
一种基于层次结构深度信念网络的音素识别方法
2014-02-21 11:49:06杨俊安
应用科学学报 2014年5期
王 一, 杨俊安, 刘 辉, 柳 林, 卢 高
1.电子工程学院404教研室,合肥230037
2.安徽省电子制约技术重点实验室,合肥230037
3.科大讯飞公司,合肥230037
4.77108部队52分队,成都611233
音素识别是指将连续语音识别成对应音素序列的过程[1],它作为现代语音识别技术的基本组成模块,已广泛应用于语音识别的各个领域,如关键词检出(keyword spotting,KWS)、语种识别(language identif ication,LI)、说话人识别(speaker identif ication,SI)等.音素识别技术在关键词检出中的作用是将包含关键词和非关键词的语音转化成相应音素序列,然后通过在音素序列中滑动关键词模板[2]或搜索对应音素词格网络(phoneme lattice)[3]检出关键词.这一领域代表性的最新成果是点过程模型[2]以及基于连续大词汇量语音识别(large vocabulary continuous speech recognition,LVCSR)的关键词检出系统[3].在基于音素识别技术的语种和说话人识别框架中,目标语种和说话人被具有区分性的音素模型分别表示,然后再利用这些已建立的模型与其他语种和说话人进行比对,以检出对应语种和说话人.利用音素识别技术的语种和说话人识别方法主要有并行音素识别(parallel phoneme recognition,PPK)、语种建模(languagemodel,LM)方法[4]和TRAPs(tempo RAl patterns,TRAPS)等[1].因此,有效的音素识别方法对推动整个现代语音识别技术的发展具有重要意义.
主流的音素识别系统主要有三部分组成,分别为特征提取、声学模型建立、解码[1].对于特征提取部分而言,它的主要功能是从输入的原始语音中提取出有利于后续分类识别的语音特征.目前用于音素识别的特征主要有梅尔倒谱系数(mel-frequency cepstral coefficient,MFCC)、感知线性预测特征(perceptual linear predictive,PLP)以及差分倒谱参数(shifted delta cepstra,SDC)等.对于声学模型部分,其主要作用是匹配输入的语音特征,进而识别出对应的语音单元(音素或词等).主流的音素识别建模方法可以简单归纳为两大类:第一类是将高斯混合模型(gaussian mixturemodel,GMM)和隐马尔科夫模型(hidden markov model,HMM)相结合的方法;另一类是将多层感知器(multilayer perceptron,MLP)和HMM相结合的音素建模方法[1].音素识别系统中的解码器从获得的语音单元中寻找出最有可能的语音单元排列方式,输出识别结果,但这个过程需要语言模型的参与.本文研究的重点集中于前两部分,即语音特征提取和声学模型建立.
对于当前语音特征而言,它们在实际应用中均存在着不足,如以MFCC和PLP等为代表的短时语音特征,它们的共同特点是每帧信号只包含20~30 ms语音.所含的语音段时长短,这就使得短时语音特征较易受到噪声干扰,鲁棒性差;而且反映音素间转换的信息都包含在数十甚至上百毫秒的语音段内,这也导致短时语音特征无法对其进行有效利用.另外,传统语音特征如SDC等都采用非监督的提取方式,这就使得这些特征无法对类别信息进行有效利用.对于当前的声学模型构建方法,由于GMM、ANN等均属于浅层结构(shallow-structure)的建模方式,它们都存在着建模能力不足,无法对复杂的语音信号进行表征的问题[5];而且ANN等还存在容易陷入局部最优的问题.上述缺陷限制了现有音素识别系统准确率的提升.
针对上述问题,由文献[6]提出的深度信念网络(deep belief network,DBN)为解决这些问题提供了新的思路.虽然从本质上来说,DBN仍然是一种MLP,但它在原有神经网络监督式回调(back propagation,BP)算法之前增加了非监督的预训练过程,这个过程能够将神经网络的初始值设置在一个最有可能达到全局最优的范围内,从而克服了困扰神经网络界多年的MLP容易陷入局部最优的问题[5].不仅如此,DBN还被证明能够有效利用其深度结构(deepstructure)对自然界中的语音信号进行建模,且建模效果好于传统浅层结构的建模方法(一般认为,浅层结构的建模方法包括隐马尔科夫模型、条件随机场和支持向量机等)[5].DBN已经在语音识别领域得到了应用,利用DBN构架的瓶颈特征和音素分类器已经在音素识别中的特征提取和声学模型这两个方面展现出优于现有其他方法的特性.对于瓶颈特征来说,顾名思义,瓶颈的意思就是指DBN中位于最中间层(即瓶颈层)的神经元个数相对于其他层要少得多,整个网络结构酷似一个瓶颈[7].相比于传统语音特征,瓶颈特征具有诸多优点:对输入数据的内部统计结构和密度函数要求不严格,能将长时段语音信号拼接后使用;对发音人的说话方式、口音以及环境噪声和传输设备差异鲁棒性强;神经网络监督式的训练方式使得输出的瓶颈特征能够包含类别信息,有利于后续的分类识别;瓶颈层的引入进一步降低了输出特征的维度,从而减少了后续的运算量[7].而将DBN作为音素分类器主要是替代声学模型建模方法中的GMM或ANN,用来产生HMM的观察值概率矩阵.正如前文所述,由于DBN具有更强的建模能力,因此相对于传统方法,利用DBN+HMM建模方法能够更好地表征输入的音素序列,用其进行音素识别的效果要好于原有方法[8-9].
