
Cochran’s Q检验在多元多水平分组实验数据中的归纳
2014-03-13 07:58于晶晶
决策与信息 2014年27期
于晶晶
首都经济贸易大学 北京 100070
Cochran’s Q检验在多元多水平分组实验数据中的归纳
于晶晶
首都经济贸易大学 北京 100070
在统计分析中,多元多水平数据越来越多的被应用到现代科学的各个领域,对于这类数据分析方法的需求也随之上升。目前,对于二元数据在完全随机分组实验里的研究是最基本也是最普遍的一种分析,然而这种二元数据的分析并非简单易行。通常的方法是GLMM分析方法,因为这能够保证检验拥有很好的精度和适当的第一类错误水平。然而GLMM分析方法在计算上较为复杂且时常出现非收敛性。反观Cochran’s Q检验不但拥有GLMM分析的优势,同时简易的计算方法和结果的收敛性使得这种方法更加有效。以前的研究我可GLMM分析方法已经被更广泛的归纳,但Cochran’s Q检验仅仅应用于两元多水平的实验数据分析中。因此本文利用实例来阐述并解释Cochran’s Q检验在多元多水平数据中的应用。
多元多水平;完全随机分组实验;Cochran’s Q检验;GLMM;Wald统计量
引言
随着多元多水平数据在生物学,经济学,社会科学等多个领域中的广泛出现和应用,对这类数据分析方法的需求也日益增多。作为其中的代表,GLMM分析方法可以很好的解决这类数据在完全随机分组实验中的问题,但其计算的繁琐程度,分析的复杂性,以及结果收敛性的不足也限制了此方法的应用。Cochran’s Q检验以简单的计算,被频繁应用于多水平数据在完全随机分组实验中的分析,Stuart教授在1955年的研究中对于Cochran’s Q检验有个归纳,但仅仅针对于二元数据。在另一项之前的研究中,Minton教授和Evans教授于2013年发现Cochran’s Q检验和GLMM分析方法在检验精度以及第一类错误水平上,相对于其他一些统计检验有较明显的优势,而GLMM分析方法已经被广泛的应用以及归纳,但Cochran’s Q检验的开发和应用才刚刚延伸到二元多水平数据。本文的研究目的在于通过两个具体的实例,向读者展示Cochran’s Q检验对于二元多水平数据的分析以及延伸到对于多元多水平数据的分析。
基础工作
多元多水平数据在完全随机分组实验中的分析是基于二元多水平数据在完全随机分组实验中的分析,所以在此我们先回顾一下二元多水平数据在完全随机分组实验中的数理基础。
我们定义Yij为二重水平中第j个变量的第i个分组为:
假设原假设中等概率的假设是正确的,那么协方差阵中对于第j个变量的第i个水平是一个单独贝努利变量,他的结果可以表示为1成功,2失败:
由于贝努利变量只有两个结果,非1即2,所以我们可以将表达式简化为:
基于上面的表达式以及假设原假设是正确的,我们可以得出:
因此Y的协方差阵是:
在带入估计量πi后,我们可以得到一个关于协方差阵稳定的估计量。
在1955年,Stuart教授将Cochran’s Q检验延伸到可以分析二元多水平数据的完全随机分组实验,但是从二元向多元的延伸并没有出现在他的论文中,所以在下文中,我们将基于之前的分析研究,将Cochran’s Q检验从二元多水平数据的应用拓展到多元多水平数据的应用。
职中语文是提高学生语文表达能力与人文素养的重要课程,应该为学生的个人发展、社会需要、适应生活而服务。常规语文教学往往难以达到预期的目标,进行职业教育语文教学改革,促进语文教学专业化、个性化,走与市场相结合的道路十分必要。
定义多重贝努力变量Yijk对于第j个变量,第k个水平以及第i个分组
在原假设之下,处于同一水平下的t个变量的概率应该相同,对于第i个分组,概率的期望值为:
把第k个水平中的所有分组加和之后,我们可以得到估计量:
一个单独的多重贝努力变量(例如Yij)的协方差阵为:
假设原假设是正确的,在把第i个分组和第j个变量加和之后,协方差阵为:
或者表达为
带入估计量之后,我们就可以得到多重贝努力变量的协方差阵的估计量。在多重贝努力变量进行Cochran’s Q检验时,统计量W的表达式为
