计特性,没有考虑词语的内在含义,因此实际效果较为一般。
1.2 基于语义词典的方法
基于语义词典的方法主要是借助知网、同义词词林[4]等较为成熟的语义词典资源,根据其中的语义分类体系,采用一定的方式计算词语之间的词义相似度,再通过词义相似度计算句子间的语义相似度[5,6]。这种该种方法充分考虑了句子中每个词的内在语义信息,对于计算句子相似性有一定的提高。但由于词典的不全面和词义消歧准确率的限制,也给计算带来了一定的误差。
1.3 基于公共短语的句子相似度计算
在现有的几种计算方法中,句子相似度计算的粒度一般是词语。在汉语句子中,词语是句子表达的基本粒度,基于词语匹配的方法是一种自然的选择。但是,这种基于词语的计算方法视句子为词语的组合,没有考虑句子内部的组合关系,因此无法准确的反映句子的内在信息组合。基于公共短语的计算方法是在词语粒度的基础上,更看重词语的组合对句子相关性的区分[7,8],然而这种分析方法受句子中词语表达选择的影响较大,意思相近的句子在词语选择上有很小的变化相似度可能会差别很大,通常只是在专业性较强的领域内比较有效。
1.4 基于语义依存的句子相似度计算
依存句法是由法国语言学家L.Tesnier提出,对计算语言学产生了深远的影响,通过分析句子内部成分之间的依存关系揭示其句法结构[9]。语义依存句法分析在一定程度上可以准确的反映出句子中各成分之间的修饰关系,它可以获得长距离的搭配,并跟句子成分的物理位置无关。斯坦福大学自然语言研究室的依存句法分析器和国内哈尔滨工业大学计算机科学与技术学院智能内容管理实验室的依存句法分析器,准确率都能达到 85%以上。
语义依存关系能够比较准确的反映句子成分之间的搭配关系,李彬、赵妍妍等人利用句子的关键依存关系进行相似度匹配,利用句子的语义依存关系进行句子理解[10],但其中仅仅利用依存关系中的词语相同与否计算依存关系相似度,无法真实准确的反映句子内在的语义关系。
2 语义依存关系分析
通过对句子进行语义依存关系分析,可以比较准确的得到各个成分之间的依存关系。首先利用依存关系分析工具处理句子,得到其中的依存关系结果,然后在利用语言学的知识对其中的语义依存关系进行扩展,从而更加准确的理解句子。
2.1 语义依存关系树
本文采用了哈尔滨工业大学计算机科学与技术学院智能内容管理实验室所做的依存句法分析器。对于如下句子分析得到各自的依存关系:
(1) 张某醉酒后驾驶追尾,造成乘车人当场死亡的交通事故。

图1 句子(1)语义依存关系树Fig.1 Dependency tree of sentence 1
(2) 江宁区发生一起醉酒驾车导致的交通事故,事故造成3人身亡。

图2 句子(2)语义依存关系树Fig.2 Dependency tree of sentence 2
通过语义依存关系分析,可以得到句子中各个词语直接的组合关系,同时,也包含了每个实体词语的语义表示,如驾驶的词林Hf01,比较准确的反映了词语的具体含义,这些都对句子的准确理解提高了帮助。
2.2 依存关系筛选
句子语义依存关系分析可以得到词语之间的相互关系,但不少关系对于句子的理解作用不大。在哈工大LTP依存句法标注体系中,共有主谓关系(SBV)、动宾关系(VOB)、介宾关系(POB)、动补结构(CMP)等共计25种依存关系。
一个句子中存在的各种语义关系其重要性和相互间的关联程度不一,不能统一对待。在文章[10]中,作者采用的词性分类的方法,按照依存关系中两个词语的词性对句子中的依存关系进行了简单分析,主要选取VN、VV、NN用于句子相似度的计算。
但这种方法将语法依存关系这种语义信息丰富的关系表达式退化成词性搭配的组合,短语之间的语义关系没有充分利用。我们提出了一种基于关系匹配的依存关系相似度计算方法,在计算两个依存关系的相似度时,不仅仅考虑词语之间的关联,还要考虑依存关系类别的影响,这种计算方法考虑了构成一个依存关系的所有三个元素,因此计算上更为准确。
在汉语句子中,主谓宾在句子语义表达上起起支配作用,我们首先筛选出主谓关系(SBV)、动宾关系(VOB)、介宾关系(POB)等表示句子总体框架的语义关系。另外,并列关系(COO)、定中关系(ATT)、同位关系(APP)都是非常重要的修饰关系,也需要纳入计算中来。在基于关系匹配的依存关系分析中,共有6种语义关系用于相似度计算。