现有的基于DBN的瓶颈特征和音素分类器仍有进一步提升性能的空间.而对于基于DBN的方法,提升性能最简单和直接的方法就是通过增加DBN网络的隐层数(即增加非线性运算单元的层数)或每个隐层所含神经元数来实现.但是相关研究也发现,大规模的增加隐层数目以及神经元数目会导致整个神经网络训练时间过长,而且当DBN中的隐层数和神经元数目达到一定峰值后,再增加数目并不会提升识别性能[8-9].因此要进一步提升基于DBN的瓶颈特征和音素分类器的性能就需要从改变整个提取网络的结构组成上入手.本文将一种层次结构的神经网络架构方式引入到基于DBN的提取网络架构中.基于层次结构的神经网络架构方式由文献[10-11]提出并应用于音素和连续语音识别领域.层次结构是指将两个或多个MLP串联后进行使用的一种网络架构方式,它的优点在于能够利用第1个MLP先对输入的原始特征进行一次后验概率估计,而得到的后验概率特征一方面能够有效减少说话人习惯、外界噪声等对原始特征的影响;相比于原始输入特征,后验概率特征包含了更多的音位配列和发音信息:这些优点使得基于层次结构的MLP取得了相对于单个MLP更好的音素识别效果[10-11].因此,本文将这种网络架构方式应用于DBN网络的构建中.
综上所述,本文受层次结构的网络架构方式和DBN的双重启发,将这两种音素识别领域的最新研究成果相结合,提出了一种基于层次结构DBN的音素识别方法,将特征提取和声学模型有效地结合在一起.它在网络结构上由3个DBN串联而成的,其中前两个DBN的作用是从11帧拼接而成的长时段语音中提取出瓶颈特征,后一个DBN利用得到的后验概率特征对音素进行识别,输出音素后验概率到HMM中.基于本文方法的音素识别系统结构框图如图1所示,其中虚线框中的部分是本文完成的工作,下文将其统称为基于层次结构DBN的音素识别器.

图1 基于层次结构DBN的音素识别系统原理框图Figure 1 Schematic representation of hierarchical DBN based phoneme recognition system
本文提出基于层次结构DBN的音素识别器的初衷是充分利用DBN能够处理较长时间段语音的特点,将包含更多音素间转换信息的11帧拼接MFCC作为输入特征,然后将其转化为低维且包含监督信息的瓶颈特征,送入具有更强非线性建模能力的DBN分类器中输出音素的后验概率特征,从而达到较好的音素识别效果.在实验部分,利用本文提出的基于层次结构DBN的音素识别器构建了新的音素识别系统,该系统在TIMIT数据库上进行了实验,结果表明本文方法得到的音素错误率(phoneme error rate,PER)降低到18.5%,低于其他对比系统.
1 深度信念网络(DBN)[5-6]
一个标准的DBN结构图如图2所示.DBN本质上仍然是一种MLP,但与传统MLP不同的是:它是由一系列受限波尔兹曼机(restricted Boltzmann machine,RBM)叠加而成的.