其中H是一个(t-1)(s-1)乘以ts的矩阵,而Wald的统计量也如之前一样,渐进的服从于自由度为H矩阵的秩例如((t-1)(s-1))的卡方分布。
实例:
为了验证之前数理理论的正确性,我们会用以下一个例子来将理论付诸于实际问题。
Remedios Vallimor是一位就读于美国华盛顿州立大学食品科学科学学院的博士生,他在研究乙醇浓度对于葡萄酒味觉影响的论文中使用了以下数据,在小组成员品评葡萄酒味觉时使用了3种不同浓度的乙醇,分别为8%,12%以及16%。本次试验使用了完全随机分组实验,一共有三个变量,对于每一种葡萄酒的水果香气我们定级为三个级别,为低(0),中(1)以及高(2),汇总后的数据如下表所示:

表2:8%,12%以及16%乙醇溶度对于葡萄酒味觉的影响
本次试验的目的在于调查不同浓度的乙醇水平,对于葡萄酒味觉的影响是不是显著的不同。基于原假设等概率的假设,那么相关的差异列表如下(此处只列出一部分):
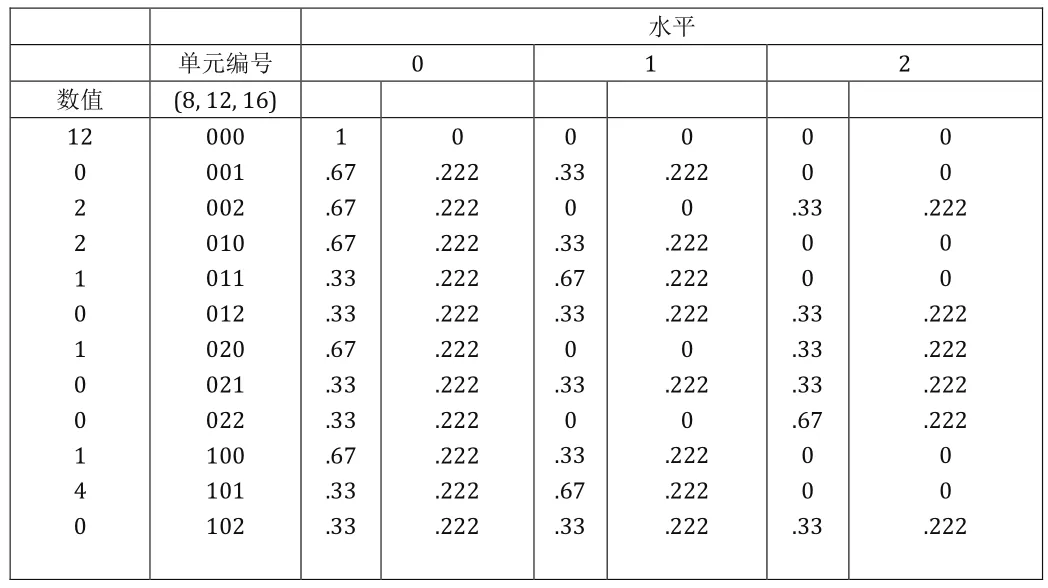
表3:三个不同水平下单元编号, 单元数值以及估计概率
从上表中的数值我们可以得出,Y的表达式,并且对于第j个变量的所有水平,我们可以得出协方差阵为:
在结合各个水平相对应的数值,我们可以得到他们的加和:
例如:单元编号002数值为2,单元编号020数值为1,单元编号200数值为1,单元编号220数值为2,那么总数值为6:
再结合三个变量,我们可以得到估计协方差阵:
利用下面的对比矩阵,我们便可以计算出总体的Cochran’s Q检验。
经过检验,得出的统计值为12.9405,自由度为4,P值为0.0116,由此可以得出结论:这三种不同的乙醇浓度会导致葡萄酒的口味有显著差异。由于总体的检验结论拒绝了原假设,那么就希望能够更进一步的探索出具体这三种不同浓度的乙醇之间的相互比较。基于Cochran’s Q检验的表达式,可以很方便的得出两两比较需要使用的原假设以及在计算中需要使用的矩阵H。
计算后我们得出三组比较分别得Wald统计量为: = 2.9418, = 12.1817 and = 4.2872.在95%的置信区间范围内,当自由度为2时,临界值为5.99,通过将Wald统计量于临界值相比较,我们可以得出,8%与12%的对比,以及12%与16%的对比都并不显著,但是8%与16%的比较则有显著地差距。同样的,我们再一次利用SAS中Proc NLMixed的模块计算出极大似然统计值,结果为13.4,自由度为4,P值为0.0095,由此我们可以同样的到拒绝原假设的结论。而利用这种方法得到的结果与我们Cochran’s Q检验的结果非常接近,也验证了我们理论的正确性及实用性。
讨论
当讨论和研究多元多水平数据在完全随机分组实验中的分析时,Cochran’s Q检验这种分析方法为我们提供了便捷的计算以及准确的结果。就如上述的例子,利用Cochran’s Q检验得到的结果,与利用计算更为复杂的GLMM分析方法所得出的结论非常接近。尽管仅通过一个例子很难全方位的展示该理论的准确性以及实用性,但是我仍然坚信该理论能够很好地应用于科学研究之中。对于该检验的其他侧面,例如精度以及第一类错误的水平等,会在之后的研究,利用电脑模拟的方法进行检测,并与其他的主流检验方法进行比较。
于晶晶(1990-),女,北京市,研究生在读,学历:研究生,研究方向:数据挖掘。
猜你喜欢
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年11期)2021-09-05
建材发展导向(2021年6期)2021-06-09
舰船科学技术(2021年12期)2021-03-29
舰船科学技术(2021年12期)2021-03-29
舰船电子工程(2020年3期)2020-06-11
中国航海(2019年2期)2019-07-24
经济研究导刊(2018年24期)2018-09-18
经济研究导刊(2018年19期)2018-07-24