2.3 依存关系关联分析
表面上看,6种语义关系表达的含义差别很大,计算语义关系相似性时只需要考虑同种类型的语义关系,无需考虑彼此之间的联系。但由于汉语概念关系表达上的多样性,各种语义关系在知识表达上会有一定的关联。同时,语义依存关系分析上的局限性,语义关系分析可能会产生一定的错误。这些情况都决定了必须要考虑关系之间的关联。
2.3.1 主谓宾关系分析
主谓宾关系,这里指的是主谓关系(SBV)、动宾关系(VOB),由于这两种关系与定中关系(ATT)在知识表达上存在较大的关联,有时候甚至出现类别错分的情况,需要仔细研究它们在关系表达上的关联。
例如,在句子中出现的,在以下的三个短句子中,“汽车”和“驾驶”、 “驾驶”和“技术”之间的依存关系如下:
(3) 汽车驾驶技术的发展。
SBV(驾驶,汽车)VOB(驾驶,技术)
(4) 老李驾驶汽车的技术很好。
VOB(驾驶,汽车)ATT(驾驶,技术)
(5) 老李驾驶的汽车很新。
ATT(驾驶,汽车)
从中可以看到,“汽车”和“驾驶”之间存在三种不同的依存关系,而按照文献[10]给出的方法视作VN组合同样对待,势必会造成匹配上的不准确。
仔细看看这三个依存关系,句子(3)给出的“SBV(驾驶,汽车)”依存关系并不准确,实际上这里正确的依存关系应该是“VOB(驾驶,汽车)”。这是汉语语义分析中现有方法不可避免出现的错误,也就是说动宾关系可能被错误的理解成主谓关系。实际上,还会存在另外一种错误,将定中关系(ATT)分析成动宾关系(VOB),例如,句子(3)中,“驾驶”和“技术”之间的关系应该是定中关系而不是动宾关系。如此说来,由于汉语词语表达的特殊性,SBV、VOB、ATT三种关系都可能出现错误分析的情况,简单的用词性分类(VN组合)的方法更加准确。其实不然,因为分析出来的SBV关系可能应该是VOB关系,但不可能是ATT关系;同时,分析出来的VOB关系也不可能是SBV关系。
事实上,除了以上列出的SBV、VOB、ATT关系分析错误,还会出现词语词性分析错误的情况,进而导致关系类别的错误。
2.3.2 修饰关系分析
修饰关系有并列关系(COO)、定中关系(ATT) 、同位关系(APP)、介宾关系(POB)四种。由于介宾关系由介词和另一个短语关联而成,与其它三种关系差别较大。在考虑彼此间的关联时,只考虑并列关系(COO)、定中关系(ATT) 、同位关系(APP)。其中,同位关系和并列关系都表示一种平行关系,在语义表达上非常相近,在关系计算时视为同一种关系,如将同位关系归入并列关系。定中关系与它们之间的关联需要统计处理。

表1 依存关系关联矩阵Tab.1 Dependency relation matrix
2.3.3 关系关联矩阵
在分析依存关系之间的关联后,可以知道,依存关系之间存在着复杂的语义关联。为了准确的分析关系之间的关联,我们进行了半自动化的依存关系评测。我们从一组新闻中随机筛选了20000个句子,首先自动筛选出某种短语组合的所有语义关系,统计语义关系分析中的错误,进而人工评测依存关系之间的关联程度,建立语义依存关联表,如表1所示。
3 基于关系匹配的句子相似度计算
与英语句子相比,一个汉语句子往往由多个子句组成,通常所包含的信息量更大,这给句子相似度计算带来了麻烦。文献[3]提出了一种关键词加权的改进方法,根据词语的词性赋予不同的权重,但词性不能够准确反映词语在句子中的重要性。我们提出一种基于关系匹配分析的句子相似度计算方法,句子相似度的计算在传统概念相似度计算的基础上,充分考虑两个句子的内在的依存关系关联,即词义相似度和依存关系相似度计算相结合。
3.1 词义相似度
词语语义相似度的研究相对较为成熟,并且已经应用于自动问答、机器翻译、文本聚类和词义排歧等领域[11-13]。词语相似度计算不是本文研究的重点,本文利用《哈工大同义词词林扩展版》,根据其中词语之间的语义距离,计算相互之间的相似度。如表2所示,表中编码位是按照从左到右的顺序排列。

表2 哈工大同义词词林扩展版编码规则表Tab.2 HIR tongyici cilin code rules
中科院刘群的基于<知网>的词语相似度计算是当前比较有代表性的计算词语相似度的方法之一[18],通过词语节点之间的距离计算它们之间的相似度,其公式为:
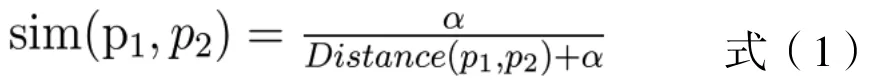
由于不同词性的词语之间关系不大,因此在词义相似度计算时,我们只计算同种词性词语之间的相似度。对于给定的一种词性(以动词为例),假设、、…、是句子中所有的动词,、、…、是句子中所有的动词,则句子和的动词相似度可以计算为:
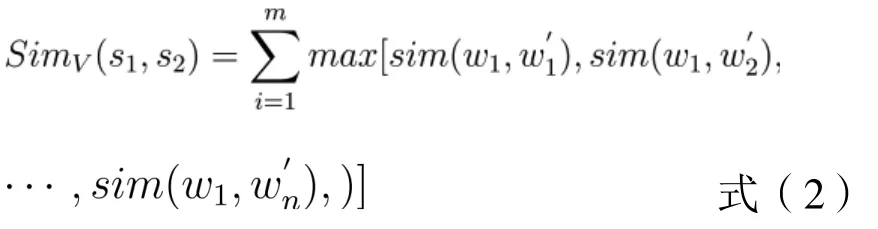

3.2 依存关系相似度

考虑到,词语相似度计算的是一对词语之间的相似度,而语义相似度为两对词语之间的相似度,其数值相对词语相似度较小,无法准确体现语义关系的重要性。为此,我们在上述公式(4)的基础上进行了改进:
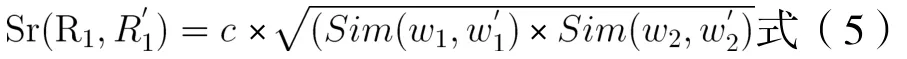
由于两个句子包含的依存关系很多,两两计算所有关系之间的相似度,计算量很大;而现实中,即使两个非常相似的句子,有关联的依存关系也非常有限。为了减少没有必要的计算,我们规定只有两个句子中的词语对之间相似度超过一定的阈值,才计算相关联的关系相似度。简单起见,我们限定和、和同义词词林编码同属一个中类,即编码前两位相同时,才需要计算关系相似度。
在一个句子中,共有5种语义关系(主谓关系、动宾关系、定中关系、并列关系和介宾关系,其中同位关系与并列关系合并),设定各种的权重分别为、、、和。从句子依存关系的分别来看,动宾关系、定中关系对于句子的语义表达起主要作用,而介宾关系是一种辅助关系,权重最低。根据这些分析,我们设定、、、和,如果某一项不存在则权重为0,。两个句子的语义依存关系相似度可以计算为:

3.3 句子整体相似度
按上述方法对句子进行关键词抽取并对不同词性的词赋予不同的权重后,可以从词义和语义关系2个方面计算句子的相似度。
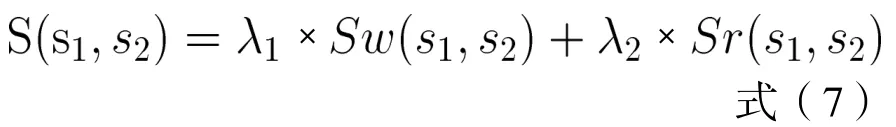
4 实验结果与分析
由于汉语中没有句子相似度检索用的标准测试集,所以我们自行构造实验所需的句子集合。本文实验所用的测试集共有30000个句子,其中,人工选择了网络上财经、娱乐、体育、科技、文化、旅游等20个子类共计25000个句子,另外有5000个句子为从新闻中随机选择的句子得到作为噪音集。
为验证语义依存匹配方法的有效性,与VSM模型进行了比较。从20个子类随机选出10个子类用于比较,每个子类随机选择10个句子用于实验评测。评价由5个大学生采用评价机制完成,对前15个答案句子进行评测,按相关性分为三类:A准确,B相关,C不相干。评价指标有评价准确了(MAP),召回率(Recall)和F1值。
从上述实验结果可以发现,本文采用的方法同类标准集句子返回比例和返回句子的得分要远远高于TF+IDF方法,综合利用依存结构能够提高实验结果的正确率。
另外,我们对语义依存匹配方法在各类句子的表现进行了分析,发现该方法对旅游类、体育类的句子检索结果提升最为明显,其中旅游类句子查询准确率有24.8%的提升。分析其中的原因,因为这类句子包含的介宾关系较多,在VSM的方法中没法利用,而在语义依存匹配的方法中介宾关系则是一个有用的匹配元素。

表3 实验结果Tab.3 Experiment result
5 结束语
本文采用了一种基于词义匹配和依存关系分析的汉语句子相似度计算方法,该方法把句子词义信息同依存文法分析结合起来,更加准确地反映了句子的内在含义。在计算依存树之间的相似度时,本方法按照语义依存关系分类匹配,这样使计算的时间复杂度大大降低,最后我们进行了该方法与VSM方法之间的对比试验,实验结果证明该方法要优于VSM方法。
(References)
[1]吕学强,任飞亮,黄志丹,姚天顺.句子相似模型和最相似句子查找算法[J].东北大学学报:自然科学版,2003.vol.24,no.6,531-534.LV Xueqiang,REN Feiliang,HUANG Zhidan,et al.Sentence similarity model and the most similar sentence search algorithm[J].Journal of Northeastern Univ (natural science),2003,24 (6):531-534.(in Chinese)