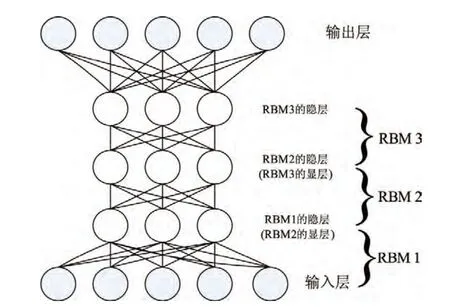
图2 DBN的结构图Figur e 2 Schematic representation of DBN
一个典型的RBM子模块结构图如图3所示,它是由两层神经元构成的:其中一层是显层神经元vi(一般为伯努利型或高斯型),另一层为隐层神经元hj(一般为伯努利型).显层神经元和隐层神经元之间相互连接,但同一层之间没有连接.各层间的连接系数和偏置量是采用无监督的贪心算法获取的,对于一个简单的伯努利-伯努利RBM来说,它的能量函数可以表示为
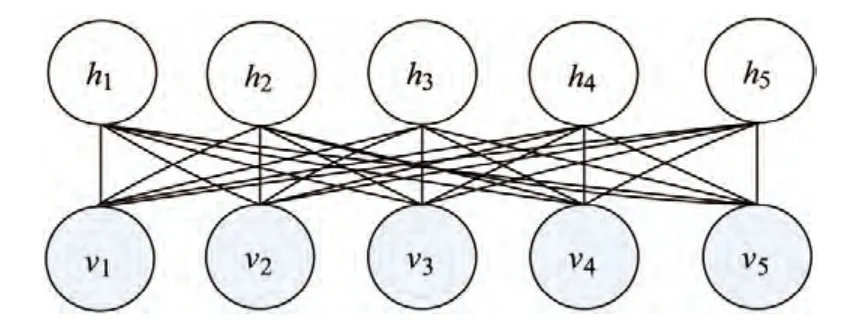
图3 RBM子模块模型Figure 3 Submodule model of RBM
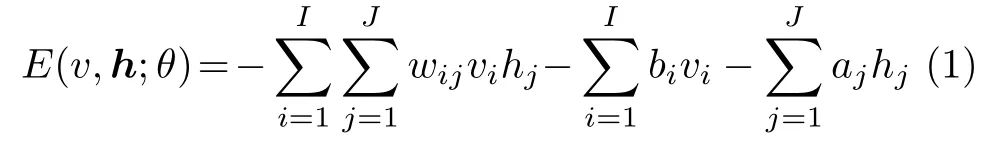
式中,vi和hj分别为RBM中的显层和隐层神经元,wij为显层和隐层神经元之间的连接系数,bi和aj为对应的偏置量.由式(1)可以得到对应于显层神经元和隐层神经元的相应映射概率分布为
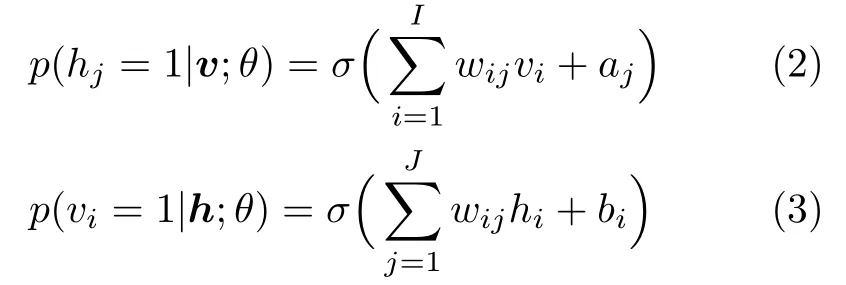
式中,的σ是sigmoid激励函数.由于伯努利-伯努利RBM不能很好地对自然界的真实数据如语音进行建模,在实际应用中一般采用高斯-伯努利RBM对语音进行建模,高斯-伯努利RBM的能量函数可以表示为式中,vi为真实数据(如语音),σi为控制能量函数宽度的参数.由式(4)同样可以得到对应于显层神经元和隐层神经元的概率分布为
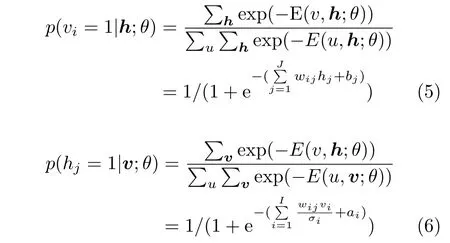
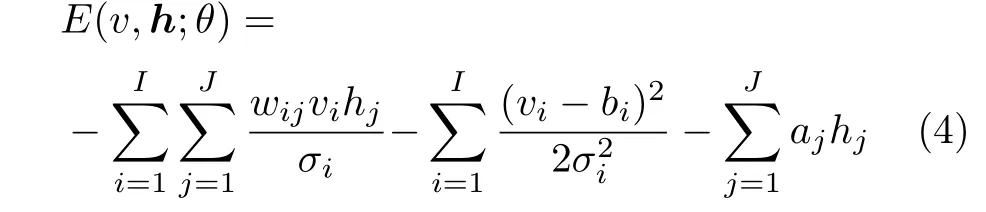
式中,σ是sigmoid激励函数.利用梯度下降法计算对数似然概率lg p(v,h;θ),可以推导出RBM的系数更新公式为
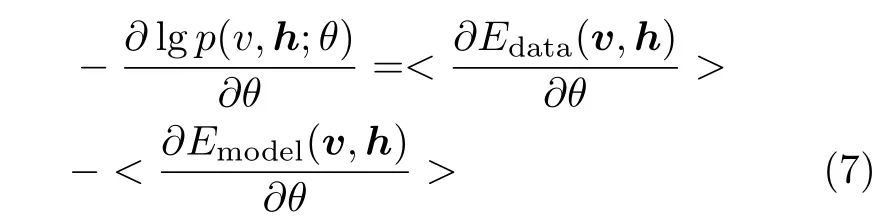
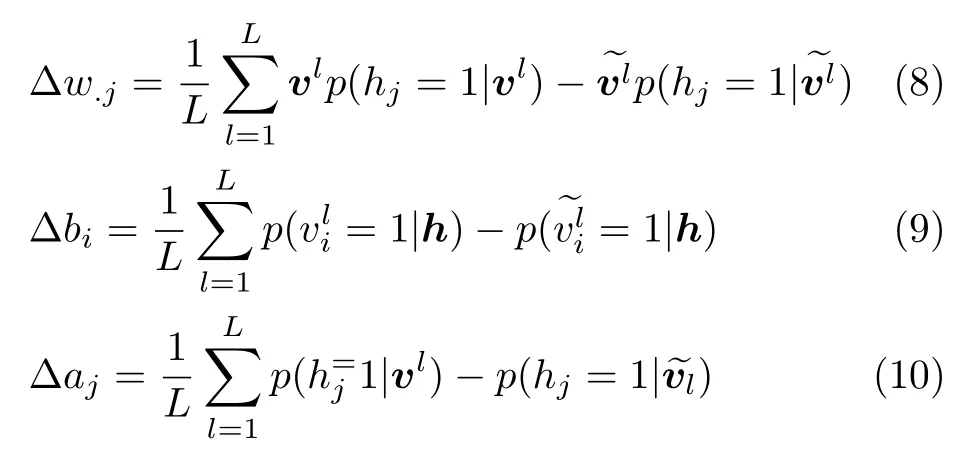
式中,(~)表示由CD算法获得的对vi的估计值.通过式(8)~(10)这样一个非监督的预训练过程就可以将一个RBM调整到合适的初始值,然后再将多个RBM自底向上组合就可以建立起一个DBN,最后采用BP算法对整个网络进行监督式学习,最终建立DBN.DBN的训练方式与传统MLP训练方法最大的不同是它能够利用非监督的预训练将神经网络的初始值设定到最优值附近,这个过程能够最大限度地避免局部最优解.文献[5-6]给出了预训练能够有效避免局部最优解的详细证明.
2 基于层次结构DBN的音素识别器
一个完整的基于层次结构DBN的音素识别器如图4所示.它是由3个DBN串联而成的.其中第1个和第2个DBN用来产生后验瓶颈特征,第3个DBN则利用后验瓶颈特征估计出音素的后验概率.本节分别介绍基于层次结构DBN的后验瓶颈特征产生网络和基于DBN的音素分类器对应的DBN结构和训练方式.
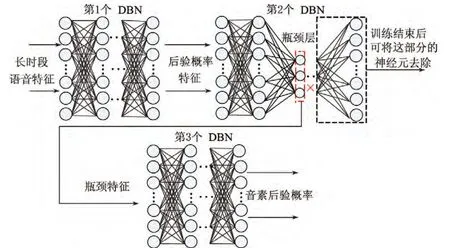
图4 基于层次结构深度信念网络的音素识别器Figure 4 Topology of hierarchical DBN based phoneme recognizer
2.1 基于层次结构DBN的后验瓶颈特征提取网络
本文通过将2个DBN串联的方式获得后验瓶颈特征.这2个DBN的功能各有不同,第1个DBN用来对输入的原始特征进行后验概率估计;第2个DBN将第1个DBN输出的后验概率特征进行降维和增加判决性处理,提取最终的后验概率瓶颈特征.相比于传统的使用单个MLP或DBN来提取瓶颈特征的方法,使用两个DBN的优势主要在于它在提取瓶颈特征之前利用第1个DBN提前进行了一次后验概率估计,这个过程已被证明不仅能有效避免随后的音素后验概率估计误差,还能将特征投影到后验概率空间中,从而最大程度地去除背景噪声、说话人方言等对语音特征的影响,文献[12]已通过大量实验证明了这种层次结构的后验瓶颈特征方法对于连续语音识别任务的有效性.因此,本文也采用将两个DBN串联的方式提取后验瓶颈特征.
第1个DBN的训练过程与其他应用于语音识别任务的DBN训练非常相似[8-9],唯一的区别就在于本文使用的输入特征是11帧拼接的长时段语音特征.获得11帧长时段语音特征的具体做法是将一帧特征的前后各5帧按顺序连接后作为单个特征使用.本文使用11帧拼接的语音特征作为输入特征有两方面的原因:一是因为长时间段的语音特征能够提供更丰富的音素间转移、变化信息,相比于单帧特征包含了更多语音信息[10-11],这对于提高后续的音素识别率具有很大帮助;二是根据文献[13]的成果,DBN相对于传统声学模型建模方法的一大优势,就在于其可以有效利用较长时间段的语音特征,而且使用长时段语音特征的DBN,识别效果明显好于使用短时语音特征.本文采用43维的MFCC作为输入的单帧特征,43维MFCC包含了39维的MFCC特征(静态、一阶、二阶差分)以及4维的音调特征.因此,输入特征维度以及输入层的神经元数目均为473(43×11).为此,第1个DBN的网络结构可以表示成473-[1024-1024-1024-1024-1024]-473的形式,其中在[]中的数字表示了DBN中的隐层.