[2]杨晓明,罗振声.模式匹配在中文问答系统中的应用研究[J].科学技术与工程,2006,6 (3):319-322.YANG Xiaoming,LUO Zhensheng,Application of pattern matching in Chinese question answering[J].Science Technology and Engineering.2006,6 (3):319-322.(in Chinese)
[3]裴婧,包宏.汉语句子相似度计算在FAQ中的应用[J].计算机工程,2009,35 (17):27-29.PEI jing,BAO Hong.Application of Chinese sentence similarity computation in FAQ[J].Computer Engineering,2009,35 (17):27-29.(in Chinese)
[4]梅家驹,竺一鸣,高蕴琦,等.同义词词林[M].上海:上海辞书出版社,1983.MEI Jiaju,ZHU Yiming,Gao Yunqi,et al.Synonyms[M].Shanghai:Shanghai Lexicographical Publishing House,1983.(in Chinese)
[5]张玉娟.基于知网的句子相似度计算的研究[D],北京:中国地质大学,2006.ZHANG Yujuan.Researches of Sentences Similarity Computation Method Based on Hownet[D].Beijing:China Univ of Geosciences,2006.(in Chinese)
[6]刘青磊,顾小丰.基于《知网》的词语相似度算法研究[J].中文信息学报,2010,24 (6):31-36.LIU Qinglei,GU Xiaofeng.Study on Hownet-based word similarity algorithm[J].Journal of Chinese Information Processing,2010,24 (6):31-36.(in Chinese)
[7]苏振魁,田园.基于公共子串的文本相似度计算模型[J],中文科技论文在线,2007.(1):54-57.SU Zhenkui,TIAN Yuan.Text similarity computing model based on common substrings[J].Sciencepaper Online.2007.(1):54-57.(in Chinese)
[8]冯凯,王小华,谌志群.基于动态规划的汉语句子相似度算法[J],计算机工程 vol.39,no.2,2013 FENG Kai,WANG Xiaohua,ZHAN Zhiqun.Chinese sentence similarity algorithm based on dynamic programming[J].Computer Engineering,2013,39 (2).(in Chinese)
[9]刘海涛.依存语法和机器翻译[J].语言文字应用,1997.vol.3,pp.89-93.LIU Haitao.Denpendency grammar and machine translation[J].Language Application,1997,(3):89-93.(in Chinese)
[10]李彬,刘挺,秦兵,李生.基于语义依存的汉语句子相似度计算[J].计算机应用研究,2003,12:35-36.LI Bing,LIU Ting,QIN Bing,LI Sheng .Chinese sentence similarity computing based on semantic dependency parsing[J].Application Research of Computers,2003,12:35-36.(in Chinese)