第1个DBN的输出将作为第2个DBN的输入特征使用.而第2个DBN的网络结构被设置成对称形式,最中间的瓶颈层神经元数目要远小于其他层,而在训练完毕后,瓶颈层之后的各层被去除(即图4虚线框中部分),瓶颈特征由第2个DBN的瓶颈层输出.之所以采用这种在整个DBN训练完成后再去除多余层的方法,而非直接将瓶颈层作为输出层使用,主要有两方面的原因:一是相关研究已经证明了当输出层的神经元数目较多时,它对类别信息的利用更加准确和有效[14];二是通过实验发现,当将瓶颈层设置在整个DBN的中间时,通过BP算法往回传递类别信息的效果好于网络的输出层,也即将瓶颈层设置于DBN中间的方式能够获得更多利于分类的信息.因此,本文将瓶颈层设置于第2个DBN的最中间.为此,第2个DBN的网络结构可以表示成473-[2048-1024-43-1024-2048]-473的形式,同时为了取得最佳的识别效果,本文根据文献[9],将瓶颈层神经元数目设置为43个,即等同于初始的输入MFCC特征.
2.2 基于DBN的音素分类器
通过前两个DBN得到后验瓶颈特征之后,第3个DBN的作用是将得到的包含265 ms语音信息的后验瓶颈特征转化成对应的音素后验概率.第3个DBN的结构可以表征为43-[1024-1024-1024-1024-1024]-183的形式,其中的输入层神经元对应于43维瓶颈特征,输出层采用183个神经元组成.
在第3个DBN的输出层之外,还需要增加一个采用softmax函数的输出层,其中的每个神经元对应后续HMM中的一个状态,此时基于DBN的音素分类器输出的结果形式为后验概率,反映了HMM状态与输入语音特征的后验概率比,即P(HMM状态/特征).
2.3 将DBN输出转化为适应于Viterbi解码的概率形式
为了在HMM的框架下对基于DBN的音素分类器输出进行Viterbi解码,需要利用Bayes公式将其转化为输入语音特征与HMM状态的概率形式,即P(特征/HMM状态),转化公式为

式中,P(HMM状态)为一个常数,一般通过将训练数据中的HMM状态进行forced alignment后再进行归一化获得.P(特征)为常数,因此在解码的过程中忽略不计.将式(12)获得的概率送入Vietrbi解码器进行解码,就可以获得输入特征所对应的音素序列.
3 实验设计
3.1 数据库
利用TIMIT数据库验证本文提出的音素识别器的有效性.实验使用了4.3 h的语音数据(其中包含1.1 h的NIST测试数据).数据库中的训练集数据排除了SA1和SA2语句,共包含由462个不同发音人朗读的3 296个句子,测试集为TIMIT核心测试集(Core Test),包含由24个不同说话人朗读的192个句子,训练集和测试集之间没有相同的说话人.在训练集和测试集之外,再利用TIMIT数据库中的60个说话人共500个句子作为开发集.对输入语音,采用窗长25 ms,窗移10 ms的汉明窗进行采样.所有数据均进行了归一化处理.
3.2 DBN训练工具
正如在第1节中所述,DBN的训练极耗时间.为此采用Python中的Theano库来进行DBN训练.Theano是根据DBN训练特点而创建的Python库,它不仅操作简单,而且可以通过调用GPU加速整个训练过程,Theano用于DBN训练的相关资料可参见文献[15].根据DBN训练中的实际经验,用Theano调用GPU进行DBN训练的速度是使用单核Intel 2.66 GHz至强处理器的20倍. 在使用Theano对DBN进行预训练之后,本文使用经过调整后的Quicknet工具包对整个DBN进行微调.
3.3 DBN训练参数
使用小批量(mini-batch)的梯度下降法对RBM进行预训练,每个mini-batch为256个输入样本.对于高斯-伯努利RBM,其训练次数(epoch)为250;对于伯努利-伯努利RBM,其epoch为80.为了避免DBN在训练过程中过早地收敛于局部最优点,本文通过在训练过程中增加随机数种子的方式来控制训练数据的顺序,使得每个epoch的训练数据按照不同的顺序排列.训练过程中的冲量(momentum)项经过多次试验,最终设置为0.9,在momentum=0.9时的最优学习速度为0.006;权重衰减因子(weight decay)经过多次试验验证后设置为1e-8.对于微调部分,则使用mini-batch=512个输入样本,momentum和weight decay与预训练过程相同.
3.4 解码
在第3个DBN的输出部分,将得到的各个音素类的后验概率作为一个三状态HMM的观察值概率使用,从而完成对各个音素的建模.随后的Viterbi算法将用于对得到的音素序列进行解码.
实验服务器配置如下:12G内存,24核Intel®Xeon®E5-2620 CPU,操作系统为Linux Ubuntu 10.10,GPU为NVIDIA GTX 650,其开发环境采用NVIDIA的CUDA 4.1.
4 实验结果与分析
本文设计了3个不同实验来验证基于层次结构DBN的音素识别器的有效性.第1和第2个实验分别通过调整每个DBN中隐层神经元数目以及DBN所含隐层的层数来确定最优的DBN参数配置,实验1验证了最佳的层次结构DBN后验瓶颈特征提取网络的结构配置,实验2验证了最佳的DBN音素分类器的网络结构配置,实验3将基于层次结构DBN的音素识别系统与当前主流的音素识别结果进行比较,验证了本文提出方法的有效性.
4.1 实验1
实验1通过分别调整后验瓶颈特征生成网络中每层神经元数目以及隐层层数,来寻找最佳的网络结构配置.DBN的隐层层数从1~6层之间变化,每个隐层所含神经元数目在512~2 048之间波动.为简便起见,实验中每个隐层的神经元数目设置为相同.图5显示了对第1个DBN调整隐层神经元数目以及隐层层数后对最终PER的影响,此时第2个DBN的结构被设置为473-[2048-1024-43].图6显示了对第2个DBN调整隐层神经元数目以及隐层层数对最终音素识别结果的影响,此时第1个DBN的结构被设置为473-[1024-1024-1024-1024-1024]-473.
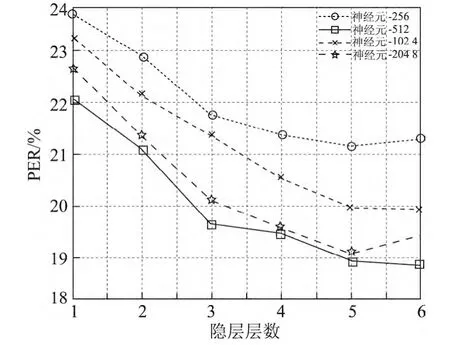
图5 第1个DBN改变网络结构后对音素识别错误率的影响Figure 5 PER by varying the number of layers and size of each layer of the 1st DBN
从图5和6中可以看出,增加隐层的层数以及增加隐层的神经元数目能够有效提高音素识别准确率.这个结果也直接证明了对于具有深度结构的DBN,增加神经元数目和隐层层数能够有效地提高其性能.从图5和6中还能看出,当隐层数达到5层时,每层神经元为1 024个,再增加隐层数量以及神经元的数目对效果的提升影响不大,因为网络已经达到了一个饱和状态.因此,综合考虑计算效率和正确率,本文将第1和第2个的DBN的结构分别设置成473-[1024-1024-1024-1024-1024]-473和473-[2048-1024]-43.
4.2 实验2
与实验1类似,本文通过改变DBN的隐层数量以及每层神经元数目来确定最优的音素分类器网络结构.DBN的隐层层数从1~6层,每个隐层所含神经元数目在512~2 048之间变动.在实验中,每个隐层的神经元数目设置为相同.同时,根据实验1的结果,第1和第2个DBN的网络结构被设置为473-[1024-1024-1024-1024-1024]-473和473-[2048-1024-43]的形式.图7显示了对第3个DBN调整隐层神经元数目以及隐层层数对最终音素识别结果的影响.