[11]田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报:信息科学版,2010,(6):602-608.TIAN Jiule,ZHAO Wei.Words similarity algorithm based on tongyici cilin in semantic web adaptive learning system[J].J Jilin Univ (information science ed.),2010,(6):602-608.(in Chinese)
[12]朱礼军,陶兰,刘慧.领域本体中的概念相似度计算[J].华南理工大学学报:自然科学版,2004.32(11):148-149.ZHU Lijun,TAO,Lan,LIU Hui.Calculation of concept similarity in domain ontology[J].Journal of South China Univ of Technology,2004,32(11):148-149.(in Chinese)
Chinese sentence similarity computing based on semantic dependency matching
WANG Weiming,LIANG Dongying
(Teaching-supervision Office,Shenzhen Institute of Information Technology,Shenzhen 518172,P.R.China.)
Sentence similarity computation is the base and core research topics of Chinese literature information processing.It has a wide range of applications,restricting the development of certain domain,such as sentence matching in information retrieval,answer extraction in question answering.This paper introduces a method of sentence similarity computation based on lexical similarity and sentence dependency matching.Experiments prove that this algorithm improves accuracy of system.
dependency;dependency matching;lexical similarity;dependency similarity;natural language processing
TP391.2
:A
1672-6332(2014)01-0056-06
【责任编辑:高潮】
2014-3-15
广东省自然科学基金(S2011010006118),深圳市科技项目(JCYJ20130401095947222)。
汪卫明(1982-),男(汉),安徽怀宁人,讲师,博士,主要研究方向:自然语言处理、信息检索、自动问答;E-mail:wangwiming@gmail.com
猜你喜欢
中学生数理化·八年级物理人教版(2022年5期)2022-06-05 06:57:38
西夏研究(2020年1期)2020-04-01 11:54:26
当代陕西(2019年15期)2019-09-02 01:52:00
新高考(英语进阶)(2018年3期)2018-05-14 07:38:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
现代工业经济和信息化(2016年2期)2016-05-17 05:34:16
中国医学影像学杂志(2015年9期)2015-12-15 11:03:26
语言与翻译(2014年3期)2014-07-12 10:31:59
导航定位与授时(2014年2期)2014-04-27 13:41:09