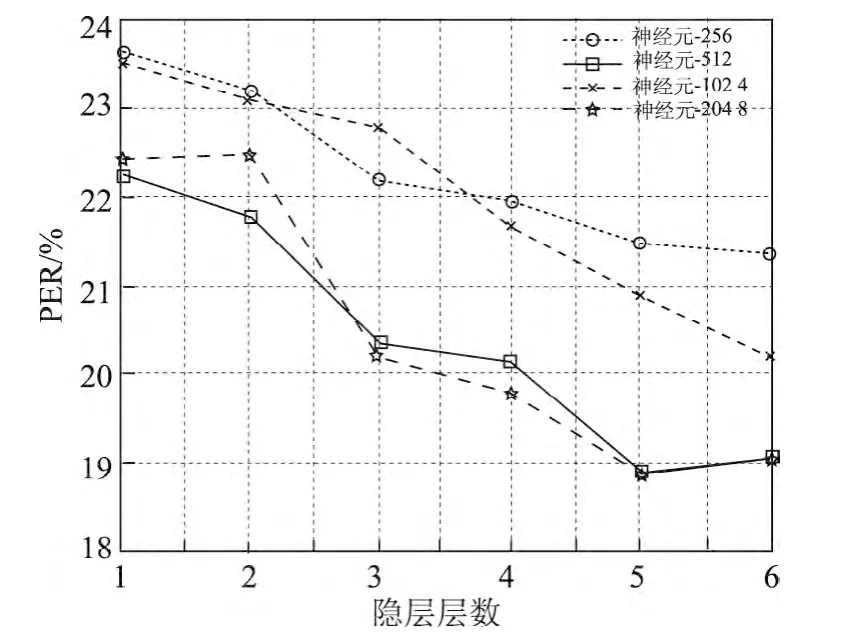
图6 第2个DBN改变网络结构后对音素识别错误率的影响Figure 6 PER by varying the number of layers and size of each layer of the 2st DBN
从图7中可以看出,音素错误率变化的趋势基本与实验1的结果相同,即增加隐层的层数以及增加隐层的神经元数目能够有效地提高音素识别准确率.因此综合考虑计算效率和正确率,本文将第3个DBN的结构设置成43-[1024-1024-1024-1024-1024]-183.
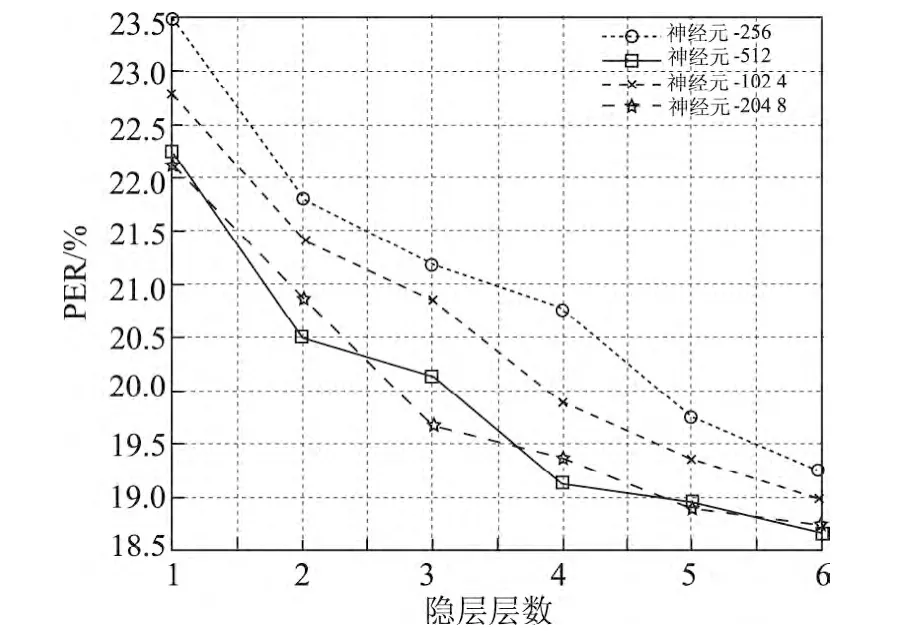
图7 第3个DBN改变网络结构对音素识别错误率的影响Figure 7 PER by varying the number of layers and size of each layer of the third DBN
4.3 实验3
实验3将基于层次结构DBN的音素识别系统得到的识别结果与现有其他音素识别系统的结果进行了比对,采用的基于层次结构的DBN音素识别器如图4所示,其具体结构如下:第1个DBN共含5个隐层,神经元数目为473-[1024-1024-1024-1024-1024]-473;第2个DBN共含2个隐层,其神经元数目为:473-[2048-1024]-43;第3个DBN共含5个隐层,其神经元数目为:43-[1024-1024-1024-1024-1024]-183.表1显示了实验结果.

表1 本文方法与现有其他音素识别系统的识别结果对比Table 1 Compare the best performing of the proposed system with previously reported results on TIMIT test set
表1的结果表明,基于层次结构DBN的音素识别器构建而成的新音素识别系统能够取得相对以往方法更好的识别结果,音素识别错误率减低到了18.5%.这是因为本文提出的系统相对于传统的CD-HMM、Triphone HMMs discriminatively trained w/BMMI等,采用了表征和建模能力更强的DBN来替换GMM,从本质上克服了GMM表征能力不足的问题;而相对于Monophone DBN等方法,本文提出的音素识别系统将它们两者的优点融合在一起,即将层次结构与DBN相结合,同时又采用了更具有判决性的瓶颈特征,因此取得了相较以往方法更好的结果.
5 结语
本文提出了一种基于层次结构DBN的音素识别器,并在其基础上构建了一种基于层次结构DBN的音素识别系统.该系统由基于层次结构DBN的后验瓶颈特征和基于DBN的音素分类器组成,它在网络结构上由3个DBN串联组成,其中前两个DBN主要用来产生后验瓶颈特征,而第3个DBN则用来对输入的音素类型进行分类.其目的是将后验瓶颈特征这种低维、包含利于分类的监督性信息的新型语音特征与DBN这种更加有效的非线性分类器相结合,从而获得更好的音素识别结果.本文在实验部分利用TIMIT数据库对这种新的音素识别系统进行了检验.实验结果表明,本文提出的方法取得了比以往音素识别系统更好的识别结果,音素识别错误率降低到18.5%.
DBN的训练非常耗时,而且需要占用大量的系统资源,这是本系统的缺陷所在.但是在实践中发现,在训练过程中仅有10%~20%左右的神经元是同时激活的,也就是说仅有少量的神经元对识别结果直接产生作用,整个神经网络呈现稀疏的状态.因此,下一步研究重点是将稀疏表示引入到DBN的训练中以提高训练速度.
[1]SCHwARZP.Phoneme recognition based on long temporal context[D].Faculty of Information Technology BUT,Brno University of Technology,Brno,Czech,2008.
[2]JANSENA,NIYOGIP.Point process models for spotting keywords in continuous speech[J].IEEE Transaction on Audio,Speech,and Language Processing,2009,17(8):1457-1470.
[3]SIOHANO,BACCHIANI M.Fast vocabulary independent audio search using path-based graph indexing[C]//Proceedings of the Eurospeech 2005,Lisbon,Portugal,4-8 September 2005.
[4]MATEJKA P,SCHwARZ P,CERNOCKÝJ,CHYTIL P.Phonotactic language identif ication using high quality phoneme recognition[C]//Proceedings of the INTERSPEECH,Lisbon,Portugal,2005:2237-2240.
[5]DENG L.An overview of deep-structured learning for information processing[C]//Proceedings of the Asian-Pacif ic Signal and Information Processing-Annual Summit and Conference,Xian,China,2011:1-14.
[6]HINTONG,SALAKHUTDINOVR.Reducing the dimensionality of data with neural networks[J].Science,2006,313(5786):504-507.
[7]BAOY,JIANGH,LIUC.Investigation on dimensionality reduction of concatenated features with deep neural network for LVCSR systems[C]//Proceedings of the IEEE 11th International Conference on Signal Processing(ICSP2012),Beijing,China,2012:562-566.
[8]MOHAMED A,DAHL G,HINTON G.Acoustic modeling using deep belief networks[J].IEEE Transaction on Audio,Speech,and Language Processing,2012,20(1):14-22.
[9]DAHL G,DONG Y,DENG L,ACERO A.Contextdependent pre-trained deep neural networks for large vocabulary speech recognition[J].IEEE Transaction on Audio,Speech,and Language Processing,2012,20(1):30-42.
[10]PINTOJ,SIVARAMG,MAGIMAI-DOSSM,HERMANSKY H,BOURLARDH.Analysis of MLP based hierarchical phoneme[J].IEEE Transactions on Audio,Speech,and Language Processing,2011,19(2):225-241.
[11]SIVARAM G,HERMANSKY H.Sparse multilayer perceptron for phoneme recognition[J].IEEE Transactions on Audio,Speech,and Language Processing,2012,20(1):23-29.
[12]TARA S,BRIAN K,BHUVANA R.Auto-encoder bottleneck features using deep belief networks[C]//Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing 2012,Kyoto,Japan,March 2012:4153-4156.
[13]SINISCALCHI S,YU D,DENG L,LEE C H.Speech recognition using long-span temporal patterns in a deep network mode[J].IEEE Signal Processing Letters,2013,20(3):201-204.
[14]DONGY,DENGL.DEEPL.Its applications to signal and information processing[J].IEEE Signal Processing Magazine,2011,28(1):145-154.
[15]BERGSTRA J,BREULEUX O,BASTIEN F,LAMBLIN P,PASCANU R,DESJARDINSG,TURIAN J,WARDEFARLEY D,BENGIO Y.Theano:a CPU and GPU math expression compiler[C]//Proceedings of the Python for Scientif ic Computing Conference(SciPy)2010.Austin,U.S.A.
猜你喜欢
中学生英语·阅读与写作(2023年9期)2023-10-19 14:24:34
高技术通讯(2021年1期)2021-03-29 02:29:44
北京教育·普教版(2020年9期)2020-10-09 11:15:09
校园英语·中旬(2019年11期)2019-11-26 10:01:06
人民珠江(2019年4期)2019-04-20 02:32:00
疯狂英语·新策略(2018年7期)2018-08-29 08:54:26
法律方法(2017年2期)2017-04-18 09:00:37
项目管理技术(2016年6期)2016-05-17 05:38:29
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
